Analyzing and transforming a computer program for executing on asymmetric multiprocessing systems
US20080098208A1
2008-04-24
11/898,360
2007-09-11
Abstract:
A method is disclosed for transforming a portion of a computer program comprising a list of sequential instructions comprising control code and data processing code and a program separation indicator indicating a point where said sequential instructions may be divided to form separate sections that are capable of being separately executed and that each comprise different data processing code. The m method comprises the steps of: (i) analysing said portion of said program to determine if said sequential instructions can be divided at said point indicated by said program separation indicator and in response to determining that it can: (iia) providing data communication between said separate sections indicated by said program separation indicator, such that said separate sections can be decoupled from each other, such that at least one of said sections is capable of being separately executed by an execution mechanism that is separate from an execution mechanism executing another of said separate sections, said at least one of said sections being capable of generating data and communicating said data to at least one other of said separate sections; and in response to determining it can not: (iib) not performing step (iia). If step (iia) is not performed then a warning may be output, or the program may be amended so it can be separated at that point, or the program separation indicator may be removed and the sections that were to be separated merged.
Inventors:
- Alastair David REID 8 🇬🇧 Cambridge, United Kingdom
- Simon Andrew FORD 33 🇬🇧 Cambridge, United Kingdom
- Yuan Lin 1 🇺🇸 Hillsboro, OR, United States
Assignee:
- ARM Limited 3,187 🇬🇧 Cambridge, United Kingdom
Interested in similar patents?
Get notified when new applications in this technology area are published.
Classification:
G06F11/362 » CPC main
Error detection; Error correction; Monitoring; Preventing errors by testing or debugging software Software debugging
G06F11/3636 » CPC further
Error detection; Error correction; Monitoring; Preventing errors by testing or debugging software; Software debugging by tracing the execution of the program
G06F9/38 IPC
Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs; Arrangements for executing machine instructions, e.g. instruction decode Concurrent instruction execution, e.g. pipeline, look ahead
Description
This application claims the benefit of U.S. Provisional Application No. 60/853,756, filed Oct. 24, 2006, the entire content of which is hereby incorporated by reference in this application.
BACKGROUND OF THE INVENTION
1. Field of the Invention
The field of the invention relates to data processing and in particular to improving the performance of program execution.
2. Description of the Prior Art
It is becoming increasingly difficult to provide programs that are simple to write and yet perform efficiently on complex systems. Such complex systems may comprise a number of different processing or execution units and they may be heterogeneous or asymmetric, with specialised processing units being used to increase energy efficiency and lower gate count. In particular, the programming of embedded systems with their hardware restriction, demand for efficiency and the ever decreasing time to market is becoming a real problem.
It is known in high level computing systems to provide multiple processors that are identical and to split processing between them to increase efficiency. In such systems a loop that executes say 100 times, may be split so that a first processor processes the loop for the first fifty times and the second for the second fifty.
It is also known to address the problem of programming multiprocessing systems by sending individual instructions to be processed to separate execution units where the processors communicate with each other via FIFO queues. This is effective in allowing a sequential program to be processed using many different execution units on a complex system, however, there is a need for low latency high throughput data communication mechanism to enable this to function efficiently. Clearly such mechanisms have an overhead of area and power.
Decoupling programs to produce a number of threads communicating via FIFO pipelines has been used many times before: Smith (James E. Smith, “Decoupled access/execute computer architectures”, ACM Transactions Computing Systems, 2(4), 289-308, 1984) applies the technique manually to Cray assembly code; Palacharla and Smith (S. Palacharla and J. E. Smith, “Decoupling integer execution in superscalar processors”, in MICRO 28: Proc. of International Symposium on Microarchitecture, 285-290, 1995) describe the use of program slicing to automate the separation. These uses of decoupling were targeted at hiding memory latency by having one thread perform all load-store operations while the other thread performs all arithmetic operations. Decoupling has experienced a revival in some very interesting recent work: Ottoni et al. (G. Ottoni, R. Rangan, A. Stoler and D. August, “Automatic Thread Extraction with Decoupled Software Pipelining”, in MICRO '05: Proc. Int. Symposium on Microarchitecture, 2005), use decoupling to parallelize inner loops for multiprocessors, and Dai et al. (J. Dai, B. Huang, L. Li and L. Harrison, “Automatically partitioning packet processing applications for pipelined architectures”, in Proc. 2005 Conf. on Programming language design and implementation, 237-248, ACM Press, 2005), use decoupling to parallelize packet processing code for multithreaded, multiprocessor packet processing processors. In both papers, the boundary between threads is automatically chosen to optimize performance through load balancing and reducing communication cost.
The majority of prior work on decoupling uses what we call “fine-grained decoupling”: the operations being split between threads are individual machine instructions and the data passed between threads consists of scalar values. In contrast, Ziegler et al. (H. Ziegler, B. So, M. Hall and P. Diniz, “Coarse-Grain Pipelining on Multiple {FPGA} Architectures”, in FCCM '02: Proc. of Symposium on Field-Programmable Custom Computing Machines, 2002) and Du et al. (W. Du, R. Ferreira and G. Agrawal, “Compiler Support for Exploiting Coarse-Grained Pipelined Parallelism”, in Proceedings of the ACM/IEEE SC2003 Conference on High Performance Networking and Computing, 2003) perform what we call “coarse-grained decoupling”: the operations being split between threads are procedure calls and the data passed between threads consists of arrays. An example is Ottoni et al.'s work where a special queue is needed to support access by a speculative, out-of-order processor.
The architectures of system on chip (SoC) platforms found in high end consumer devices are getting more and more complex as designers strive to deliver compute intensive applications on ever shrinking power budgets. Workloads running on these platforms require the exploitation of large amounts of heterogeneous parallelism and increasingly irregular memory hierarchies. The conventional approach to programming such hardware is very low level. The consequence of this is that when the core functionality of an application is mapped to the platform, its logic becomes obscured by the transformations and the glue code used during the mapping process. This yields software which is intimately and inseparably tied to the details of the platform it was originally designed for, limiting the software's portability and ultimately the architectural choices available to future generations of platform architects.
It would be desirable to provide a sequential program which could be automatically or at least semi-automatically transformed such that sections of it could be processed independently by different execution mechanisms, thereby improving performance. Many of the problems experienced in mapping applications onto SoC platforms come not from deciding how to map a program onto the hardware but from the fragmentation of the application that results from implementing these decisions. This is particularly so when the system itself decides how to parallelise the program as this becomes extremely complex and means that future analysis of the program by a programmer is very difficult. In particular, although sequential programs can be fairly readily understood by a human being, once they are parallelised it becomes increasingly difficult for the human mind to understand them. Thus, it would be desirable if some control could be provided as to where to divide such programs in order to generate a system that is more readily understandable by a human and yet can execute efficiently on a parallel system.
SUMMARY OF THE INVENTION
A first aspect of the present invention provides a method of transforming a portion of a computer program comprising a list of sequential instructions comprising control code and data processing code and a program separation indicator indicating a point where said sequential instructions may be divided to form separate sections that are capable of being separately executed and that each comprise different data processing code, said method comprising the steps of: (i) analysing said portion of said program to determine if said sequential instructions can be divided at said point indicated by said program separation indicator and in response to determining that it can: (iia) providing data communication between said separate sections indicated by said program separation indicator, such that said separate sections can be decoupled from each other, such that at least one of said sections is capable of being separately executed by an execution mechanism that is separate from an execution mechanism executing another of said separate sections, said at least one of said sections being capable of generating data and communicating said data to at least one other of said separate sections; and in response to determining it can not: (iib) not performing step (iia).
As noted above it would be desirable to be able to split a program having a list of instructions to be processed sequentially into sections that can be processed independently. The list of sequential instructions that is to be split comprises a single thread and does not provide parallel/concurrent operations. There may however, be branches or loops within this portion of the program. Thus, if the program is to be run on a system that can handle parallel execution of instructions, either by virtue of it having several execution mechanisms or a single processing device that can handle parallel execution, these sections could be split up to be executed separately.
The present method provides a tool for analysing a portion of the program to determine if the instructions can be divided at a point indicated by a separation indicator. These separation indicators are provided within at least a section of the program and indicate where it is desirable to divide the program. Thus, the division of the program is determined to some degree by these separation indicators and can thus, be controlled by a programmer. The method of the present invention forms an analysis of a program that actually includes the separation indicators and decides if the program can indeed be separated at these points. If it is decided that it can be it provides data communication between the two sections to allow them to be decoupled from each other. Thus, if appropriate the program can be split into sections suitable for separate execution allowing a program to be efficiently processed by a variety of different, often complex devices. If it decides it cannot be divided at this point then it does not perform the data communication step.
In some embodiments, if it decides it cannot be separated at a point indicated by a separation indicator then a warning indicating an error in the computer program is output. Providing the programmer with a warning may be the most appropriate thing to do if the separation indicators are not in the correct position.
In some embodiments, said step (iib) comprises amending said computer program such that said sequential instructions can be divided at said point and then performing step (iia).
Alternatively, to outputting a warning the method can amend the computer program so that the sequential instructions can be divided at this point and then the data communication can be divided between the different sections. It may be that it is a relatively simple matter to amend the computer program so that it can be divided at the point indicated and if this is the case then the method can perform this step rather than outputting a warning.
In some embodiments, said step of amending said computer program comprises inserting data transfer instructions at said point indicated by said program separation indicator.
The step required to amend the computer program may be one of inserting data transfer instructions at the point indicated by the program separation indicator.
In some embodiments, said step (iib) comprises merging said two sections together and removing said program separation indicator.
One way of dealing with discovering that two sections are not suitable for being executed on separate execution mechanisms is to simply remove the program separation indicator and merge the two sections together.
In some embodiments, said program separation indicator comprises at least one data transfer instruction, said data communication between said separate sections being provided in dependence upon said at least one data transfer instruction.
Although the program separation indicators can take a number of forms it is quite efficient if they take the form of data transfer instructions.
In order for sections to be able to execute separately there needs to be some sort of data communication and synchronisation in place between the two sections. Thus, providing program separation indictors in the form of data transfer instructions may facilitate their separation by providing the data communication required.
In some embodiments, said step (iia) of providing data communication comprises inserting at least one “put data into a data store” instruction and at least one “get data from said data store” instruction into said instruction stream, and dividing said computer program between said put and get instructions to form said at least one separate section.
The step of providing data communication can be done by inserting a put data into data store and a get data from said data store instructions into the instruction stream. This allows data to be removed from one section of the program and then input into the other section via a data store. Thus, the two sections are in effect decoupled from each other but data can travel between the two via this data store.
In some embodiments, said data store comprises a FIFO buffer.
Although, in some embodiments, the data store may comprise a FIFO buffer as this is clearly the simplest arrangement where the first data to exit from a section of the program is the first data to enter the next section, it may be that the data is not required in a particular order or indeed that all the data generated by one section is not required by the other. Thus, a variety of different data stores and different arrangements can be used in some embodiments. For example, a stack which has a last in first out semantics could be used, one advantage of this is that a stack is simple to implement.
In some embodiments, said step (iia) comprises providing cyclic data communication between said separate sections.
The decoupling of threads can be further extended to use where communication between threads is cyclic. Cyclic thread dependencies can lead to deadlock that is, two threads may not run in parallel because of data dependencies between them and thus, in devices of the prior art decoupling is limited to acyclic thread dependencies. Embodiments of the present invention address this problem and provide cyclic dependencies. This may be done, for example, by using put and get instructions and not requiring the number of puts to be equal to the number of gets. This is in contrast to the prior art where put and get operations are always inserted in corresponding places in each thread. Allowing put operations to be inserted in places that do not correspond to get operations in other threads, means that code such as is illustrated in FIG. 4 can be produced.
In some embodiments, said separate sections comprise the same control code.
In many embodiments, the control code is the same in the two sections as the computer program is divided such that different data processing steps are performed under the same control in each divided section. Duplicating control code in this way enables the program to be divided.
However, in some embodiments the control code will be different. This is because it may be advantageous occasionally to slightly modify the control code in one of the sections such that, for example, a conditional code that is no longer required is not present.
In some embodiments, said portion of said computer program comprises a plurality of program separation indicators each indicating a point where said sequential instructions may be divided to form separate sections, each of said separate sections being capable of being separately executed and comprising different data processing code, said method providing data communication between said separate sections indicated by said plurality of program separation indicators.
An instruction loop having several data processing steps for example can be divided by embodiments of the present invention into two sections by allowing the different sections to have different data processing codes. This can increase the performance of a system significantly. Generally this is done by duplicating the control code and in effect performing two loops, one performing one or more of the data processing steps of the original loop and the other performing the rest of the steps.
In some embodiments, said transformed computer program is suitable for execution upon respective execution mechanisms of a heterogeneous system having a complex asymmetric memory hierarchy and a plurality of execution mechanisms.
Embodiments of the present invention, although applicable to symmetric systems are particularly valuable in asymmetric heterogeneous systems wherein it is often difficult to separately execute sections of a program, particularly where at least a portion of the program is written sequentially.
Although, in some embodiments, a section of code is executed by a single execution mechanisms, in other embodiments said control code of at least one of said sections is operable to be processed by a processor of said heterogeneous system and said data processing code of said section is operable to be processed by an execution mechanism under control of said control code processed by said processor.
An execution mechanism may be a simple mechanism designed for a particular function, such as a memory transfer unit (colloquially known as a “DMA engine”) and in such cases it may be that the control code is performed on a separate processor, while the data processing operations are performed on the simpler mechanism.
It should be noted that the plurality of execution mechanisms can take a number of forms, including a general purpose processor; a direct memory access unit; a coprocessor; a VLIW processor; a digital signal processor; and a hardware accelerator unit.
In some embodiments, said method step comprises an initial step performed before step (i) of: defining said portion of said computer program by marking said computer program with indications delimiting said portion of said sequential instructions within which said at least two sections are to be located.
It is often easier to identify the potential to execute short sections of a program independently than to execute long sections independently. Thus, it may be appropriate to mark the portion of the program to be analysed. This marking may be done by a programmer or it may be done automatically.
In some embodiments, said computer program comprises said portion having a number of instructions to be executed sequentially and at least one further portion having instructions to be performed in parallel with each other.
A computer program may have different portions, some for execution sequentially and some already written for parallel processing. In such a case, it is the portion that has the instructions for sequential execution that is analysed to see if it can be divided into sections for separate execution. It should be noted that a portion to be analysed may be within a section that is to be executed in parallel. Furthermore, a portion to be analysed may also contain two or more sections that are to be executed in parallel.
In some embodiments, said portion of said computer program comprises an instruction loop comprising at least two data processing instructions, and said at least two sections each comprise said instruction loop each section comprising at least one of said at least two data processing instructions, said at least two sections comprising different data processing instructions.
An instruction loop having several data processing steps, can be divided into two sections, and thereby increase the performance of a system significantly. The present method is able to duplicate the control code and perform in effect two loops, one performing one or more of the data processing steps of the initial loop and the other performing the rest of the steps.
In some embodiments said portion of said computer program comprises a whole computer program.
A second aspect of the present invention provides a computer-readable storage medium comprising a computer program for controlling a computer to perform the method of the first aspect of the present invention.
A third aspect of the invention provides a computer executing a computer program to perform the method of a first aspect of the present invention.
A further aspect of the present invention provides a method of transforming a portion of a computer program comprising a list of sequential instructions and a program separation indicator indicating a point where said sequential instructions may be divided to form separate sections that are capable of being separately executed and that each comprise different data processing code, said list of instructions comprising control code and data processing code, said method comprising the step of:
(i) in response to said program separation indicator, providing data communication between said separate sections such that they can be decoupled from each other, such that at least one of said sections is capable of being separately executed by an execution mechanism that is separate from an execution mechanism executing another of said separate sections and said at least one of said sections can communicate data that it generates to at least one other of said separate sections via said provided data communication.
It is desirable to be able to split a program having a list of instructions to be processed sequentially into sections that can be processed independently. If the program comprises program separation indictors indicating points where they may be divided then the program can be transformed by providing data communication between the separate sections at the points indicated so that they can be decoupled from each other. This allows the program to be split into sections suitable for separate execution and allows the program to be efficiently processed by a variety of different often complex devices. This enables future analysis of the program via a programmer to be relatively straight forward and yet still enable it to execute efficiently on a parallel system.
In some embodiments, said method comprises a further initial step (0) performed before step (i) of in response to said program separation indicator, analysing said portion of said computer program and determining which of said sequential instructions should be in which of said separate sections prior to providing said data communication.
An additional step of analysing the program to ensure that it can indeed be separated at these points can be helpful and allows programs that have program separation indicators in them that are potentially in an incorrect place to still be transformed.
The above, and other objects, features and advantages of this invention will be apparent from the following detailed description of illustrative embodiments which is to be read in connection with the accompanying drawings.
BRIEF DESCRIPTION OF THE DRAWINGS
FIGS. 1a to 1c show flow diagrams of methods according to embodiments of the present invention;
FIG. 2a to 2d schematically shows the splitting into separately executable sections of a computer program according to an embodiment of the present invention;
FIG. 3a to 3b schematically shows a method of splitting and then merging sections of a computer program;
FIG. 4 schematically shows data communication between two sections of a program;
FIG. 5a shows a simple computer program annotated according to an embodiment of the present invention;
FIG. 5b shows the maximal set of threads for the program of FIG. 4a.
FIG. 6 schematically illustrates an asymmetric multiprocessing apparatus with an asymmetric memory hierarchy;
FIG. 7 illustrates an architectural description;
FIG. 8 illustrates a communication requirement; and
FIG. 9 illustrates communication support.
DESCRIPTION OF THE PREFERRED EMBODIMENTS
FIG. 1a shows a flow diagram illustrating a method according to an embodiment of the present invention. A first step is performed in which a portion of a computer program comprising a list of sequential instructions and a program separation indicator indicating a point where the sequential instructions may be divided to form separate sections that are capable of being separately executed is analysed. The analysis determines if the sequential instructions can be split at the point indicated by the separation indicator into separate sections that can be processed on different execution mechanisms. If it determines it can the sequential instructions are divided into the separate sections at the point indicated by the program separation indicator. If it determines they cannot be separated at this point then a warning is output to the programmer to indicate an error in the program.
FIG. 1b illustrates an alternative embodiment in which rather than outputting a warning if the program cannot be decoupled and separated at the indicated point, the program is amended by inserting data communication instructions into the list of sequential instructions, these data communication instructions enabling the different sections to be decoupled and thus, separated. The separation can then be performed.
FIG. 1c provides an alternative embodiment in which in response to determining that the program cannot be separated at the indicated point the two sections are merged together and the program separation indicator removed.
As can be seen the three embodiments provide different solutions to an analysis that determines that it is not possible to separate a program into sections at the point indicated. Different ones of these embodiments may be used in the same analysis of a program for different separation indicators depending on circumstances. Thus, it may be that the preferred course of action is to amend the program to make it separable at he indicated point, if this cannot be done then it may be chosen to merge the two portions, or if this would result in an unacceptably large portion then a warning may be output.
FIG. 2a shows a portion of a computer program comprising a loop in which data items are processed, function f operating on the data items, and function g operating on the data items output by function f and then function h operating on these items. These functions being performed n times in a row for values of i from 1 to n.
Thus, the control flow can be seen as following the solid arrows while data flow follows the dotted arrows. In order to try to parallelise this portion of the computer program it is analysed, either automatically or by a programmer and “decouple” or program separation indications are inserted into the data flow where it is seen as being desirable to split the portion into sections that are decoupled from each other and can thus, be executed on separate execution mechanisms. In this case, a decouple indication is provided between the data processing operations f and g. This can be seen as being equivalent to inserting a buffer in the data flow, as the two sections are decoupled by providing a data store between then so that the function f can produce its results which can then be accessed at a different time by function g.
The program is then analysed to see if it can indeed be decoupled at the point indicated by the separation indicators. If it can then the method proceeds to FIG. 2c. If it cannot then a warning may be output to the programmer, the program may be amended to enable it to be decoupled at this point, or the decouple indication may be removed from the program and the two sections merged.
FIG. 2c, shows how the separate sections of the program are decoupled by the insertion of “put” and “get” instructions into the data stream. These result in the data being generated by the f function being put into a data store, from which it is retrieved by the get instruction to be processed by function g. This enables the program to be split into two sections as is shown in FIG. 2d. One section performs function f on the data for i=1 to n and puts it into a buffer data store. The other section then retrieves this data and performs functions g and h on it. Thus, by the provision of a data store the two sections of the program are in effect decoupled from each other and can be executed on separate executions mechanisms. This decoupling by the use of a specialised buffer and extra instructions to write and read data to it, are only required for systems having heterogeneous memory, whereby two execution mechanisms may not be able to access the same memory. If the memory is shared, then the data path between the two sections does not need a data copy but can simply be provided with a data store identifier.
Thus, if the program is being processed by a data processing apparatus having a number of different processors, the two sections can be processed in parallel which can improve the performance of the apparatus. Alternatively, one of the functions may be a function suitable for processing by an accelerator in which case it can be directed to an accelerator, while the other portion is processed by say, the CPU of the apparatus.
As can be seen from FIG. 2d, the splitting of the program results in the control code of the program being duplicated in both section, while the data processing code is different in each section.
It should be noted that the put and get operations used in FIG. 2c can be used in programs both for scalar and non-scalar values but they are inefficient for large (non-scalar) values as they require a memory copy. In operating systems, it is conventional to use “zero copy” interfaces for bulk data transfer: instead of generating data into one buffer and then copying the data to the final destination, the final destination is first determined and the data directly generated into the final destination. A different embodiment of the invention applies this idea to the channel interface, by replacing the simple ‘put’ operation with two functions: put_begin obtains the address of the next free buffer in the channel and put end makes this buffer available to readers of the channel:
void* put_begin(channel *ch);
void put_end(channel *ch, void* buf);
Similarly, the get operation is split into a get_begin and get_end pair
void* get_begin(channel *ch);
void get_end(channel *ch, void* buf);
Using these operations, sequences of code such as:
int x[100];
generate(x);
put(ch,x);
Can be rewritten to this more efficient sequence:
int px=put_begin(ch);
generate(px);
put_end(ch,px);
And similarly, for get:
int x[100];
get(ch,x);
consume(x);
to this more efficient sequence:
int px=get_begin(ch);
consume(px);
get_end(ch,px);
The use of puts and gets to decouple threads can be further extended to use where communication between threads is cyclic. Cyclic thread dependencies can lead to deadlock—that is, two threads may not run in parallel because of data dependencies between them and thus, in devices of the prior art decoupling is generally limited to acyclic thread dependencies.
-
- 1. A particularly common case of cyclic thread dependencies is code such as
| y = 1; | |
| while(1) { | |
| x = f(y); | |
| y = g(x); | |
| } | |
Under conventional decoupling schemes, puts are always inserted after assignment to any data boundary variable. This would require both a put outside the loop and a put at the end of the loop:
| y1 = 1; | |
| put(ch,y1); | |
| while(1) { | |
| y2 = get(ch); | |
| x = f(y2); | |
| y3 = g(x); | |
| put(ch,y3); | |
| } | |
Conventional decoupling schemes only generate matched pairs of puts and gets (i.e., there is only one put on each channel and only one get on each channel) so they cannot generate such code.
Embodiments of the present invention use an alternative way of decoupling this code and generate:
| y1 = 1; | |
| while(1) { | |
| put(ch,y1); | |
| y2 = get(ch); | |
| x = f(y2); | |
| y1 = g(x); | |
| } | |
This does have matched pairs of puts and gets but breaks the rule of always performing a put after any assignment to a variable.
FIGS. 3a and 3b schematically illustrate the program code shown in FIG. 2. In this Figure a data store is provided to decouple functions f and g, but one is not provided between g and h. In this embodiment analysis of the program to decouple it is performed automatically and several potential sections are provided, in this case these are loops having functions f, g and h in them. The automatic analysis then checks that each loop can be executed separately and in this case identifies a missing data path between functions g and h. Thus, these two functions are remerged to provide two sections with a data path between.
A further example of a code fragment that can be split by an embodiment of the present invention is provided below. Since communication lies at the boundaries between threads, the compiler's job is to “color in” the code that lies between the boundaries. This is done through a dependency analysis to decide the set of operations that are on the “producer” side of a channel and the set of operations on the “consumer” side of a channel. The compiler then partitions the operations according to that analysis; and generates a separate thread for each equivalence class.
| 1 PIPELINE{ | |
| 2 for(int i=0; i<100; ++i) { | |
| 3 int x = f(); | |
| 4 if (i % 10 != 0) { | |
| 5 FIFO(2,x); | |
| 6 g(x); | |
| 7 } | |
| 8 } | |
| 9 } | |
The PIPELINE annotation on line 1 identifies the region of code to be split into threads. The FIFO annotation on line 5 identifies that the communication between threads is to be performed between f and g. The compiler performs a data and control flow analysis to determine that the call to g has a data dependency on the FIFO operation and also has control dependencies on the if statement (line 4) and the for loop (line 2). This results in the following thread:
| 2 for(int i=0; i<100; ++i) { | |
| 3 if (i % 10 != 0) { | |
| 5 int x = fifo_get(fifo); | |
| 6 g(x); | |
| 7 } | |
| 8 } | |
Note that the dependency on the FIFO operation caused the compiler to insert a fifo get operation.
The data and control flow analysis also determines that the FIFO operation (line 5) has a data dependency on the call to f (line 3) and also has control dependencies on the if statement (line 4) and the for loop (line 2). This results in the following thread:
| 2 for(int i=0; i<100; ++i) { | |
| 3 int x = f( ); | |
| 4 if (i % 10 != 0) { | |
| 5 fifo_put(fifo,x); | |
| 7 } | |
| 8 } | |
Note that because the data dependency is from the FIFO operation, the compiler inserted a fifo_put operation.
Because decoupling respects data and control dependencies and FIFO channels preserve the order of their elements, the resulting threads are equivalent to the unannotated code. (Obviously, this property is not preserved when timed channels are used.)
Decoupling must make two essential decisions: “What variables and operations to replicate?” and “What operations to place in the same thread?”.
The task of decoupling is to split the region of code into as many threads as possible, without introducing timing-dependent behaviour, using channels to communicate between threads. As the example above shows, the generated threads do not strictly partition the statements in the original code: some variables and operations (principally those used for control) are duplicated between threads. The choice of what to duplicate is an essential part of the transformation: if too much code or data is duplicated, the transformed program can run slower and use much more memory than the original program. While these decisions could be controlled using annotations on every variable and statement, some simple default rules can be used that give the programmer control without requiring excessive annotation. By default, the variables to be duplicated (i.e., privatized) are determined by the location of their declaration (variables declared inside the PIPELINE annotation may be duplicated) and their size (scalar variables may be duplicated). Operations other than function calls may be duplicated unless they have side-effects or modify a non-duplicable variable.
The other essential decision that the transformation must make is “What operations must be in the same thread as each other?”. To avoid introducing timing-dependent behaviour, we apply the following two rules:
-
- 1. To preserve data and control dependencies, any dependent operations must be in the same thread as each other unless the dependency is from an operation to a FIFO operation. This special treatment of dependencies on FIFO operations has the effect of cutting edges in the dataflow graph. Note that dependencies include both direct data dependencies due to function inputs and outputs and indirect dependencies due to side-effects.
- 2. To avoid introducing race conditions, any operations which write to an unduplicated non-channel variable must be in the same thread as all operations which read from or write to that variable. Channels are excluded because all channel operations atomically modify the channel.
- 3. To avoid introducing non-determinism, all puts to a given channel must be in the same thread as each other and all gets from a given channel must be in the same thread as each other.
Our implementation of decoupling finds the unique, maximal solution in three stages: dependency analysis, merging, and thread production.
The dependency analysis stage forms a large number of “pre-threads” by computing a backward data and control slice (see Mark Weiser, “Program slicing”, in ICSE '81: Proc. of International Conference on Software Engineering, 439-449, 1981) from each unduplicated operation ignoring data dependencies on FIFO operations but including all duplicable and unduplicable operations in the slice. That is, we repeatedly apply rules (1) and (2) to form prethreads. In our running example, there are three prethreads: one each for f( ), FIFO(2,x), and g(x).
For example, the prethread for f( ) is:
| 1 PIPELINE{ | |
| 2 for(int i=0; i<100; ++i) { | |
| 3 int x = f( ); | |
| 8 } | |
| 9 } | |
the prethread for FIFO(2,x) is:
| 1 PIPELINE{ | |
| 2 for(int i=0; i<100; ++i) { | |
| 3 int x = f( ); | |
| 4 if (i % 10 != 0) { | |
| 5 FIFO(x,2); | |
| 7 } | |
| 8 } | |
| 9 } | |
and the prethread for g(x) is:
| 1 PIPELINE{ | |
| 2 for(int i=0; i<100; ++i) { | |
| 3 int x; | |
| 4 if (i % 10 != 0) { | |
| 6 g(x); | |
| 7 } | |
| 8 } | |
| 9 } | |
Note that the prethread for g(x) omits the FIFO operation (line 5): the dependency rules ensure that FIFO operations are placed in the producer thread but not the consumer thread.
The merging stage combines “prethreads” by merging threads that contain the same non-duplicable operation or variable. For example, the prethread for f( ) is merged with the prethread for FIFO(2,x) because they both contain the operation f( ), resulting in the prethread:
| 1 PIPELINE{ | |
| 2 for(int i=0; i<100; ++i) { | |
| 3 int x = f( ); | |
| 4 if (i % 10 != 0) { | |
| 5 FIFO(x,2); | |
| 7 } | |
| 8 } | |
| 9 } | |
This is identical to the prethread for FIFO(2,x) because the prethread already contained the f(x) operation.
The thread production stage converts prethreads to threads by inserting channel declarations and initialization, privatizing duplicable variables, replacing FIFO operations with fifo_put operations and inserting a fifo_get operation in every thread that contains an operation dependent on a FIFO operation. If multiple threads contain operations dependent on the same FIFO operation, a separate channel has to be introduced for each fifo_get operation introduced and the FIFO operation is replaced with a fifo_put operation on each channel.
When adding FIFO annotations, it is easy for the programmer to overlook dependencies between operations. For example, if the if-statement were changed to x>0, then the control dependency of g(x) on the if-statement and the data dependency of the condition x>0 requires the prethread for x=f( ) to be merged with the prethread for g(x) and no pipeline parallelism is introduced. Since the use of FIFO suggests that the programmer expected parallelism, the compiler reports a warning that both sides of the channel are in the same thread. In this case, the problem can be fixed by moving the FIFO operation to before the if-statement or by arranging to pass the if-condition through a channel by changing the if-statement to if (FIFO(2,x>0)) { . . . }.
Decoupling can be used with all channel types except non-blocking FIFOs.
When optimizing inter-thread communication and introducing pipeline parallelism, our compiler needs to perform dataflow analysis on both scalar and non-scalar variables. When a function is written in C, it is often possible to perform this analysis automatically using, for example, the techniques of Tu et al. (P. Tu and D. Padua, “Automatic Array Privatization”, in Proc. Workshop on Compiler Optimizations for Scalable Parallel Systems Languages (LNCS 768), Springer Verlag, 500-521, 1993) to compute DEF, USE and KILL sets. In typical SoC architectures, this analysis is not possible because the PE is programmed in assembly language or is a fixed-function accelerator, so the programmer must annotate the function declarations for RPC functions with whether an argument is an “in”, “out” or “inout” argument. Similarly, side-effects on global variables or on device state are annotated by recording dependencies on those variables/devices.
FIG. 4 shows a further example of how an original piece of code can be split into two threads to be executed in parallel using of put and get instructions.
Parallelizing at a coarse granularity allows the duplication of more control code between threads which reduces and simplifies inter-thread communication allowing the generation of distributed schedules. That is, we can distribute the control code across multiple processors both by putting each control thread on a different processor and by putting different parts of a single control thread onto different processors.
The transfer of data may be done by, writing the data to a particular buffer such as a FIFO. Alternatively it may simply be done by providing the other section of the program with information as to where the data has been stored.
The way of transferring the data depends on the system the program is executing on. In particular, if the architecture does not have shared memory, it is necessary to insert DMA copies from a buffer in one memory to a buffer in a different memory. This can lead to a lot of changes in the code: declaring both buffers, performing the copy, etc. In embodiments of the invention an analysis is performed to determine which buffers need to be replicated in multiple memory regions and to determine exactly which form of copy should be used. DMA copies are also inserted automatically subject to some heuristics when the benefit from having the programmer make the decision themselves is too small.
One of the advantages of inserting channel indicators into a program explicitly is that it is possible to use channels which do not provide first-in-first-out semantics. This section describes some alternative implementations which can be used.
Atomic channels provide atomic access to an element: an atomic_get operation acquires a copy of the element and makes the element unavailable to other threads (i.e., it “locks” the variable) and an atomic_put operation makes the variable available for use by other threads (i.e., it “unlocks” the variable). We note that atomic channels are equivalent to a fifo channel of maximum length 1.
Nonblocking put and get channels are a variant on fifo channels where the nbpfifo_put operation returns an error code if the channel is full instead of blocking as fifo channels do. These channels are for use in interrupt handlers since it is possible to block a thread but not an interrupt. We also provide channels that provide a non-blocking nbgfifo_get operation.
Timed channels provide time-indexed access to data. When data is inserted into or removed from the channel, a timestamp is specified:
void ts_put(tschan_t c, int timestamp, void* v);
void ts_get(tschan_t c, int timestamp, void* v);
The ts_get operation returns the entry with the closest timestamp to that specified. All ts_put operations must use strictly increasing times and all ts_get operations must use strictly increasing times. This restriction allows entries to be discarded when they can no longer be accessed.
Timed channels allow for more parallelism between threads since, after the first ts_put is performed, ts_get operations never block because there is always an entry with a closest timestamp. The cost of this increased performance is less precise synchronization between threads than with FIFO channels: applications that use timed channels are unlikely to give deterministic results.
Timed channels are useful for implementing time-sensitive information where it is important to use current data. For example, mobile telephones implementing the “3rd generation” W-CDMA protocol use rake receivers to increase the bandwidth of links subject to multipath fading (i.e., where the signal contains delayed echoes of the transmitted signal typically due to reflections off buildings). Rake receivers estimate the strength and delay of these reflections and use these estimates to combine delayed copies of the received signal to maximize the amount of received signal energy. In such applications, the best estimate to use is the one closest in time to the data arrived which may be different from the next estimate generated.
Timed channels are an example of a channel type which makes sense in some domains or applications but not in others. Rather than fix the set of channel types in the language, our compiler allows new channel types to be added using annotations to identify channel types and put and get operations. The only properties on which SoC-C relies are that operations are atomic, directional and obey a copy semantics. That is, put operations atomically copy data into a channel and get operations atomically copy data out of a channel.
Most alternative channel types of interest have the effect of making the application non-deterministic: the behaviour of the application depends on the precise order in which parallel operations complete. For this reason, we require the programmer to explicitly decide which type of queue to use.
FIG. 5a shows a simple computer program annotated according to an embodiment of the present invention. An analysis of this program is performed initially and parts of the program are identified by programmer annotation in this embodiment although it could be identified by some other analysis including static analysis, profile driven feedback, etc. The parts identified are as follows:
What can be regarded as the “decoupling scope”. This is a contiguous sequence of code that we wish to split into multiple threads.
The “replicatable objects”: that is variables and operations which it is acceptable to replicate. A simple rule of thumb is that scalar variables (i.e., not arrays) which are not used outside the scope, scalar operations which only depend on and only modify replicatable variables, and control flow operations should be replicated but more sophisticated policies are possible.
Ordering dependencies between different operations: if two function calls both modify a non-replicated variable, the order of those two function calls is preserved in the decoupled code. (Extensions to the basic algorithm allow this requirement to be relaxed in various ways.)
The “data boundaries” between threads: that is, the non-replicatable variables which will become FIFO channels. (The “copies” data annotation described above determines the number of entries in the FIFO.)
This degree of annotation is fine for examples but would be excessive in practice so most real embodiments would rely on tools to add the annotations automatically based on heuristics and/or analyses.
At a high level, the algorithm splits the operations in the scope into a number of threads whose execution will produce the same result as the original program under any scheduling policy that respects the FIFO access ordering of the channels used to communicate between threads.
The particular decoupling algorithm used generates a maximal set of threads such that the following properties hold:
-
- All threads have the same control flow structure and may have copies of the replicatable variables and operations.
- Each non-replicatable operation is included in only one of the threads.
- Each non-replicatable variable must satisfy one of the following:
- The only accesses to the variable in the original program are reads; or
- All reads and writes to the variable are in a single thread; or
- The variable was marked as a data boundary and all reads are in one thread and all writes are in another thread.
- If two operations have an ordering dependency between them which is not due to a read after write (RAW) dependency on a variable which has been marked as a data boundary, then the operations must be in the same thread.
FIG. 5b shows the maximal set of threads for the program of FIG. 5a. One way to generate the set of threads shown in FIG. 5b is as follows:
-
- 1. For each non-replicatable operation, create a ‘protothread’ consisting of just that operation plus a copy of all the replicatable operations and variables.
Each replicatable variable must be initialized at the start of each thread with the value of the original variable before entering the scope and one of the copies of each replicatable variable should be copied back into the master copy on leaving the scope. (Executing all these protothreads is highly unlikely to give the same answer as the original program, because it lacks the necessary synchronization between threads. This is fixed by the next steps.)
-
- 2. Repeatedly pick two threads and merge them into a single thread if any of the following problems exist:
- a. One thread writes a non-replicatable variable which is accessed (read or written) by the other thread and the variable is not marked as a data boundary.
- b. Two threads both write to a variable which is marked as a data boundary.
- c. Two threads both read from a variable that is marked as a data boundary.
- d. There is an ordering dependency between an operation in one thread and an operation in the other thread which is not a RAW dependency on a variable marked as a data boundary.
- 3. When no more threads can be merged, quit
- 2. Repeatedly pick two threads and merge them into a single thread if any of the following problems exist:
Another way is to pick an operation, identify all the operations which must be in the same thread as that operation by repeatedly adding operations which would be merged (in step 2 above). Then pick the next operation not yet assigned to a thread and add all operations which must be in the same thread as that operation. Repeat until there are no more non-replicatable operations. It should be noted that this is just one possible way of tackling this problem: basically, we are forming equivalence classes based on a partial order and there are many other known ways to do this.
The above method splits a program into a number of sections which can be executed in parallel. There are many possible mechanisms that can be used to accomplish this task.
Execution mechanism.
FIG. 6 shows a flow diagram of a method according to an embodiment of the present invention. An initial step of the method comprises analysing the computer program that contains sequential code and program separation indicators. For each program separation indicator the program is analysed to determine how it can be divided into separate sections around this separation indicator. First of all it is checked that it is reasonable to divide it there. If it can be divided at this point then data communication between the two sections is provided and this may be done in a number of ways including the insertion of put and get instructions as was discussed earlier and then the program is analysed to determine if there are further program separation indicators. If there is then the program at this point is analysed to determine if it can be divided. If it cannot in its present state then it is checked to determine if it requires further data transfer instructions to divide it. If it does then these are inserted and data communication in line with these data transfer instructions can then be provided between the two sections. If it is determined that it cannot be divided at this point then the two potential sections can be merged and the program separation indicator removed from the list. In some embodiments, rather than merging the two potential sections a warning is output to indicate that the program is not correct and then programmer can then amend it.
Program separation indicators can take a number of forms. They may simply be some sort of indicator such as a split indicating that the program needs to be divided there or they can in fact be data transfer functions which do by themselves provide a data communication between the two sections. Thus, they may be fifo instructions indicating that data should be sent fifo to transfer the data between the two sections as was discussed earlier or they may be put and get instructions. It may be that several variables need to be transferred between the two sections and that there are not sufficient data transfer instructions within the program. In such a case then the further data transfer instructions for these variables which have not been addressed can be inserted into the program and then the data communication between the two sections is provided and can then be separated before separate execution on separate execution mechanisms.
1. Introduction
The following describes language extensions/annotations, compilation tools, analysis tools, debug/profiling tools, runtime libraries and visualization tools to help programmers program complex multiprocessor systems. It is primarily aimed at programming complex SoCs which contain heterogeneous parallelism (CPUs, DEs, DSPs, programmable accelerators, fixed-function accelerators and DMA engines) and irregular memory hierarchies.
The compilation tools can take a program that is either sequential or contains few threads and map it onto the available hardware, introducing parallelism in the process.
When the program is executed, we can exploit the fact that we know mappings between the user's program and what is executing to efficiently present a debug and profile experience close to what the programmer expects while still giving the benefit of using the parallel hardware. We can also exploit the high level view of the overall system to test the system more thoroughly, or to abstract away details that do not matter for some views of the system.
This provides a way of providing a full view for SoC programming.
2. Single View Compilation
2.1 Overview
The task of programming a SoC is to map different parts of an application onto different parts of the hardware. In particular, blocks of code must be mapped onto processors, data engines, accelerators, etc. and data must be mapped onto various memories. In a heterogeneous system, we may need to write several versions of each kernel (each optimized for a different processor) and some blocks of code may be implemented by a fixed-function accelerator with the same semantics as the code. The mapping process is both tedious and error-prone because the mappings must be consistent with each other and with the capabilities of the hardware. We reduce these problems using program analysis which:
-
- detect errors in the mapping
- infer what mappings would be legal
- choose legal mappings automatically subject to some heuristics
The number of legal mappings is usually large but once the programmer has made a few choices, the number of legal options usually drops significantly so it is feasible to ask the programmer to make a few key choices and then have the tool fill in the less obvious choices automatically.
Often the code needs minor changes to allow some mappings. In particular, if the architecture does not have shared memory, it is necessary to insert DMA copies from a buffer in one memory to a buffer in a different memory buffer. This leads to a lot of changes in the code: declaring both buffers, performing the copy, etc. Our compiler performs an analysis to determine which buffers need to be replicated in multiple memory regions and to determine exactly which form of copy should be used. It also inserts DMA copies automatically subject to some heuristics when the benefit from having the programmer make the decision themselves is too small.
Systems with multiple local memories often have tight memory requirements which are exacerbated by allocating a copy of a buffer in multiple memories. Our compiler uses lifetime analysis and heuristics to reduce the memory requirement by overlapping buffers in a single memory when they are never simultaneously live.
Programmable accelerators may have limited program memory so it is desirable to upload new code while old code is running. For correctness, we must guarantee that the new code is uploaded (and I-caches made consistent) before we start running it.
Our compiler uses program analysis to check this and/or to schedule uploading of code at appropriate places.
For applications with highly variable load, it is desirable to have multiple mappings of an application and to switch dynamically between different mappings.
Some features of our approach are:
-
- Using an architecture description to derive the ‘rules’ for what code can execute where. In particular, we use the type of each processor and the memories attached to each processor.
- The use of program analysis together with the architecture description to detect inconsistent mappings.
- Using our ability to detect inconsistent mappings to narrow down the list of consistent mappings to reduce the number of (redundant) decisions that the programmer has to make.
- Selecting an appropriate copy of a buffer according to which processor is using it and inserting appropriate DMA copy operations.
- Use of lifetime analyses and heuristics to reduce memory usage due to having multiple copies of a buffer.
- Dynamic switching of mappings.
2.2 Annotations to Specify Mappings
To describe this idea further, we need some syntax for annotations. Here we provide one embodiment of annotations which provide the semantics we want.
In this document, all annotations take the form:
-
- . . . @ {tag1=>value1, . . . tagm=>value}
Or, when there is just one tag and it is obvious,
-
- . . . @ value
The primary annotations are on data and on code. If a tag is repeated, it indicates alternative mappings.
The tags associated with data include:
-
- {memory=>“bank3”} specifies which region of memory a variable is declared in.
- {copies=>2} specifies that a variable is double buffered
- {processor=>“P1”} specifies that a variable is in a region of memory accessible by processor P1.
For example, the annotation:
-
- int x[100] @ {memory=>“bank3”, copies=>2, memory=>“bank4”, copies=>1} indicates that there are 3 alternative mappings of the array x: two in memory bank3 and one in memory bank4.
The tags associated with code include:
-
- {processor=>“P1”} specifies which processor the code is to run on
- {priority=>5} specifies the priority with which that code should run relative to other code running on the same processor
- {atomic=>true} specifies that the code is to run without pre-emption.
- {runtime=>“<=10 ms”} specifies that the code must be able to run in less than 10 milliseconds on that processor. This is one method used to guide automatic system mapping.
For example, the annotation:
-
- {fir(x); fft(x,y);} @ {processor=>“P1”}
Specifies that processor P1 is to execute fft followed by P1. The semantics is similar to that of a synchronous remote procedure call: when control reaches this code, free variables are marshalled and sent to processor P1, processor P1 starts executing the code and the program continues when the code finishes executing.
It is not always desirable to have synchronous RPC behaviour. It is possible to implement asynchronous RPCs using this primitive either by executing mapped code in a separate thread or by splitting each call into two parts: one which signals the start and one which signals completion.
The tags associated with functions are:
-
- {cpu=>“AR1DE”} specifies that this version of an algorithm can be run on a processor/accelerator of type “AR1 DE”
- {flags=>“-O3”} specifies compiler options that should be used when compiling this function
- {implements=>“fir”} specifies that this version of an algorithm can be used as a drop in replacement for another function in the system
For example, the annotation:
-
- Void copy_DMA(void* src, void* tgt, unsigned length) @ {cpu=>“PL081”, implements=>“copy”};
Specifies that this function runs on a PL081 accelerator (a DMA Primesys engine) and can be used whenever a call to “copy” is mapped to a PL081 accelerator.
2.3 Extracting Architectural Rules from the Architectural Description
There are a variety of languages for describing hardware architectures including the SPIRIT language and ARM SoCDesigner's internal language. While the languages differ in syntax, they share the property that we can extract information such as the following:
-
- The address mapping of each processor. That is, which elements of each memory region and which peripheral device registers are accessed at each address in the address and I/O space. A special case of this is being able to detect that a component cannot address a particular memory region at all.
- The type of each component including any particular attributes such as cache size or type.
- That a processor's load-store unit, a bus, a combination of buses in parallel with each other, a memory controller or the address mapping makes it possible for accesses to two addresses that map to the same component or to different components from one processor to be seen in a different order by another processor. That is, the processors are not sequentially consistent with respect to some memory accesses.
- That a combination of load-store units, caches, buffers in buses, memory controllers, etc. makes it possible for writes by one processor to the same memory location to suffer from coherency problems wrt another processor for certain address ranges.
Thus, from the architecture, we can detect both address maps which can be used to fill in fine details of the mapping process and we can detect problems such as connectivity, sequential consistency and incoherence that can affect the correctness of a mapping.
2.4 Detecting Errors in a System Mapping
Based on rules detected in an architectural description and/or rules from other sources, we can analyse both sequential and parallel programs to detect errors in the mapping. Some examples:
-
- If a piece of code is mapped to a processor P and that code reads or writes data mapped to a memory M and P cannot access M, then there is an error in the mapping.
- If two pieces of code mapped to processors P1 and P2 both access the same variable x (e.g. P1 writes to x and P2 reads from x), then any write by P1 that can be observed by a read by P2 must:
- have some synchronization between P1 and P2
- be coherent (e.g., there may need to be a cache flush by P1 before the synchronization and a cache invalidate by P2 after the synchronization)
- be sequentially consistent (e.g., there may need to be a memory barrier by P1 before the synchronization and a memory barrier by P2 after the synchronization)
- share memory (e.g., it may be necessary to insert one or more copy operations (by DMA engines or by other processors/accelerators) to transfer the data from one copy of x to the other.
- Synchronization and signalling can be checked
- Timing and bandwidth can be checked
- Processor capability can be checked: a DMA engine probably cannot play Pacman
- Processor speed can be checked: a processor may not be fast enough to meet certain deadlines.
- Etc.
Thus, we can check the mapping of a software system against the hardware system it is to run on based on a specification of the architecture or additional information obtained in different ways.
2.5 Filling in Details and Correcting Errors in a System Mapping
Having detected errors in a system mapping, there are a variety of responses. An error such as mapping a piece of code to a fixed-function accelerator that does not support that function should probably just be reported as an error that the programmer must fix. Errors such as omitting synchronization can sometimes be fixed by automatically inserting synchronization. Errors such as requiring more variables to a memory bank than will fit can be solved, to some extent, using overlay techniques. Errors such as mapping an overly large variable to a memory can be resolved using software managed paging though this may need hardware support or require that the kernel be compiled with software paging turned on (note: software paging is fairly unusual so we have to implement it before we can turn it on!). Errors such as omitting memory barriers, cache flush/invalidate operations or DMA transfers can always be fixed automatically though it can require heuristics to insert them efficiently and, in some cases, it is more appropriate to request that the programmer fix the problem themselves.
3. Architecture Driven Communication
3.1 Overview
Given a program that has been mapped to the hardware, the precise way that the code is compiled depends on details of the hardware architecture. In particular, it depends on whether two communicating processors have a coherent and sequentially consistent view of a memory through which they are passing data.
3.2 Communication Glue Code
Our compiler uses information about the SoC architecture, extracted from the architecture description, to determine how to implement the communication requirements specified within the program. This enables it to generate the glue code necessary for communication to occur efficiently and correctly. This can include generation of memory barriers, cache maintenance operations, DMA transfers and synchronisation on different processing elements.
This automation reduces programming complexity, increases reliability and flexibility, and provides a useful mechanism for extended debugging options.
3.3 Communication Error Checking
Other manual and automatic factors may be used to influence the communication mechanism decisions. Errors and warnings within communication mappings can be found using information derived from the architecture description.
3.4 Summary
Some features of our approach are:
-
- Detecting coherence and consistency problems of communication requirements from a hardware description.
- Automatically inserting memory barriers, cache maintenance, DMA transfers etc. to fix coherence/consistency problems into remote procedure call stubs (i.e., the “glue code”) based on above.
4. Accelerator RPC
We take the concept of Remote Procedure Calls (RPCs) which are familiar on fully programmable processors communicating over a network, and adapt and develop it for application in the context of a SoC: processors communicating over a bus with fixed function, programmable accelerators and data engines.
Expressing execution of code on other processing elements or invocation of accelerators as RPCs gives a function based model for programmers, separating the function from the execution mechanism. This enables greater flexibility and scope for automation and optimisation.
4.1 RPC Abstraction
An RPC abstraction can be expressed as functions mapped to particular execution mechanisms:
| main( ) { | |
| foo( ); | |
| foo( ) @ {processor => p2}; | |
| } | |
This provides a simple mechanism to express invocation of functions, and the associated resourcing, communication and synchronisation requirements.
Code can be translated to target the selected processing elements, providing the associated synchronisation and communication. For example, this could include checking the resource is free, configuring it, starting it and copying the results on completion. The compiler can select appropriate glue mechanisms based on the source and target of the function call. For example, an accelerator is likely to be invoked primarily by glue on a processor using a mechanism specific to the accelerator.
The glue code may be generated automatically based on a high level description of the accelerator or the programmer may write one or more pieces of glue by hand.
The choice of processor on which the operation runs can be determined statically or can be determined dynamically. For example, if there are two identical DMA engines, one might indicate that the operation can be mapped onto either engine depending on which is available first.
The compiler optimisations based on the desired RPC interface can range from a dynamically linked interface to inter-procedural specialisation of the particular RPC interface.
4.2 RPC Semantics
RPC calls may be synchronous or asynchronous. Asynchronous calls naturally introduce parallelism, while synchronous calls are useful as a simpler function call model, and may be used in conjunction with fork-join parallelism. In fact, parallelism is not necessary for efficiency; a synchronous call alone can get the majority of the gain when targeting accelerators. Manually and automatically selecting between asynchronous and synchronous options can benefit debugging, tracing and optimisation.
RPC calls may be re-entrant or non-reentrant, and these decisions can be made implicitly, explicitly or through program analysis to provide benefit such as optimisation where appropriate.
4.3 RPC Debugging
This mechanism enables a particular function to have a number of different execution targets within a program, but each of those targets can be associated back to the original function; debugging and trace can exploit this information. This enables a user to set a breakpoint on a particular function, and the debug and trace mechanisms be arranged such that it can be caught wherever it executes, or on a restricted subset (e.g. a particular processing element).
The details of the RPC interface implementation can be abstracted away in some debugging views.
4.4 Summary
Some features of our approach are:
-
- Using an RPC-like approach for mapping functions on to programmable and fixed function accelerators, including multiple variants.
- Providing mechanisms for directing mapping and generation of the marshalling and synchronisation to achieve it.
- Optimising the RPC code based on inter-procedural and program analysis.
- Providing debug functionality based on information from the RPC abstraction and the final function implementations.
5. Coarse Grained Dataflow
5.1 Overview
Increasingly, applications are being built using libraries which define datatypes and a set of operations on those types. The datatypes are often bulk datastructures such as arrays of data, multimedia data, signal processing data, network packets, etc. and the operations may be executed with some degree of parallelism on a coprocessor, DSP processor, accelerator, etc. It is therefore possible to view programs as a series of often quite coarse-grained operations applied to quite large data structures instead of the conventional view of a program as a sequence of ‘scalar’ operations (like ‘32 bit add’) applied to ‘scalar’ values like 32-bit integers or the small sets of values found in SIMD within a register (SWAR) processing such as that found in NEON. It is also advantageous to do so because this coarse-grained view can be a good match for accelerators found in modern SoCs.
We observe that with some non-trivial adaptation and some additional observations, optimization techniques known to work on fine-grained operations and data can be adapted to operate on coarse-grained operations and data.
Our compiler understands the semantics associated with the data structures and their use within the system, and can manipulate them and the program to perform transformations and optimisations to enable and optimise execution of the program.
5.2 Conventional Analyses and Their Extension
Most optimizing compilers perform a dataflow analysis prior to optimization. For example, section 10.5 of Aho Sethi and Ullman's ‘Compilers: Principles Techniques and Tools’, published by Addison Wesley, 1986, ISBN: 0-201-10194-7 describes dataflow analysis. The dataflow analysis is restricted to scalar values: those that fit in a single CPU register. Two parts of a dataflow analysis are:
-
- identifying the dataflow through individual operations
- combining the dataflow analysis with a control-flow analysis to determine the dataflow from one program point to another.
In order to use dataflow analysis techniques with coarse-grained dataflow, we modify the first part so that instead of identifying the effect of a single instruction on a single element, we identify the effect of a coarse-grained operation (e.g., a function call or coprocessor invocation) on an entire data structure in terms of whether the operation is a ‘use’, a ‘def’ or a ‘kill’ of the value in a data structure. Care must be taken if an operation modifies only half of an array since the operation does not completely kill the value of the array.
For operations implemented in hardware or in software, this might be generated automatically from a precise description of the operation (including the implementation of the operation) or it might be generated from an approximate description of the main effects of the operation or it might be provided as a direct annotation.
In particular, for software, these coarse-grained operations often consist of a simple combination of nested loops and we can analyze the code to show that the operation writes to an entire array and therefore ‘kills’ the old value in the array. In scalar analysis, this is trivial since any write necessarily kills the entire old value.
The following sections identify some of the uses of coarse-grained dataflow analysis
5.3 Multiple Versions of the Same Buffer
Especially when writing parallel programs or when using I/O devices and when dealing with complex memory hierarchies, it is necessary to allocate multiple identically sized buffers and copy between the different buffers (or use memory remapping hardware to achieve the effect of a copy). We propose that in many cases these multiple buffers can be viewed as alternative versions of a single, logical variable. It is possible to detect this situation in a program with multiple buffers, or the programmer can identify the situation. One way the programmer can identify the situation is to declare a single variable and then use annotations to specify that the variable lives in multiple places or the programmer could declare multiple variables and use annotations to specify that they are the same logical variable.
However the different buffers are identified as being one logical variable, the advantages that can be obtained include:
-
- more intelligent buffer allocation
- detecting errors where one version is updated and that change is not propagated to other version before it is used
- debug, trace and profile tools can treat a variable as one logical entity so that, for example, if programmer sets watchpoint on x then tools watch for changes on any version of x. Likewise, if compiler has put x and y in the same memory location (following liveness analysis), then the programmer will only be informed about a write to x when that memory location is being used to store x, not when it is being used to store y. When doing this, you might well want to omit writes to a variable which exist only to preserve the multi-version illusion. For example, if one accelerator writes to version 1, then a dma copies version 1 to version 2, then another accelerator modifies the variable, then the programmer will often not be interested in the dma copy.
We note that compilers do something similar for scalar variables: the value of a scalar variable ‘x’ might sometimes live on the stack, sometimes in register 3, sometimes in register 6, etc. and the compiler keeps track of which copies currently contain the live value.
5.4 Allocation
By performing a liveness analysis of the data structures, the compiler can provide improved memory allocation through memory reuse because it can identify opportunities to place two different variables in the same memory location. Indeed, one can use many algorithms normally used for register allocation (where the registers contain scalar values) to perform allocation of data structures. One modification required is that one must handle the varying size of buffers whereas, typically, all scalar registers are the same size.
5.5 Scheduling
One thing that can increase memory use is having many variables simultaneously live. It has been known for a long time that you can reduce the number of scalar registers required by a piece of code by reordering the scalar operations so that less variables are simultaneously live.
Using a coarse-grained dataflow analysis, one can identify the lifetime of each coarse-grained data structure and then reorder code to reduce the number of simultaneously live variables. One can even choose to recalculate the value of some data structure because it is cheaper to recalculate it than to remember its value.
When parallelising programs, one can also deliberately choose to restrain the degree of parallelism to reduce the number of simultaneously live values. Various ways to restrain the parallelism exist: forcing two operations into the same thread, using mutexes/semaphores to block one thread if another is using a lot of resource, tweaking priorities or other scheduler parameters.
If a processor/accelerator has a limited amount of available memory, performing a context switch on that processor can be challenging. Context switching memory-allocated variables used by that processor solves the problem.
5.6 Optimisation
Compiler books list many other standard transformations that can be performed to scalar code. Some of the mapping and optimisation techniques that can be applied at the coarse-grain we discuss include value splitting, spilling, coalescing, dead variable removal, recomputation, loop hoisting and CSE.
Data structures will be passed as arguments, possibly as part of an ABI. Optimisations such as specialisation and not conforming to the ABI when it is not exposed can be applied.
5.7 Multigranularity Operation
In some cases, one would want to view a complex datastructure at multiple granularities. For example, given a buffer of complex values, one might wish to reason about dataflow affecting all real values in the buffer, dataflow affecting all imaginary values or dataflow involving the whole buffer. (More complex examples exist)
5.8 Debugging
When debugging, it is possible for the data structure to live in a number of different places throughout the program. We can provide a single debug view of all copies, and watch a value wherever it is throughout the lifetime of a program, optionally omitting omit certain accesses such as DMAs.
The same is possible for tracing data structures within the system.
5.9 Zero Copying
Using this coarse-grained view, one can achieve zero copy optimization of a sequence of code like this:
-
- int x[100];
- generate(&x); // writes to x
- put(channel,&x)
by inlining the definition of put to get: - int x[100];
- generate(&x); // writes to x
- int *px=put_begin(channel);
- copy(px,&x);
- put_end(channel,px);
then reordering the code a little: - int *px=put_begin(channel);
- int x[100];
- generate(&x); // writes to x
- copy(px,&x);
- put_end(channel,px);
and optimizing the memory allocation and copy: - int *px=put_begin(channel);
- generate(px); // writes to *px
- put_end(channel,px);
5.10 Trace
Most of this section is about coarse-grained data structure but some benefits from identifying coarse-grained operations come when we are generating trace. Instead of tracing every scalar operation that is used inside a coarse-grained operation, we can instead just trace the start and stop of the operation. This can also be used for cross-triggering the start/stop of recording other information through trace.
Likewise, instead of tracing the input to/output from the whole sequence of scalar operations, we can trace just the values at the start/end of the operation.
5.11 Validating Programmer Assertions
If we rely on programmer assertions, documentation, etc. in performing our dataflow analysis, it is possible that an error in the assertions will lead to an error in the analysis or transformations performed. To guard against these we can often use hardware or software check mechanisms. For example, if we believe that a function should be read but not written by a given function, then we can perform a compile-time analysis to verify it ahead of time or we can program an MMU or MPU to watch for writes to that range of addresses or we can insert instrumentation to check for such errors. We can also perform a ‘lint’ check which looks for things which may be wrong even if it cannot prove that they are wrong. Indeed, one kind of warning is that the program is too complex for automatica analysis to prove that it is correct.
5.12 Summary
Some of the features of our approach are:
-
- Using a register like (aka scalar-like) approach to data structure semantics within the system
- Using liveness analysis to influence memory allocation, parallelism and scheduling decisions.
- Applying register optimisations found in compiler to data structures within a program.
- Providing debugging and tracing of variables as a single view
6. Decoupling
6.1 Overview
Given a program that uses some accelerators, it is possible to make it run faster by executing different parts in parallel with one another. Many methods for parallelizing programs exist but many of them require homogeneous hardware to work and/or require very low cost, low latency communication mechanisms to obtain any benefit. Our compiler uses programmer annotations (many/all of which can be inserted automatically) to split the code that invokes the accelerators (‘the control code’) into a number of parallel “threads” which communicate infrequently. Parallelizing the control code is advantage because it allows tasks on independent accelerators to run concurrently.
Our compiler supports a variety of code generation strategies which allow the parallelized control code to run on a control processor in a real time operating system, in interrupt handlers or in a polling loop (using ‘wait for event’ if available to reduce power) and it also supports distributed scheduling where some control code runs on one or more control processors, some control code runs on programmable accelerators, some simple parts of the code are implemented using conventional task-chaining hardware mechanisms. It is also possible to design special ‘scheduler devices’ which could execute some parts of the control code. The advantage of not running all the control code on the control processor is that it can greatly decrease the load on the control processor.
Other parallelising methods may be used in conjunction with the other aspects of this compiler.
Some of the features of our approach are:
-
- By applying decoupled software pipelining to the task of parallelizing the control code in a system that uses heterogeneous accelerators, we significantly extend the reach of decoupled software pipelining and by working on coarser grained units of parallelism, we avoid the need to add hardware to support high frequency streaming.
- By parallelizing at a significantly coarser granularity, we avoid the need for low latency, high throughput communication mechanisms used in prior art.
- Parallelizing at a significantly coarser granularity also allows us to duplicate more control code between threads which reduces and simplifies inter-thread communication which allows us to generate distributed schedules. That is, we can distribute the control code across multiple processors both by putting each control thread on a different processor and by putting different parts of a single control thread onto different processors.
- By optionally allowing the programmer more control over the communication between threads, we are able to overcome the restriction of decoupled software pipelining to acyclic ‘pipelines’.
- The wide range of backends including distributed scheduling and use of hardware support for scheduling.
- Our decoupling algorithm is applied at the source code level whereas existing decoupling algorithms are applied at the assembly code level after instruction scheduling.
Some of the recent known discussions on decoupled software pipelining are:
-
- Decoupled Software Pipelining: http://liberty.princeton.edu/Research/DSWP/http://liberty.princeton.edu/Publications/index.php?abs=1&setselect=pact04_dswp http://liberty.cs.princeton.edu/Publications/index.php?abs=1&setselect=micro38_dswp
- Automatically partitioning packet processing applications for pipelined architectures, PLDI 2005, ACM http://portal.acm.org/citation.cfm?id=1065010.1065039
6.2 A Basic Decoupling Algorithm
The basic decoupling algorithm splits a block of code into a number of threads that pass data between each other via FIFO channels. The algorithm requires us to identify (by programmer annotation or by some other analysis including static analysis, profile driven feedback, etc.) the following parts of the program:
-
- The “decoupling scope”: that is a contiguous sequence of code that we wish to split into multiple threads. Some ways this can be done are by marking a compound statement, or we can insert a ‘barrier’ annotation that indicates that some parallelism ends/starts here.
- The “replicatable objects”: that is variables and operations which it is acceptable to replicate. A simple rule of thumb is that scalar variables (i.e., not arrays) which are not used outside the scope, scalar operations which only depend on and only modify replicatable variables, and control flow operations should be replicated but more sophisticated policies are possible.
- Ordering dependencies between different operations: if two function calls both modify a non-replicated variable, the order of those two function calls is preserved in the decoupled code. (Extensions to the basic algorithm allow this requirement to be relaxed in various ways.)
- The “data boundaries” between threads: that is, the non-replicatable variables which will become FIFO channels. (The “copies” data annotation described above determines the number of entries in the FIFO.)
(Identifying replicatable objects and data boundaries are two of the features of our decoupling algorithm.)
If we use annotations on the program to identify these program parts, a simple program might look like this:
| void main( ) { | |
| int i; | |
| for(i=0; i<10; ++i) { | |
| int x[100] @ {copies=2, replicatable=false; boundary=true} ; | |
| produce(x) @ {replicatable=false, writes_to=[x]}; | |
| DECOUPLE(x); | |
| consume(x) @ {replicatable=false, reads_from=[x]}; | |
| } | |
| } | |
This degree of annotation is fine for examples but would be excessive in practice so most real embodiments would rely on tools to add the annotations automatically based on heuristics and/or analyses.
At a high level, the algorithm splits the operations in the scope into a number of threads whose execution will produce the same result as the original program under any scheduling policy that respects the FIFO access ordering of the channels used to communicate between threads.
The particular decoupling algorithm we use generates a maximal set of threads such that the following properties hold:
-
- All threads have the same control flow structure and may have copies of the replicatable variables and operations.
- Each non-replicatable operation is included in only one of the threads.
- Each non-replicatable variable must satisfy one of the following:
- The only accesses to the variable in the original program are reads; or
- All reads and writes to the variable are in a single thread; or
- The variable was marked as a data boundary and all reads are in one thread and all writes are in another thread.
- If two operations have an ordering dependency between them which is not due to a read after write (RAW) dependency on a variable which has been marked as a data boundary, then the operations must be in the same thread.
For the example program above, the maximal set of threads is:
| void main( ) { | |
| int x[100] @ {copies=2}; | |
| channel c @ {buffers=x}; | |
| parallel sections{ | |
| section{ | |
| int i; | |
| for(i=0; i<10; ++i) { | |
| int x1[100]; | |
| produce(x1); | |
| put(c,x1); | |
| } | |
| } | |
| section{ | |
| int i; | |
| for(i=0; i<10; ++i) { | |
| int x2[100]; | |
| get(c,x2); | |
| consume(x2); | |
| } | |
| } | |
| } | |
One way to generate this set of threads is as follows:
-
- 4. For each non-replicatable operation, create a ‘protothread’ consisting of just that operation plus a copy of all the replicatable operations and variables. Each replicatable variable must be initialized at the start of each thread with the value of the original variable before entering the scope and one of the copies of each replicatable variable should be copied back into the master copy on leaving the scope. (Executing all these protothreads is highly unlikely to give the same answer as the original program, because it lacks the necessary synchronization between threads. This is fixed by the next steps.)
- 5. Repeatedly pick two threads and merge them into a single thread if any of the following problems exist:
- a. One thread writes a non-replicatable variable which is accessed (read or written) by the other thread and the variable is not marked as a data boundary.
- b. Two threads both write to a variable which is marked as a data boundary.
- c. Two threads both read from a variable that is marked as a data boundary.
- d. There is an ordering dependency between an operation in one thread and an operation in the other thread which is not a RAW dependency on a variable marked as a data boundary.
- 6. When no more threads can be merged, quit
Another way if to pick an operation, identify all the operations which must be in the same thread as that operation by repeatedly adding operations which would be merged (in step 2 above). Then pick the next operation not yet assigned to a thread and add all operations which must be in the same thread as that operation. Repeat until there are no more non-replicatable operations. (There are lots of other ways of tackling this problem: basically, we are forming equivalence classes based on a partial order and there are many known ways to do that.)
Note that doing dataflow analysis on arrays one must distinguish defs which are also kills (i.e., the entire value of a variable is overwritten by an operation) and that requires a more advanced analysis than is normally used.
6.3 Decoupling Extensions
There are a number of extensions to this model
6.3.1 Range Splitting Preprocessing
It is conventional to use dataflow analysis to determine the live ranges of a scalar variable and then replace the variable with multiple copies of the variable: one for each live range. We use the same analysis techniques to determine the live range of arrays and split their live ranges in the same way. This has the benefit of increasing the precision of later analyses which can enable more threads to be generated. On some compilers it also has the undesirable effect of increasing memory usage which can be mitigated by later merging these copies if they end up in the same thread and by being selective about splitting live ranges where the additional decoupling has little overall effect on performance.
6.3.2 Zero Copy Optimizations
The put and get operations used when decoupling can be used both for scalar and non-scalar values (i.e., both for individual values (scalars) and arrays of values (non-scalars) but they are inefficient for large scalar values because they require a memory copy. Therefore, for coarse-grained decoupling, it is desirable to use an optimized mechanism to pass data between threads.
In operating systems, it is conventional to use “zero copy” interfaces for bulk data transfer: instead of generating data into one buffer and then copying the data to the final destination, we first determine the final destination and generate the data directly into the final destination. Applying this idea to the channel interface, we can replace the simple ‘put’ operation with two functions: put_begin obtains the address of the next free buffer in the channel and put_end makes this buffer available to readers of the channel:
-
- Void* put _begin(channel *ch);
- Void put_end(channel *ch, void* buf);
Similarily, the get operation is split into a get_begin and get_end pair
-
- Void* get_begin(channel *ch);
- Void get_end(channel *ch, void* buf);
Using these operations, we can often rewrite sequences of code such as:
-
- Int x[100];
- Generate(x);
- Put(ch,x);
to this more efficient sequence: - Int *px=put_begin(ch);
- Generate(px);
- Put_end(ch,px);
And similarily, for get: - Int x[100];
- Get(ch,x);
- Consume(x);
to this more efficient sequence: - Int *px=get_begin(ch);
- Consume(px);
- get_end(ch,px);
Note that doing zero copy correctly requires us to take lifetime of variables into account.
We can do that using queues with multiple readers, queues with intermediate r/w points, reference counts or by restricting the decoupling (all readers must be in same thread and . . . ) to make lifetime trivial to track. This can be done by generating custom queue structures to match the code or custom queues can be built out of a small set of primitives.
6.3.3 Dead Code and Data Elimination
This section illustrates both how to get better results and also that we may not get exactly the same control structure but that they are very similar.
6.3.4 Allowing Cyclic Thread Dependencies
Prior art on decoupling restricts the use of decoupling to cases where the communication between the different threads is acyclic. There are two reasons why prior art has done this:
-
- 2. Cyclic thread dependencies can lead to deadlock—that is, two threads may not run in parallel because of data dependencies between them.
- 3. A particularity common case of cyclic thread dependencies is code such as
| y = 1; | |
| while(1) { | |
| x = f(y); | |
| y = g(x); | |
| } | |
-
- Under existing decoupling schemes, puts are always inserted after assignment to any data boundary variable. This would require both a put outside the loop and a put at the end of the loop:
| y1 = 1; | |
| put(ch,y1); | |
| while(1) { | |
| y2 = get(ch); | |
| x = f(y2); | |
| y3 = g(x); | |
| put(ch,y3); | |
| } | |
-
- Existing decoupling schemes only generate matched pairs of puts and gets (i.e., there is only one put on each channel and only one get on each channel so they cannot generate such code An alternative way of decoupling this code is to generate:
| y1 = 1; | |
| while(1) { | |
| put(ch,y1); | |
| y2 = get(ch); | |
| x = f(y2); | |
| y1 = g(x); | |
| } | |
-
- This does have matched pairs of puts and gets but breaks the rule of always performing a put after any assignment to a variable so it is also not generated by existing decoupling techniques.
6.3.5 Exposing Channels to the Programmer
It is possible to modify the decoupling algorithm to allow the programmer to insert puts and gets (or put_begin/end, get_begin/end pairs) themselves. The modified decoupling algorithm treats the puts and gets in much the same way that the standard algorithm treats data boundaries. Specifically, it constructs the maximal set of threads such that:
-
- Almost all the same conditions as for standard algorithm go here
- All puts to a channel are in the same thread
- All gets to a channel are in the same thread
For example, given this program:
| channel ch1; | |
| put(ch1,0); | |
| for(int i=0; i<N); ++i) { | |
| int x = f( ); | |
| put(ch1,x); | |
| int y = g(get(ch1)); | |
| DECOUPLE(y); | |
| h(x,y); | |
| } | |
The modified decoupling algorithm will produce:
| channel ch1, ch2; | |
| put(ch1,0); | |
| parallel sections{ | |
| section{ | |
| for(int i=0; i<10; ++i) { | |
| x = f( ); | |
| put(ch1,x); | |
| int y = get(ch2); | |
| h(x,y); | |
| } | |
| } | |
| section{ | |
| for(int i=0; i<10; ++i) { | |
| int y = g(get(ch1)); | |
| put(ch2,y); | |
| } | |
| } | |
This extension of decoupling is useful for creating additional parallelism because it allows f and g to be called in parallel.
Writing code using explicit puts can also be performed as a preprocessing step. For example, we could transform:
| for(i=0; i<N; ++i) { | |
| x = f(i); | |
| y = g(i,x); | |
| h(i,x,y); | |
| } | |
To the following equivalent code:
| x = f(0); | |
| for(i=0: i<N; ++i) { | |
| y = g(i,x); | |
| h(i,x,y); | |
| if (i+1<N) x = f(i+1); | |
| } | |
Which, when decoupled gives very similar code to the above.
(There are numerous variations on this transformation including computing f(i+1) unconditionally, peeling the last iteration of the loop, etc.)
6.3.6 Alternatives to FIFO Channels
A First-In First-Out (FIFO) channel preserves the order of values that pass through it: the first value inserted is the first value extracted, the second value inserted is the second value extracted, etc. Other kinds of channel are possible including:
-
- a “stack” which has Last in First out (LIFO) semantics. Amongst other advantages, stacks can be simpler to implement
- a priority queue where entries are prioritized by the writer or according to some property of the entry and the reader always received the highest priority entry in the queue.
- a merging queue where a new value is not inserted if it matches the value at the back of the queue or as a variant, if it matches any value in the queue. Omitting duplicate values which may help reduce duplicated work
- a channel which only tracks the last value written to the queue. That is, the queue logically contains only the most recently written entry. This is useful if the value being passed is time-dependent (e.g., current temperature) and it is desirable to always use the most recent value. Note that with fine-grained decoupling the amount of time between generation of the value and its consumption is usually small so being up to date is not a problem; whereas in coarse-grained decoupling, a lot of time may pass between generation and consumption and the data could easily be out of date if passed using a FIFO structure.
- A channel which communicates with a hardware device. For example, a DMA device may communicate with a CPU using a memory mapped doubly-linked list of queue entries which identify buffers to be copied or a temperature sensor may communicate with a CPU using a device register which contains the current temperature.
Using most of these alternative channels has an affect on program meaning so we either have to perform an analysis before using a different kind of channel or the programmer can indicate that a different choice is appropriate/allowed.
6.3.7 Using Locks
In parallel programming, it is often necessary for one thread to need exclusive access to some resource while it is using that resource to avoid a class of timing dependent behaviour known as a “race condition” or just a “race”. The regions of exclusive access are known as “critical sections” and are often clearly marked in a program. Exclusive access can be arranged in several ways. For example, one may ‘acquire’ (aka ‘lock) a ‘lock’ (aka ‘mutex’) before starting to access the resource and ‘release’ (aka ‘unlock’) the lock after using the resource. Exclusive access may also be arranged by disabling pre-emption (such as interrupts) while in a critical section (i.e., a section in which exclusive access is required). In some circumstances, one might also use a ‘lock free’ mechanism where multiple users may use a resource but at some point during use (in particular, at the end), they will detect the conflict, clean up and retry.
Some examples of wanting exclusive access include having exclusive access to a hardware accelerator, exclusive access to a block of memory or exclusive access to an input/output device. Note that in these cases, it is usually not necessary to preserve the order of accesses to the resource.
The basic decoupling algorithm avoids introducing race conditions by preserving all ordering dependencies on statements that access non-replicated resources. Where locks have been inserted into the program, the basic decoupling algorithm is modified as follows:
-
- The ordering dependencies on operations which use shared resources can be relaxed. This requires programmer annotation and/or program analysis which, for each operation which may be reordered, identifies:
- Which other operations it can be reordered relative to
- Which operations can simultaneously access the same resource (i.e., without requiring exclusive access)
- Which critical section each operation occurs in.
- For example, one might identify a hardware device as a resource, then indicate which operations read from the resource (and so can be executed in parallel with each other) and which operations modify the resource (and so must have exclusive access to the resource).
- For simplicity, one might identify all operations inside a critical section as having an ordering dependency between them though one can sometimes relax this if the entire critical section lies inside the scope of decoupling.
- One might determine which critical section each operation occurs in using an analysis which conservatively approximates the set of locks held at all points in the program.
- The ordering dependencies on operations which use shared resources can be relaxed. This requires programmer annotation and/or program analysis which, for each operation which may be reordered, identifies:
6.3.8 Multithreaded Input
Decoupling can be applied to any sequential section of a parallel program. If the section communicates with the parallel program, we must determine any ordering dependencies that apply to operations within the section (a safe default is that the order of such operations should be preserved). What I'm saying here is that one of the nice properties of decoupling is that it interacts well with other forms of paralellization including manual parallelization.
6.4 Decoupling Backends
The decoupling algorithm generates sections of code that are suitable for execution on separate processors but can be executed on a variety of different execution engines by modifying the “back end” of the compiler. That is, by applying a further transformation to the code after decoupling to better match the hardware or the context we wish it to run in.
6.4.1 Multiprocessor and Multithreaded Processor Backends
The most straightforward execution model is to execute each separate section in the decoupled program on a separate processor or, on a processor that supports multiple hardware contexts (i.e., threads), to execute each separate section on a separate thread.
Since most programs have at least one sequential section before the separate sections start (e.g., there may be a sequential section to allocate and initialize channels), execution will typically start on one processor which will later synchronize with the other processors/threads to start parallel sections on them.
6.4.2 Using Accelerators
In the context of an embedded system and, especially, a System on Chip (SoC), some of the data processing may be performed by separate processors such as general purpose processors, digital signal processors (DSPs), graphics processing units (GPUs), direct memory access (DMA) units, data engines, programmable accelerators or fixed-function accelerators. This data processing can be modelled as a synchronous remote procedure call. For example, a memory copy operation on a DMA engine can be modelled as a function call to perform a memory copy. When such an operation executes, the thread will typically:
-
- acquire a lock to ensure it has exclusive access to the DMA engine
- configure the DMA engine with the source and destination addresses and the data size
- start the DMA engine to initiate the copy
- wait for the DMA engine to complete the copy which will be detected either by an interrupt to a control processor or by polling
- copy out any result from the copy (such as a status value)
- release the lock on the accelerator
This mode of execution can be especially effective because one ‘control processor’ can keep a number of accelerator's busy with the control processor possibly doing little more than deciding which accelerator to start next and on what data. This mode of execution can be usefully combined with all of the following forms of execution.
6.4.3 RTOS Backend
Instead of a multiprocessor or multithreaded processor, one can use a thread library, operating system (OS) or real time operating system (RTOS) running on one or more processors to execute the threads introduced by decoupling. This is especially effective when combined with the use of accelerators because running an RTOS does not provide parallelism and hence does not increase performance but using accelerators does provide parallelism and can therefore increase performance.
6.4.4 Transforming to Event-Based Execution
Instead of executing threads directly using a thread library, OS or RTOS, one can transform threads into an ‘event-based’ form which can execute more efficiently than threads. The methods can be briefly summarized as follows:
-
- Transformations to data representation.
- The usual representation of threads allocates thread-local variables on a stack and requires one stack per thread. The overhead of managing this stack and some of the space overhead of stacks can be reduced by using a different allocation policy for thread-local variables based on how many copies of the variable can be live at once and on the lifetime of the variables.
- If only one copy of each variable can be live at once (e.g., if the functions are not required to be re-entrant), then all variables can be allocated statically (i.e., not on a stack or heap).
- If multiple copies of a variable can be live at once (e.g., if more than once instance of a thread can be live at once), the variables can be allocated on the heap.
- Transformations to context-switch mechanism
- When one processor executes more threads than the processor supports, the processor must sometimes switch from executing one thread to executing another thread. This is known as a ‘context switch’. The usual context mechanism used by threads is to save the values of all registers on the stack or in a reserved area of memory called the “thread control block”, then load all the registers with values from a different thread control block and restart the thread. The advantage of this approach is that a context switch can be performed at almost any point during execution so any code can be made multithreaded just by using a suitable thread library, OS or RTOS.
- An alternative mechanism for context switching is to transform each thread to contain explicit context switch points where the thread saves its current context in a thread control block and returns to the scheduler which selects a new thread to run and starts it. The advantages of this approach are that thread control blocks can be made significantly smaller. If all context switches occur in the top-level function and all thread-local variables can be statically allocated, it is possible to completely eliminate the stack so that the entire context of a thread can be reduced to just the program counter value which makes context switches very cheap and makes thread control blocks extremely small.
- A further advantage of performing context switches only at explicit context switch points is that it is easier and faster to ensure that a resource shared between multiple threads is accessed exclusively by at most one thread at a time because, in many cases, it is possible to arrange that pre-emption only happens when the shared resource is not being used by the current thread.
Together, these transformations can be viewed as a way of transforming a thread into a state machine with each context switch point representing a state and the code that continues execution from each context switch point viewed as a transition function to determine the next state. Execution of transformed threads can be viewed as having been transformed to an event-based model where all execution occurs in response to external events such as responses from input/output devices or from accelerators. It is not necessary to transform all threads: event-based execution can coexist with threaded execution.
6.4.5 Interrupt-Driven Execution
Transforming threads as described above to allow event-based execution is a good match for applications that use accelerators that signal task completion via interrupts. On receiving an interrupt signalling task completion the following steps occur:
-
- the state of the associated accelerator is updated
- all threads that could be blocked waiting for that task to complete or for that accelerator to become available are executed. This may lead to further threads becoming unblocked.
- When there are no runnable threads left, the interrupt handler completes
6.4.6 Polling-Based Execution
Transforming threads as described above is also a good match for polling-based execution where the control processor tests for completion of tasks on a set of accelerators by reading a status register associated with each accelerator. This is essentially the same as interrupt-driven execution except that the state of the accelerators is updated by polling and the polling loop executes until all threads complete execution.
6.4.7 Distributed Scheduling
Distributed scheduling can be done in various ways. Some part of a program may be simple enough that it can be implemented using a simple state machine which schedules one invocation of an accelerator after completion of another accelerator. Or, a control processor can hand over execution of a section within a thread to another processor. In both cases, this can be viewed as a RPC like mechanism (“{foo( ); bar( )@P0;}@P1”). In the first case, one way to implement it is to first transform the thread to event-based form and then opportunistically spot that a sequence of system states can be mapped onto a simple state machine and/or you may perform transformations to make it map better.
6.4.8 Non-Work-Conserving Schedulers and Priorities/Deadlines
Two claims in this section: 1) using a priority mechanism and 2) using a non-work-conserving scheduler in the context of decoupling
If a system has to meet a set of deadlines and the threads within the system share resources such as processors, it is common to use a priority mechanism to select which thread to run next. These priorities might be static or they may depend on dynamic properties such as the time until the next deadline or how full/empty input and output queues are.
In a multiprocessor system, using a priority mechanism can be problematic because at the instant that one task completes, the set of tasks available to run next is too small to make a meaningful choice and better schedules occur if one waits a small period of time before making a choice. Such schedulers are known as non-work-conserving schedulers.
7. Trace Reconstruction
7.1 Overview
A long-standing problem of parallelizing compilers is that it is hard to relate the view of execution seen by debug mechanisms to the view of execution the programmer expects from the original sequential program. Our tools can take an execution trace obtained from running a program on parallel hardware and reorder it to obtain a sequential trace that matches the original program. This is especially applicable to but not limited to the coarse-grained nature of our parallelization method.
To achieve complete reconstruction, it helps if the parallelizing compiler inserts hints in the code that make it easier to match up corresponding parts of the program. In the absence of explicit hints, it may be possible to obtain full reconstruction using debug information to match parts of the program.
When there are no explicit hints or debug information, partial reconstruction can be achieved by using points in the program that synchronize with each other to guide the matching process. The resulting trace will not be sequential but will be easier to understand. A useful application is to make it simpler to understand a trace of a program written using an event-based programming style (e.g., a GUI, interrupt handlers, device drivers, etc.)
Partial reconstruction could also be used to simplify parallel programs running on systems that use release consistency. Such programs must use explicit memory barriers at all synchronization points so it will be possible to simplify traces to reduce the degree of parallelism the programmer must consider.
One simple case of this is reconstructing a ‘message passing’ view of bus traffic.
HP has been looking at using trace to enable performance debugging of distributed protocols. Their focus is on data mining and performance not reconstructing a sequential trace.
http://portal.acm.org/citation.cfm?id=945445.945454&dl =portal&dl=ACM&type=series&idx=945445&part=Proceedings&WantType=Proceedings&title=ACM %20Symposium%20on%20Operating%20Systems%20Principles&CFID=11111111&CFTOKEN=2222222
7.2 Partial Reconstruction Based on Observed Dataflow
Suppose we can identify sections of the system execution and we have a trace which lets us identify when each section was running and we have a trace of the memory accesses they performed or, from knowing properties of some of the sections, we know what memory accesses they would perform without needing a trace. The sections we can identify might be:
-
- function calls
- remote procedure calls
- execution of a fixed-function accelerator such as a DMA transfer
- message passing
We can summarize the memory accesses of each section in terms of the input data and the output data (what addresses were accessed and, perhaps, what values were read or written).
Given a sequence of traces of sections, we can construct a dynamic dataflow graph where each section is a node in a directed graph and there is an edge from a node M to a node N if the section corresponding to M writes to an address x and the section corresponding to N reads from address x and, in the original trace, no write to x happens between M's write to x and N's read from x.
This directed dataflow graph shows how different sections communicate with each other and can be used for a variety of purposes:
-
- identify potential parallelism
- identify timing-sensitive behaviour such as race conditions (when combined with a trace of synchronizations between parallel threads): if M writes to x and N reads from x and there is no chain of synchronizations from M to N to ensure that N cannot read from x before M does the read, there is a potential problem
- identify redundant memory writes (if a value is overwritten before it has been read)
- provides a simple way to show programmers what is happening in a complex, possibly parallel, system
- can be analyzed to determine the time between when data is being generated and when it is consumed. If the time is long it might suggest that memory requirements could be reduced by calculating data nearer the time or, in a parallel or concurrent system that the generating task can be executed later.
- can be analyzed to identify number and identity of consumers of data: it is often possible to manage memory more efficiently or generate data more efficiently if we know what it is being used for, when it is being used, etc.
Many other uses exist.
7.3 Full Reconstruction Based on Parallelization Transformations
The first section talks about what you need for the general case of a program that has been parallelized and you would like to serialize trace from a run of the parallel program based on some understanding of what transformations were done during parallelization (i.e., you know how different bits of the program relate to the original program). The second part talks about how you would specifically do this if the paralellization process included decoupling. The sketch describes the simplest case in which it can work but it is possible to relax these restrictions significantly.
Here is a brief description of what is required to do trace reconstruction for decoupled programs. That is, to be able to take a trace from the decoupled program and reorder it to obtain a legal trace of the original program.
Most relevant should be conditions 1-9 which say what we need from trace. Where the conditions do not hold, there need to be mechanisms to achieve the same effect or a way of relaxing the goals so that they can still be met. For example, if we can only trace activity on the bus and two kernels running on the same DE communicate by one leaving the result in DE-local memory and the other using it from there, then we either add hardware to observe accesses to local memories or we tweak the schedule to add a spurious DMA copy out of the local memory so that it appears on the bus or we pretend we didn't want to see that kind of activity anyway.
Condition 10 onwards relate mainly to what decoupling aims to achieve. But, some conditions are relevant such as conditions 5 and 6 because, in practice, it is useful to be able to relax these conditions slightly. For example (5) says that kernels have exclusive access to buffers but it is obviously ok to have multiple readers of the same buffer and it would also be ok (in most real programs) for two kernels to (atomically) invoke ‘malloc’ and ‘free’ in the middle of the kernels even though the particular heap areas returned will depend on the precise interleaving of those calls and it may even be ok for debugging printfs from each kernel to be ordered.
Initial assumptions (to be relaxed later):
-
- 1. Trace can see the start and end of each kernel execution and can identify which kernel is being started or is stopping.
- 2. Trace can see context switches on each processor and can identify which context we are leaving and which context we are entering.
Consequences of (1)-(2): We can derive which kernel instance is running on any processor at any time.
-
- 3. Trace has a coherent, consistent view of all activity on all processors.
- 4. Trace can identify the source of all transactions it observes.
- Two mechanisms that can make this possible are:
- 1. Trace might observe directly which processor caused a transaction. or
- 2. Trace might observe some property of the transaction such as the destination address and combine that with some property of the kernels running at that time.
- Condition 2 can be satisfied if we have each kernel only accesses buffers that are either:
- 1. At a static address (and of static length); or
- 2. At an address (and of a length) that are handed to the kernel at the start of kernel execution and trace can infer what that address and length are.
Consequences of (1)-(4): We can identify each transaction with a kernel instance and we can see all transactions a kernel performs.
-
- 5. Each kernel instance has exclusive access to each buffer during its execution. That is, all inter-kernel communication occurs at kernel boundaries.
- 6. Each kernel's transactions only depend on the state of the buffers it accesses and the state of those buffers only depends on the initial state of the system and on transactions that kernels have performed since then.
Consequences of (1)-(6): Given a trace consisting of the interleaved transactions of a set of kernel instances, we can reorder the transactions such that all transactions of a kernel are contiguous and the resulting trace satisfies all read after write data dependencies. That is, we can construct a sequentially consistent view of the transactions as though kernels executed atomically and sequentially.
Note that there may be many legal traces. e.g., if A (only) writes to address 0 and then 1 and B (only) writes to address 2 and then 3 then the trace ‘0,2,1,3’ could be reordered to ‘0,1,2,3’ or to ‘2,3,0,1’.
-
- 7. Sequencing of each kernel instance is triggered by a (single) state machine. There are a number of parallel state machines. (State machines may be in dedicated hardware or a number of state machines may be simulated on a processor.)
- 8. State machines can synchronize with each other and can wait for completion of a kernel and state transitions can depend (only) on those synchronizations and on the results of kernels.
- 9. Trace has a sequentially consistent, coherent view of all state transitions of the sequencers and all synchronization.
Consequences of (7)-(9): Given a trace of the state transitions and synchronizations, we can reorder them into any of the set of legal transitions those state machines could have made where a transition is legal if it respects synchronization dependencies. Consequences of (1)-(9): Given a trace of all kernel transactions and all state transitions and synchronizations, we can reorder them into any legal trace which respects the same synchronization dependencies and data dependencies.
The challenge of trace reconstruction is to show that, if you decouple a program, then the following holds. (Actually, this is what you want to show for almost any way you may parallelize a program.)
-
- 10. We assume that we have a single ‘master’ deterministic state machine that corresponds to the set of parallel, deterministic state machines in the following way:
- a. Any trace of the ‘master’ state machine is a legal trace of the parallel state machine.
- b. Some traces of the parallel state machine can be reordered into a legal trace of the master state machine.
- c. Those traces of the parallel state machine that cannot be reordered to give a legal trace of the master, are a prefix of a trace that can be reordered to give a legal trace of the master.
- That is, any run of the parallel machine can be run forward to a point equivalent to a run of the master state machine.
- 10. We assume that we have a single ‘master’ deterministic state machine that corresponds to the set of parallel, deterministic state machines in the following way:
(We further assume that we know how to do this reordering and how to identify equivalent points.)
Consequences of (1)-(10): We can reorder any trace to match a sequential version of the same program.
To show that decoupling gives us property (10) (i.e., that any trace of the decoupled program can be reordered to give a trace of the original program and to show how to do that reordering), we need to establish a relationship between the parallel state machine and the master state machine (i.e., the original program). This relationship is an “embedding” (i.e., a mapping between states in the parallel and the master machines such that the transitions map to each other in the obvious way). It is probably easiest to prove this by considering what happens when we decouple a single state machine (i.e., a program) into two parallel state machines.
When we decouple, we take a connected set of states in the original and create a new state machine containing copies of those states but:
-
- 1. The two machines synchronize with each other on all transitions into and out of that set of states.
- 2. The two machines contain a partition of the kernel activations of the original machine.
- 3. The two machines each contain a subset (which may overlap) of the transitions of the original machine.
From this, it follows that the parallel machine_can_execute the same sequence as the original machine. To show that it_must_execute an equivalent sequence (i.e., that we can always reorder the trace), we need the following properties of decoupling:
-
- 4. All data dependencies are respected: if kernel B reads data written by kernel A, then both are executed in sequence on the same state machine or the state machines will synchronize after A completes and before B starts.
- Note that this depends on the fact that channels are FIFO queues so data is delivered in order.
- 4. All data dependencies are respected: if kernel B reads data written by kernel A, then both are executed in sequence on the same state machine or the state machines will synchronize after A completes and before B starts.
Extensions of decoupling allow the programmer to indicate that two operations can be executed in either order even though there is a data dependency between them (e.g., both increment a variable atomically). This mostly needs us to relax the definition of what trace reconstruction is meant to do. One major requirement is that the choice of order doesn't have any knock-on effects on control flow.
-
- 5. Deadlock should not happen:
- threads cannot block indefinitely on a put as long as each queue has space for at least one value.
- threads cannot block indefinitely on a get: either one thread is still making progress towards a put or, if they both hit a get, at least one will succeed.
- 5. Deadlock should not happen:
Outline proof: Because they share the same control flow, the two threads perform opposing actions (i.e., a put/get pair) on channels in the same sequence as each other. A thread can only block on a get or a put if it has run ahead of the other thread. Therefore, when one thread is blocked, the other is always runnable.
Extensions of decoupling allow for the following:
-
- 1. Locks are added by the programmer.
- To avoid deadlock, we require:
- The standard condition that locks must always be obtained in a consistent order.
- If the leading thread blocks on a channel while holding a lock, then the trailing thread cannot block on the same lock.
A sufficient (and almost necessary) condition is that a put and a get on the same channel must not be inside corresponding critical sections (in different threads):
| // Not allowed | |
| parallel_sections{ | |
| section{ ... lock(1); ... put(ch,x); ... unlock(1); ...} | |
| section{ ... lock(1); ... get(ch,x); ... unlock(1); ...} | |
| } | |
which means that the original code cannot have looked like this:
-
- . . . lock(1); . . . DECOUPLE(ch,x); . . . unlock(1); . . .
That is, extreme care must be taken if DECOUPLE occurs inside a critical section especially when inserting DECOUPLE annotations automatically
-
- 2. Puts and gets don't have to occur in pairs in the program.
A useful and safe special case is that all initialization code does N puts, a loop then contains only put_get pairs and then finalization code does at most N gets. It should be possible to prove that this special case is ok.
It might also be possible to prove the following for programs containing arbitrary puts and gets: if the original single-threaded program does not deadlock (i.e., never does a get on an empty channel or a put on a full channel), then neither will the decoupled program.
8. Exploiting Schedule Flexibility
8.1 Overview
A long-standing problem of parallelizing compilers is that it is virtually impossible to provide the programmer with a start-stop debugger that lets them debug in terms of their sequential program even though it runs in parallel. In particular, we would like to be able to run the program quickly (on the parallel hardware) for a few minutes and then switch to a sequential view when we want to debug.
It is not necessary (and hard) to seamlessly switch from running parallel code to running sequential code but it is feasible to change the scheduling rules to force the program to run only one task at a time. With compiler help, it is possible to execute in almost the sequence that the original program would have executed. With less compiler help or where the original program was parallel, it is possible to present a simpler schedule than on the original program. This method can be applied to interrupt driven program too.
This same method of tweaking the scheduler while leaving the application unchanged can be used to test programs more thoroughly. Some useful examples:
-
- Testing the robustness of a real time system by modifying the runtime of tasks.
- Making a task longer may cause a deadline to be missed. Making a task longer may detect scheduling anomalies where the system runs faster if one part becomes slower. (Scheduling anomalies usually indicate that priorities have been set incorrectly.) Making tasks take randomly longer times establishes how stable a schedule is.
- Providing better test coverage in parallel systems. Race conditions and deadlock often have a small window of opportunity which it is hard to detect in testing because the ‘windows’ of several threads have to be aligned for the problem to manifest. By delaying threads by different amounts, we can cause different parts of each thread to overlap so that we can test a variety of alignments. (We can also measure which alignments we have tested so far for test-coverage statistics and for guided search.) This is especially useful for interrupt-driven code.
John Regehr did some work on avoiding interrupt overload by delaying and combining interrupts.
http://portal.acm.org/citation.cfm?id=945445.945454&dl=portal&dl=ACM&type=series&idx=945445&part=Proceedings&WantType=Proceedings&title=ACM %20Symposium%20on%20Operating%20Systems%20Principles&CFID=11111111&CFTOKEN=2222222
but this is really about modifying the (hardware) scheduling of interrupts to have more desirable properties for building real time systems whereas we are more interested in:
-
- debugging, tracing and testing systems (and some of the stuff we do might actually break real-time properties of the system)
- thread schedulers (but we still want to do some interrupt tweaking)
8.2 Testing Concurrent Systems
Errors in concurrent systems often stem from timing-dependent behaviour. It is hard to find and to reproduce errors because they depend on two independently executing sections of code executing at the same time (on a single-processor system, this means that one section is pre-empted and the other section runs). The problematic sections are often not identified in the code.
Concurrent systems often have a lot of flexibility about when a particular piece of code should run: a task may have a deadline or it may require that it receive 2 seconds of CPU in every 10 second interval but tasks rarely require that they receive a particular pattern of scheduling.
The idea is to use the flexibility that the system provides to explore different sequences from those that a traditional scheduler would provide. In particular, we can use the same scheduler but modify task properties (such as deadlines or priorities) so that the system should still satisfy real time requirements or, more flexibly, use a different scheduler which uses a different schedule.
Most schedulers in common use are ‘work conserving schedulers’: if the resources needed to run a task are available and the task is due to execute, the task is started. In contrast, a non-work-conserving scheduler might choose to leave a resource idle for a short time even though it could be used. Non-work-conserving schedulers are normally used to improve efficiency where there is a possibility that a better choice of task will become available if the scheduler delays for a short time.
A non-work-conserving scheduler for testing concurrent systems because they provide more flexibility over the precise timing of different tasks than does a work-conserving scheduler. In particular, we can exploit flexibility in the following way:
-
- model the effect of possibly increased runtime of different tasks. e.g., if task A takes 100 microseconds and we want to know what would happen if it took 150 microseconds, the scheduler can delay scheduling any tasks for 50 microseconds after A completes. A special case is uniformly slowing down all tasks to establish the ‘critical scaling factor’. Another interesting thing to watch for is ‘scheduling anomalies’ where a small change in the runtime of a task can have a large effect on the overall schedule and, in particular, where increasing the runtime of one task can cause another task to execute earlier (which can have both good and bad effects).
- model the effect of variability in the runtime of different tasks by waiting a random amount of time after each task completes
- cause two tasks to execute at a range of different phases relative to each other by delaying the start of execution of one or the other of the tasks by different amounts. Where the tasks are not periodic, (e.g., they are triggered by external events) you might delay execution of one task until some time after the other task has been triggered.
In all these cases, the modification of the schedule is probably done within the constraints of the real-time requirements of the tasks. For example, when a task becomes runnable, one might establish how much ‘slack’ there is in the schedule and then choose to delay the task for at most that amount. In particular, when exploring different phases, if the second event doesn't happen within that period of slack, then the first event must be sent to the system and we will hope to explore that phase the next time the event triggers.
It is often useful to monitor which different schedules have been explored either to report to the programmer exactly what tests have been performed and which ones found problems or to drive a feedback loop where a test harness keeps testing different schedules until sufficient test coverage has been achieved.
8.3 Debugging Parallel Systems
When a sequential program is parallelized, it is often the case that one of the possible schedules that the scheduler might choose causes the program to execute in exactly the same order that the original program would have executed. (Where this is not true, such as with a non-preemptive scheduler it is sometimes possible to insert pre-emption points into the code to make it true.)
If the scheduler is able to determine what is currently executing and what would have run next in the original program, the scheduler can choose to execute the thread that would run that piece of code. (Again, it may be necessary to insert instrumentation into the code to help the scheduler figure out the status of each thread so that it can execute them in the correct order.)
8.4 Tracing Parallel Systems
Reduce amount of reordering required by reordering the execution which might reduce size of window required, simplify task of separating out parallel streams of memory accesses, eliminate the need to reorder trace at all, etc.
9. Exploiting High Level View
9.1 Overview
Working with the whole program at once and following compilation through many different levels of abstraction allows us to exploit information from one level of compilation in a higher or lower level. Some examples:
-
- Executing with very abstract models of kernels can give us faster simulation which gives visualization, compiler feedback and regression checks on meeting deadlines.
- We can plug a high level simulator of one component into a low level system simulation (using back-annotation of timing) and vice-versa.
- We can simulate at various levels of detail: trace start/stop events (but don't simulate kernels), functional simulation using semihosting, bus traffic simulation, etc.
- We can use our knowledge of the high level semantics to insert checking to confirm that the high-level semantics is enforced. For example, if a kernel is supposed to access only some address ranges, we can use an MPU to enforce that.
- We can reconstruct a ‘message-passing view’ of bus traffic.
Although illustrative embodiments of the invention have been described in detail herein with reference to the accompanying drawings, it is to be understood that the invention is not limited to those precise embodiments, and that various changes and modifications can be effected therein by one skilled in the art without departing from the scope and spirit of the invention as defined by the appended claims.
Claims
1. A method of transforming a portion of a computer program comprising a list of sequential instructions comprising control code and data processing code and a program separation indicator indicating a point where said sequential instructions may be divided to form separate sections that are capable of being separately executed and that each comprise different data processing code, said method comprising the steps of:
(i) analysing said portion of said program to determine if said sequential instructions can be divided at said point indicated by said program separation indicator and in response to determining that it can:
(iia) providing data communication between said separate sections indicated by said program separation indicator, such that said separate sections can be decoupled from each other, such that at least one of said sections is capable of being separately executed by an execution mechanism that is separate from an execution mechanism executing another of said separate sections, said at least one of said sections being capable of generating data and communicating said data to at least one other of said separate sections; and
in response to determining it can not:
(iib) not performing step (iia).
2. A method according to claim 1, wherein said step (iib) further comprises outputting a warning indicating an error in said computer program.
3. A method according to claim 1, wherein said step (iib) comprises amending said computer program such that said sequential instructions can be divided at said point and then performing step (iia).
4. A method according to claim 3, wherein said step of amending said computer program comprises inserting data transfer instructions at said point indicated by said program separation indicator.
5. A method according to claim 1, wherein said step (iib) comprises merging said two sections together and removing said program separation indicator.
6. A method according to claim 1, wherein said program separation indicator comprises at least one data transfer instruction, said data communication between said separate sections being provided in dependence upon said at least one data transfer instruction.
7. A method according to claim 1, wherein said program separation indicator comprises a plurality of data transfer instructions each corresponding to one of a plurality of data variables.
8. A method according to claim 6, wherein said step (iia) of providing data communication comprises inserting at least one “put data into a data store” instruction and at least one “get data from said data store” instruction into said instruction stream, and dividing said computer program between said put and get instructions to form said at least one separate section.
9. A method according to claim 8, wherein said data store comprises a FIFO buffer.
10. A method according to claim 1, wherein said step (iia) of providing data communication comprises allowing said data to be transferred in an order different to that it is generated in.
11. A method according to claim 1, wherein said step (iia) comprises providing cyclic data communication between said separate sections.
12. A method according to claim 1, wherein said separate sections comprise the same control code.
13. A method according to claim 1, said portion of said computer program comprising a plurality of program separation indicators each indicating a point where said sequential instructions may be divided to form separate sections, each of said separate sections being capable of being separately executed and comprising different data processing code, said method providing data communication between said separate sections indicated by said plurality of program separation indicators.
14. A method according to claim 1, wherein said transformed computer program is suitable for execution upon respective execution mechanisms of a heterogeneous system having a plurality of execution mechanisms.
15. A method according to claim 14, wherein said heterogeneous system comprises an asymmetric memory hierarchy.
16. A method according to claim 14, wherein said control code of at least one of said sections is operable to be processed by a processor of said heterogeneous system and said data processing code of said section is operable to be processed by an execution mechanism under control of said control code processed by said processor.
17. A method according to claim 14, wherein said plurality of execution mechanisms include one or more of:
a general purpose processor;
a direct memory access unit;
a coprocessor;
an VLIW processor;
a digital signal processor; and
a hardware accelerator unit.
18. A method according to claim 1, wherein said method step comprises an initial step performed before step (i) of:
defining said portion of said computer program by marking said computer program with indications delimiting said portion of said sequential instructions within which said at least two sections are to be located.
19. A method according to claim 1, wherein said computer program comprises said portion having a number of instructions to be executed sequentially and at least one further portion having instructions to be performed in parallel with each other.
20. A method according to claim 1, wherein said portion of said computer program comprises an instruction loop comprising at least two data processing instructions, and said at least two sections each comprise said instruction loop each section comprising at least one of said at least two data processing instructions, said at least two sections comprising different data processing instructions.
21. A method according to claim 1, wherein said portion of said computer program comprises a whole computer program.
22. A computer-readable storage medium comprising a computer program for controlling a computer to perform the method as claimed in claim 1.
23. A computer executing a computer program to perform the method of claim 1.
24. A method of transforming a portion of a computer program comprising a list of sequential instructions and a program separation indicator indicating a point where said sequential instructions may be divided to form separate sections that are capable of being separately executed and that each comprise different data processing code, said list of instructions comprising control code and data processing code, said method comprising the step of:
(i) in response to said program separation indicator, providing data communication between said separate sections such that they can be decoupled from each other, such that at least one of said sections is capable of being separately executed by an execution mechanism that is separate from an execution mechanism executing another of said separate sections and said at least one of said sections can communicate data that it generates to at least one other of said separate sections via said provided data communication.
25. A method according to claim 24, comprising a further initial step (0) performed before step (i) of in response to said program separation indicator, analysing said portion of said computer program and determining which of said sequential instructions should be in which of said separate sections prior to providing said data communication.
Images & Drawings included:
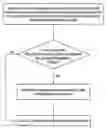










Sources:
- United States Patent and Trademark Office - verify current appl. status at the USPTO↗
Recent applications in this class:
- » 20250138986 2025-05-01
ARTIFICIAL INTELLIGENCE-ASSISTED TROUBLESHOOTING FOR APPLICATION DEVELOPMENT TOOLS - » 20250123948 2025-04-17
DEBUGGING METHOD, IOT DEVICE, DEBUGGING SERVER AND DEBUGGING SYSTEM - » 20250103465 2025-03-27
Debugging assistance device, control system, debugging assistance method, and recording medium - » 20250086093 2025-03-13
DETECTING UNWANTED SOFTWARE USING A MACHINE LEARNING OPERATION - » 20240403188 2024-12-05
COMPUTER SYSTEM AND METHOD FOR PROCESSING DEBUG MESSAGE OF COMPUTER SYSTEM - » 20240370352 2024-11-07
AUTOMATED PROGRAM REPAIR TOOL - » 20240362148 2024-10-31
SYSTEM AND METHOD FOR CONSOLE DEBUG MODE FOR USE WITH CUSTOMIZING CLOUD ENVIRONMENTS - » 20240289252 2024-08-29
DEFERRED CREATION OF REMOTE DEBUGGING SESSIONS - » 20240281361 2024-08-22
BINTYPER: TYPE CONFUSION BUG DETECTION FOR C++ PROGRAM BINARIES - » 20240232049 2024-07-11
System Unique Artificial Intelligence Applied for RISC based Ecosystems in a multi-core hetereogeneous embedded System
Recent applications for this Assignee:
- » 20250173922 2025-05-29
METHOD AND SYSTEM FOR COMPRESSING DATA REPRENTATIVE OF A MAPPING FOR USE IN IMAGE PROCESSING - » 20250173829 2025-05-29
METHOD AND SYSTEM FOR PROCESSING AN IMAGE - » 20250173246 2025-05-29
TRACE GENERATION - » 20250173198 2025-05-29
DATA PROCESSING SYSTEM - » 20250173151 2025-05-29
DATA PROCESSORS - » 20250173148 2025-05-29
TECHNIQUE FOR HANDLING DATA ELEMENTS STORED IN AN ARRAY STORAGE - » 20250173146 2025-05-29
TECHNIQUE FOR HANDLING DATA ELEMENTS STORED IN AN ARRAY STORAGE - » 20250165647 2025-05-22
METHODS AND APPARATUS FOR AMBIENT COMPUTING - » 20250157145 2025-05-15
GRAPHICS PROCESSING - » 20250156184 2025-05-15
SUB-VECTOR-SUPPORTING INSTRUCTION FOR SCALABLE VECTOR INSTRUCTION SET ARCHITECTURE