Antibodies for oncogenic strains of HPV and methods of their use
US20090047660A1
2009-02-19
12/156,013
2008-05-28
Abstract:
The subject invention provides antibodies, including polyclonal and monoclonal antibodies, that bind to E6 proteins from at least three oncogenic strains of HPV. In general, the antibodies bind to amino acids motifs that are conserved between the E6 proteins of different HPV strains, particularly HPV strains 16 and 18. The subject antibodies may be used to detect HPV E6 protein in a sample, and, accordingly, the antibodies find use in a variety of diagnostic applications, including methods of diagnosing cancer. Kits for performing the subject methods and containing the subject antibodies are also provided.
Inventors:
- Chamorro Somoza Diaz-Sarmiento 9 🇺🇸 Mountain View, CA, United States
- Michael P. Belmares 33 🇺🇸 San Jose, CA, United States
- Jonathan David Garman 20 🇺🇸 San Jose, CA, United States
- Peter Lu 5 🇺🇸 Sunnyvale, CA, United States
- Johannes Schweizer 5 🇺🇸 Sunnyvale, CA, United States
Interested in similar patents?
Get notified when new applications in this technology area are published.
Classification:
C07K16/084 » CPC main
Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses from DNA viruses Papovaviridae, e.g. papillomavirus, polyomavirus, SV40, BK virus, JC virus
A61P15/00 » CPC further
Drugs for genital or sexual disorders ; Contraceptives
A61P35/00 » CPC further
Antineoplastic agents
G01N33/56983 » CPC further
Investigating or analysing materials by specific methods not covered by groups -; Biological material, e.g. blood, urine ; Haemocytometers; Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing; Immunoassay; Biospecific binding assay; Materials therefor for microorganisms, e.g. protozoa, bacteria, viruses Viruses
G01N33/57411 » CPC further
Investigating or analysing materials by specific methods not covered by groups -; Biological material, e.g. blood, urine ; Haemocytometers; Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing; Immunoassay; Biospecific binding assay; Materials therefor for cancer; Specifically defined cancers of cervix
G01N33/5748 » CPC further
Investigating or analysing materials by specific methods not covered by groups -; Biological material, e.g. blood, urine ; Haemocytometers; Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing; Immunoassay; Biospecific binding assay; Materials therefor for cancer involving oncogenic proteins
C07K2317/33 » CPC further
Immunoglobulins specific features characterized by aspects of specificity or valency Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
C07K2317/34 » CPC further
Immunoglobulins specific features characterized by aspects of specificity or valency Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
C07K2317/92 » CPC further
Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
G01N2333/025 » CPC further
Assays involving biological materials from specific organisms or of a specific nature from viruses; DNA viruses Papovaviridae, e.g. papillomavirus, polyomavirus, SV40, BK virus, JC virus
C12Q1/70 IPC
Measuring or testing processes involving enzymes, nucleic acids or microorganisms ; Compositions therefor; Processes of preparing such compositions involving virus or bacteriophage
C12M1/00 IPC
Apparatus for enzymology or microbiology
Description
CROSS-REFERENCE
This application is a continuation application of Ser. No. 11/021,949, filed Dec. 23, 2004, which claims the benefit of U.S. provisional patent application Ser. No. 60/532,373, filed Dec. 23, 2003, which applications are incorporated herein by reference in their entirety.
FIELD OF INVENTION
The present invention relates to detection of oncogenic strains of human papillomavirus (HPV).
BACKGROUND OF THE INVENTION
Cervical cancer is the second most common cancer diagnosis in women and is linked to high-risk human papillomavirus infection 99.7% of the time. Currently, 12,000 new cases of invasive cervical cancer are diagnosed in US women annually, resulting in 5,000 deaths each year. Furthermore, there are approximately 400,000 cases of cervical cancer and close to 200,000 deaths annually worldwide. Human papillomaviruses (HPVs) are one of the most common causes of sexually transmitted disease in the world. Overall, 50-75% of sexually active men and women acquire genital HPV infections at some point in their lives. An estimated 5.5 million people become infected with HPV each year in the US alone, and at least 20 million are currently infected. The more than 100 different isolates of HPV have been broadly subdivided into high-risk and low-risk subtypes based on their association with cervical carcinomas or with benign cervical lesions or dysplasias.
A number of lines of evidence point to HPV infections as the etiological agents of cervical cancers. Multiple studies in the 1980's reported the presence of HPV variants in cervical dysplasias, cancer, and in cell lines derived from cervical cancer. Further research demonstrated that the E6-E7 region of the genome from oncogenic HPV 18 is selectively retained in cervical cancer cells, suggesting that HPV infection could be causative and that continued expression of the E6-E7 region is required for maintenance of the immortalized or cancerous state. Further research demonstrated that the E6-E7 genes from HPV 16 were sufficient to immortalize human keratinocytes in culture. It was also demonstrated that although E6-E7 genes from high risk HPVs could transform cell lines, the E6-E7 regions from low risk, or non-oncogenic variants such as HPV 6 and HPV 111 were unable to transform human keratinocytes. HPV 16 and 18 infection was examined by in situ hybridization and E6 protein expression by immunocytochemistry in 623 cervical tissue samples at various stages of tumor progression and found a significant correlation between histological abnormality and HPV infection.
A significant unmet need exists for early and accurate diagnosis of oncogenic HPV infection as well as for treatments directed at the causative HPV infection, preventing the development of cervical cancer by intervening earlier in disease progression. Human papillomaviruses characterized to date are associated with lesions confined to the epithelial layers of skin, or oral, pharyngeal, respiratory, and, most importantly, anogenital mucosae. Specific human papillomavirus types, including HPV 6 and 11, frequently cause benign mucosal lesions, whereas other types such as HPV 16, 18, and a host of other strains, are predominantly found in high-grade lesions and cancer. Individual types of human papillomaviruses (HPV) which infect mucosal surfaces have been implicated as the causative agents for carcinomas of the cervix, breast (Yu et al. (1999) Anticancer Res. 19:55555057-5061; Liu et al. (2001) J. Hum. Virol. 44:329-334), anus, penis, prostate (De Villiers et al. (1989) Virology 171:248:253), larynx and the buccal cavity, tonsils (Snijders et al. (1994) J. Gen. Virol. 75(Pt 10):2769-2775), nasal passage (Trujillo et al. (1996) Virus Genes 12:165-178; Wu et al. (1993) Lancet 341:522-524), skin (Trenfield et al. (1993) Australas. J. Dermatol. 34:71-78), bladder (Baithun et al. (1998) Cancer Surv. 31:17-27), head and neck squamous-cell carcinomas (Braakhuis et al. (2004) J. Natl. Cancer Inst. 96:978-980), occasional periungal carcinomas, as well as benign anogenital warts. The identification of particular HPV types is used for identifying patients with premalignant lesions who are at risk of progression to malignancy. Although visible anogenital lesions are present in some persons infected with human papillomavirus, the majority of individuals with HPV genital tract infection do not have clinically apparent disease, but analysis of cytomorphological traits present in cervical smears can be used to detect HPV infection. Papanicolaou tests are a valuable screening tool, but they miss a large proportion of HPV-infected persons due to the unfortunate false positive and false negative test results. In addition, they are not amenable to worldwide testing because interpretation of results requires trained pathologists.
HPV infection is also associated with Netherton's syndrome (Weber et al. (2001) Br. J. Dermatol. 144:1044-1049) and epidermolysis verruciformis (Rubaie et al. (1998) Int. J. Dermatol. 37:766-771). HPV can also be transmitted to a fetus by the mother (Smith et al. (2004) Sex. Transm. Dis. 31:57-62; Xu et al. (1998) Chin. Med. Sci. J. 13:29-31; Cason et al. (1998) Intervirology 41:213-218).
The detection and diagnosis of disease is a prerequisite for the treatment of disease. Numerous markers and characteristics of diseases have been identified and many are used for the diagnosis of disease. Many diseases are preceded by, and are characterized by, changes in the state of the affected cells. Changes can include the expression of pathogengenes or proteins in infected cells, changes in the expression patterns of genes or proteins in affected cells, and changes in cell morphology. The detection, diagnosis, and monitoring of diseases can be aided by the accurate assessment of these changes. Inexpensive, rapid, early and accurate detection of pathogens can allow treatment and prevention of diseases that range in effect from discomfort to death.
Literature
Literature of interest includes the following references: Zozulya et al., (Genome Biology 2:0018.1-0018.12, 2001; Mombairts (Annu. Rev. Neurosci 22:487-509, 1999); Raming et al., (Nature 361: 353-356, 1993); Belluscio et al., (Neuron 20: 69-81, 1988); Ronnet et al., (Annu. Rev. Physiol. 64:189-222, 2002); Lu et al., (Traffic 4: 416-533, 2003); Buck (Cell 100:611-618, 2000); Malnic et al., (Cell 96:713-723, 1999); Firestein (Nature 413:211-218, 2001); Zhao et al., (Science 279: 237-242, 1998); Touhara et al., (Proc. Natl. Acad. Sci. 96: 4040-4045, 1999); Sklar et al., (J. Biol. Chem. 261:15538-15543, 1986); Dryer et al., (TiPS 20:413-417, 1999); Ivic et al., (J. Neurobiol. 50:56-68, 2002); Munger (2002) Front. Biosci. 7:d641-9; Glaunsinger (2000) Oncogene 19:5270-80; Gardiol (1999) Oncogene 18:5487-96; Pim (1999) Oncogene 18:7403-8; Meschede (1998) J. Clin. Microbiol. 36:475-80; Kiyono (1997) Proc. Natl. Acad. Sci. 94:11612-6; and Lee (1997) Proc. Natl. Acad. Sci. 94:6670-5; Banks (1987) J. Gen. Virol. 68:1351-1359; Fuchs et al., (Hum. Genet. 108:1-13, 2001); and Giovane et al. (1999) Journal of Molecular Recognition. 12:141-152 and published US patent applications 20030143679 and 20030105285; and U.S. Pat. Nos. 6,610,511, 6,492,143 6,410,249, 6,322,794, 6,344,314, 5,415,995, 5,753,233, 5,876,723, 5,648,459, 6,391,539, 5,665,535 and 4,777,239.
SUMMARY OF THE INVENTION
The subject invention provides antibodies, including polyclonal and monoclonal antibodies, that bind to the E6 proteins from at least three different oncogenic strains of HPV. In general, the antibodies bind to amino acids motifs that are conserved between the E6 proteins of different HPV strains, particularly HPV strains 16 and 18. The subject antibodies may be used to detect HPV E6 protein in a sample, and, accordingly, the antibodies find use in a variety of diagnostic applications, including methods of diagnosing cancer. Kits for performing the subject methods and containing the subject antibodies are also provided.
In certain embodiments, the invention provides an antibody composition comprising a monoclonal antibody that specifically binds to the E6 proteins of at least three (e.g., 4, 5, 6, 7 or 8 or more, usually up to 10 or 12) different oncogenic HPV strains. The antibody composition may comprise a mixture of monoclonal antibodies that specifically bind to the E6 proteins of HPV strains 16, 18, 31, 33 and 45 (e.g., HPV strains 16, 18, 31, 33, 45, 52 and 58, HPV strains 16, 18, 31, 33, 45, 52, 58, 35 and 59 or HPV strains 16, 18, 26, 30, 31, 33, 34, 45, 51, 52, 53, 58, 59, 66, 68b, 69, 70, 73 and 82, wherein at least one of said monoclonal antibodies specifically binds to the E6 proteins of at least three different oncogenic HPV strains. In certain embodiments, the monoclonal antibody may bind to the E6 proteins of HPV strains 16 and 18, wherein said antibody binds SEQ ID NOS: 1, 3 or 5 of HPV strain 16 E6 and SEQ ID NOS: 2, 4 or 6 of HPV strain 18 E6. In certain embodiments, the monoclonal antibody binds to E6 proteins of HPV strains 16 and 45 or HPV strains 16, 18, 31, 33 and 45.
The invention also provides a method of detecting an HPV E6 protein in a sample. This methods generally involves contacting the subject antibody composition with the sample, and detecting any binding of the antibodies in the composition to the sample, wherein binding of an antibody to the sample indicates the presence of an HPV E6 protein. The sample may be suspected of containing an oncogenic strain of HPV.
The invention also provides a system for detecting the presence of an oncogenic HPV E6 polypeptide in a sample. This system generally comprises a first and a second binding partner for an oncogenic HPV E6 polypeptide, wherein the first binding partner is a PDZ domain protein and said second binding partner is an subject antibody. At least one of said binding partners is attached to a solid support.
The invention also provides a method of detecting the presence of an oncogenic HPV E6 protein in a sample. This method generally comprises: contacting a sample containing an oncogenic HPV E6 protein with a PDZ domain polypeptide; and detecting any binding of the oncogenic HPV E6 protein in said sample to said PDZ domain polypeptide using an subject antibody, wherein binding of the oncogenic HPV E6 protein to said PDZ domain polypeptide indicates the presence of an oncogenic HPV E6 protein in said sample.
The invention also provides a kit containing a subject antibody; and instructions for using the antibody to detect a HPV E6 protein. The kit may also contain a PDZ domain polypeptide.
The invention also provides a peptide of less than 15 amino acids comprising any one of the sequences set forth in Table 1.
INCORPORATION BY REFERENCE
All publications, patents, and patent applications mentioned in this specification are herein incorporated by reference to the same extent as if each individual publication, patent, or patent application was specifically and individually indicated to be incorporated by reference.
BRIEF DESCRIPTION OF THE DRAWINGS
The novel features of the invention are set forth with particularity in the appended claims. A better understanding of the features and advantages of the present invention will be obtained by reference to the following detailed description that sets forth illustrative embodiments, in which the principles of the invention are utilized, and the accompanying drawings of which:
FIG. 1 is an alignment of E6 amino acid sequences from various oncogenic strains of HPV. From top to bottom, the various HPV E6 amino acid sequences are set forth in the sequence listing as SEQ ID NOS: 13-32, respectively. Amino acid sequence from three other oncogenic strains of HPV (strains 34, 67 and 70) are found in the sequence listing as SEQ ID NOS: 359-361.
FIG. 2 is an alignment of E6 amino acid sequences from a subset of oncogenic strains of HPV shown in FIG. 1.
FIG. 3 is a slot western blot showing antibody reactivity with E6 protein.
FIG. 4 is graph showing cross-reactivity of F22-10D11 monoclonal antibody.
DEFINITIONS
Before the present invention is further described, it is to be understood that this invention is not limited to particular embodiments described, as such may of course vary. It is also to be understood that the terminology used herein is for the purpose of describing particular embodiments only, and is not intended to be limiting. Unless defined otherwise, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs.
Where a range of values is provided, it is understood that each intervening value, to the tenth of the unit of the lower limit unless the context clearly dictates otherwise, between the upper and lower limit of that range and any other stated or intervening value in that stated range, is encompassed within the invention. The upper and lower limits of these smaller ranges may independently be included in the smaller ranges, and are also encompassed within the invention, subject to any specifically excluded limit in the stated range. Where the stated range includes one or both of the limits, ranges excluding either or both of those included limits are also included in the invention.
Throughout this application, various publications, patents and published patent applications are cited. The disclosures of these publications, patents and published patent applications referenced in this application are hereby incorporated by reference in their entirety into the present disclosure. Citation herein by Applicant of a publication, patent, or published patent application is not an admission by Applicant of said publication, patent, or published patent application as prior art.
It must be noted that as used herein and in the appended claims, the singular forms “a”, “and”, and “the” include plural referents unless the context clearly dictates otherwise. Thus, for example, reference to “a sample” includes a plurality of such sample, and reference to “the antibody” includes reference to one or more antibodies and equivalents thereof known to those skilled in the art, and so forth. It is further noted that the claims may be drafted to exclude any optional element. As such, this statement is intended to serve as antecedent basis for use of such exclusive terminology as “solely”, “only” and the like in connection with the recitation of claim elements, or the use of a “negative” limitation.
A “biopolymer” is a polymer of one or more types of repeating units, regardless of the source. Biopolymers may be found in biological systems and particularly include polypeptides and polynucleotides, as well as such compounds containing amino acids, nucleotides, or analogs thereof. The term “polynucleotide” refers to a polymer of nucleotides, or analogs thereof, of any length, including oligonucleotides that range from 10-100 nucleotides in length and polynucleotides of greater than 100 nucleotides in length. The term “polypeptide” refers to a polymer of amino acids of any length, including peptides that range from 6-50 amino acids in length and polypeptides that are greater than about 50 amino acids in length.
In most embodiments, the terms “polypeptide” and “protein” are used interchangeably. The term “polypeptide” includes polypeptides in which the conventional backbone has been replaced with non-naturally occurring or synthetic backbones, and peptides in which one or more of the conventional amino acids have been replaced with a non-naturally occurring or synthetic amino acid capable of participating in peptide bonding interactions. The term “fusion protein” or grammatical equivalents thereof is meant a protein composed of a plurality of polypeptide components, that while typically not attached in their native state, typically are joined by their respective amino and carboxyl termini through a peptide linkage to form a single continuous polypeptide. Fusion proteins may be a combination of two, three or even four or more different proteins. The term polypeptide includes fusion proteins, including, but not limited to, fusion proteins with a heterologous amino acid sequence, fusions with heterologous and homologous leader sequences, with or without N-terminal methionine residues; immunologically tagged proteins; fusion proteins with detectable fusion partners, e.g., fusion proteins including as a fusion partner a fluorescent protein, β-galactosidase, luciferase, etc., and the like.
In general, polypeptides may be of any length, e.g., greater than 2 amino acids, greater than 4 amino acids, greater than about 10 amino acids, greater than about 20 amino acids, greater than about 50 amino acids, greater than about 100 amino acids, greater than about 300 amino acids, usually up to about 500 or 1000 or more amino acids. “Peptides” are generally greater than 2 amino acids, greater than 4 amino acids, greater than about 10 amino acids, greater than about 20 amino acids, usually up to about 50 amino acids. In some embodiments, peptides are between 5 and 30 or between 8 and 15 amino acids in length.
The term “capture agent” refers to an agent that binds an analyte through an interaction that is sufficient to permit the agent to bind and concentrate the analyte from a homogeneous mixture of different analytes. The binding interaction is typically mediated by an affinity region of the capture agent. Typical capture agents include any polypeptide, e.g., a PDZ protein, however antibodies may be employed. Capture agents usually “specifically bind” one or more analytes, e.g., an oncogenic E6 protein. Accordingly, the term “capture agent” refers to a molecule or a multi-molecular complex which can specifically bind an analyte, e.g., specifically bind an analyte for the capture agent, with a dissociation constant (KD) of less than about 10−6 M without binding to other targets.
The term “specific binding” refers to the ability of a capture agent to preferentially bind to a particular analyte that is present in a homogeneous mixture of different analytes. Typically, a specific binding interaction will discriminate between desirable and undesirable analytes in a sample, typically more than about 10 to 100-fold or more (e.g., more than about 1000- or 10,000-fold). Typically, the affinity between a capture agent and analyte when they are specifically bound in a capture agent/analyte complex is at least 10−7, at least 10−8 M, at least 10−9 M, usually up to about 10−10 M.
The term “capture agent/analyte complex” is a complex that results from the specific binding of a capture agent with an analyte, i.e., a “binding partner pair”. A capture agent and an analyte for the capture agent will typically specifically bind to each other under “conditions suitable to for specific binding”, where such conditions are those conditions (in terms of salt concentration, pH, detergent, protein concentration, temperature, etc.) which allow for binding to occur between capture agents and analytes to bind in solution. Such conditions, particularly with respect to antibodies and their antigens, are well known in the art (see, e.g., Harlow and Lane (Antibodies. A Laboratory Manual Cold Spring Harbor Laboratory, Cold Spring Harbor, N.Y. (1989)). Conditions suitable for specific binding typically permit capture agents and target pairs that have a dissociation constant (KD) of less than about 10−6 M to bind to each other, but not with other capture agents or targets.
As used herein, “binding partners” and equivalents refer to pairs of molecules that can be found in a capture agent/analyte complex, i.e., exhibit specific binding with each other.
The phrase “surface-bound capture agent” refers to a capture agent that is immobilized on a surface of a solid substrate, where the substrate can have a variety of configurations, e.g., a sheet, bead, strip, or other structure, such as a plate with wells.
The term “pre-determined” refers to an element whose identity is known prior to its use. For example, a “pre-determined analyte” is an analyte whose identity is known prior to any binding to a capture agent. An element may be known by name, sequence, molecular weight, its function, or any other attribute or identifier. In some embodiments, the term “analyte of interest”, i.e., an known analyte that is of interest, is used synonymously with the term “pre-determined analyte”.
The terms “antibody” and “immunoglobulin” are used interchangeably herein to refer to a type capture agent that has at least an epitope binding domain of an antibody. These terms are well understood by those in the field, and refer to a protein containing one or more polypeptides that specifically binds an antigen. One form of antibody constitutes the basic structural unit of an antibody. This form is a tetramer and consists of two identical pairs of antibody chains, each pair having one light and one heavy chain. In each pair, the light and heavy chain variable regions are together responsible for binding to an antigen, and the constant regions are responsible for the antibody effector functions.
The recognized immunoglobulin polypeptides include the kappa and lambda light chains and the alpha, gamma (IgG1, IgG2, IgG3, IgG4), delta, epsilon and mu heavy chains or equivalents in other species. Full-length immunoglobulin “light chains” (of about 25 kDa or about 214 amino acids) comprise a variable region of about 110 amino acids at the NH2-terminus and a kappa or lambda constant region at the COOH-terminus. Full-length immunoglobulin “heavy chains” (of about 50 kDa or about 446 amino acids), similarly comprise a variable region (of about 116 amino acids) and one of the aforementioned heavy chain constant regions, e.g., gamma (of about 330 amino acids).
The terms “antibodies” and “immunoglobulin” include antibodies or immunoglobulins of any isotype, fragments of antibodies which retain specific binding to antigen, including, but not limited to, Fab, Fv, scFv, and Fd fragments, chimeric antibodies, humanized antibodies, single-chain antibodies, and fusion proteins comprising an antigen-binding portion of an antibody and a non-antibody protein. The antibodies may be detectably labeled, e.g., with a radioisotope, an enzyme which generates a detectable product, a fluorescent protein, and the like. The antibodies may be further conjugated to other moieties, such as members of specific binding pairs, e.g., biotin (member of biotin-avidin specific binding pair), and the like. The antibodies may also be bound to a solid support, including, but not limited to, polystyrene plates or beads, and the like. Also encompassed by the terms are Fab′, Fv, F(ab′)2, and or other antibody fragments that retain specific binding to antigen.
Antibodies may exist in a variety of other forms including, for example, Fv, Fab, and (Fab′)2, as well as bi-functional (i.e. bi-specific) hybrid antibodies (e.g., Lanzavecchia et al., Eur. J. Immunol. 17, 105 (1987)) and in single chains (e.g., Huston et al., Proc. Natl. Acad. Sci. U.S.A., 85, 5879-5883 (1988) and Bird et al., Science, 242, 423-426 (1988), which are incorporated herein by reference). (See, generally, Hood et al, Immunology, Benjamin, N.Y., 2nd ed. (1984), and Hunkapiller and Hood, Nature, 323, 15-16 (1986). Monoclonal antibodies, polyclonal antibodies, and “phage display” antibodies are well known in the art and encompassed by the term “antibodies”.
The term “mixture”, as used herein, refers to a combination of elements, e.g., capture agents or analytes, that are interspersed and not in any particular order. A mixture is homogeneous and not spatially separable into its different constituents. Examples of mixtures of elements include a number of different elements that are dissolved in the same aqueous solution, or a number of different elements attached to a solid support at random or in no particular order in which the different elements are not specially distinct. In other words, a mixture is not addressable. To be specific, an array of capture agents, as is commonly known in the art, is not a mixture of capture agents because the species of capture agents are spatially distinct and the array is addressable.
“Isolated” or “purified” general refers to isolation of a substance (compound, polynucleotide, protein, polypeptide, polypeptide composition) such that the substance comprises the majority percent of the sample in which it resides. Typically in a sample a substantially purified component comprises 50%, preferably 80%-85%, more preferably 90-95% of the sample. Techniques for purifying polynucleotides and polypeptides, e.g., antibodies, of interest are well-known in the art and include, for example, ion-exchange chromatography, affinity chromatography and sedimentation according to density.
The term “assessing” refers to any form of measurement, and includes determining if an element is present or not. The terms “determining”, “measuring”, “evaluating”, “assessing” and “assaying” are used interchangeably and include both quantitative and qualitative determinations. Assessing may be relative or absolute. “Assessing the presence of” includes determining the amount of something present, as well as determining whether it is present or absent.
The term “marker” or “biological marker”, as used herein, refers to a measurable or detectable entity in a biological sample. Examples or markers include nucleic acids, proteins, or chemicals that are present in biological samples. One example of a marker is the presence of viral or pathogen proteins or nucleic acids in a biological sample from a human source.
The term “sample” as used herein relates to a material or mixture of materials, typically, although not necessarily, in fluid form, i.e., aqueous, containing one or more components of interest. Samples may be derived from a variety of sources such as from food stuffs, environmental materials, a biological sample or solid, such as tissue or fluid isolated from an individual, including but not limited to, for example, plasma, serum, spinal fluid, semen, lymph fluid, the external sections of the skin, respiratory, intestinal, and genitourinary tracts, tears, saliva, milk, blood cells, tumors, organs, and also samples of in vitro cell culture constituents (including but not limited to conditioned medium resulting from the growth of cells in cell culture medium, putatively virally infected cells, recombinant cells, and cell components). The term “biological sample” is meant to distinguish between a sample in a clinical setting from a sample that may be a recombinant sample or derived from a recombinant sample.
Components in a sample are termed “analytes” herein. In many embodiments, the sample is a complex sample containing at least about 102, 5×102, 103, 5×103, 104, 5×104, 105, 5×105, 106, 5×106, 107, 5×107, 103, 109, 1010, 1011, 1012 or more species of analyte.
The term “analyte” is used herein interchangeably and refers to a known or unknown component of a sample, which will specifically bind to a capture agent if the analyte and the capture agent are members of a specific binding pair. In general, analytes are biopolymers, i.e., an oligomer or polymer such as an oligonucleotide, a peptide, a polypeptide, an antibody, or the like. In this case, an “analyte” is referenced as a moiety in a mobile phase (typically fluid), to be detected by a “capture agent” which, in some embodiments, is bound to a substrate, or in other embodiments, is in solution. However, either of the “analyte” or “capture agent” may be the one which is to be evaluated by the other (thus, either one could be an unknown mixture of analytes, e.g., polypeptides, to be evaluated by binding with the other).
A “fusion protein” or “fusion polypeptide” as used herein refers to a composite protein, i.e., a single contiguous amino acid sequence, made up of two (or more) distinct, heterologous polypeptides that are not normally fused together in a single amino acid sequence. Thus, a fusion protein can include a single amino acid sequence that contains two entirely distinct amino acid sequences or two similar or identical polypeptide sequences, provided that these sequences are not normally found together in the same configuration in a single amino acid sequence found in nature. Fusion proteins can generally be prepared using either recombinant nucleic acid methods, i.e., as a result of transcription and translation of a recombinant gene fusion product, which fusion comprises a segment encoding a polypeptide of the invention and a segment encoding a heterologous protein, or by chemical synthesis methods well known in the art.
An “oncogenic HPV strain” is an HPV strain that is known to cause cervical cancer as determined by the National Cancer Institute (NCI, 2001). “Oncogenic E6 proteins” are E6 proteins encoded by the above oncogenic HPV strains. The sequences of exemplary oncogenic E6 proteins of interest are shown in FIG. 1. The sequences of various HPV proteins are also found as database entries at NCBI's Genbank database, as follows: HPV16-E6: GI:9627100; HPV18-E6: GI:9626069; HPV31-E6: GI:9627109; HPV35-E6: GI:9627127; HPV30-E6: GI:9627320; HPV39-E6: GI:9627165; HPV45-E6: GI:9627356; HPV51-E6: GI:9627155; HPV52-E6: GI:9627370; HPV56-E6: GI:9627383; HPV59-E6: GI:9627962; HPV58-E6: GI:9626489; HPV33-E6: GI:9627118; HPV66-E6: GI:9628582; HPV68b-E6: GI:184383; HPV69-E6: GI:9634605; HPV26-E6: GI:396956; HPV53-E6: GI:9627377; HPV73: GI:1491692; HPV82: GI:9634614, HPV34 GI:396989; HPV67 GI:3228267; and HPV70 GI:11173493.
An “oncogenic E6 protein binding partner” can be any molecule that specifically binds to an oncogenic E6 protein. Suitable oncogenic E6 protein binding partners include a PDZ domain (as described below), antibodies against oncogenic E6 proteins (such as those described below); other proteins that recognize oncogenic E6 protein (e.g., p53, E6-AP or E6-BP); DNA (i.e., cruciform DNA); and other partners such as aptamers. In some embodiments, detection of more than 1 oncogenic E6 protein (e.g., all oncogenic E6 proteins, E6 proteins from HPV strains 16 and 18, or E6 proteins from HPV strains 16 and 45 etc.) is desirable, and, as such, an oncogenic E6 protein binding partner may be antibody that binds to these proteins, as described below, or a mixture of antibodies that each bind to a different proteins. As is known in the art, such binding partners may be labeled to facilitate their detection. In general, binding partner bind E6 with an binding affinity of less then 10−5 M, e.g., less than 10−6, less than 10−7, less than 10−8 M (e.g., less than 10−9 M, 10−10, 10−11, etc.).
As used herein, the term “PDZ domain” refers to protein sequence of less than approximately 90 amino acids, (i.e., about 80-90, about 70-80, about 60-70 or about 50-60 amino acids), characterized by homology to the brain synaptic protein PSD-95, the Drosophila septate junction protein Discs-Large (DLG), and the epithelial tight junction protein ZO1 (ZO1). PDZ domains are also known as Discs-Large homology repeats (“DHRs”) and GLGF repeats. PDZ domains generally appear to maintain a core consensus sequence (Doyle, D. A., 1996, Cell 85: 1067-76).
PDZ domains are found in diverse membrane-associated proteins including members of the MAGUK family of guanylate kinase homologs, several protein phosphatases and kinases, neuronal nitric oxide synthase, tumor suppressor proteins, and several dystrophin-associated proteins, collectively known as syntrophins.
Exemplary PDZ domain-containing proteins and PDZ domain sequences are shown in TABLE 2. The term “PDZ domain” also encompasses variants (e.g., naturally occurring variants) of the sequences (e.g., polymorphic variants, variants with conservative substitutions, and the like) and domains from alternative species (e.g. mouse, rat). Typically, PDZ domains are substantially identical to those shown in U.S. patent application Ser. Nos. 09/724,553 and 10/938,249), e.g., at least about 70%, at least about 80%, or at least about 90% amino acid residue identity when compared and aligned for maximum correspondence. It is appreciated in the art that PDZ domains can be mutated to give amino acid changes that can strengthen or weaken binding and to alter specificity, yet they remain PDZ domains (Schneider et al., 1998, Nat. Biotech. 17:170-5). Unless otherwise indicated, a reference to a particular PDZ domain (e.g. a MAGI-1 domain 2) is intended to encompass the particular PDZ domain and HPV E6-binding variants thereof. In other words, if a reference is made to a particular PDZ domain, a reference is also made to variants of that PDZ domain that bind oncogenic E6 protein of HPV, as described below. In this respect it is noted that the numbering of PDZ domains in a protein may change. For example, the MAGI-1 domain 2, as referenced herein, may be referenced as MAGI-1 domain 1 in other literature. As such, when a particular PDZ domain of a protein is referenced in this application, this reference should be understood in view of the sequence of that domain, as described herein, particularly in the sequence listing. Table 2 shows the relationship between the sequences of the sequence listing and the names and Genbank accession numbers for various domains, where appropriate. Further description of PDZ proteins, particularly a description of MAGI-1 domain 2 protein, is found in Ser. No. 10/630,590, filed Jul. 29, 2003 and published as US20040018487. This publication is incorporated by reference herein in its entirety for all purposes.
As used herein, the term “PDZ protein” refers to a naturally occurring protein containing a PDZ domain. Exemplary PDZ proteins include CASK, MPP1, DLG1, DLG2, PSD95, NeDLG, TIP-33, SYN1a, TIP-43, LDP, LIM, LIMK1, LIMK2, MPP2, NOS1, AF6, PTN-4, prIL16, 41.8 kD, KIAA0559, RGS12, KIAA0316, DVL1, TIP40, TIAM1, MINT1, MAGI-1, MAGI-2, MAGI-3, KIAA0303, CBP, MINT3, TIP-2, KIAA0561, and TIP-1.
As used herein, the term “PL protein” or “PDZ Ligand protein” refers to a protein that forms a molecular complex with a PDZ-domain, or to a protein whose carboxy-terminus, when expressed separately from the full length protein (e.g., as a peptide fragment of 4-25 residues, e.g., 8, 10, 12, 14 or 16 residues), forms such a molecular complex. The molecular complex can be observed in vitro using a variety of assays described infra.
As used herein, a “PL sequence” refers to the amino acid sequence of the C-terminus of a PL protein (e.g., the C-terminal 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 14, 16, 20 or 25 residues) (“C-terminal PL sequence”) or to an internal sequence known to bind a PDZ domain (“internal PL sequence”).
As used herein, a “PL fusion protein” is a fusion protein that has a PL sequence as one domain, typically as the C-terminal domain of the fusion protein. An exemplary PL fusion protein is a tat-PL sequence fusion.
In the case of the PDZ domains described herein, a “HPV E6-binding variant” of a particular PDZ domain is a PDZ domain variant that retains HPV E6 PDZ ligand binding activity. Assays for determining whether a PDZ domain variant binds HPV E6 are described in great detail below, and guidance for identifying which amino acids to change in a specific PDZ domain to make it into a variant may be found in a variety of sources. In one example, a PDZ domain may be compared to other PDZ domains described herein and amino acids at corresponding positions may be substituted, for example. In another example, the sequence a PDZ domain of a particular PDZ protein may be compared to the sequence of an equivalent PDZ domain in an equivalent PDZ protein from another species. For example, the sequence of a PDZ domain from a human PDZ protein may be compared to the sequence of other known and equivalent PDZ domains from other species (e.g., mouse, rat, etc.) and any amino acids that are variant between the two sequences may be substituted into the human PDZ domain to make a variant of the PDZ domain. For example, the sequence of the human MAGI-1 PDZ domain 2 may be compared to equivalent MAGI-1 PDZ domains from other species (e.g. mouse Genbank gi numbers 7513782 and 28526157 or other homologous sequences) to identify amino acids that may be substituted into the human MAGI-1-PDZ domain to make a variant thereof. Such method may be applied to any of the MAGI-1 PDZ domains described herein. Minimal MAGI-PDZ domain 2 sequence is provided as SEQ ID NOS:68-76. Particular variants may have 1, up to 5, up to about 10, up to about 15, up to about 20 or up to about 30 or more, usually up to about 50 amino acid changes as compared to a sequence set forth in the sequence listing. Exemplary MAGI-1 PDZ variants include the sequences set forth in SEQ ID NOS: 76-105. In making a variant, if a GFG motif is present in a PDZ domain, in general, it should not be altered in sequence.
In general, variant PDZ domain polypeptides have a PDZ domain that has at least about 70 or 80%, usually at least about 90%, and more usually at least about 98% sequence identity with a variant PDZ domain polypeptide described herein, as measured by BLAST 2.0 using default parameters, over a region extending over the entire PDZ domain.
As used herein, a “detectable label” has the ordinary meaning in the art and refers to an atom (e.g., radionuclide), molecule (e.g., fluorescein), or complex, that is or can be used to detect (e.g., due to a physical or chemical property), indicate the presence of a molecule or to enable binding of another molecule to which it is covalently bound or otherwise associated. The term “label” also refers to covalently bound or otherwise associated molecules (e.g., a biomolecule such as an enzyme) that act on a substrate to produce a detectable atom, molecule or complex. Detectable labels suitable for use in the present invention include any composition detectable by spectroscopic, photochemical, biochemical, immunochemical, electrical, optical or chemical means. Labels useful in the present invention include biotin for staining with labeled streptavidin conjugate, magnetic beads (e.g., Dynabeads™), fluorescent dyes (e.g., fluorescein, Texas red, rhodamine, green fluorescent protein, enhanced green fluorescent protein, and the like), radiolabels (e.g., 3H, 125I, 35S, 14C, or 32P), enzymes (e.g., hydrolases, particularly phosphatases such as alkaline phosphatase, esterases and glycosidases, or oxidoreductases, particularly peroxidases such as horse radish peroxidase, and others commonly used in ELISAs), substrates, cofactors, inhibitors, chemiluminescent groups, chromogenic agents, and colorimetric labels such as colloidal gold or colored glass or plastic. (e.g., polystyrene, polypropylene, latex, etc.) beads. Patents disclosing such labels include U.S. Pat. Nos. 3,817,837; 3,850,752; 3,939,350; 3,996,345; 4,277,437; 4,275,149; and 4,366,241. Means of detecting such labels are well known to those of skill in the art.
As used herein, the terms “sandwich”, “sandwich ELISA”, “Sandwich diagnostic” and “capture ELISA” all refer to the concept of detecting a biological polypeptide with two different test agents. For example, a PDZ protein could be directly or indirectly attached to a solid support. Test sample could be passed over the surface and the PDZ protein could bind its cognate PL protein(s). A labeled antibody or alternative detection reagent could then be used to determine whether a specific PL protein had bound the PDZ protein.
By “solid phase support” or “carrier” is intended any support capable of binding polypeptide, antigen or antibody. Well-known supports or carriers, include glass, polystyrene, polypropylene, polyethylene, dextran, nylon, amylases, natural and modified celluloses, polyacrylamides, agaroses, and magnetite. The nature of the carrier can be either soluble to some extent or insoluble for the purposes of the present invention. The support material can have virtually any possible structural configuration so long as the coupled molecule is capable of binding to a PDZ domain polypeptide or an E6 antibody. Thus, the support configuration can be spherical, as in a bead, or cylindrical, as in the inside surface of a test tube, or the external surface of a rod. Alternatively, the surface can be flat, such as a sheet, culture dish, test strip, etc. Those skilled in the art will know many other suitable carriers for binding antibody, peptide or antigen, or can ascertain the same by routine experimentation. In some embodiments “proteasome inhibitors”, i.e., inhibitors of the proteasome, may be used. These inhibitors, including carbobenzoxyl-leucinyl-leuciny-1 norvalinal II (MG 115) or CBZ-LLL, can be purchased from chemical supply companies (e.g., Sigma). As a skilled person would understand, proteasome inhibitors are not protease inhibitors.
As used herein, a “plurality” of components has its usual meaning. In some embodiments, the plurality is at least 5, and often at least 25, at least 40, or at least 60 or more, usually up to about 100 or 1000.
Reference to an “amount” of a E6 protein in these contexts is not intended to require quantitative assessment, and may be either qualitative or quantitative, unless specifically indicated otherwise.
The term “non-naturally occurring” or “recombinant” means artificial or otherwise not found in nature. Recombinant cells usually contain nucleic acid that is not usually found in that cell, recombinant nucleic acid usually contain a fusion of two or more nucleic acids that is not found in nature, and a recombinant polypeptide is usually produced by a recombinant nucleic acid.
“Subject”, “individual,” “host” and “patient” are used interchangeably herein, to refer to any animal, e.g., mammal, human or non-human. Generally, the subject is a mammalian subject. Exemplary subjects include, but are not necessarily limited to, humans, non-human primates, mice, rats, cattle, sheep, goats, pigs, dogs, cats, birds, deer, elk, rabbit, reindeer, deer, and horses, with humans being of particular interest.
DETAILED DESCRIPTION OF THE INVENTION
While preferred embodiments of the present invention have been shown and described herein, it will be obvious to those skilled in the art that such embodiments are provided by way of example only. Numerous variations, changes, and substitutions will now occur to those skilled in the art without departing from the invention. It should be understood that various alternatives to the embodiments of the invention described herein may be employed in practicing the invention. It is intended that the following claims define the scope of the invention and that methods and structures within the scope of these claims and their equivalents be covered thereby.
The subject invention provides antibodies, including polyclonal and monoclonal antibodies, that bind to E6 proteins from at least three oncogenic strains of HPV. In general, the antibodies bind to amino acid motifs that are conserved between the E6 proteins of different HPV strains, particularly HPV strains 16 and 18. The subject antibodies may be used to detect HPV E6 protein in a sample, and, accordingly, the antibodies find use in a variety of diagnostic applications, including methods of diagnosing cancer. Kits for performing the subject methods and containing the subject antibodies are also provided.
In further describing the invention in greater detail than provided in the Summary and as informed by the Background and Definitions provided above, the subject antibodies are described first, followed by a description of methods in which the subject antibodies find use. Finally, kits for performing the subject methods are described.
Antibody Compositions
The invention provides antibodies, particularly monoclonal antibodies, that bind to E6 proteins of multiple strains of HPV. In other words, the invention provides antibodies that “recognize”, i.e., specifically bind to with KD of 10−6 M or less, multiple E6 proteins. In other words, the subject antibodies each bind to (i.e., cross-react with) a plurality of different E6 proteins (i.e., at least 2, at least 3, at least 4, at least 5, at least 6 or at least 10, usually up to about 12, 15 or 20 or more different E6 proteins) from oncogenic, and, in certain embodiments, non-oncogenic strains of HPV. In general, the subject antibodies bind to amino acid motifs that are conserved between the E6 proteins of different HPV strains, and, accordingly, bind to E6 proteins that have this motif. In many embodiments the antibodies bind at least the E6 proteins of HPV strains 16 and 18 (e.g. the E6 proteins of HPV strains 16, 18, 31, 33 and 45; 16, 18 and 45; or, in other embodiments, the E6 proteins of all of the HPV strains listed in FIG. 1 or 2). In other embodiments, the antibodies bind to at least the E6 proteins from HPV strains 16 and 45. The subject antibodies may bind E6 protein from non-oncogenic strains of HPV (e.g., HPV strains 6 and/or 11) and, accordingly, the subject antibodies may bind to E6 proteins from oncogenic, as well as non-oncogenic, strains of HPV.
The subject antibodies may specifically bind to one of three sequence motifs found in HPV E6 proteins. These motifs are boxed in FIG. 1, and generally correspond to regions of sequence similarity, between E6 proteins from different strains of HPV. In general, therefore, a subject antibody binds to peptides having the following sequence: FQDPQERPRKLPQLCTELQTFIHDI (SEQ ID NO:1) and FEDPTRRPYKLPDLCTELNTSLQDI (SEQ ID NO:2), corresponding to a first common sequence motif in the E6 proteins of HPV strains 16 and 18, respectively, LLIRCINCQKPLCPEEKQRHLDK (SEQ ID NO:3) and LLIRCLRCQKPLNPAEKLRHLNE (SEQ ID NO:4), corresponding to a second common sequence motif in the E6 proteins of HPV strains 16 and 18, respectively, or RHLDKKQRFHNIRGRWTGRCMSCC (SEQ ID NO:5) and RHLNEKRRFHNIAGHYRGQCHSCC (SEQ ID NO:6) corresponding to a third common sequence motif in the E6 proteins of HPV strains 16 and 18, respectively. If a subject antibody binds to other E6 proteins, then it usually binds to the other E6 proteins at positions equivalent to those discussed above, or boxed in FIG. 1, where “positions equivalent to” generally means a stretch of contiguous amino acids that correspond to, i.e., are aligned with, the boxed amino acids when the sequence of the other E6 proteins are with those in FIG. 1.
Accordingly, since antibodies generally recognize motifs smaller than those listed above, a subject antibody may recognize peptides that are smaller than and contained within the motifs described above. For example, a subject antibody may bind to a peptide having any 9 contiguous amino acids set forth in any one of SEQ NOS: 1-6. In particular, a subject antibody may recognize the sequences RPRKLPQLCTEL (SEQ ID NO:7) and RPYKLPDLCTEL (SEQ ID NO:8), corresponding to sub-sequences of the first common sequences of E6 proteins of HPV strains 16 and 18, described above, LLIRCINCQKPL (SEQ ID NO:9) and LLIRCLRCQKPL (SEQ ID NO:10) corresponding to sub-sequences of the second common sequences of E6 proteins of HPV strains 16 and 18, as described above, or RHLDKKQRFHNI (SEQ ID NO:11) and RHLNEKRRFHNI (SEQ ID NO:12) corresponding to sub-sequences of the third common sequences of E6 proteins of HPV strains 16 and 18, as described above. Since these sub-sequences are generally conserved between different E6 proteins, as discussed above, antibodies that bind to the above-recited sequences generally bind to E6 proteins from other HPV strains.
In certain alternative embodiments, the subject antibodies will bind to E6 proteins from HPV strains 16 and 45. In general, therefore, a subject antibody binds to peptides having the following sequence: FQDPQERPRKLPQLCTELQTTIHDI (SEQ ID NO:1) and FDDPKQRPYKLPDLCTELNTSLQDV (SEQ ID NO:57), corresponding to a first common sequence motif in the E6 proteins of HPV strains 16 and 45, respectively, LLIRCINCQKPLCPEEKQRHLDK (SEQ ID NO:3) and LLIRCLRCQKPLNPAEKRRHLKD (SEQ ID NO: 58), corresponding to a second common sequence motif in the E6 proteins of HPV strains 16 and 45, respectively, or RHLDKKQRFHNIRGRWTGRCMSCC (SEQ ID NO:5) and RHLKDKRRFHSIAGQYRGQCNTCC (SEQ ID NO:59) corresponding to a third common sequence motif in the E6 proteins of HPV strains 16 and 45, respectively. If a subject antibody binds to other E6 proteins, then it usually binds to the other E6 proteins at positions equivalent to those discussed above, or boxed in FIG. 1. For example, the E6 proteins from HPV58, HPV33, HPV52, HPV31, HPV16, HPV18 and HPV45 are shown in FIG. 2, and the above-referenced motifs are boxed therein.
Accordingly, since antibodies generally recognize motifs smaller than those listed above, a subject antibody may recognize peptides that are smaller than and contained within the motifs described above. For example, a subject antibody may bind to a peptide having any 9 contiguous amino acids set forth in any one of SEQ NOS: 1, 3, 5, 57, 58 and 59. In particular, a subject antibody may recognize the sequences RPRKLPQLCTEL (SEQ ID NO:7) and RPYKLPDLCTEL (SEQ ID NO:60), corresponding to sub-sequences of the first common sequences of E6 proteins of HPV strains 16 and 45, described above, LLIRCINCQKPL (SEQ ID NO:9) and LLIRCLRCQKPL (SEQ ID NO: 61) corresponding to sub-sequences of the second common sequences of E6 proteins of HPV strains 16 and 45, as described above, or RHLDKKQRFHNI (SEQ ID NO:11) and RHLKDKRRFHSI (SEQ ID NO: 62) corresponding to sub-sequences of the third common sequences of E6 proteins of HPV strains 16 and 45, as described above. Since these sub-sequences are generally conserved between different E6 proteins, as discussed above, antibodies that bind to the above-recited sequences generally bind to E6 proteins from other HPV strains. In certain embodiments, cysteine residues can be replaced by serine residues to avoid disulfide bridge formation.
Methods for making antibodies, particular monoclonal antibodies, are well known in the art and described in various well known laboratory manuals (e.g., Harlow et al., Antibodies: A Laboratory Manual, First Edition (1988) Cold spring Harbor, N.Y.; Harlow and Lane, Using Antibodies: A Laboratory Manual, CSHL Press (1999) and Ausubel, et al., Short Protocols in Molecular Biology, 3rd ed., Wiley & Sons, (1995)). Accordingly, given the peptide sequences set forth above and in the accompanying tables, methods for making the subject antibodies do not need to be described herein in any great detail. Any fragment of a longer full-length E6 protein that contains a subject common motif (e.g., the full length protein), a full length E6 protein, or a fusion protein thereof may be used to make the subject antibodies. In certain embodiments, a full length E6 protein, a peptide containing a recited sequence, or a chemically modified (e.g., conjugated) derivative or fusion thereof (e.g., a MBP or GST fusion), may be used as an antigen. In certain embodiments, a nucleic acid encoding the polypeptide may be employed, or a mixture of different polypeptides (e.g., a mixture of E6 polypeptides, each polypeptide from a different HPV strain) may be used as an antigen (Michel (2002) Vaccine 20:A83-A88). Accordingly an antigen is mixed with an adjuvant, and a suitable non-human animal (e.g., a mouse, chicken, goat, rabbit, hamster, horse, rat or guinea pig, etc.) is immunized using standard immunization techniques (e.g., intramuscular injection) and once a specific immune response of the has been established, blood from the animal may be collected and polyclonal antisera that specifically binds to described peptides may be isolated. In many cases, cells from the spleen of the immunized animal are fused with a myeloma cell line, and, after fusion, the cells are grown in selective medium containing e.g., hypoxanthine, aminopterin, and thymidine (HAT), to select for hybridoma growth, and after 2-3 weeks, hybridoma colonies appear. Supernatants from these cultured hybridoma cells are screened for antibody secretion, usually by enzyme-linked immunosorbent assay (ELISA) or the like, and positive clones secreting monoclonal antibodies specific for the antigen can be selected and expanded according to standard procedures.
Exemplary peptides suitable for immunizations are described in Table 1. The peptides are shown as a “consensus” sequence (i.e. peptides in which one of several amino acids may exist at one or more positions) in order to indicate that any one or a mixture of different peptides that are described by the consensus could be used to make the subject antibodies. Accordingly, when a consensus sequence is described, every individual peptide that falls within the consensus should be considered explicitly described. In particular embodiments, exemplary species of peptide encompassed by the consensus sequences have a sequence found in a naturally-occurring HPV E6 protein, such as those described in FIG. 1. Such exemplary sequences can be identified as sequences starting at the amino acid positions defined by the third column of Table 1, “Starting AA” of particular HPV types “HPV type”, and corresponding positions of other HPV E6 proteins (i.e., those positions that are aligned with the positions indicated in Table 1).
Accordingly, peptides having 9, 10, 11, 12, 13, 14, 15 or more, usually up to about 20 or more contiguous amino acids of any of the peptides described above may be used for immunizations. In some embodiments, a recited peptide sequence may be contained within a larger peptide that may be 1, 2, 3, 4, 5, 6, 7, 8, 9 or 10 or more, sometimes up to about 15 or 20 or more amino acids greater in size than a recited polypeptide. Accordingly, a subject peptide may be from about 8 to about 30 amino acids in length. In certain embodiments, a subject peptide is about 9-20 amino acids in length, and usually contains an amino acid sequence described above.
Accordingly, depending on the antibodies desired, a suitable animal is immunized with a subject peptide or a mixture of subject peptides (e.g., a mixture of 2, 3, 4, 5 about 6 or more, about 10 or more or about 15 or more, usually up to about 20 or 30 or more peptides described above). Antibodies are usually isolated from the animal and tested for binding to different HPV E6 proteins using standard methods (e.g., ELISA, western blot, etc.). In many embodiments, therefore, antibodies will be screened for binding to E6 proteins from HPV strains 16 and 18, HPV strains 16, 18, 31, 33 and 45, or, in certain embodiments, all of the HPV strains shown in FIG. 1 or 2, and maybe others. Accordingly, antibodies that bind to, i.e., cross-react with, E6 proteins from more than one strain of HPV may be identified, and permanent cell lines producing those antibodies may be established using known methods. In other words, antibodies are usually tested for binding to more than one antigen, and those antigens are usually E6 proteins from various HPV strains, or fragments thereof. In most embodiments, the antibodies will be tested for binding to antigens in native and denatured states. Antibodies that bind to a plurality of E6 proteins have desirable binding properties, and, accordingly, find use in the subject methods.
As is well known in the art, the subject antibodies may be conjugated to a detectable label, or may be part of a signal generating system, as described above.
Accordingly, using the methods set forth above, an antibody composition for detecting a plurality of HPV E6 proteins is provided. In certain embodiments, a mixture of different antibodies that recognize at least 5, 7, 9, 12, 15, 20 or 24 different strains of HPV may be employed. The composition may contain at least one antibody that recognizes at least 3 different oncogenic E6 proteins. The composition may contain 1, 2, 3, 4, or 5 or more different antibodies, each antibody of the composition recognizing at least one (e.g., 2, 3, about 5, about 10, etc.) E6 protein. Collectively, the antibodies bind to all or a portion of the E6 proteins shown in FIG. 1, and, in certain embodiments, may also bind to non-oncogenic E6 proteins. The antibodies may be mixed, or separate from each other, i.e., in different vessels.
Any of the above-described antibodies may bind to an epitope set forth in Table 1.
| TABLE 1 |
| Epitopes |
| HPV | Starting | ||
| Sequence | type | AA | |
| (K/R)-(K/R)-R-F-H-(N/K/S/E/R)-I-(A/S) | 59 | 124 | |
| F-H-(N/K/S/E/R)-I-(A/S)-(G/H)-X-(W/Y) | 59 | 127 | |
| H-(N/K/S/E/R)-I-(A/S)-(G/H)-(R/Q)-(W/Y)-(T/K/R) | 59 | 128 | |
| P-(E/A/Q)-E-K-(Q/L/K/R)-(R/K/L)-(H/V/I/L)-(V/L/C) | 26 | 112 | |
| (G/H)-(R/Q/T/M/G/A/Y/H/S/N/I)-(W/Y/F)-(T/R/K/A)-G-(R/Q/S/L)-C-(R/L/M/A/T) | 59 | 132 | |
| (W/Y/F)-(T/R/K/A)-G-(R/Q/S/L)-C-(R/L/M/A/T)-(L/R/A/T)-(N/R/S/A/Q/G) | 59 | 134 | |
| G-(R/Q/S/L)-C-(R/L/M/A/T)-(L/R/A/T)-(N/R/S/A/Q/G)-C-(W/C/R) | 59 | 136 | |
| (R/K)-P-(R/Y)-(K/T/S)-(L/V)-(H/P)-(D/E/H/Q)-L | 59 | 10 | |
| (M/R/L)-F-(E/Q/D/H)-(D/N)-(P/T)-(Q/R/A/E/T)-(E/Q)-(R/K) | 59 | 3 | |
| (D/N)-(P/T)-(Q/R/A/E/T)-(E/Q)-(R/K)-(R/K)-P-(R/Y) | 59 | 6 | |
| (L/V)-(H/P)-(D/E/Q)-L-(C/S)-(E/T/Q)-(E/V/A/T)-(L/V)-(N/E/D) | 59 | 14 | |
| (D/E/N)-(L/V/I)-(Q/E/R/T)-(L/V/I)-(Q/N/D/S/A/N)-C-V-(F/Y/E)- | 59 | 26 | |
| L-(L/S)-I-R-C-(I/Y/H/L/M)-(R/I/C)-C | 59 | 101 | |
| (R/I/C)-C-(Q/L)-(K/R)-P-L-(C/T/G/N)-P | 59 | 107 | |
| (K/R)-P-L-(C/T/G/N)-P-(E/A/Q)-E-K | 59 | 110 | |
| P-(E/A/Q)-E-K-(Q/L/K)-(R/L/K)-(H/I)-(L/V/C) | 26 | 112 | |
| K-(Q/L/K)-(R/L/K)-(H/I)-(L/V/C)-(D/E/N)-(E/D/Y/L/K/S)-(K/N) | 26 | 115 | |
| (L/V/C)-(D/E/N)-(E/D/Y/L/K/S)-(K/N)-(K/R)-R-F-H | 26 | 119 | |
| I-(A/S)-(G/H)-(R/Q)-(W/Y)-(T/K/R)-G-(R/Q/L/S) | 26 | 128 | |
| (W/Y)-(T/K/R)-G-(R/Q/L/S)-C-(M/A/L/R/T)-(N/S/A/R)-C | 26 | 132 | |
Certain hybridomas that produce the monoclonal antibodies described above and below may be deposited at the ATCC. Any of the deposited hybridomas, the antibodies produced by those hybridomas, as well as other antibodies that bind the same epitopes as the antibodies produced by those hybridomas, are also embodiments of this invention and may be claimed herein. Such antibodies may be employed in any of the methods described herein.
Methods for Detecting an HPV E6 Protein in a Sample
The invention provides a method of detecting an HPV E6 protein in a sample. In general, the methods involve contacting a subject antibody composition with a sample, and assessing any binding of the antibody to the sample. In most embodiments, binding of the antibody to the sample indicates the presence of an HPV E6 protein.
The antibodies of the invention may be screened for immunospecific binding by any method known in the art. The immunoassays which can be used include but are not limited to competitive and non-competitive assay systems using techniques such as western blots, radioimmunoassays, ELISA (enzyme linked immunosorbent assay), “sandwich” immunoassays, immunoprecipitation assays, precipitin reactions, gel diffusion precipitin reactions, immunodiffusion assays, agglutination assays, complement-fixation assays, immunoradiometric assays, fluorescent immunoassays, protein A immunoassays, and cellular immunostaining (fixed or native) assays to name but a few. Such assays are routine and well known in the art (see, e.g., Ausubel et al., eds, 1994, Current Protocols in Molecular Biology, Vol. 1, John Wiley & Sons, Inc., New York, which is incorporated by reference herein in its entirety). Exemplary immunoassays are described briefly below (but are not intended by way of limitation).
Immunoprecipitation protocols generally involve lysing a population of cells in a lysis buffer such as RIPA buffer (1% NP-40 or Triton X-100, 1% sodium deoxycholate, 0.1% SDS, 0.15 M NaCl, 0.01 M sodium phosphate at pH 7.2, 1% Trasylol) supplemented with protein phosphatase and/or protease inhibitors (e.g., EDTA, PMSF, aprotinin, sodium vanadate), adding the antibody of interest to the cell lysate, incubating for a period of time (e.g., 1-4 hours) at 4° C., adding protein A and/or protein G sepharose beads to the cell lysate, incubating for about an hour or more at 4° C., washing the beads in lysis buffer and resuspending the beads in SDS/sample buffer. The ability of the antibody of interest to immunoprecipitate a particular antigen can be assessed by, e.g., western blot analysis. One of skill in the art would be knowledgeable as to the parameters that can be modified to increase the binding of the antibody to an antigen and decrease the background (e.g., pre-clearing the cell lysate with sepharose beads).
Western blot analysis generally involves preparation of protein samples followed by electrophoresis of the protein samples in a polyacrylamide gel (e.g., 8%-20% SDS-PAGE depending on the molecular weight of the antigen), and transfer of the separated protein samples from the polyacrylamide gel to a membrane such as nitrocellulose, PVDF or nylon. Following transfer, the membrane is blocked in blocking solution (e.g., PBS with 3% BSA or non-fat milk), washed in washing buffer (e.g., PBS-Tween 20), and incubated with primary antibody (the antibody of interest) diluted in blocking buffer. After this incubation, the membrane is washed in washing buffer, incubated with a secondary antibody (which recognizes the primary antibody, e.g., an anti-human antibody) conjugated to an enzymatic substrate (e.g., horseradish peroxidase or alkaline phosphatase) or radioactive molecule (e.g., 32P or 125I), and after a further wash, the presence of the antigen may be detected. One of skill in the art would be knowledgeable as to the parameters that can be modified to increase the signal detected and to reduce the background noise.
ELISAs involve preparing antigen, coating the well of a 96 well multiwell plate with the antigen, adding the antibody of interest conjugated to a detectable compound such as an enzymatic substrate (e.g., horseradish peroxidase or alkaline phosphatase) to the well and incubating for a period of time, and detecting the presence of the antigen. In ELISAs the antibody of interest does not have to be conjugated to a detectable compound; instead, a second antibody (which recognizes the antibody of interest) conjugated to a detectable compound may be added to the well. Further, instead of coating the well with the antigen, the antibody may be coated to the well. In this case, a second antibody conjugated to a detectable compound may be added following the addition of the antigen of interest to the coated well. One of skill in the art would be knowledgeable as to the parameters that can be modified to increase the signal detected as well as other variations of ELISAs known in the art.
The binding affinity of an antibody to an antigen and the off-rate of an antibody-antigen interaction can be determined by competitive binding assays. One example of a competitive binding assay is a radioimmunoassay comprising the incubation of labeled antigen (e.g., 3H or 125I) with the antibody of interest in the presence of increasing amounts of unlabeled antigen, and the detection of the antibody bound to the labeled antigen. The affinity of the antibody of interest for a particular antigen and the binding off-rates can be determined from the data by scatchard plot analysis. Competition with a second antibody can also be determined using radioimmunoassays. In this case, the antigen is incubated with antibody of interest conjugated to a labeled compound (e.g., 3H or 125I) in the presence of increasing amounts of an unlabeled second antibody.
Antibodies of the invention may be screened using immunocytochemisty methods on cells (e.g., mammalian cells, such as CHO cells) transfected with a vector enabling the expression of an antigen or with vector alone using techniques commonly known in the art. Antibodies that bind antigen transfected cells, but not vector-only transfected cells, are antigen specific.
In certain embodiments, however, the assay is an antigen capture assay, and an array or microarray of antibodies may be employed for this purpose. Methods for making and using microarrays of polypeptides are known in the art (see e.g. U.S. Pat. Nos. 6,372,483, 6,352,842, 6,346,416, and 6,242,266).
Systems for Detecting an Oncogenic HPV E6 Protein
The invention provides a system for detecting the presence of an oncogenic HPV E6 polypeptide in a sample. In general, the system comprises a first and a second binding partner for an oncogenic HPV E6 polypeptide. In most embodiments, the first binding partner is a PDZ domain protein and the second binding partner is a subject antibody.
The subject antibodies may be used along with certain PDZ domain proteins as part of a system for detecting E6 protein from oncogenic strains of HPV. As mentioned above, oncogenic HPV E6 proteins contain a “PDZ-ligand” (“PL”) that is bound by certain PDZ domain polypeptides. Non-oncogenic HPV E6 proteins do not contain such a PDZ-ligand, and, accordingly, are not bound by PDZ-domain polypeptides. Many PDZ domains suitable for use in the subject system are generally described in Table 2, and include MAGI-1 PDZ domain 2, the PDZ domain of TIP-1, and the PDZ domains 1 and 2 of DLG1, and many others. As would be recognized by one of skill in the art, a PDZ domain may be employed as part of a fusion protein, particularly in embodiments in which the PDZ domain polypeptide is anchored to a substrate. Accordingly, the subject system generally contains a suitable PDZ domain polypeptide, which is usually a fusion protein, and a subject antibody.
In certain embodiments, one of the binding partners is attached to a solid support, and the other binding partner may be labeled or part of a signal producing system. Proteins may be covalently bound or noncovalently attached through nonspecific bonding. If covalent bonding between the fusion protein and the surface is desired, the surface will usually be polyfunctional or be capable of being polyfunctionalized. Functional groups which may be present on the surface and used for linking can include carboxylic acids, aldehydes, amino groups, cyano groups, ethylenic groups, hydroxyl groups, mercapto groups and the like. The manner of linking a wide variety of compounds to various surfaces is well known and is amply illustrated in the literature.
| TABLE 2 | ||||
| SEQ | ||||
| ID | GI or | |||
| NO. | name | Acc. # | Sequence | |
| 106 | AF6 domain 1 | 430993 | LRKEPEIITVTLKKQNGMGLSI | |
| VAAKGAGQDKLGIYVKSVVKGG | ||||
| AADVDGRLAAGDQLLSVDGRSL | ||||
| VGLSQERAAELMTRTSSVVTLE | ||||
| VAKQG | ||||
| 107 | AIPC domain 1 | 12751451 | LIRPSVISIIGLYKEKGKGLGF | |
| SIAGGRDCIRGQMGIFVKTIFP | ||||
| NGSAAEDGRLKEGDEILDVNGI | ||||
| PIKGLTFQEAIHTFKQIRSGLF | ||||
| VLTVRTKLVSPSLTNSS | ||||
| 108 | AIPC domain 3 | 12751451 | QSENEEDVCFIVLNRKEGSGLG | |
| FSVAGGTDVEPKSITVHRVFSQ | ||||
| GAASQEGTMNRGDFLLSVNGAS | ||||
| LAGLAHGNVLKVLHQAQLHKDA | ||||
| LVVIKKGMDQPRPSNSS | ||||
| 109 | AIPC domain 2 | 12751451 | GISSLGRKTPGPKDRIVMEVTL | |
| NKEPRVGLGIGACCLALENSPP | ||||
| GIYIHSLAPGSVAKMESNLSRG | ||||
| DQILEVNSVNVRHAALSKVHAI | ||||
| LSKCPPGPVRLVIGRHPNPKVS | ||||
| EQEMDEVIARSTYQESKEANSS | ||||
| 110 | AIPC domain 4 | 12751451 | LGRSVAVHDALCVEVLKTSAGL | |
| GLSLDGGKSSVTGDGPLVIKRV | ||||
| YKGGAAEQAGIIEAGDEILAIN | ||||
| GKPLVGLMHFDAWNIMKSVPEG | ||||
| PVQLLIRKHRNSS | ||||
| 111 | ALP domain 1 | 2773059 | REEGGMPQTVILPGPAPWGFRL | |
| SGGIDFNQPLVITRITPGSKAA | ||||
| AANLCPGDVILAIDGFGTESMT | ||||
| HADAQDRIKAAAHQLCLKIDRG | ||||
| ETHLWSPNSS | ||||
| 112 | APXL1 domain 1 | 13651263 | ILVEVQLSGGAPWGFTLKGGRE | |
| HGEPLVITKIEEGSKAAAVDKL | ||||
| LAGDEIVGINDIGLSGFRQEAI | ||||
| CLVKGSHKTLKLVVKRNSS | ||||
| 113 | CARD11 domain 1 | 12382772 | SVGHVRGPGPSVQHTTLNGDSL | |
| TSQLTLLGGNARGSFVHSVKPG | ||||
| SLAEKAGLREGHQLLLLEGCIR | ||||
| GERQSVPLDTCTKEEAHWTIQR | ||||
| CSGPVTLHYKVNHEGYRK | ||||
| 114 | CARD14 domain 1 | 13129123 | RRPARRILSQVTMLAFQGDALL | |
| EQISVIGGNLTGIFIHRVTPGS | ||||
| AADQMALRPGTQIVMVDYEASE | ||||
| PLFKAVLEDTTLEEAVGLLRRV | ||||
| DGFCCLSVKVNTDGYKR | ||||
| 115 | CARD14 domain 1 | 13129123 | ILSQVTMLAFQGDALLEQISVI | |
| GGNLTGIFIHRVTPGSAADQMA | ||||
| LRPGTQIVMVDYEASEPLFKAV | ||||
| LEDTTLEEAVGLLRRVDGFCCL | ||||
| SVKVNTDGYKRL | ||||
| 116 | CASK domain 1 | 3087815 | TRVRLVQFQKNTDEPMGITLKM | |
| NELNHCIVARIMHGGMIHRQGT | ||||
| LHVGDEIREINGISVANQTVEQ | ||||
| LQKMLREMRGSITFKIVPSYRT | ||||
| QS | ||||
| 117 | CNK1 domain 1 | 3930780 | LEQKAVLEQVQLDSPLGLEIHT | |
| TSNCQHFVSQVDTQVPTDSRLQ | ||||
| IQPGDEVVQINEQVVVGWPRKN | ||||
| MVRELLREPAGLSLVLKKIPIP | ||||
| 118 | Cytohesin | 3192908 | QRKLVTVEKQDNETFGFEIQSY | |
| binding | RPQNQNACSSEMFTLICKIQED | |||
| Protein | SPAHCAGLQAGDVLANINGVST | |||
| domain 1 | EGFTYKQVVDLIRSSGNLLTIE | |||
| TLNG | ||||
| 119 | Densin domain 1 | 16755892 | RCLIQTKGQRSMDGYPEQFCVR | |
| IEKNPGLGFSISGGISGQGNPF | ||||
| KPSDKGIFVTRVQPDGPASNLL | ||||
| QPGDKILQANGHSFVHMEHEKA | ||||
| VLLLKSFQNTVDLVIQRELTV | ||||
| 120 | DLG 6 splice | AB053303 | PTSPEIQELRQMLQAPHFKGAT | |
| variant 2 | IKRHEMTGDILVARIIHGGLAE | |||
| domain 1 | RSGLLYAGDKLVEVNGVSVEGL | |||
| DPEQVIHILAMSRGTIMFKVVP | ||||
| VSDPPVNSS | ||||
| 121 | DLG 6 splice | 14647140 | PTSPEIQELRQMLQAPHFKALL | |
| variant 1 | SAHDTIAQKDFEPLLPPLPDNI | |||
| domain 1 | PESEEAMRIVCLVKNQQPLGAT | |||
| IKRHEMTGDILVARIIHGGLAE | ||||
| RSGLLYAGDKLVEVNGVSVEGL | ||||
| DPEQVIHILAMSRGTIMFKVVP | ||||
| VSDPPVNSS | ||||
| 122 | DLG1 domain 1 | 475816 | IQVNGTDADYEYEEITLERGNS | |
| GLGFSIAGGTDNPHIGDDSSIF | ||||
| ITKIITGGAAAQDGRLRVNDCI | ||||
| LQVNEVDVRDVTHSKAVEALKE | ||||
| AGSIVRLYVKRRN | ||||
| 123 | DLG1 domain 2 | 475816 | IQLIKGPKGLGFSIAGGVGNQH | |
| IPGDNSIYVTKIIEGGAAHKDG | ||||
| KLQIGDKLLAVNNVCLEEVTHE | ||||
| EAVTALKNTSDFVYLKVAKPTS | ||||
| MYMNDGN | ||||
| 124 | DLG1 domains | 475816 | VNGTDADYEYEEITLERGNSGL | |
| 1 and 2 | GFSIAGGTDNPHIGDDSSIFIT | |||
| KIITGGAAAQDGRLRVNDCILQ | ||||
| VNEVDVRDVTHSKAVEALKEAG | ||||
| SIVRLYVKRRKPVSEKIMEIKL | ||||
| IKGPKGLGFSIAGGVGNQHIPG | ||||
| DNSIYVTKIIEGGAAHKDGKLQ | ||||
| IGDKLLAVNNVCLEEVTHEEAV | ||||
| TALKNTSDFVYLKVAKPTSMYM | ||||
| NDGYA | ||||
| 125 | DLG1 domain 3 | 475816 | ILHRGSTGLGFNIVGGEDGEGI | |
| FISFILAGGPADLSGELRKGDR | ||||
| IISVNSVDLRAASHEQAAAALK | ||||
| NAGQAVTIVAQYRPEEYSR | ||||
| 126 | DLG2 domain 3 | 12736552 | IEGRGILEGEPRKVVLHKGSTG | |
| LGFNIVGGEDGEGIFVSFILAG | ||||
| GPADLSGELQRGDQILSVNGID | ||||
| LRGASHEQAAAALKGAGQTVTI | ||||
| IAQHQPEDYARFEAKIHDLNSS | ||||
| 127 | DLG2 domain 1 | 12736552 | ISYVNGTEIEYEFEEITLERGN | |
| SGLGFSIAGGTDNPHIGDDPGI | ||||
| FITKIIPGGAAAEDGRLRVNDC | ||||
| ILRVNEVDVSEVSHSKAVEALK | ||||
| EAGSIVRLYVRRR | ||||
| 128 | DLG2 domain 2 | 12736552 | IPILETVVEIKLFKGPKGLGFS | |
| IAGGVGNQHIPGDNSIYVTKII | ||||
| DGGAAQKDGRLQVGDRLLMVNN | ||||
| YSLEEVTHEEAVAILKNTSEVV | ||||
| YLKVGKPTTIYMTDPYGPPNSS | ||||
| LTD | ||||
| 129 | DLG5 domain 1 | 3650451 | GIPYVEEPRHVKVQKGSEPLGI | |
| SIVSGEKGGIYVSKVTVGSIAH | ||||
| QAGLEYGDQLLEFNGINLRSAT | ||||
| EQQARLIIGQQCDTITILAQYN | ||||
| PHVHQLRNSSLTD | ||||
| 130 | DLG5 domain 2 | 3650451 | GILAGDANKKTLEPRVVFIKKS | |
| QLELGVHLCGGNLHGVFVAEVE | ||||
| DDSPAKGPDGLVPGDLILEYGS | ||||
| LDVRNKTVEEVYVEMLKPRDGV | ||||
| RLKVQYRPEEFIVTD | ||||
| 131 | DVL1 domain 1 | 2291005 | LNIVTVTLNMERHHFLGISIVG | |
| QSNDRGDGGIYIGSIMKGGAVA | ||||
| ADGRIEPGDMLLQVNDVNFENM | ||||
| SNDDAVRVLREIVSQTGPISLT | ||||
| VAKCW | ||||
| 132 | DVL2 domain 1 | 2291007 | LNIITVTLNMEKYNFLGISIVG | |
| QSNERGDGGIYIGSIMKGGAVA | ||||
| ADGRIEPGDMLLQVNDMNFENM | ||||
| SNDDAVRVLRDIVHKPGPIVLT | ||||
| VAKCWDPSPQNS | ||||
| 133 | DVL3 domain 1 | 6806886 | IITVTLNMEKYNFLGISIVGQS | |
| NERGDGGIYIGSIMKGGAVAAD | ||||
| GRIEPGDMLLQVNEINFENMSN | ||||
| DDAVRVLREIVHKPGPITLTVA | ||||
| KCWDPSP | ||||
| 134 | EBP50 domain 2 | 3220018 | QQRELRPRLCTMKKGPSGYGFN | |
| LHSDKSKPGQFIRSVDPDSPAE | ||||
| ASGLRAQDRIVEVNGVCMEGKQ | ||||
| HGDVVSAIRAGGDETKLLVVDR | ||||
| ETDEFFKNSS | ||||
| 135 | EBP50 domain 1 | 3220018 | GIQMSADAAAGAPLPRLCCLEK | |
| GPNGYGFHLHGEKGKLGQYIRL | ||||
| VEPGSPAEKAGLLAGDRLVEVN | ||||
| GENVEKETHQQVVSRIRAALNA | ||||
| VRLLVVDPETDEQLQKLGVQVR | ||||
| EELLRAQEAPGQAEPPAAAEVQ | ||||
| GAGNENEPREADKSHPEQRELR | ||||
| N | ||||
| 136 | EBP50 domains | 3220018 | GIQMSADAAAGAPLPRLCCLEK | |
| 1 and 2 | GPNGYGFHLHGEKGKLGQYIRL | |||
| VEPGSPAEKAGLLAGDRLVEVN | ||||
| GENVEKETHQQVVSRIRAALNA | ||||
| VRLLVVDPETDEQLQKLGVQVR | ||||
| EELLRAQEAPGQAEPPAAAEVQ | ||||
| GAGNENEPREADKSHPEQRELR | ||||
| PRLCTMKKGPSGYGFNLHSDKS | ||||
| KPGQFIRSVDPDSPAEASGLRA | ||||
| QDRIVEVNGVCMEGKQHGDVVS | ||||
| AIRAGGDETKLLVVDRETDEFF | ||||
| K | ||||
| 137 | EBP50 domain 1 | 3220018 | QMSADAAAGAPLPRLCCLEKGP | |
| NGYGFHLHGEKGKLGQYIRLVE | ||||
| PGSPAEKAGLLAGDRLVEVNGE | ||||
| NVEKETHQQVVSRIRAALNAVR | ||||
| LLVVDPETDEQLQKLGVQVREE | ||||
| LLRAQEAPGQAEPPAAAEVQGA | ||||
| GNENEPREADKSHPEQRELRNS | ||||
| S | ||||
| 138 | ELFIN 1 | 2957144 | LTTQQIDLQGPGPWGFRLVGGK | |
| domain 1 | DFEQPLAISRVTPGSKAALANL | |||
| CIGDVITAIDGENTSNMTHLEA | ||||
| QNRIKGCTDNLTLTVARSEHKV | ||||
| WSPLVTNSSW | ||||
| 139 | ENIGMA domain 1 | 561636 | IFMDSFKVVLEGPAPWGFRLQG | |
| GKDFNVPLSISRLTPGGKAAQA | ||||
| GVAVGDWVLSIDGENAGSLTHI | ||||
| EAQNKIRACGERLSLGLSRAQP | ||||
| V | ||||
| 140 | ERBIN domain 1 | 8923908 | QGHELAKQEIRVRVEKDPELGF | |
| SISGGVGGRGNPFRPDDDGIFV | ||||
| TRVQPEGPASKLLQPGDKIIQA | ||||
| NGYSFINIEHGQAVSLLKTFQN | ||||
| TVELIIVREVSS | ||||
| 141 | FLJ00011 | 10440352 | KNPSGELKTVTLSKMKQSLGIS | |
| domain 1 | ISGGIESKVQPMVKIEKIFPGG | |||
| AAFLSGALQAGFELVAVDGENL | ||||
| EQVTHQRAVDTIRRAYRNKARE | ||||
| PMELVVRVPGPSPRPSPSD | ||||
| 142 | FLJ11215 | 11436365 | EGHSHPRVVELPKTEEGLGFNI | |
| domain 1 | MGGKEQNSPIYISRIIPGGIAD | |||
| RHGGLKRGDQLLSVNGVSVEGE | ||||
| HHEKAVELLKAAQGKVKLVVRY | ||||
| TPKVLEEME | ||||
| 143 | FLJ12428 | BC012040 | PGAPYARKTFTIVGDAVGWGFV | |
| domain 1 | VRGSKPCHIQAVDPSGPAAAAG | |||
| MKVCQFVVSVNGLNVLHVDYRT | ||||
| VSNLILTGPRTIVMEVMEELEC | ||||
| 144 | FLJ12615 | 10434209 | GQYGGETVKIVRIEKARDIPLG | |
| domain 1 | ATVRNEMDSVIISRIVKGGAAE | |||
| KSGLLHEGDEVLEINGIEIRGK | ||||
| DVNEVFDLLSDMHGTLTFVLIP | ||||
| SQQIKPPPA | ||||
| 145 | FLJ21687 | 10437836 | KPSQASGHFSVELVRGYAGFGL | |
| domain 1 | TLGGGRDVAGDTPLAVRGLLKD | |||
| GPAQRCGRLEVGDLVLHINGES | ||||
| TQGLTHAQAVERIRAGGPQLHL | ||||
| VIRRPLETHPGKPRGV | ||||
| 146 | FLJ31349 | AK055911 | PVMSQCACLEEVHLPNIKPGEG | |
| domain 1 | LGMYIKSTYDGLHVITGTTENS | |||
| PADRSQKIHAGDEVTQVNQQTV | ||||
| VGWQLKNLVKKLRENPTGVVLL | ||||
| LKKRPTGSFNFTP | ||||
| 147 | FLJ32798 | AK057360 | IDDEEDSVKIIRLVKNREPLGA | |
| domain 1 | TIKKDEQTGAIIVARIMRGGAA | |||
| DRSGLIHVGDELREVNGIPVED | ||||
| KRPEEIIQILAQSQGAITFKII | ||||
| PGSKEETPS | ||||
| 148 | GORASP 2 | 13994253 | MGSSQSVEIPGGGTEGYHVLRV | |
| domains 1 | QENSPGHRAGLEPFFDFIVSIN | |||
| and 2 | GSRLNKDNDTLKDLLKANVEKP | |||
| VKMLIYSSKTLELRETSVTPSN | ||||
| LWGGQGLLGVSIRFCSFDGANE | ||||
| NVWHVLEVESNSPAALAGLRPH | ||||
| SDYIIGADTVMNESEDLFSLIE | ||||
| THEAKPLKLYVYNTDTDNCREV | ||||
| IITPNSAWGGEGSLGCGIGYGY | ||||
| LHRIPTRPFEEGKKISLPGQMA | ||||
| GTPITPLKDGFTEVQLSSVNPP | ||||
| SLSPPGTTGIEQSLTGLSISST | ||||
| PPAVSSVLSTGVPTVPLLPPQV | ||||
| NQSLTSVPPMNPATTLPGLMPL | ||||
| PAGLPNLPNLNLNLPAPHIMPG | ||||
| VGLPELVNPGLPPLPSMPPRNL | ||||
| PGIAPLPLPSEFLPSFPLVPES | ||||
| SSAASSGELLSSLPPTSNAPSD | ||||
| PATTTAKADAASSLTVDVTPPT | ||||
| AKAPTTVEDRVGDSTPVSEKPV | ||||
| SAAVDANASESP | ||||
| 149 | GORASP 2 | 13994253 | NENVWHVLEVESNSPAALAGLR | |
| domain 2 | PHSDYIIGADTVMNESEDLFSL | |||
| IETHEAKPLKLYVYNTDTDNCR | ||||
| EVIITPNSAWGGEGSLGCGIGY | ||||
| GYLHRIPTR | ||||
| 150 | GORASP 2 | 13994253 | MGSSQSVEIPGGGTEGYHVLRV | |
| domain 1 | QENSPGHRAGLEPFFDFIVSIN | |||
| GSRLNKDNDTLKDLLKANVEKP | ||||
| VKMLIYSSKTLELRETSVTPSN | ||||
| LWGGQGLLGVSIRFCSFDGANE | ||||
| 151 | GORASP 1 | 29826292 | RASEQVWHVLDVEPSSPAALAG | |
| domain 2 | LRPYTDYVVGSDQILQESEDFF | |||
| TLIESHEGKPLKLMVYNSKSDS | ||||
| CREVTVTPNAAWGGEGSLGCGI | ||||
| GYGYLHRIPTQ | ||||
| 152 | GORASP 1 | 29826292 | MGLGVSAEQPAGGAEGFHLHGV | |
| domain 1 | QENSPAQQAGLEPYFDFIITIG | |||
| HSRLNKENDTLKALLKANVEKP | ||||
| VKLEVFNMKTMRVREVEVVPSN | ||||
| MWGGQGLLGASVRFCSFRRASE | ||||
| 153 | GORASP 1 | 29826292 | MGLGVSAEQPAGGAEGFHLHGV | |
| domains 1 | QENSPAQQAGLEPYFDFIITIG | |||
| and 2 | HSRLNKENDTLKALLKANVEKP | |||
| VKLEVFNMKTMRVREVEVVPSN | ||||
| MWGGQGLLGASVRFCSFRRASE | ||||
| QVWHVLDVEPSSPAALAGLRPY | ||||
| TDYVVGSDQILQESEDFFTLIE | ||||
| SHEGKPLKLMVYNSKSDSCREV | ||||
| TVTPNAAWGGEGSLGCGIGYGY | ||||
| LHRIPTQPPSYHKKPPGTPPPS | ||||
| ALPLGAPPPDALPPGPTPEDSP | ||||
| SLETGSRQSDYMEALLQAPGSS | ||||
| MEDPLPGPGSPSHSAPDPDGLP | ||||
| HFMETPLQPPPPVQRVMDPGFL | ||||
| DVSGISLLDNSNASVWPSLPSS | ||||
| TELTTTAVSTSGPEDICSSSSS | ||||
| HERGGEATWSGSEFEVSFLDSP | ||||
| GAQAQADHLPQLTLPDSLTSAA | ||||
| SPEDGLSAELLEAQAEEEPAST | ||||
| EGLDTGTEAEGLDSQAQISTTE | ||||
| 154 | GRIP 1 | 4539083 | IYTVELKRYGGPLGITISGTEE | |
| domain 6 | PFDPIIISSLTKGGLAERTGAI | |||
| HIGDRILANSSSLKGKPLSEAI | ||||
| HLLQMAGETVTLKIKKQTDAQS | ||||
| A | ||||
| 155 | GRIP 1 | 4539083 | VVELMKKEGTTLGLTVSGGIDK | |
| domain 1 | DGKPRVSNLRQGGIAARSDQLD | |||
| VGDYIKAVNGINLAKFRHDEII | ||||
| SLLKNVGERVVLEVEYE | ||||
| 156 | GRIP 1 | 4539083 | HVATASGPLLVEVAKTPGASLG | |
| domain 3 | VALTTSMCCNKIQVIVIDKIKS | |||
| ASIADRCGALHVGDHILSIDGT | ||||
| SMEYCTLAEATQFLANTTDQVK | ||||
| LEILPHHQTRLALKGPNSS | ||||
| 157 | GRIP 1 | 4539083 | IMSPTPVELHKVTLYKDSDMED | |
| domain 7 | FGFSVADGLLEKGVYVKNIRPA | |||
| GPGDLGGLKPYDRLLQVNHVRT | ||||
| RDFDCCLVVPLIAESGNKLDLV | ||||
| ISRNPLA | ||||
| 158 | GRIP 1 | 4539083 | IYTVELKRYGGPLGITISGTEE | |
| domain 4 | PFDPIIISSLTKGGLAERTGAI | |||
| HIGDRILAINSSSLKGKPLSEA | ||||
| IHLLQMAGETVTLKIKKQTDAQ | ||||
| SA | ||||
| 159 | GRIP 1 | 4539083 | IMSPTPVELHKVTLYKDSDMED | |
| domain 5 | FGFSVADGLLEKGVYVKNIRPA | |||
| GPGDLGGLKPYDRLLQVNHVRT | ||||
| RDFDCCLVVPLIAESGNKLDLV | ||||
| ISRNPLA | ||||
| 160 | GTPase | 2389008 | SRGCETRELALPRDGQGRLGFE | |
| activating | VDAEGFVTHVERFTFAETAGLR | |||
| enzyme | PGARLLRVCGQTLPSLRPEAAA | |||
| domain 1 | QLLRSAPKVCVTVLPPDESGRP | |||
| 161 | Guanine | 6650765 | CSVMIFEVVEQAGAIILEDGQE | |
| exchange | LDSWYVILNGTVEISHPDGKVE | |||
| factor | NLFMGNSFGITPTLDKQYMHGI | |||
| domain 1 | VRTKVDDCQFVCIAQQDYWRIL | |||
| NHVEKNTHKVEEEGEIVMVH | ||||
| 162 | HEMBA 1000505 | 10436367 | PRETVKIPDSADGLGFQIRGFG | |
| domain 2 | PSVVHAVGRGTVAAAAGLHPGQ | |||
| CIIKVNGINVSKETHASVIAHV | ||||
| TACRKYRRPTKQDSIQ | ||||
| 163 | HEMBA 1000505 | 10436367 | LENVIAKSLLIKSNEGSYGFGL | |
| domain 1 | EDKNKVPIIKLVEKGSNAEMAG | |||
| MEVGKKIFAINGDLVFMRPFNE | ||||
| VDCFLKSCLNSRKPLRVLVSTK | ||||
| P | ||||
| 164 | HEMBA 1003117 | 7022001 | EDFCYVFTVELERGPSGLGMGL | |
| domain 1 | IDGMHTHLGALPGLYIQTLLPG | |||
| SPAAADGRLSLGDRILEVNGSS | ||||
| LLGLGYLRAVDLIRHGGKKMRF | ||||
| LVAKSDVETAKKI | ||||
| 165 | hShroom | 18652858 | IYLEAFLEGGAPWGFTLKGGLE | |
| domain 1 | HGEPLIISKVEEGGKADTLSSK | |||
| LQAGDEVVHINEVTLSSSRKEA | ||||
| VSLVKGSYKTLRLVVRRDVCTD | ||||
| PGH | ||||
| 166 | HSPC227 | 7106843 | NNELTQFLPRTITLKKPPGAQL | |
| domain 1 | GFNIRGGKASQLGIFISKVIPD | |||
| SDAHRAGLQEGDQVLAVNDVDF | ||||
| QDIEHSKAVEILKTAREISMRV | ||||
| RFFPYNYHRQKE | ||||
| 167 | HTRA 3 | AY040094 | FLTEFQDKQIKDWKKRFIGIRM | |
| domain 1 | RTITPSLVDELKASNPDFPEVS | |||
| SGIYVQEVAPNSPSQRGGIQDG | ||||
| DIIVKVNGRPLVDSSELQEAVL | ||||
| TESPLLLEVRRGNDDLLFS | ||||
| 168 | HTRA 4 | AL576444 | NKKYLGLQMLSLTVPLSEELKM | |
| domain 1 | HYPDFPDVSSGVYVCKVVEGTA | |||
| AQSSGLRDHDVIVNINGKPITT | ||||
| TTDVVKALDSDSLSMAVLRGKD | ||||
| NLLLTV | ||||
| 169 | INADL | 2370148 | PGSDSSLFETYNVELVRKDGQS | |
| domain 3 | LGIRIVGYVGTSHTGEASGIYV | |||
| KSIIPGSAAYHNGHIQVNDKIV | ||||
| AVDGVNIQGFANHDVVEVLRNA | ||||
| GQVVHLTLVRRKTSSSTSRIHR | ||||
| D | ||||
| 170 | INADL | 2370148 | PATCPIVPGQEMIIEISKGRSG | |
| domain 8 | LGLSIVGGKDTPLNAIVIHEVY | |||
| EEGAAARDGRLWAGDQILEVNG | ||||
| VDLRNSSHEEAITALRQTPQKV | ||||
| RLVVY | ||||
| 171 | INADL | 2370148 | LPETVCWGHVEEVELINDGSGL | |
| domain 2 | GFGIVGGKTSGVVVRTIVPGGL | |||
| ADRDGRLQTGDHILKIGGTNVQ | ||||
| GMTSEQVAQVLRNCGNSVRMLV | ||||
| ARDPAGDIQSPI | ||||
| 172 | INADL | 2370148 | PNFSHWGPPRIVEIFREPNVSL | |
| domain 6 | GISIVVGQTVIKRLKNGEELKG | |||
| IFIKQVLEDSPAGKTNALKTGD | ||||
| KILEVSGVDLQNASHSEAVEAI | ||||
| KNAGNPVVFIVQSLSSTPRVIP | ||||
| NVHNKANSS | ||||
| 173 | INADL | 2370148 | PGELHIIELEKDKNGLGLSLAG | |
| domain 7 | NKDRSRMSIFVVGINPEGPAAA | |||
| DGRMRIGDELLEINNQILYGRS | ||||
| HQNASAIIKTAPSKVKLVFIRN | ||||
| EDAVNQMANSS | ||||
| 174 | INADL | 2370148 | LSSPEVKIVELVKDCKGLGFSI | |
| domain 5 | LDYQDPLDPTRSVIVIRSLVAD | |||
| GVAERSGGLLPGDRLVSVNEYC | ||||
| LDNTSLAEAVEILKAVPPGLVH | ||||
| LGICKPLVEFIVTD | ||||
| 175 | INADL | 2370148 | IWQIEYIDIERPSTGGLGFSVV | |
| domain 1 | ALRSQNLGKVDIFVKDVQPGSV | |||
| ADRDQRLKENDQILAINHTPLD | ||||
| QNISHQQAIALLQQTTGSLRLI | ||||
| VAREPVHTKSSTSSSE | ||||
| 176 | INADL | 2370148 | NSDDAELQKYSKLLPIHTLRLG | |
| domain 4 | VEVDSFDGHHYISSIVSGGPVD | |||
| TLGLLQPEDELLEVNGMQLYGK | ||||
| SRREAVSFLKEVPPPFTLVCCR | ||||
| RLFDDEAS | ||||
| 177 | KIAA0313 | 7657260 | HLRLLNIACAAKAKRRLMTLTK | |
| domain 1 | PSREAPLPFILLGGSEKGFGIF | |||
| VDSVDSGSKATEAGLKRGDQIL | ||||
| EVNGQNFENIQLSKAMEILRNN | ||||
| THLSITVKTNLFVFKELLTRLS | ||||
| EEKRNGAP | ||||
| 178 | KIAA0316 | 6683123 | IPPAPRKVEMRRDPVLGFGFVA | |
| domain 1 | GSEKPVVVRSVTPGGPSEGKLI | |||
| PGDQIVMINDEPVSAAPRERVI | ||||
| DLVRSCKESILLTVIQPYPSPK | ||||
| 179 | KIAA0340 | 2224620 | LNKRTTMPKDSGALLGLKVVGG | |
| domain 1 | KMTDLGRLGAFITKVKKGSLAD | |||
| VVGHLRAGDEVLEWNGKPLPGA | ||||
| TNEEVYNIILESKSEPQVEIIV | ||||
| SRPIGDIPRIHRD | ||||
| 180 | KIAA0380 | 2224700 | RCVIIQKDQHGFGFTVSGDRIV | |
| domain 1 | LVQSVRPGGAAMKAGVKEGDRI | |||
| IKVNGTMVTNSSHLEVVKLIKS | ||||
| GAYVALTLLGS | ||||
| 181 | KIAA0382 | 7662087 | ILVQRCVIIQKDDNGFGLTVSG | |
| domain 1 | DNPVFVQSVKEDGAAMRAGVQT | |||
| GDRIIKVNGTLVTHSNHLEVVK | ||||
| LIKSGSYVALTVQGRPPGNSS | ||||
| 182 | KIAA0440 | 2662160 | SVEMTLRRNGLGQLGFHVNYEG | |
| domain 1 | IVADVEPYGYAWQAGLRQGSRL | |||
| VEICKVAVATLSHEQMIDLLRT | ||||
| SVTVKVVIIPPH | ||||
| 183 | KIAA0545 | 14762850 | LKVMTSGWETVDMTLRRNGLGQ | |
| domain 1 | LGFHVKYDGTVAEVEDYGFAWQ | |||
| AGLRQGSRLVEICKVAVVTLTH | ||||
| DQMIDLLRTSVTVKVVIIPPFE | ||||
| DGTPRRGW | ||||
| 184 | KIAA0559 | 3043641 | HYIFPHARIKITRDSKDHTVSG | |
| domain 1 | NGLGIRIVGGKEIPGHSGEIGA | |||
| YIAKILPGGSAEQTGKLMEGMQ | ||||
| VLEWNGIPLTSKTYEEVQSIIS | ||||
| QQSGEAEICVRLDLNML | ||||
| 185 | KIAA0613 | 3327039 | SYSVTLTGPGPWGFRLQGGKDF | |
| domain 1 | NMPLTISRITPGSKAAQSQLSQ | |||
| GDLVVAIDGVNTDTMTHLEAQN | ||||
| KIKSASYNLSLTLQKSKNSS | ||||
| 186 | KIAA0858 | 4240204 | FSDMRISINQTPGKSLDFGFTI | |
| domain 1 | KWDIPGIFVASVEAGSPAEFSQ | |||
| LQVDDEIIAINNTKFSYNDSKE | ||||
| WEEAMAKAQETGHLVMDVRRYG | ||||
| KAGSPE | ||||
| 187 | KIAA0902 | 4240292 | QSAHLEVIQLANIKPSEGLGMY | |
| domain 1 | IKSTYDGLHVITGTTENSPADR | |||
| CKKIHIAGDEVIQVNHQTVVGW | ||||
| QLKNLVNALREDPSGVILTLKK | ||||
| RPQSMLTSAPA | ||||
| 188 | KIAA0967 | 4589577 | ILTQTLIPVRHTVKIDKDTLLQ | |
| domain 1 | DYGFHISESLPLTVVAVTAGGS | |||
| AHGKLFPGDQILQMNNEPAEDL | ||||
| SWERAVDILREAEDSLSITVVR | ||||
| CTSGVPKSSNSS | ||||
| 189 | KIAA1202 | 6330421 | RSFQYVPVQLQGGAPWGFTLKG | |
| domain 1 | GLEHCEPLTVSKIEDGGKAALS | |||
| QKMRTGDELVNINGTPLYGSRQ | ||||
| EAILILIKGSFRILKLIVRRRN | ||||
| APVS | ||||
| 190 | KIAA1222 | 6330610 | ILEKLELFPVELEKDEDGLGIS | |
| domain 1 | IIGMGVGADAGLEKLGIFVKTV | |||
| TEGGAAQRDGRIQVNDQIVEVD | ||||
| GISLVGVTQNFAATVLRNTKGN | ||||
| VRFVIGREKPGQVSE | ||||
| 191 | KIAA1284 | 6331369 | KDVNVYVNPKKLTVIKAKEQLK | |
| domain 1 | LLEVLVGIIHQTKWSWRRTGKQ | |||
| GDGERLVVHGLLPGGSAMKSGQ | ||||
| VLIGDVLVAVNDVDVTTENIER | ||||
| VLSCIPGPMQVKLTFENAYDVK | ||||
| RET | ||||
| 192 | KIAA1389 | 7243158 | TRGCETVEMTLRRNGLGQLGFH | |
| domain 1 | VNFEGIVADVEPFGFAWKAGLR | |||
| QGSRLVEICKVAVATLTHEQMI | ||||
| DLLRTSVTVKVVIIQPHDDGSP | ||||
| RR | ||||
| 193 | KIAA1415 | 7243210 | VENILAKRLLILPQEEDYGFDI | |
| domain 1 | EEKNKAVVVKSVQRGSLAEVAG | |||
| LQVGRKIYSINEDLVFLRPFSE | ||||
| VESILNQSFCSRRPLRLLVATK | ||||
| AKEIIKIP | ||||
| 194 | KIAA1526 | 5817166 | PDSAGPGEVRLVSLRRAKAHEG | |
| domain 1 | LGFSIRGGSEHGVGIYVSLVEP | |||
| GSLAEKEGLRVGDQILRVNDKS | ||||
| LARVTHAEAVKALKGSKKLVLS | ||||
| VYSAGRIPGGYVTNH | ||||
| 195 | KIAA1526 | 5817166 | LQGGDEKKVNLVLGDGRSLGLT | |
| domain 2 | IRGGAEYGLGIYITGVDPGSEA | |||
| EGSGLKVGDQILEVNGRSFLNI | ||||
| LHDEAVRLLKSSRHLILTVKDV | ||||
| GRLPHARTTVDE | ||||
| 196 | KIAA1620 | 10047316 | LRRAELVEIIVETEAQTGVSGI | |
| domain 1 | NVAGGGKEGIFVRELREDSPAA | |||
| RSLSLQEGDQLLSARVFFENFK | ||||
| YEDALRLLQCAEPYKVSFCLKR | ||||
| TVPTGDLALR | ||||
| 197 | KIAA1719 | 1267982 | IQTTGAVSYTVELKRYGGPLGI | |
| domain 5 | TISGTEEPFDPIVISGLTKRGL | |||
| AERTGAIHVGDRILAINNVSLK | ||||
| GRPLSEAIHLLQVAGETVTLKI | ||||
| KKQLDR | ||||
| 198 | KIAA1719 | 1267982 | ILEMEELLLPTPLEMHKVTLHK | |
| domain 6 | DPMRHDFGFSVSDGLLEKGVYV | |||
| HTVRPDGPAHRGGLQPFDRVLQ | ||||
| VNHVRTRDFDCCLAVPLLAEAG | ||||
| DVLELIISRKPHTAHSS | ||||
| 199 | KIAA1719 | 1267982 | IHTVANASGPLMVEIVKTPGSA | |
| domain 2 | LGISLTTTSLRNKSVITIDRIK | |||
| PASVVDRSGALHPGDHILSIDG | ||||
| TSMEHCSLLEATKLLASISEKV | ||||
| RLEILPVPQSQRPL | ||||
| 200 | KIAA1719 | 1267982 | ITVVELIKKEGSTLGLTISGGT | |
| domain 1 | DKDGKPRVSNLRPGGLAARSDL | |||
| LNIGDYIRSVNGIHLTRLRHDE | ||||
| IITLLKNVGERVVLEVEY | ||||
| 201 | KIAA1719 | 1267982 | IQIVHTETTEVVLCGDPLSGFG | |
| domain 3 | LQLQGGIFATETLSSPPLVCFI | |||
| EPDSPAERCGLLQVGDRVLSIN | ||||
| GIATEDGTMEEANQLLRDAALA | ||||
| HKVVLEVEFDVAESV | ||||
| 202 | KIAA1719 | 1267982 | ILDVSLYKEGNSFGFVLRGGAH | |
| domain 1 | EDGHKSRPLVLTYVRPGGPADR | |||
| EGSLKVGDRLLSVDGIPLHGAS | ||||
| HATALATLRQCSHEALFQVEYD | ||||
| VATP | ||||
| 203 | KIAA1719 | 1267982 | QFDVAESVIPSSGTFHVKLPKK | |
| domain 4 | RSVELGITISSASRKRGEPLII | |||
| SDIKKGSVAHRTGTLEPGDKLL | ||||
| AIDNIRLDNCPMEDAVQILRQC | ||||
| EDLVKLKIRKDEDN | ||||
| 204 | LIM mystique | 12734250 | MALTVDVAGPAPWGFRITGGRD | |
| domain 1 | FHTPIMVTKVAERGKAKDADLR | |||
| PGDIIVAINGESAEGMLHAEAQ | ||||
| SKIRQSPSPLRLQLDRSQATSP | ||||
| GQT | ||||
| 205 | LIM protein | 3108092 | SNYSVSLVGPAPWGFRLQGGKD | |
| domain 1 | FNMPLTISSLKDGGKAAQANVR | |||
| IGDVVLSIDGINAQGMTHLEAQ | ||||
| NKIKGCTGSLNMTLQRAS | ||||
| 206 | LIMK1 | 4587498 | TLVEHSKLYCGHCYYQTVVTPV | |
| domain 1 | IEQILPDSPGSHLPHTVTLVSI | |||
| PASSHGKRGLSVSIDPPHGPPG | ||||
| CGTEHSHTVRVQGVDPGCMSPD | ||||
| VKNSIHVGDRILEINGTPIRNV | ||||
| PLDEIDLLIQETSRLLQLTLEH | ||||
| D | ||||
| 207 | LIMK2 | 1805593 | PYSVTLISMPATTEGRRGFSVS | |
| domain 1 | VESACSNYATTVQVKEVNRMHI | |||
| SPNNRNAIHPGDRILEINGTPV | ||||
| RTLRVEEVEDAISQTSQTLQLL | ||||
| IEHD | ||||
| 208 | LIM-RIL | 1085021 | IHSVTLRGPSPWGFRLVGRDFS | |
| domain 1 | APLTISRVHAGSKASLAALDPG | |||
| DLIQAINGESTELMTHLEAQNR | ||||
| IKGCHDHLTLSVSRPE | ||||
| 209 | LU-1 domain 1 | U52111 | VCYRTDDEEDLGIYVGEVNPNS | |
| IAAKDGRIREGDRIIQINGVDV | ||||
| QNREEAVAILSQEENTNISLLV | ||||
| ARPESQLA | ||||
| 210 | MAGI 1 | 3370997 | IPATQPELITVHIVKGPMGFGF | |
| domain 2 | TIADSPGGGGQRVKQIVDSPRC | |||
| RGLKEGDLIVEVNKKNVQALTH | ||||
| NQVVDMLVECPKGSEVTLLVQR | ||||
| GGNSS | ||||
| 211 | MAGI 1 | 3370997 | IPDYQEQDIFLWRKETGFGFRI | |
| domain 5 | LGGNEPGEPIYIGHIVPLGAAD | |||
| TDGRLRSGDELICVDGTPVIGK | ||||
| SHQLVVQLMQQAAKQGHVNLTV | ||||
| RRKVVFAVPKTENSS | ||||
| 212 | MAGI 1 | 3370997 | IPGVVSTVVQPYDVEIRRGENE | |
| domain 4 | GFGFVIVSSVSRPEAGTTFAGN | |||
| ACVAMPHKIGRIIEGSPADRCG | ||||
| KLKVGDRILAVNGCSITNKSHS | ||||
| DIVNLIKEAGNTVTLRIIPGDE | ||||
| SSNAEFIVTD | ||||
| 213 | MAGI 1 | 3370997 | IPSELKGKFIHTKLRKSSRGFG | |
| domain 1 | FTVVGGDEPDEFLQIKSLVLDG | |||
| PAALDGKMETGDVIVSVNDTCV | ||||
| LGHTHAQVVKIFQSIPIGASVD | ||||
| LELCRGYPLPFDPDGIHRD | ||||
| 214 | MAGI 1 | 3370997 | QATQEQDFYTVELERGAKGFGF | |
| domain 3 | SLRGGREYNMDLYVLRLAEDGP | |||
| AERCGKMRIGDEILEINGETTK | ||||
| NMKHSRAIELIKNGGRRVRLFL | ||||
| KRG | ||||
| 215 | Magi 2 | 2947231 | REKPLFTRDASQLKGTFLSTTL | |
| domain 1 | KKSNMGFGFTIIGGDEPDEFLQ | |||
| VKSVIPDGPAAQDGKMETGDVI | ||||
| VYINEVCVLGHTHADVVKLFQS | ||||
| VPIGQSVNLVLCRGYP | ||||
| 216 | Magi 2 | 2947231 | HYKELDVHLRRMESGFGFRILG | |
| domain 3 | GDEPGQPILIGAVIAMGSADRD | |||
| GRLHPGDELVYVDGIPVAGKTH | ||||
| RYVIDLMHHAARNGQVNLTVRR | ||||
| KVLCG | ||||
| 217 | Magi 2 | 2947231 | EGRGISSHSLQTSDAVIHRKEN | |
| domain 4 | EGFGFVIISSLNRPESGSTITV | |||
| PHKIGRIIDGSPADRCAKLKVG | ||||
| DRILAVNGQSIINMPHADIVKL | ||||
| IKDAGLSVTLRIIPQEEL | ||||
| 218 | Magi 2 | 2947231 | LSGATQAELMTLTIVKGAQGFG | |
| domain 2 | FTIADSPTGQRVKQILDIQGCP | |||
| GLCEGDLIVEINQQNVQNLSHT | ||||
| EVVDILKDCPIGSETSLIIHRG | ||||
| GFF | ||||
| 219 | Magi 2 | 2947231 | LSDYRQPQDFDYFTVDMEKGAK | |
| domain 5 | GFGFSIRGGREYKMDLYVLRLA | |||
| EDGPAIRNGRMRVGDQIIEING | ||||
| ESTRDMTHARAIELIKSGGRRV | ||||
| RLLLKRGTGQ | ||||
| 220 | Magi 2 | 2947231 | HESVIGRNPEGQLGFELKGGAE | |
| domain 6 | NGQFPYLGEVKPGKVAYESGSK | |||
| LVSEELLLEVNETPVAGLTIRD | ||||
| VLAVIKHCKDPLRLKCVKQGGI | ||||
| HR | ||||
| 221 | MAGI 3 | 10047344 | ASSGSSQPELVTIPLIKGPKGF | |
| domain 2 | GFAIADSPTGQKVKMILDSQWC | |||
| QGLQKGDIIKEIYHQNVQNLTH | ||||
| LQVVEVLKQFPVGADVPLLILR | ||||
| GGPPSPTKTAKM | ||||
| 222 | MAGI 3 | 10047344 | QNLGCYPVELERGPRGFGFSLR | |
| domain 5 | GGKEYNMGLFILRLAEDGPAIK | |||
| DGRIHVGDQIVEINGEPTQGIT | ||||
| HTRAIELIQAGGNKVLLLLRPG | ||||
| TGLIPDHGLA | ||||
| 223 | MAGI 3 | 10047344 | LYEDKPPNTKDLDVFLRKQESG | |
| domain 3 | FGFRVLGGDGPDQSIYIGAIIP | |||
| LGAAEKDGRLRAADELMCIDGI | ||||
| PVKGKSHKQVLDLMTTAARNGH | ||||
| VLLTVRRKIFYGEKQPEDDS | ||||
| 224 | MAGI 3 | 10047344 | PSQLKGVLVRASLKKSTMGFGF | |
| domain 1 | TIIGGDRPDEFLQVKNVLKDGP | |||
| AAQDGKIAPGDVIVDINGNCVL | ||||
| GHTHADVVQMFQLVPVNQYVNL | ||||
| TLCRGYPLPDDSED | ||||
| 225 | MAGI 3 | 10047344 | PAPQEPYDVVLQRKENEGFGFV | |
| domain 4 | ILTSKNKPPPGVIPHKIGRVIE | |||
| GSPADRCGKLKVGDHISAVNGQ | ||||
| SIVELSHDNIVQLIKDAGVTVT | ||||
| LTVIAEEEHHGPPS | ||||
| 226 | MAST1 | 4589589 | GLRSPITIQRSGKKYGFTLRAI | |
| domain 1 | RVYMGDTDVYSVHHIVWHVEEG | |||
| GPAQEAGLCAGDLITHVNGEPV | ||||
| HGMVHPEVVELILKSGNKVAVT | ||||
| TTPFEN | ||||
| 227 | MAST2 | 3882334 | ISALGSMRPPIIIHRAGKKYGF | |
| domain 1 | TLRAIRVYMGDSDVYTVHHMVW | |||
| HVEDGGPASEAGLRQGDLITHV | ||||
| NGEPVHGLVHTEVVELILKSGN | ||||
| KVAISTTPLENSS | ||||
| 228 | MAST3 | 3043645 | LCGSLRPPIVIHSSGKKYGFSL | |
| domain 1 | RAIRVYMGDSDVYTVHHVVWSV | |||
| EDGSPAQEAGLRAGDLITHING | ||||
| ESVLGLVHMDVVELLLKSGNKI | ||||
| SLRTTALENTSIKVG | ||||
| 229 | MAST4 | 2224546 | PHQPIVIHSSGKNYGFTIRAIR | |
| domain 1 | VYVGDSDIYTVHHIVWNVEEGS | |||
| PACQAGLKAGDLITHINGEPVH | ||||
| GLVHTEVIELLLKSGNKVSITT | ||||
| TPF | ||||
| 230 | MGC5395 | BC012477 | PAKMEKEETTRELLLPNWQGSG | |
| domain 1 | SHGLTIAQRDDGVFVQEVTQNS | |||
| PAARTGVVKEGDQIVGATIYFD | ||||
| NLQSGEVTQLLNTMGHHTVGLK | ||||
| LHRKGDRSPNSS | ||||
| 231 | MINT1 domain 1 | 2625024 | SENCKdVFIEKQKGEILGVVIV | |
| ESGWGSILPTVIIANMMHGGPA | ||||
| EKSGKLNIGDQIMSINGTSLVG | ||||
| LPLSTCQSIIKGLKNQSRVKLN | ||||
| IVRCPPVNSS | ||||
| 232 | MINT1 domains | 2625024 | SENCKDVFIEKQKGEILGVVIV | |
| 1 and 2 | ESGWGSILPTVIIANMMHGGPA | |||
| EKSGKLNIGDQIMSINGTSLVG | ||||
| LPLSTCQSIIKGLENQSRVKLN | ||||
| IVRCPPVTTVLIRRPDLRYQLG | ||||
| FSVQNGIICSLMRGGIAERGGV | ||||
| RVGHRIIEINGQSVVATPHEKI | ||||
| VHILSNAVGEIHMKTMPAAMYR | ||||
| LL | ||||
| 233 | MINT1 domain 2 | 2625024 | LRCPPVTTVLIRRPDLRYQLGF | |
| SVQNGIICSLMRGGIAERGGVR | ||||
| VGHRIIEINGQSVVATPHEKIV | ||||
| HILSNAVGEIHMKTMPAAMYRL | ||||
| LNSS | ||||
| 234 | MINT3 domain 1 | 3169808 | HNGDLDHFSNSDNCREVHLEKR | |
| RGEGLGVALVESGWGSLLPTAV | ||||
| IANLLHGGPAERSGALSIGDRL | ||||
| TAINGTSLVGLPLAACQAAVRE | ||||
| TKSQTSVTLSIVHCPPVT | ||||
| 235 | MINT3 domain 2 | 3169808 | PVTTAIIHRPHAREQLGFCVED | |
| GIICSLLRGGIAERGGIRVGHR | ||||
| IIEINGQSVVATPHARIIELLT | ||||
| EAYGEVHIKTMPAATYRLLTGN | ||||
| SS | ||||
| 236 | MINT3 domain 1 | 3169808 | LSNSDNCREVHLEKRRGEGLGV | |
| ALVESGWGSLLPTAVIANLLHG | ||||
| GPAERSGALSIGDRLTAINGTS | ||||
| LVGLPLAACQAAVRETKSQTSV | ||||
| TLSIVHCPPVTTAIM | ||||
| 237 | MPP1 domain 1 | 189785 | RKVRLIQFEKVTEEPMGITLKL | |
| NEKQSCTVARILHGGMIHRQGS | ||||
| LHVGDEILEINGTNVTNHSVDQ | ||||
| LQKAMKETKGMISLKVIPNQ | ||||
| 238 | MPP2 domain 1 | 939884 | PVPPDAVRMVGIRKTAGEHLGV | |
| TFRVEGGELVIARILHGGMVAQ | ||||
| QGLLHVGDIIKEVNGQPVGSDP | ||||
| RALQELLRNASGSVILKILPNY | ||||
| Q | ||||
| 239 | MPP3 domain 1 | 21536463 | NIDEDFDEESVKIVRLVKNKEP | |
| LGATIRRDEHSGAVVVARIMRG | ||||
| GAADRSGLVHVGDELREVNGIA | ||||
| VLHKRPDEISQILAQSQGSITL | ||||
| KIIPATQEEDR | ||||
| 240 | MUPP1 domain 5 | 2104784 | WEAGIQHIELEKGSKGLGFSIL | |
| DYQDPIDPASTVIIIRSLVPGG | ||||
| IAEKDGRLLPGDRLMFVNDVNL | ||||
| ENSSLEEAVEALKGAPSGTVRI | ||||
| GVAKPLPLSPEE | ||||
| 241 | MUPP1 domain 12 | 2104784 | LQGLRTVEMKKGPTDSLGISIA | |
| GGVGSPLGDVPIFIAMMHPTGV | ||||
| AAQTQKLRVGDRIVTICGTSTE | ||||
| GMTHTQAVNLLKNASGSIEMQV | ||||
| VAGGDVSV | ||||
| 242 | MUPP1 domain 2 | 2104784 | PVHWQHMETIELVNDGSGLGFG | |
| IIGGKATGVIVKTILPGGVADQ | ||||
| HGRLCSGDHILKIGDTDLAGMS | ||||
| SEQVAQVLRQCGNRVKLMIARG | ||||
| AIEERTAPT | ||||
| 243 | MUPP1 domain 3 | 2104784 | QESETFDVELTKNVQGLGITIA | |
| GYIGDKKLEPSGIFVKSITKSS | ||||
| AVEHDGRIQIGDQIIAVDGTNL | ||||
| QGFTNQQAVEVLRHTGQTVLLT | ||||
| LMRRGMKQEA | ||||
| 244 | MUPP1 domain 11 | 2104784 | KEEEVCDTLTIELQKKPGKGLG | |
| LSIVGKRNDTGVFVSDIVKGGI | ||||
| ADADGRLMQGDQILMVNGEDVR | ||||
| NATQEAVAALLKCSLGTVTLEV | ||||
| GRIKAGPFHS | ||||
| 245 | MUPP1 domain 8 | 2104784 | LTGELHMIELEKGHSGLGLSLA | |
| GNKDRSRMSVFIVGIDPNGAAG | ||||
| KDGRLQIADELLEINGQILYGR | ||||
| SHQNASSIIKCAPSKVKIIFIR | ||||
| NKDAVNQ | ||||
| 246 | MUPP1 domain 13 | 2104784 | LGPPQCKSITLERGPDGLGFSI | |
| VGGYGSPHGDLPIYVKTVFAKG | ||||
| AASEDGRLKRGDQIIAVNGQSL | ||||
| EGVTHEEAVAILKRTKGTVTLM | ||||
| VLS | ||||
| 247 | MUPP1 domain 6 | 2104784 | RNVSKESFERTINIAKGNSSLG | |
| MTVSANKDGLGMIVRSIIHGGA | ||||
| ISRDGRIAIGDCILSINEESTI | ||||
| SVTNAQARAMLRRHSLIGPDIK | ||||
| ITYVPAEHLEE | ||||
| 248 | MUPP1 domain 10 | 2104784 | LPGCETTIEISKGRTGLGLSIV | |
| GGSDTLLGAIIIHEVYEEGAAC | ||||
| KDGRLWAGDQILEVNGIDLRKA | ||||
| THDEAINVLRQTPQRVRLTLYR | ||||
| DEAPYKE | ||||
| 249 | MUPP1 domain 7 | 2104784 | LNWNQPRRVELWREPSKSLGIS | |
| IVGGRGMGSRLSNGEVMRGIFI | ||||
| KHVLEDSPAGKNGTLKPGDRIV | ||||
| EVDGMDLRDASHEQAVEAIRKA | ||||
| GNPVVFMVQSIINRPRKSPLPS | ||||
| LL | ||||
| 250 | MUPP1 domain 9 | 2104784 | LSSFKNVQHLELPKDQGGLGIA | |
| ISEEDTLSGVIIKSLTEHGVAA | ||||
| TDGRLKVGDQILAVDDEIVVGY | ||||
| PIEKFISLLKTAKMTVKLTIHA | ||||
| ENPDSQ | ||||
| 251 | MUPP1 domain 1 | 2104784 | QGRHVEVFELLKPPSGGLGFSV | |
| VGLRSENRGELGIFVQEIQEGS | ||||
| VAHRDGRLKETDQILAINGQAL | ||||
| DQTITHQQAISILQKAKDTVQL | ||||
| VIARGSLPQLV | ||||
| 252 | MUPP1 domain 4 | 2104784 | LNYEIVVAHVSKFSENSGLGIS | |
| LEATVGHHFIRSVLPEGPVGHS | ||||
| GKLFSGDELLEVNGITLLGENH | ||||
| QDVVNILKELPIEVTMVCCRRT | ||||
| VPPT | ||||
| 253 | NeDLG domain 2 | 10863920 | ITLLKGPKGLGFSIAGGIGNQH | |
| IIPGDNSIYITKIIEGGAAQKD | ||||
| GRLQIGDRLLAVNNTNLQDVRH | ||||
| EEAVASLKNTSDMVYLKVAKPG | ||||
| SLE | ||||
| 254 | NeDLG domain 1 | 10863920 | IQYEEIVLERGNSGLGFSIAGG | |
| IDNPHVPDDPGIFITKIIPGGA | ||||
| AAMDGRLGVNPCVLRVNEVEVS | ||||
| EVVHSRAVEALKEAGPVVRLVV | ||||
| RRRQN | ||||
| 255 | NeDLG domain 3 | 10863920 | ILLHKGSTGLGFNIVGGEDGEG | |
| IFVSFILAGGPADLSGELRRGD | ||||
| RILSVNGVNLRNATHEQAAAAL | ||||
| KRAGQSVTIVAQYRPEEYSRFE | ||||
| SKIHDLREQMMNSSMSSGSGSL | ||||
| RTSEKRSLE | ||||
| 256 | NeDLG domains | 10863920 | YEEIVLERGNSGLGFSIAGGID | |
| 1 and 2 | NPHVPDDPGIFITKIIIPGGAA | |||
| AMDGRLGVNDCVLRVNEVEVSE | ||||
| VVHSRAVEALKEAGPVVRLVVR | ||||
| RRQPPPETIMEVNLLKGPKGLG | ||||
| FSIAGGIGNQHIPGDNSIYITK | ||||
| IIEGGAAQKDGRLQIGDRLLAV | ||||
| NNTNLQDVRHEEAVASLKNTSD | ||||
| MVYLKVAKPGSL | ||||
| 257 | Neurabin II | AJ401189 | RVERLELFPVELEKDSEGLGIS | |
| domain 1 | IIGMGAGADMGLEKLGIFVKTV | |||
| TEGGAAHRDGRIQVNDLLVEVD | ||||
| GTSLVGVTQSFAASVLRNTKGR | ||||
| VRCRFMIGRERPGEQSEV | ||||
| 258 | NOS1 domain 1 | 642525 | QPNVISVRLFKRKVGGLGFLVK | |
| ERVSKPPVIISDLIRGGAAEQS | ||||
| GLIQAGDIILAVNGRPLVDLSY | ||||
| DSALEVLRGIASETHVVLILRG | ||||
| PE | ||||
| 259 | novel PDZ gene | 7228177 | PSDTSSEDGVRRIVHLYTTSDD | |
| domain 2 | FCLGFNIRGGKEFGLGIYVSKV | |||
| DHGGLAEENGIKVGDQVLAANG | ||||
| VRFDDISHSQAVEVLKGQTHIM | ||||
| LTIKETGRYPAYKEM | ||||
| 260 | novel PDZ gene | 7228177 | EANSDESDIIHSVRVEKSPAGR | |
| domain 1 | LGFSVRGGSEHGLGIFVSKVEE | |||
| GSSAERAGLCVGDKITEVNGLS | ||||
| LESTTMGSAVKVLTSSSRLHMM | ||||
| VRRMGRVPGIKFSKEK | ||||
| 261 | novel serine | 1621243 | DKIKKFLTESHDRQAKGKAITK | |
| protease | KKYIGIRMMSLTSSKAKELKDR | |||
| domain 1 | HRDFPDVISGAYIIEVIPDTPA | |||
| EAGGLKENDVIISINGQSVVSA | ||||
| NDVSDVIKRESTLNMVVRRGNE | ||||
| DIMITV | ||||
| 262 | Numb BP | AK056823 | YRPRDDSFHVILNKSSPEEQLG | |
| domain 2 | IKLVRKVDEPGVFIFNALDGGV | |||
| AYRHGQLEENDRVLAINGHDLR | ||||
| YGSPESAAHLIQASERRVHLVV | ||||
| SRQVRQRSPD | ||||
| 263 | Numb BP | AK056823 | PTITCHEKVVNIQKDPGESLGM | |
| domain 3 | TVAGGASHREWDLPIYVISVEP | |||
| GGVISRDGRIKTGDILLNVDGV | ||||
| ELTEVSRSEAVALLKRTSSSIV | ||||
| LKALEVKEYEPQ | ||||
| 264 | Numb BP | AK056823 | PDGEITSIKINRVDPSESLSIR | |
| domain 1 | LVGGSETPLVHIIIQHIYRDGV | |||
| IARDGRLLPRDIILKVNGMDIS | ||||
| NVPHNYAVRLLRQPCQVLWLTV | ||||
| MREQKFRSR | ||||
| 265 | Numb BP | AK056823 | PRCLYNCKDIVLRRNTAGSLGF | |
| domain 4 | CIVGGYEEYNGNKPFFIKSIVE | |||
| GTPAYNDGRIRCGDILLAVNGR | ||||
| STSGMIHACLARLLKELKGRIT | ||||
| LTIVSWPGTFL | ||||
| 266 | outer | 7023825 | LLTEEEINLTRGPSGLGFNIVG | |
| membrane | GTDQQYVSNDSGIYVSRIKENG | |||
| domain 1 | AAALDGRLQEGDKILSVNGQDL | |||
| KNLLHQDAVDLFRNAGYAVSLR | ||||
| VQHRLQVQNGIHS | ||||
| 267 | p55T domain 1 | 12733367 | PVDAIRILGIHKRAGEPLGVTF | |
| RVENNDLVIARILHGGMIDRQG | ||||
| LLHVGDIIKEVNGHEVGNNPKE | ||||
| LQELLKNISGSVTLKILPSYRD | ||||
| TITPQQ | ||||
| 268 | PAR3 domain 2 | 8037914 | GKRLNIQLKKGTEGLGFSITSR | |
| DVTIGGSAPIYVKNILPRGAAI | ||||
| QDGRLKAGDRLIEVNGVDLVGK | ||||
| SQEEVVSLLRSTKMEGTVSLLV | ||||
| FRQEDA | ||||
| 269 | PAR3 domain 1 | 8037914 | IPNFSLDDMVKLVEVPNDGGPL | |
| GIHVVPFSARGGRTLGLLVKRL | ||||
| EKGGKAEHENLFRENDCIVRIN | ||||
| DGDLRNRRFEQAQHMFRQAMRT | ||||
| PIIWFHVVPAANKEQYEQ | ||||
| 270 | PAR3 domain 3 | 8037914 | PREFLTFEVPLNDSGSAGLGVS | |
| VKGNRSKENHADLGIFVKSIIN | ||||
| GGAASKDGRLRVNDQLIAVNGE | ||||
| SLLGKTNQDAMETLRRSMSTEG | ||||
| NKRGMIQLIVASRISKCNELKS | ||||
| NSS | ||||
| 271 | PAR3L domain 2 | 18874467 | ISNKNAKKIKIDLKKGPEGLGF | |
| TVVTRDSSIHGPGPIFVKNILP | ||||
| KGAAIKDGRLQSGDRILEVNGR | ||||
| DVTGRTQEELVAMLRSTKQGET | ||||
| ASLVIARQEGH | ||||
| 272 | PAR3L domain 3 | 18874467 | ITSEQLTFEIPLNDSGSAGLGV | |
| SLKGNKSRETGTDLGIFIKSII | ||||
| HGGAAFKDGRLRMNDQLIAVNG | ||||
| ESLLGKSNHEAMETLRRSMSME | ||||
| GNIRGMIQLVILRRPERP | ||||
| 273 | PAR3L domain 1 | 18874467 | IPRTKDTLSDMTRTVEISGEGG | |
| PLGIHVVPFFSSLSGRILGLFI | ||||
| RGIEDNSRSKREGLFHENECIV | ||||
| KINNVDLVDKTFAQAQDVFRQA | ||||
| MKSPSVLLHVLPPQNR | ||||
| 274 | PAR6 domain 1 | 2613011 | PETHRRVRLHKHGSDRPLGFYI | |
| RDGMSVRVAPQGLERVPGIFIS | ||||
| RLVRGGLAESTGLLAVSDEILE | ||||
| VNGIEVAGKTLDQVTDMMVANS | ||||
| HNLIVTVKPANQRNNV | ||||
| 275 | PAR6 beta | 1353716 | IPVSSIIDVDILPETHRRVRLY | |
| domain 1 | KYGTEKPLGFYIRDGSSVRVTP | |||
| HGLEKVPGIFISRLVPGGLAQS | ||||
| TGLLAVNDEVLEVNGIEVSGKS | ||||
| LDQVTDMMIANSRNLIITVRPA | ||||
| NQRNNRIHRD | ||||
| 276 | PAR6 GAMMA | 13537118 | IDVDLVPETHRRVRLHRHGCEK | |
| domain 1 | PLGFIRDGASVRVTPHGLEKVP | |||
| GIFISRMVPGGLAESTGLLAVN | ||||
| DEVLEVNGIEVAGKTLDQVTDM | ||||
| MIANSHNLIVTVKPANQRNNVV | ||||
| 277 | PDZ-73 | 5031978 | PEQIMGKDVRLLRIKKEGSLDL | |
| domain 3 | ALEGGVDSPIGKVVVSAVYERG | |||
| AAERHGGIVKGDEIMAINGKIV | ||||
| TDYTLAEADAALQKAWNQGGDW | ||||
| IDLVVAVCPPKEYDD | ||||
| 278 | PDZ-73 | 5031978 | IPGNRENKEKKVFISLVGSRGL | |
| domain 2 | GCSISSGPIQKPGIFISHVKPG | |||
| SLSAEVGLEIGDQIVEVNGVDF | ||||
| SNLDHKEAVNVLKSSRSLTISI | ||||
| VAAAGRELFMTDEF | ||||
| 279 | PDZ-73 | 5031978 | RSRKLKEVRLDRLHPEGLGLSV | |
| domain 1 | RGGLEFGCGLFISHLIKGGQAD | |||
| SVGLQVGDEIVRINGYSISSCT | ||||
| HEEVINLIRTKKTVSIKVRHIG | ||||
| LIPVKSSPDEFH | ||||
| 280 | PDZK1 | 2944188 | RLCYLVKEGGSYGFSLKTVQGK | |
| domain 2 | KGVYMTDITPQGVAMRAGVLAD | |||
| DHLIEVNGENVEDASHEEVVEK | ||||
| VKKSGSRVMFLLVDKETDKREF | ||||
| IVTD | ||||
| 281 | PDZK1 | 2944188 | QFKRETASLKLLPHQPRIVEMK | |
| domain 3 | KGSNGYGFYLRAGSEQKGQIIK | |||
| DIDSGSPAEEAGLKNNDLVVAV | ||||
| NGESVETLDHDSVVEMIRKGGD | ||||
| QTSLLVVDKETDNMYRLAEFIV | ||||
| TD | ||||
| 282 | PDZK1 domains | 2944188 | RLCYLVKEGGSYGFSLKTVQGK | |
| 2 and 3 and 4 | KGVYMTDITPQGVAMRAGVLAD | |||
| DHLIEVNGENVEDASHEKVVEK | ||||
| VKKSGSRVMFLLVDKETDKRHV | ||||
| EQKIQFKRETASLKLLPHQPRI | ||||
| VEMKKGSNGYGFYLRAGSEQKG | ||||
| QIIKDIDSGSPAEEAGLKNNDL | ||||
| VVAVNGESVETLDHDSVVEMIR | ||||
| KGGDQTSLLVVDKETDNMYRLA | ||||
| HFSPFLYYQSQELPNGSVKEAP | ||||
| APTPTSLEVSSPPDTTEEVDHK | ||||
| PKLCRLAKGENGYGFHLNAIRG | ||||
| LPGSFIKEVQKGGPADLAGLED | ||||
| EDVIIEVNGVNVLDEPYEKVVD | ||||
| RIQSSGKNVTLLVCGK | ||||
| 283 | PDZK1 | 2944188 | PDTTEEVDHKPKLCRLAKGENG | |
| domain 4 | YGFHLNAIRGLPGSFIKEVQKG | |||
| GPADLAGLEDEDVIIEVNGVNV | ||||
| LDEPYEKVVDRIQSSGKNVTLL | ||||
| VGKNSS | ||||
| 284 | PDZK1 | 2944188 | LTSTFNPRECKLSKQEGQNYGF | |
| domain 1 | FLRIEKDTEGHLVRVVEKCSPA | |||
| EKAGLQDGDRVLRINGVFVDKE | ||||
| EHMQVVDLVRKSGNSVTLLVLD | ||||
| GDSYEKAGSHEPS | ||||
| 285 | PICK1 | 4678411 | LGIPTVPGKVTLQKDAQNLIGI | |
| domain 1 | SIGGGAQYCPCLYIVQVFDNTP | |||
| AALDGTVAAGDEITGVNGRSIK | ||||
| GKTKVEVAKMIQEVKGEVTIHY | ||||
| NKLQADPKQGM | ||||
| 286 | PIST domain 1 | 98374330 | SQGVGPIRKVLLLKEDHEGLGI | |
| SITGGKEHGVPILISEIHPGQP | ||||
| ADRCGGLHVGDAILAVNGVNLR | ||||
| DTKHKEAVTILSQQRGEIEFEV | ||||
| VYVAPEVDSD | ||||
| 287 | prIL16 | 1478492 | TAEATVCTVTLEKMSAGLGFSL | |
| domain 2 | EGGKGSLHGDKPLTINRIFKGA | |||
| ASEQSETVQPGDEILQLGGTAM | ||||
| QGLTRFEAWNIIKALPDGPVTI | ||||
| VIRRKSLQSK | ||||
| 288 | prIL16 | 1478492 | IHVTILHKEEGAGLGFSLAGGA | |
| domain 1 | DLENKVITVHRVFPNGLASQEG | |||
| TIQKGNEVLSINGKSLKGTTHH | ||||
| DALAILRQAREPRQAVIVTRKL | ||||
| TPEEFIVTD | ||||
| 289 | prIL16 domains | 1478492 | IHVTILHKEEGAGLGFSLAGGA | |
| 1 and 2 | DLENKVITVHRVFPNGLASQEG | |||
| TIQKGNEVLSINGKSLKGTTHH | ||||
| DALAILRQAREPRQAVIVTRKL | ||||
| TPEAMPDLNSSTDSAASASAAS | ||||
| DVSVESTAEATVCTVTLEKMSA | ||||
| GLGFSLEGGKGSLHGDKPLTIN | ||||
| RIFKGAASEQSETVQPGDEILQ | ||||
| LGGTAMQGLTRFEAWNIIKALP | ||||
| DGPVTIVRRKSLQSK | ||||
| 290 | PSAP domain 1 | 6409315 | IREAKYSGVLSSIGKIFKEEGL | |
| LGFFVGLIPHLLGDVVFLWGCN | ||||
| LLAHFINAYLVDDSVSDTPGGL | ||||
| GNDQNPGSQFSQALAIRSYTKF | ||||
| VMGIAVSMLTYPFLLVGDLMAV | ||||
| NNCGLQAGLPPYSPVFKSWIHC | ||||
| WKYLSVQGQLFRGSSLLFRRVS | ||||
| SGSCFALE | ||||
| 291 | PSD95 domains | 3318652 | EGEMEYEEITLERGNSGLGFSI | |
| 1 and 2 and 3 | AGGTDNPHIGDDPSIFITKIIP | |||
| GGAAAQDGRLRVNDSILFVNEV | ||||
| DVREVTHSAAVEALKEAGSIVR | ||||
| LYVMRRKPPAEKVMEIKLIKGP | ||||
| KGLGFSIAGGVGNQHIPGDNSI | ||||
| YVTKIIEGGAAHKDGRLQIGDK | ||||
| ILAVNSVGLEDVMHEDAVAALK | ||||
| NTYDVVYLKVAKPSNAYLSDSY | ||||
| APPDITTSYSQHLDNEISHSSY | ||||
| LGTDYPTAMTPTSPRRYSPVAK | ||||
| DLLGEEDIPREPRRIVIHRGST | ||||
| GLGFNIVGGEDGEGIFISFILA | ||||
| GGPADLSGELRKGDQILSVNGV | ||||
| DLRNASHEQAAIALKNAGQTVT | ||||
| IIAQYKPE | ||||
| 292 | PSD95 | 3318652 | HVMRRKPPAEKVMEIKLIKGPK | |
| domain 2 | GLGFSIAGGVGNQHIPGDNSIY | |||
| VTKIIEGGAAHKDGRLQIGDKI | ||||
| LAVNSVGLEDVMHEDAVAALKN | ||||
| TYDVVYLKVAKPSNAYL | ||||
| 293 | PSD95 | 3318652 | REDIPREPRRIVIHRGSTGLGF | |
| domain 3 | NIVGGEDGEGIFISFILAGGPA | |||
| DLSGELRKGDQILSVNGVDLRN | ||||
| ASHEQAAIALKNAGQTVTIIAQ | ||||
| YKPEFIVTD | ||||
| 294 | PSD95 | 3318652 | LEYEeITLERGNSGLGFSIAGG | |
| domain 1 | TDNPHIGDDPSIFITKIIPGGA | |||
| AAQDGRLRVNDSILFVNEVDVR | ||||
| EVTHSAAVEALKEAGSIVRLYV | ||||
| MRRKPPAENSS | ||||
| 295 | PSMD9 domain 1 | 9184389 | RDMAEAHKEAMSRKLGQSESQG | |
| PPRAFAKVNSISPGSPASIAGL | ||||
| QVDDEIVEFGSVNTQNFQSLHN | ||||
| IGSVVQHSEGALAPTILLSVSM | ||||
| 296 | PTN-3 domain 1 | 179912 | QNDNGDSYLVLIRITPDEDGKF | |
| GFNLKGGVDQKMPLVVSRINPE | ||||
| SPADTCIPKLNEGDQIVLINGR | ||||
| DISEHTHDQVVMFIKASRESHS | ||||
| RELALVIRRRAVRS | ||||
| 297 | PTN-4 domain 1 | 190747 | IRMKPDENGRFGFNVKGGYDQK | |
| MPVIVSRVAPGTPADLCVPRLN | ||||
| EGDQVVLINGRDIAEHTHDQVV | ||||
| LFIKASCERHSGELMLLVRPNA | ||||
| 298 | PTPL1 domain 2 | 515030 | GDIFEVELAKNDNSLGISVTGG | |
| VNTSVRHGGIYVKAVIPQGAAE | ||||
| SDGRIHKGDRVLAVNGVSLEGA | ||||
| THKQAVETLRNTGQVVHLLLEK | ||||
| GQSPTSK | ||||
| 299 | PTPL1 domain 1 | 515030 | PEREITLVNLKKDAKYGLGFQI | |
| IGGEKMGRLDLGIFISSVAPGG | ||||
| PADFHGCLKPGDRLISVNSVSL | ||||
| EGVSHHAAIEILQNAPEDVTLV | ||||
| ISQPKEKISKVPSTPVHL | ||||
| 300 | PTPL1 domain 4 | 515030 | ELEVELLITLIKSEKASLGFTV | |
| TKGNQRIGCYVHDVIQDPAKSD | ||||
| GRLKPGDRLIKVNDTDVTNMTH | ||||
| TDAVNLLRAASKTVRLVIGRVL | ||||
| ELPRIPMLPH | ||||
| 301 | PTPL1 domain 3 | 515030 | TEENTFEVKLFKNSSGLGFSFS | |
| REDNLIPEQINASIVRVKKLFA | ||||
| GQPAAESGKIDVGDVILKVNGA | ||||
| SLKGLSQQEVISALRGTAPEVF | ||||
| LLLCRPPPGVLPEIDT | ||||
| 302 | PTPL1 domain 5 | 515030 | MLPHLLPDITLTCNKEELGFSL | |
| CGGHDSLYQVVYISDINPRSVA | ||||
| AIEGNLQLLDVIHYVNGVSTQG | ||||
| MTLEEVNRALDMSLPSLVLKAT | ||||
| RNDLPV | ||||
| 303 | RGS 3 domain 1 | 18644735 | VCSERRYRQITIPRGKDGFGFT | |
| ICCDSPVRVQAVDSGGPAERAG | ||||
| LQQLDTVLQLNERPVEHWKCVE | ||||
| LAHEIRSCPSEIILLVWRMVPQ | ||||
| VKPG | ||||
| 304 | RGS12 domain 1 | 3290015 | RPSPPRVRSVEVARGRAGYGFT | |
| LSGQAPCVLSCVMRGSPADFVG | ||||
| LRAGDQILAVNEINVKKASHED | ||||
| VVKLIGKCSGVLHMVIAEGVGR | ||||
| FESCS | ||||
| 305 | Rho-GAP 10 | 50345878 | SEDETFSWPGPKTVTLKRTSQG | |
| domain 1 | FGFTLRHFIVYPPESAIQFSYK | |||
| DEENGNRGGKQRNRLEPMDTIF | ||||
| VKQVKEGGPAFEAGLCTGDRII | ||||
| KVNGESVIGKTYSQVIALIQNS | ||||
| DTTLELSVMPKDED | ||||
| 306 | Rhophilin | AY082588 | SAKNRWRLVGPVHLTRGEGGFG | |
| domain 1 | LTRGDSPVLIAAVIPGSQAAAA | |||
| GLKEGDYIVSVNGQPCRWWRHA | ||||
| EVVTELKAAGEAGASLQVVSLL | ||||
| PSSRLPS | ||||
| 307 | Rhophilin-like | AF268032 | ISFSANKRWTPPRSIRFTAEEG | |
| domain 1 | DLGFTLRGNAPVQVHFLDPYCS | |||
| ASVAGAREGDYIVSIQLVDCKW | ||||
| LTLSEVMKLLKSFGEDEIEMKV | ||||
| VSLLDSTSSMHNKSAT | ||||
| 308 | RIM2 domain 1 | 12734165 | TLNEEHSHSDKHPVTWQPSKDG | |
| DRLIGRILLNKRLKDGSVPRDS | ||||
| GAMLGLKVVGGKMTESGRLCAF | ||||
| ITKVKKGSLADTVGHLRPGDEV | ||||
| LEWNGRLLQGATFEEVYNIILE | ||||
| SKPEPQVELVVSRPIG | ||||
| 309 | SEMCAP 3 | 5889526 | QEMDREELELEEVDLYRMNSQD | |
| domain 2 | KLGLTVCYRTDDEDDIGIYISE | |||
| IDPNSIAAKDGRIREGDRIIQI | ||||
| NGIEVQNREEAVALLTSEENKN | ||||
| FSLLIARPELQLD | ||||
| 310 | SEMCAP 3 | 5889526 | QGEETKSLTLVLHRDSGSLGFN | |
| domain 1 | IIGGRPSVDNHDGSSSEGIFVS | |||
| KIVDSGPAAKEGGLQIHDRIIE | ||||
| VNGRDLSRATHDQAVEAFKTAK | ||||
| EPIVVQVLRRTPRTKMFTP | ||||
| 311 | semcap2 | 7019938 | ILAHVKGIEKEVNVYKSEDSLG | |
| domain 1 | LTITDNGVGYAFIKRIKDGGVI | |||
| DSVKTICVGDHIESINGENIVG | ||||
| WRHYDVAKKLKELKKEELFTMK | ||||
| LIEPKKAFEI | ||||
| 312 | serine | 2738914 | RGEKKNSSSGISGSQRRYIGVM | |
| protease | MLTLSPSILAELQLREPSFPDV | |||
| domain 1 | QHGVLIHKVILGSPAHRAGLRP | |||
| GDVILAIGEQMVQNAEDVYEAV | ||||
| RTQSQLAVQIRRGRETLTLYV | ||||
| 313 | Shank 1 | 6049185 | ILEEKTVVLQKKDNEGFGFVLR | |
| domain 1 | GAKADTPIEEFTPTPAFPALQY | |||
| LESVDEGGVAWRAGLRMGDFLI | ||||
| EVNGQNVVKVGRQVVNMIRQGG | ||||
| NHLVLKVVTVTRNLDPDDNSS | ||||
| 314 | Shank 2 | 7025450 | ILKEKTVLLQKKDSEGFGFVLR | |
| domain 1 | GAKAQTPIEEFTPTPAFPALQY | |||
| LESVDEGGVAWRAGLRMGDFLI | ||||
| EVNGQNVVKVGHRQVVNMIRQG | ||||
| GNTLMVKVVMVTRHPDMDEAVQ | ||||
| NSS | ||||
| 315 | Shank 3 | * | SDYVIDDKVAVLQKRDHEGFGF | |
| domain 1 | VLRGAKAETPIEEFTPTPAFPA | |||
| LQYLESVDVEGVAWRAGLRTGD | ||||
| FLIEVNGVNVVKVGHKQVVALI | ||||
| RQGGNRLVMKVVSVTRKPEEDG | ||||
| 316 | sim to lig of | 22477649 | SNSPREEIFQVALHKRDSGEQL | |
| numb px2 | GIKLVRRTDEPGVFILDLLEGG | |||
| domain 2 | LAAQDGRLSSNDRVLAINGHDL | |||
| KYGTPELAAQIIQASGERVNLT | ||||
| IARPGKPQPG | ||||
| 317 | sim to lig of | 22477649 | IQCVTCQEKHITVKKEPHESLG | |
| numb px2 | MTVAGGRGSKSGELPIFVTSVP | |||
| domain 3 | PHGCLARDGRIKRGDVLLNING | |||
| IDLTNLSHSEAVAMLKASAASP | ||||
| AVALKALEVQIVEEAT | ||||
| 318 | Similar to | 14286261 | MGLGVSAEQPAGGAEGFHLHGV | |
| GRASP65 | QENSPAQQAGLEPYFDFIITIG | |||
| domain 1 | HSRLNKENDTLKALLKANVEKP | |||
| VKLEVFNMKTMRVREVEVVPSN | ||||
| MWGGQGLLGASVRFCSFRRASE | ||||
| 319 | Similar to | 14286261 | RASEQVWHVLDVEPSSPAALAG | |
| GRASP65 | LRPYTDYVVGSDQILQESEDFF | |||
| domain 2 | TLIESHEGKPLKLMVYNSKSDS | |||
| CRESGMWHWLWVSTPDPNSAPQ | ||||
| LPQEATWHPTTFCSTTWCPTT | ||||
| 320 | Similar to | 21595065 | ISVTDGPKFEVKLKKNANGLGF | |
| Protein- | SFVQMEKESCSHLKSDLVRIKR | |||
| Tyrosine- | LFPGQPAEENGAIAAGDIILAV | |||
| Phosphatase | NGRSTEGLIFQEVLHLLRGAPQ | |||
| Homolog | EVTLLLCRPPPGA | |||
| domain 1 | ||||
| 321 | SIP1 domain 1 | 2047327 | QPEPLRPRLCRLVRGEQGYGFH | |
| LHGEKGRRGQFIRRVEPGSPAE | ||||
| AAALRAGDRLVEVNGVNVEGET | ||||
| HHQVVQRIKAVEGQTRLLVVDQ | ||||
| ETDEELRRRNSS | ||||
| 322 | SIP1 domain 2 | 2047327 | PLRELRPRLCHLRKGPQGYGFN | |
| LHSDKSRPGQYIRSVDPGSPAA | ||||
| RSGLRAQDRLIEVNGQNVEGLR | ||||
| HAEVVASIKAREDEARLLVVDP | ||||
| ETDEHFKRNSS | ||||
| 323 | SITAC 18 | 8886071 | PGVREIHLCKDERGKTGLRLRK | |
| domain 1 | VDQGLFVQLVQANTPASLVGLR | |||
| FGDQLLQIDGRDCAGWSSHKAH | ||||
| QVVKKASGDKIVVVVRDRPFQR | ||||
| TVTM | ||||
| 324 | SITAC 18 | 8886071 | PFQRTVTMHKDSMGHVGFVIKK | |
| domain 2 | GKIVSLVKGSSAARNGLLTNHY | |||
| VCEVDGQNVIGLKDKKIMEILA | ||||
| TAGNVVTLTIIPSVIYEHIVEF | ||||
| IV | ||||
| 325 | SNPC IIa | 20809633 | SLERPRFCLLSKEEGKSFGFHL | |
| domain 1 | QQELGRAGHVVCRVDPGTSAQR | |||
| QGLQEGDRILAVNNDVVEHEDY | ||||
| AVVVRRIRASSPRVLLTVLARH | ||||
| AHDVARAQ | ||||
| 326 | SYNTENIN | 2795862 | LRDRPFERTITMHKDSTGHVGF | |
| domain 2 | IFKNGKITSIVKDSSAARNGLL | |||
| TEHNICEINGQNVIGLKDSQIA | ||||
| DILSTSGTVVTITIMPAFIFEH | ||||
| MNSS | ||||
| 327 | SYNTENIN | 2795862 | LEIKQGIREVILCKDQDGKIGL | |
| domain 1 | RLKSIDNGIFVQLVQANSPASL | |||
| VGLRFGDQVLQINGENCAGWSS | ||||
| DKAHKVLKQAFGEKITMRIHRD | ||||
| 328 | Syntrophin 1 | 1145727 | QRRRVTVRKADAGGLGISIKGG | |
| alpha domain 1 | RENKMPILISKIFKGLAADQTE | |||
| ALFVGDAILSVNGEDLSSATHD | ||||
| EAVQVLKKTGKEVVLEVKYMKD | ||||
| VSPYFK | ||||
| 329 | Syntrophin | 476700 | PVRRVRVVKQEAGGLGISIKGG | |
| beta 2 | RENRMPILISKIFPGLAADQSR | |||
| domain 1 | ALRLGDAILSVNGTDLRQATHD | |||
| QAVQALKRAGKEVLLEVKFIRE | ||||
| 330 | Syntrophin | 9507162 | EPFYSGERTVTIRRQTVGGFGL | |
| gamma 1 | SIKGGAEHNIPVVVSKISKEQR | |||
| domain 1 | AELSGLLFIGDAILQINGINVR | |||
| KCRHEEVVQVLRNAGEEVTLTV | ||||
| SFLKRAPAFLKL | ||||
| 331 | Syntrophin | 9507164 | SHQGRNRRTVTLRRQPVGGLGL | |
| gamma 2 | SIKGGSEHNVPVVISKIFEDQA | |||
| domain 1 | ADQTGMLFVGDAVLQVNGIHVE | |||
| NATHEEVVHLLRNAGDEVTITV | ||||
| EYLREAPAFLK | ||||
| 332 | TAX2-like | 3253116 | RGETKEVEVTKTEDALGLTITD | |
| protein | NGAGYAFIKRIKEGSIINRIEA | |||
| domain 1 | VCVGDSIEAINDHSIVGCRHYE | |||
| VAKMLRELPKSQPFTLRLVQPK | ||||
| RAF | ||||
| 333 | TIAM1 domain 1 | 4507500 | HSIHIEKSDTAADTYGFSLSSV | |
| EEDGIRRLYVNSVKETGLASKK | ||||
| GLKAGDEILEINNRAADALNSS | ||||
| MLKDFLSQPSLGL | ||||
| LVRTYPELE | ||||
| 334 | TIAM2 domain 1 | 6912703 | PLNVYDVQLTKTGSVCDFGFAV | |
| TAQVDERQHLSRIFISDVLPDG | ||||
| LAYGEGLRKGNEIMTLNGEAVS | ||||
| DLDLKQMEALFSEKSVGLTLIA | ||||
| RPPDTKATL | ||||
| 335 | TIP1 domain 1 | 2613001 | QRVEIHKLRQGENLILGFSIGG | |
| GIDQDPSQNPFSEDKTDKGIYV | ||||
| TRVSEGGPAEIAGLQIGDKIMQ | ||||
| VNGWDMTMVTHDQARKRLTKRS | ||||
| EEVVRLLVTRQSLQK | ||||
| 336 | TIP2 domain 1 | 2613003 | RKEVEVFKSEDALGLTITDNGA | |
| GYAFIKRIKEGSVIDHIHLISV | ||||
| GDMIEAINGQSLLGCRHYEVAR | ||||
| LLKELPRGRTFTLKLTEPRK | ||||
| 337 | TIP33 domain 1 | 2613007 | HSHPRVVELPKTDEGLGFNVMG | |
| GKEQNSPIYISRIIPGGVAERH | ||||
| GGLKRGDQLLSVNGVSVEGEHH | ||||
| EKAVELLKAAKDSVKLVVRYTP | ||||
| KVL | ||||
| 338 | TIP43 domain 1 | 2613011 | LSNQKRGVKVLKQELGGLGISI | |
| KGGKENKMPILISKIFKGLAAD | ||||
| QTQALYVGDAILSVNGADLRDA | ||||
| THDEAVQALKRAGKEVLLEVKY | ||||
| MREATPYVK | ||||
| 339 | Unknown PDZ | 22382223 | IQRSSIKTVELIKGNLQSVGLT | |
| domain 1 | LRLVQSTDGYAGHVIIETVAPN | |||
| SPAAIADLQRGDRLIAIGGVKI | ||||
| TSTLQVLKLIKQAGDRVLVYYE | ||||
| RPVGQSNQGA | ||||
| 340 | Vartul domain 1 | 1469875 | ILTLTILRQTGGLGISIAGGKG | |
| STPYKGDDEGIFISRVSEEGPA | ||||
| ARAGVRVGDKLLEVNGVALQGA | ||||
| EHHEAVEALRGAGTAVQMRVWR | ||||
| ERMVEPENAEFIVTD | ||||
| 341 | Vartul domain 4 | 1469875 | RELCIQKAPGERLGISIRGGAR | |
| GHAGNPRDPTDEGIFISKVSPT | ||||
| GAAGRDGRLRVGLRLLEVNQQS | ||||
| LLGLTHGEAVQLLRSVGDTLTV | ||||
| LVCDGFEASTDAALEVS | ||||
| 342 | Vartul domain 3 | 1469875 | LEGPYPVEEIRLPRAGGPLGLS | |
| IVGGSDHSSHPFGVQEPGVFIS | ||||
| KVLPRGLAARSGLRVGDRILAV | ||||
| NGQDVRDATHQEAVSALLRPCL | ||||
| ELSLLVRRDPAEFIVTD | ||||
| 343 | Vartul domain 2 | 1469875 | PLRQRHVACLARSERGLGFSIA | |
| GGKGSTPYRAGDAGIFVSRIAE | ||||
| GGAAHRAGTLQVGDRVLSINGV | ||||
| DVTEARHDHAVSLLTAASPTIA | ||||
| LLLEREAGG | ||||
| 344 | Vartul domains | 1469875 | TLTILRQTGGLGISIAGGKGST | |
| 1 and 2 | PYKGDDEGIFISRVSEEGPAAR | |||
| AGVRVGDKLLEGIFVSRIAEGG | ||||
| AAHRAGTLQVGDRVLSINGVDV | ||||
| TEARHDHAVSLLTAASPTIALL | ||||
| LERE | ||||
| 345 | X-11 beta | 3005559 | IPPVTTVLIKRPDLKYQLGFSV | |
| domain 2 | QNGIICSLMRGGIAERGGVRVG | |||
| HRIIEINGQSVVATAHEKIVQA | ||||
| LSNSVGEIHMKTMPAAMFRLLT | ||||
| GQENSSL | ||||
| 346 | X-11 beta | 3005559 | IHFSNSENCKELQLEKHKGEIL | |
| domain 1 | GVVVVESGWGSILPTVILANMM | |||
| NGGPAARSGKLSIGDQIMSING | ||||
| TSLVGLPLATCQGIIKGLKNQT | ||||
| QVKLNIVSCPPVTTVLIKRNSS | ||||
| 347 | ZO-1 domain 1 | 292937 | IWEQHTVTLHRAPGFGFGIAIS | |
| GGRDNPHFQSGETSIVISDVLK | ||||
| GGPAEGQLQENDRVAMVNGVSM | ||||
| DNVEHAFAVQQLRKSGKNAKIT | ||||
| IRRKKKVQIPNSS | ||||
| 348 | ZO-1 domain 2 | 292937 | ISSQPAKPTKVTLVKSRKNEEY | |
| GLRLASHIFVKEISQDSLAARD | ||||
| GNIQEGDVVLKINGTVTENMSL | ||||
| TDAKTLIERSKGKLKMVVQRDR | ||||
| ATLLNSS | ||||
| 349 | ZO-1 domain 3 | 292937 | IRMKLVKFRKGDSVGLRLAGGN | |
| DVGIFVAGVLEDSPAAKEGLEE | ||||
| GDQILRVNNVDFTNIIREEAVL | ||||
| FLLDLPKGEEVTILAQKKKDVF | ||||
| SN | ||||
| 350 | ZO-2 domain 1 | 12734763 | IQHTVTLHRAPGFGFGIAISGG | |
| RDNPHFQSGETSIVISDVLKGG | ||||
| PAEGQLQENDRVAMVNGVSMDN | ||||
| VEHAFAVQQLRKSGKNAKITIR | ||||
| RKKKVQIPNSS | ||||
| 351 | ZO-2 domain 3 | 12734763 | HAPNTKMVRFKKGDSVGLRLAG | |
| GNDVGIFVAGIQEGTSAEQEGL | ||||
| QEGDQILKVNTQDFRGLVREDA | ||||
| VLYLLEIPKGEMVTILAQSRAD | ||||
| VY | ||||
| 352 | ZO-2 domain 2 | 12734763 | RVLLMKSRANEEYGLRLGSQIF | |
| VKEMTRTGLATKDGNLHEGDII | ||||
| LKINGTVTENMSLTDARKLIEK | ||||
| SRGKLQLVVLRDS | ||||
| 353 | ZO-3 domain 3 | 10092690 | RGYSPDTRVVRFLKGKSIGLRL | |
| AGGNDVGIFVSGVQAGSPADGQ | ||||
| GIQEGDQILQVNDVPFQNLTRE | ||||
| EAVQFLLGLPPGEEMELVTQRK | ||||
| QDIFWKMVQSEFIVTD | ||||
| 354 | ZO-3 domain 1 | 10092690 | IPGNSTIWEQHTATLSKDPRRG | |
| FGIAISGGRDRPGGSMVVSDVV | ||||
| PGGPAEGRLQTGDHIVMVNGVS | ||||
| MENATSAFAIQILKTCTKMANI | ||||
| TVKRPRRIHLPAEFIVTD | ||||
| 355 | ZO-3 domain 2 | 10092690 | QDVQMKPVKSVLVKRRDSEEFG | |
| VKLGSQIFIKHITDSGLAARHR | ||||
| GLQEGDLILQINGVSSQNLSLN | ||||
| DTRRLIEKSEGKLSLLVLRDRG | ||||
| QFLVNIPNSS | ||||
| *: No GI number for this PDZ domain containing protein as it was computer cloned using rat Shank3 sequence against human genomic clone AC000036 and in silico spliced together nucleotides 6400-6496, 6985-7109, 7211-7400 to create hypothetical human Shank3. |
Methods for Detecting the Presence of an Oncogenic HPV E6 Protein in a Sample
The invention provides a method of detecting the presence of an oncogenic HPV E6 protein in a sample. In general, the method involves contacting a biological sample containing or potentially containing an oncogenic HPV E6 protein with a PDZ domain polypeptide and detecting any binding of the oncogenic HPV E6 protein in said sample to the PDZ domain polypeptide using a subject antibody. In alternative embodiments, a sample may be contacted with a subject antibody, and the presence of the E6 protein may be detected using the PDZ domain polypeptide. In most embodiments, binding of an oncogenic HPV E6 protein to the PDZ domain polypeptide and a subject antibody indicates the presence of an oncogenic HPV E6 protein in the sample.
Biological samples to be analyzed using the methods of the invention may be obtained from any mammal, e.g., a human or a non-human animal model of HPV. In many embodiments, the biological sample is obtained from a living subject.
In some embodiments, the subject from whom the sample is obtained is apparently healthy, where the analysis is performed as a part of routine screening. In other embodiments, the subject is one who is susceptible to HPV, (e.g., as determined by family history; exposure to certain environmental factors; etc.). In other embodiments, the subject has symptoms of HPV (e.g., cervical warts, or the like). In other embodiments, the subject has been provisionally diagnosed as having HPV (e.g. as determined by other tests based on e.g., PCR).
The biological sample may be derived from any tissue, organ or group of cells of the subject.
In some embodiments a cervical scrape, biopsy, or lavage is obtained from a subject. In other embodiments, the sample is a blood or urine sample.
In some embodiments, the biological sample is processed, e.g., to remove certain components that may interfere with an assay method of the invention, using methods that are standard in the art. In some embodiments, the biological sample is processed to enrich for proteins, e.g., by salt precipitation, and the like. In certain embodiments, the sample is processed in the presence proteasome inhibitor to inhibit degradation of the E6 protein.
In the assay methods of the invention, in some embodiments, the level of E6 protein in a sample may be quantified and/or compared to controls. Suitable control samples are from individuals known to be healthy, e.g., individuals known not to have HPV. Control samples can be from individuals genetically related to the subject being tested, but can also be from genetically unrelated individuals. A suitable control sample also includes a sample from an individual taken at a time point earlier than the time point at which the test sample is taken, e.g., a biological sample taken from the individual prior to exhibiting possible symptoms of HPV.
In certain embodiments, a sample is contacted to a solid support-bound PDZ domain polypeptide under conditions suitable for binding of the PDZ domain polypeptide to any PL proteins in the sample, and, after separation of unbound sample proteins from the bound proteins, the bound proteins are detected using the subject antibody using known methods.
Kits
The present invention also includes kits for carrying out the methods of the invention. A subject kit usually contains a subject antibody. In many embodiments, the kits contain a first and second binding partner, where the first binding partner is a PDZ domain polypeptide and the second binding partner is a subject antibody. In some embodiments, the second binding partner is labeled with a detectable label. In other embodiments, a secondary labeling component, such as a detectably labeled secondary antibody, is included. In some embodiments, a subject kit further comprises a means, such as a device or a system, for isolating oncogenic HPV E6 from the sample. The kit may optionally contain proteasome inhibitor.
A subject kit can further include, if desired, one or more of various conventional components, such as, for example, containers with one or more buffers, detection reagents or antibodies. Printed instructions, either as inserts or as labels, indicating quantities of the components to be used and guidelines for their use, can also be included in the kit. In the present disclosure it should be understood that the specified materials and conditions are important in practicing the invention but that unspecified materials and conditions are not excluded so long as they do not prevent the benefits of the invention from being realized. Exemplary embodiments of the diagnostic methods of the invention are described above in detail.
In a subject kit, the oncogenic E6 detection reaction may be performed using an aqueous or solid substrate, where the kit may comprise reagents for use with several separation and detection platforms such as test strips, sandwich assays, etc. In many embodiments of the test strip kit, the test strip has bound thereto a PDZ domain polypeptide that specifically binds the PL domain of an oncogenic E6 protein and captures oncogenic E6 protein on the solid support. The kit usually comprises a subject antibody for detection, which is either directly or indirectly detectable, and which binds to the oncogenic E6 protein to allow its detection. Kits may also include components for conducting western blots (e.g., pre-made gels, membranes, transfer systems, etc.); components for carrying out ELISAs (e.g., 96-well plates); components for carrying out immunoprecipitation (e.g. protein A); columns, especially spin columns, for affinity or size separation of oncogenic E6 protein from a sample (e.g. gel filtration columns, PDZ domain polypeptide columns, size exclusion columns, membrane cut-off spin columns etc.).
Subject kits may also contain control samples containing oncogenic or non-oncogenic E6, and/or a dilution series of oncogenic E6, where the dilution series represents a range of appropriate standards with which a user of the kit can compare their results and estimate the level of oncogenic E6 in their sample. Such a dilution series may provide an estimation of the progression of any cancer in a patient. Fluorescence, color, or autoradiological film development results may also be compared to a standard curves of fluorescence, color or film density provided by the kit.
In addition to above-mentioned components, the subject kits typically further include instructions for using the components of the kit to practice the subject methods. The instructions for practicing the subject methods are generally recorded on a suitable recording medium. For example, the instructions may be printed on a substrate, such as paper or plastic, etc. As such, the instructions may be present in the kits as a package insert, in the labeling of the container of the kit or components thereof (i.e., associated with the packaging or subpackaging) etc. In other embodiments, the instructions are present as an electronic storage data file present on a suitable computer readable storage medium, e.g. CD-ROM, diskette, etc. In yet other embodiments, the actual instructions are not present in the kit, but means for obtaining the instructions from a remote source, e.g. via the internet, are provided. An example of this embodiment is a kit that includes a web address where the instructions can be viewed and/or from which the instructions can be downloaded. As with the instructions, this means for obtaining the instructions is recorded on a suitable substrate.
Also provided by the subject invention are kits including at least a computer readable medium including programming as discussed above and instructions. The instructions may include installation or setup directions. The instructions may include directions for use of the invention with options or combinations of options as described above. In certain embodiments, the instructions include both types of information.
The instructions are generally recorded on a suitable recording medium. For example, the instructions may be printed on a substrate, such as paper or plastic, etc. As such, the instructions may be present in the kits as a package insert, in the labeling of the container of the kit or components thereof (i.e., associated with the packaging or subpackaging), etc. In other embodiments, the instructions are present as an electronic storage data file present on a suitable computer readable storage medium, e.g., CD-ROM, diskette, etc, including the same medium on which the program is presented.
Utility
The antibodies and methods of the instant invention are useful for a variety of diagnostic analyses. The instant antibodies and methods are useful for diagnosing infection by an oncogenic strain of HPV in an individual; for determining the likelihood of having cancer; for determining a patient's response to treatment for HPV; for determining the severity of HPV infection in an individual; and for monitoring the progression of HPV in an individual. The antibodies and the methods of the instant invention are useful in the diagnosis of infection with an oncogenic or a non-oncogenic strain of HPV associated with cancer, including cervical, ovarian, breast, anus, penis, prostate, larynx and the buccal cavity, tonsils, nasal passage, skin, bladder, head and neck squamous-cell, occasional periungal carcinomas, as well as benign anogenital warts. The antibodies and the methods of the instant invention are useful in the diagnosis of infection with an oncogenic or a non-oncogenic strain of HPV associated with Netherton's syndrome, epidermolysis verruciformis, endometriosis, and other disorders. The antibodies and the methods of the instant invention are useful in the diagnosis of infection with an oncogenic or a non-oncogenic strain of HPV in adult women, adult men, fetuses, infants, children, and immunocompromised individuals.
The subject methods may generally be performed on biological samples from living subjects. A particularly advantageous feature of the invention is that the methods can simultaneously detect, in one reaction, several known oncogenic strains of HPV.
In particular embodiments, the antibodies of the invention may be employed in immunohistological examination of a sample.
EXAMPLES
The following examples are put forth so as to provide those of ordinary skill in the art with a complete disclosure and description of how to make and use the present invention, and are not intended to limit the scope of what the inventors regard as their invention nor are they intended to represent that the experiments below are all or the only experiments performed. Efforts have been made to ensure accuracy with respect to numbers used (e.g. amounts, temperature, etc.) but some experimental errors and deviations should be accounted for. Unless indicated otherwise, parts are parts by weight, molecular weight is weight average molecular weight, temperature is in degrees Centigrade, and pressure is at or near atmospheric.
Example 1
Sequence Analysis of HPV E6 Proteins to Determine Oncogenic Potential
PDZ proteins are known to bind certain carboxyl-terminal sequences of proteins (PLs). PL sequences that bind PDZ domains are predictable, and have been described in greater detail in U.S. patent application Ser. Nos. 09/710,059, 09/724,553 and 09/688,017. One of the major classes of PL motifs is the set of proteins terminating in the sequences —X—(S/T)-X—(V/I/L). We have examined the C-terminal sequences of E6 proteins from a number of HPV strains. All of the strains determined to be oncogenic by the National Cancer Institute exhibit a consensus PDZ binding sequence. Those E6 proteins from papillomavirus strains that are not cancerous lack a sequence that would be predicted to bind to PDZ domains, thus suggesting that interaction with PDZ proteins is a prerequisite for causing cancer in humans. This correlation between presence of a PL and ability to cause cancer is 100% in the sequences examined (Table 3A). In theory, with the disclosed PL consensus sequences from the patents listed supra, new variants of HPVs can be assessed for their ability to bind PDZ proteins and oncogenicity can be predicted on the basis of whether a PL is present. Earlier this year, five new oncogenic strains of Human papillomavirus were identified and their E6 proteins sequenced. As predicted, these proteins all contain a PL consensus sequence (Table 3B).
| TABLE 3A |
| Correlation of E6 PDZ-ligands and oncogenicity |
| E6 C-terminal | ||||
| HPV strain | sequence | PL yes/no | Oncogenic | Seq ID No |
| HPV 4 | GYCRNCIRKQ | No | No | 33 |
| HPV 11 | WTTCMEDLLP | No | No | 34 |
| HPV 20 | GICRLCKHFQ | No | No | 35 |
| HPV 24 | KGLCRQCKQI | No | No | 36 |
| HPV 28 | WLRCTVRIPQ | No | No | 37 |
| HPV 36 | RQCKHFYNDW | No | No | 38 |
| HPV 48 | CRNCISHEGR | No | No | 39 |
| HPV 50 | CCRNCYEHEG | No | No | 40 |
| HPV 16 | SSRTRRETQL | Yes | Yes | 41 |
| HPV 18 | RLQRRRETQV | Yes | Yes | 42 |
| HPV 31 | WRRPRTETQV | Yes | Yes | 43 |
| HPV 35 | WKPTRRETEV | Yes | Yes | 44 |
| HPV 30 | RRTLRRETQV | Yes | Yes | 45 |
| HPV 39 | RRLTRRETQV | Yes | Yes | 46 |
| HPV 45 | RLRRRRETQV | Yes | Yes | 47 |
| HPV 51 | RLQRRNETQV | Yes | Yes | 48 |
| HPV 52 | RLQRRRVTQV | Yes | Yes | 49 |
| HPV 56 | TSREPRESTV | Yes | Yes | 50 |
| HPV 59 | QRQARSETLV | Yes | Yes | 51 |
| HPV 58 | RLQRRRQTQV | Yes | Yes | 52 |
| HPV 33 | RLQRRRETAL | Yes | Yes | 53 |
| HPV 66 | TSRQATESTV | Yes | Yes* | 54 |
| HPV 68 | RRRTRQETQV | Yes | Yes | 55 |
| HPV 69 | RRREATETQV | Yes | Yes | 56 |
| HPV 34 | QCWRPSATVV | Yes | Yes | 356 |
| HPV 67 | WRPQRTQTQV | Yes | Yes | 357 |
| HPV 70 | RRRIRRETQV | Yes | Yes | 358 |
| Table 3A: E6 C-terminal sequences and oncogenicity. HPV variants are listed at the left. Sequences were identified from Genbank sequence records. PL Yes/No was defined by a match or non-match to the consenses determined by the inventors and by Songyang et al. -X-(S/T)-X-(V/I/L). Oncogenicity data collected from National Cancer Institute; Kawashima et. al. (1986) J. Virol. 57: 688-692; Kirii et al. (1998) Virus Genes 17: 117-121; Forslund et al. (1996) J. Clin. Microbiol. 34: 802-809. | ||||
| *Only found in oncogenic strains co-transfected with other oncogenic proteins. |
| TABLE 3B |
| Correlation of recently identified oncogenic E6 proteins |
| E6 C-terminal | ||||
| HPV strain | sequence | PL yes/no | oncogenic | Seq ID No |
| HPV 26 | RPRRQTETQV | Yes | Yes | 63 |
| HPV 53 | RHTTATESAV | Yes | Yes | 64 |
| HPV 66 | TSRQATESTV | Yes | Yes | 65 |
| HPV 73 | RCWRPSATVV | Yes | Yes | 66 |
| HPV 82 | PPRQRSETQV | Yes | Yes | 67 |
| Table 3B: E6 C-terminal sequences and oncogenicity. HPV variants are listed at the left. Sequences were identified from Genbank sequence records. PL Yes/No was defined by a match or non-match to the consensus sequence: -X-(S/T)-X-(V/I/L). Oncogenicity data on new strains collected from N Engl J Med 2003; 348: 518-527. |
These tables provide a classification of the HPV strains based on the sequence of the C-terminal four amino acids of the E6 protein encoded by the HPV genome. The 21 oncogenic strains of HPV fall into one of 11 classes (based on the C-terminal four amino acids), and HPV strains not specifically listed above may also fall into these classes. As such, it is desirable to detect HPV strains from all 11 classes: the instant methods provide such detection.
A cross-reactive antibodie of the invention may recognize E6 proteins from HPV strains of multiple (e.g., 2, 3, 4, 5, 6, or 7 or more different) classes.
Example 2
Identification of PDZ Domains that Interact with the C-Termini of Oncogenic E6 Proteins
In order to determine the PDZ domains that can be used to detect oncogenic E6 proteins in a diagnostic assay, the assay was used to identify interactions between E6 PLs and PDZ domains. Peptides were synthesized corresponding to the C-terminal amino acid sequences of E6 proteins from oncogenic strains of human papillomavirus. These peptides were assessed for the ability to bind PDZ domains using an assay and PDZ proteins synthesized from the expression constructs described in greater detail in U.S. patent application Ser. Nos. 09/710,059, 09/724,553 and 09/688,017. Results of these assays that show a high binding affinity are listed in Table 4 below.
As we can see below, there a large number of PDZ domains that bind some of the oncogenic E6 proteins and the second PDZ domain from MAGI-1 binds all of the oncogenic E6 PLs tested. The PDZ domain of TIP-1 binds all but one of the oncogenic E6 PLs tested, and may be useful in conjunction with MAGI-1 domain 2 for detecting the presence of oncogenic E6 proteins.
In a similar manner, peptides corresponding to the C-terminal ends of several non-oncogenic E6 proteins were tested with assay. None of the peptides showed any affinity for binding PDZ domains.
| TABLE 4 |
| higher affinity interactions between HPV E6 PLs and PDZ domains |
| HPV | PDZ binding partner | PDZ binding partner | |
| strain | (signal 4 and 5 of 0-5) | HPV strain | (signal 4 and 5 of 0-5) |
| HPV 35 | Atrophin-1 interact. prot. | HPV 33 | Magi1 (PDZ #2) |
| (TEV) | (PDZ # 1, 3, 5) | (TAL) | TIP1 |
| Magi1 (PDZ # 2, 3, 4, 5) | DLG1 | ||
| Lim-Ril | Vartul (PDZ #1) | ||
| FLJ 11215 | KIAA 0807 | ||
| MUPP-1 (PDZ #10) | KIAA 1095 (Semcap3) (PDZ | ||
| KIAA 1095 (PDZ #1) | #1) | ||
| PTN-4 | KIAA 1934 (PDZ #1) | ||
| INADL (PDZ #8) | NeDLG (PDZ #1, 2) | ||
| Vartul (PDZ # 1, 2, 3) | Rat outer membrane (PDZ #1) | ||
| Syntrophin-1 alpha | PSD 95 (PDZ #3 and 1-3) | ||
| Syntrophin gamma-1 | |||
| TAX IP2 | |||
| KIAA 0807 | |||
| KIAA 1634 (PDZ #1) | |||
| DLG1 (PDZ1, 2) | |||
| NeDLG (1, 2, 3,) | |||
| Sim. Rat outer membrane (PDZ | |||
| #1) | |||
| MUPP-1 (PDZ #13) | |||
| PSD 95 (1, 2, 3) | |||
| HPV 58 | Atrophin-1 interact. prot. (PDZ | HPV 66 | DLG1 (PDZ #1, 2) |
| (TQV) | #1) | (STV) | NeDLG (PDZ #2) |
| Magi1 (PDZ #2) | PSD 95 (PDZ #1, 2, 3) | ||
| DLG1 (PDZ1, 2) | Magi1 (PDZ #2) | ||
| DLG2 (PDZ #2) | KIAA 0807 | ||
| KIAA 0807 | KIAA 1634 (PDZ #1) | ||
| KIAA 1634 (PDZ #1) | DLG2 (PDZ #2) | ||
| NeDLG (1, 2) | Rat outer membrane (PDZ #1) | ||
| Sim. Rat outer membrane (PDZ | NeDLG (1, 2) | ||
| #1) | TIP-1 | ||
| PSD 95 (1, 2, 3) | |||
| INADL (PDZ #8) | |||
| TIP-1 | |||
| HPV 16* | TIP-1 | HPV 52 | Magi1 (PDZ #2) |
| (TQL) | Magi1 (PDZ #2) | (TQV) | |
| HPV 18* | TIP1 | ||
| (TQV) | Magi 1 (PDZ #2) | ||
| Table 4: Interactions between the E6 C-termini of several HPV variants and human PDZ domains. HPV strain denotes the strain from which the E6 C-terminal peptide sequence information was taken. Peptides used in the assay varied from 18 to 20 amino acids in length, and the terminal four residues are listed in parenthesis. Names to the right of each HPV E6 variant denote the human PDZ domain(s) (with domain number in parenthesis for proteins with multiple PDZ domains) that saturated binding with the E6 peptide in assay | |||
| *denotes that the PDZ domains of hDlg1 were not tested against these proteins yet due to limited material, although both have been shown to bind hDlg1 in the literature. |
The subject antibodies may be used with these oncogenic HPV E6-binding PDZ proteins in methods of detecting oncogenic strains of HPV.
Materials and Methods for Examples 3-7
Immunization protocol: Five 8 week-old female BALB/c mice are immunized intraperitoneally, in the footpad, or subcutaneously on day zero with 20 μg of MBP-E6 fusion protein or 100 μg of E6 conjugated-peptide and 20 μg of polyI/polyC polymer or complete Freund's adjuvant. Animals are boosted with 20 μg of E6 protein and polyI/polyC or incomplete Freund's adjuvant. Test bleeds are performed 3 days after the last boost and screened by ELISA against the corresponding E6 protein. Immunoreactive mice have a final boost three days prior to fusion.
ELISA screening of serum antibody titer and B cell hybridoma supernatants: ELISA plates are coated with appropriate fusion protein, washed, and blocked with PBS containing 2% BSA (Sigma). Then the test sample (immune sera or hybridoma supernatant) is added, along with a pre-immune or irrelevant supernatant negative control. After incubation the plate is washed and anti-mouse IgG-HRP conjugate (Jackson Laboratories) in PBS/2% BSA is added. After thorough washing, TMB substrate is added for 30 minutes, followed by termination of the reaction with 0.18 M H2SO4. The plate is then read at 450 nm using a Molecular Devices' THERMO Max microplate reader.
Fusion: On the day of fusion, the animals are sacrificed, blood collected, and the spleens excised and minced with scissors. The cells are then gently teased up and down with a pipette, filtered through a sterile 70 μm nylon filter and washed by centrifugation. Splenocytes and the FOX-NY myeloma partner (maintained prior to fusion in log growth) are resuspended in serum-free-RPMI medium, combined at a ratio of 4:1 and spun down together. The fusion is then performed by adding 1 ml of 50% PEG (Sigma) drop-wise over one minute, followed by stirring the cells for one minute. Then 2 ml of RPMI/15% FCS media is added drop-wise over two minutes, followed by 8 ml of RPMI/15% FCS over 2 minutes with constant stirring. This mixture is centrifuged, and the cells are gently resuspended at 108 cells/ml in RPMI/15% FCS+1×HAT media (Sigma) and plated out in 96-well flat bottom plates at 200 μl/well. After 5 days ˜100 μl old medium is replaced by aspirating out of wells, and adding 100 μl fresh RPMI/HAT medium. Hybridomas are kept in RPMI/HAT for ˜7 days. Then are grown in RPMI/15% FCS containing 1×HT for ˜1 week. Wells are assayed for antibody activity by ELISA when they are 10-30% confluent.
Hybridoma cloning, antibody purification and isotyping: Wells whose supernatants give the desired activity were selected for cloning. Cells are cloned by limiting dilution in a 96-well flat bottom plate. Purification of antibodies from tissue culture supernatants is performed by protein G and A affinity chromatography (Amersham). The isotype of the antibodies is determined using Cytometric bead array.
Cell lines: Cervical cancer cell lines expressing listed strains of HPV E6 were purchased from ATCC, and are shown in the following table:
| ATCC | Common | E6 | GenBank | ||
| Name | Name | Organism | Tissue | type | Accession # |
| HTB-31 | C-33A | human | cervix | None | |
| HTB-32 | HT-3 | human | cervix | 30 | |
| HTB-33 | ME-180 | human | cervix | 68b | M73258 |
| HTB-34 | MS751 | human | cervix | 45 | X74479 |
| HTB-35 | SiHa | human | cervix | 16 | |
| CRL-1550 | CaSki | human | cervix | 16 | |
| CRL-1594 | C-41 | human | cervix | 18 | |
| CRL-1595 | C-4-II | human | cervix | 18 | |
Stably or transiently transfected cells were produced using the following methods:
The following stable cell lines were made: 3A-HA-E6-26 (expresses HPV 26 E6); C33A-HA-E6-53 (expresses HPV 53 E6); C33A-HA-E6-58 (expresses HPV 58 E6); C33A-HA-E6-59 (expresses HPV 59 E6); C33A-HA-E6-66 (expresses HPV 66 E6); C33A-HA-E6-69 (expresses HPV 69 E6) and C33A-HA-E6-73 (expresses HPV 73 E6).
Calcium Phosphate Transfection of Mammalian Cell Lines
Materials: Deionized water, 2M CaCl2, 2×HBS pH 7.1, 25 mM Chloroquine (1000×), DNA.
Day 0: Plate 0.8 million cells in each well of a 6-well plate the night before transfection. (2 wells for each construct, therefore, 3 constructs in a 6-well plate)
Day 1: a) Aliquot appropriate cell media and add Chloroquine (Add 12.5 μl for every 10 ml of media. The extra 2.5 μl is to account for the 500 ul of the calcium phosphate+DNA solution that will be added to the cells later). b) Aspirate media off the cells and add 2 mL of the media+Chloroquine solution. Return cells to incubator. c) In a 5mL polypropylene tube, add the following in the order listed: i) deionized water, ii) DNA and iii) 2M CaCl2 as follows:
| DNA | Deionized water | 2 M CaCl2 | 2X HBS |
| 10 μg | (DNA + 64 + dH20 = 500 μl | 64 μl | 500 μl |
d) Add 500 μl of the DNA mix drop wise to the 2×HBS while bubbling with automatic pipetman and Pasteur pipette; e) Add 500 μl DNA/calcium/phosphate solution to each well; and f) Incubate in incubator for 8 hours, then replace media with normal growth media.
Day 3: Start selection with G418 (Gibco) at 1 mg/ml
Cells for transient expression of HPV 51 E6 were produced by standard methods.
Example 3
HPV-E6 Recombinant Protein Expression and Purification
Polynucleotides encoding E6 proteins of high-risk HPV types listed above were chemically synthesized (DNA 2.0, Menlo Park, Calif.) or cloned via RT-PCR from cervical cancer cell lines. Both maltose-binding-protein-E6 (MBP-E6) and glutathione-S-transferase-E6 (GST-E6) fusion protein types were used. Production of GST-E6 and MBP-E6 proteins were by standard protocols recommended by the suppliers (Amersham and New England Biolabs, respectively). Proteins were expressed in DH5α E. coli using IPTG driven induction. A 2 h induction at 37° C. yielded GST-E6 or MBP-E6 recombinant proteins at ˜1 mg/L, whereas induction overnight at 20° C. and purification including rebinding of protein to the gel matrix resulted in final yield of 2-10 mg/L. Purity of MBP-E6 proteins was estimated to be >90% based on PAGE analysis. Recombinant E6 fusion proteins were used as immunogens.
Example 4
Immunization, Fusion, Screening and Cloning of Hybridomas Secreting Monoclonal Antibodies Against E6 Protein
Mice were immunized with each of the HPV E6 proteins. A variety of immunization protocols including varying antigen doses (100 μg-10 μg), adjuvants (CFA/IFA, poly(I)-poly(C), CpG+Alum) and routes (subcutaneous, intraperitoneal) were tested. A service facility for animal care, handling of immunizations and sera collection was contracted (Josman, Napa, Calif.). Immunization projects were set up with 5-15 mice each. Sera of immunized mice were tested in ELISA against the recombinant E6 protein. Mice showing sufficiently high titers (OD above 1 at 1:1000 dilution) against E6 in their sera were selected for fusions.
To increase the frequency of hybridomas secreting of anti-E6 antibodies, the recombinant E6 protein used in the final boost contained a different tag from that used during the immunization (GST-E6 was used in the boost when immunizations occurred with MBP-E6, and vice versa)
Example 5
Spleen Cells of Selected Mice were Fused
Hybridoma supernatants were tested via direct antigen ELISA against the MBP-E6 used in the immunization and MBP protein as negative control. Supernatants that showed reactivity for MBP-E6 (immunogen) but not for MBP were selected for further analysis. Selected supernatants were tested further by slot western blot for reactivity against recombinant MBP-E6 and GST-E6, to reconfirm presence of anti-E6 mAb. At this stage, hybridomas were cloned by limiting dilution to isolate hybridoma clones secreting anti-E6 mAb.
To further characterize the reactivity of the hybridomas, selected supernatants were tested in an ELISA against the recombinant E6 proteins, as well as GST-INADL (PDZ) and GST-MAGI1-PDZ1 that served as negative controls. GST-INADL represents a class of proteins that, when purified in prokaryotic expression systems, tend to be associated with a bacterial contaminating that are also present in the MBP-/GST-E6 protein preparations used for immunizations. This control ensured that reactivity found in supernatants reflected a mAb binding to HPV-E6, and not against the associated contaminants.
Example 6
Cross-Reactivity Pattern of Anti-E6 Monoclonal Antibodies
The cross-reactivity pattern of anti-E6 mAbs against E6 proteins other than the one used as immunogen was tested. For this E6 panel test, a direct ELISA approach is used (recombinant E6 protein is coated on the plate).
Monoclonal antibodies against the E6 protein of high-risk HPV types that cause cervical cancer (e.g., HPV 16, 18, 26, 30, 31, 34, 45, 51, 52, 53, 58, 59, 66, 68b, 69, 70, 73, 82) were produced.
A summary of results showing cross-reactivity of the antibodies produced is shown In Table 5 below.
| TABLE 5 | |||||
| HPV-E6 | |||||
| binding | Endogenous E6 | ||||
| mAb | HPV-E6 type binding | profile S2 | detection S2 | Immunogen and | Immunization route and |
| designation | profile-direct ELISA | ELISA | ELISA | boosts/last boost | adjuvant |
| F12-1B9 | 18, 45, 66 | N.D. | N.D. | HPV18-[MBP]-E6/ | subcutaneous/Adjuvant: |
| F12-1C9 | 18 | N.D. | N.D. | HPV18-[GST]-E6 | complete/incomplete |
| F12-1H12 | 18 | N.D. | N.D. | Freund's (initial/follow up | |
| F12-2D2 | 18, 45, 66 | N.D. | N.D. | injections) | |
| F12-3B2 | 18 | N.D. | N.D. | ||
| F12-3D5 | 18, 45, 66, 82 | 18, 45 | 18, 45 | ||
| F12-4A11 | 18 | 18 | 18 | ||
| F12-4 E2 | 18 | 18, 45 | N.D. | ||
| F12-5C2 | 18 | N.D. | N.D. | ||
| F12-6D9 | 18, 45 | N.D. | N.D. | ||
| F12-6F5 | 18 | N.D. | N.D. | ||
| F12-6F6 | 18, 45 | N.D. | N.D. | ||
| F12-6H2 | 18, 45, 66, 82 | N.D. | N.D. | ||
| F12-7A10 | 18, 45 | N.D. | N.D. | ||
| F12-7F10 | 18 | N.D. | N.D. | ||
| F12-8A3 | 18, 45 | N.D. | N.D. | ||
| F12-8B8 | 18 | N.D. | N.D. | ||
| F16-4H12 | 16, 35 | 16 | N.D. | HPV16-[MBP]-E6/ | subcutaneous/Adjuvant: |
| F16-5D5 | 16, 35 | 16 | does not | HPV16-[GST]-E6 | complete/incomplete |
| recognize 16 | Freund's (initial/follow up | ||||
| injections) | |||||
| F17-1 E11 | 26, 51, 52, 53, 58 | N.D. | N.D. | HPV58-[MBP]-E6/ | subctaneous/Adjuvant: |
| F17-6G9 | 33, 58 | 58 | does not | HPV58-[GST]-E6 | complete/incomplete |
| recognize 58 | Freund's (initial/follow up | ||||
| injections) | |||||
| F18-3G11 | 16 | 16 | does not | HPV16-[GST]-E6/ | subcutaneous/Adjuvant: |
| recognize 16 | HPV16-[MBP]-E6 | complete/incomplete | |||
| F18-4C9 | 16 | N.D. | N.D. | Freund's (initial/follow up | |
| F18-5H3 | 16 | N.D. | N.D. | injections) | |
| F18-7H8 | 16 | N.D. | N.D. | ||
| F18-8G11 | 16 | N.D. | N.D. | ||
| F18-9B10 | 16, 73 | N.D. | N.D. | ||
| F18-10 E6 | 16 | 16 | 16 | ||
| F18-10 E10 | 16 | N.D. | N.D. | ||
| F19-6D10 | 18, 68b | 18, 68b | does not | DNA plasmid | |
| recognize 18 or | immunization; boost | ||||
| 68b | with HPV18-E6 (MBP- | ||||
| F19-6F9 | 18, 68b | 18, 68b | N.D. | E6/GST-E6) | |
| F19-7B12 | 18, 35, 68b | N.D. | N.D. | ||
| F19-7C7 | 18, 68b | N.D. | N.D. | ||
| F19-8E2 | 18, 35, 68b | N.D. | N.D. | ||
| F20-2H5 | 16, 18, 35, 45 | 18, 35, 45 | does not | HPV45-[MBP]-E6/ | subcutaneous/Adjuvant: |
| recognize 18 or | HPV45-[GST]-E6 | complete/incomplete | |||
| 45; 35 N.D. | Freund's (initial/follow up | ||||
| injections) | |||||
| F21-1D12 | 18, 30, 52, 58 | 30, 58 | does not | HPV58-[MBP]-E6/ | footpad injection/Adjuvant: |
| recognize 30 or | HPV58-[GST]-E6 | CpG-ALUM | |||
| 58 | |||||
| F21-3A3 | 18, 58 | N.D. | N.D. | ||
| F21-3H2 | 18, 30, 52, 58 | 58 | N.D. | ||
| F21-4 E10 | 18, 30, 52, 58 | 58 | N.D. | ||
| F21-4F9 | 18, 33, 58 | N.D. | N.D. | ||
| F21-4H1 | 18, 30, 33, 52, 58 | 33, 58 | 33, 58 | ||
| F21-5B2 | 16, 18, 30, 52, 58, 59, 68b | N.D. | N.D. | ||
| F22-1C12 | 26, 51, 69 | 51 | 51 | HPV51-[MBP]-E6/ | subctaneous/Adjuvant: |
| F22-10D11 | 26, 30, | N.D. | N.D. | HPV51-[GST]-E6 | complete/incomplete |
| 31, 35, 51, 53, 66, 69, 82 | Freund's (initial/follow up | ||||
| F22-10F10 | 26, 51, 69 | 51 | N.D. | injections) | |
| F24-2D6 | 26, 51, 69, 82 | 26, 69 | 26, 69 | HPV69-[MBP]-E6/ | subcutaneous/Adjuvant: |
| F24-4B12 | 26, 51, 53, 69, 73, 82 | N.D. | N.D. | HPV69-[GST]-E6 | complete/incomplete |
| F24-4F2 | 26, 51, 69, 82 | 26, 69, 82 | 26, 69; 82 N.D. | Freund's (initial/follow up | |
| F24-4G1 | 26, 51, 69, 82 | N.D. | N.D. | injections) | |
| F24-8H12 | 26, 51, 69, 82 | 26, 69, 82 | N.D. | ||
| F24-9H12 | 26, 51, 69, 82 | 26, 69 | N.D. | ||
| F25-2D11 | 73 | N.D. | N.D. | HPV73-[MBP]-E6/ | subcutaneous/Adjuvant: |
| F25-3D10 | 53, 73, 82 | N.D. | N.D. | HPV73-[GST]-E6 | complete/incomplete |
| F25-3 E5 | 16, 34, 59, 70, 73 | N.D. | N.D. | Freund's (initial/follow up | |
| F25-4C11 | 16, 34, 59, 70, 73 | 34 | does not | injections) | |
| recognize 73, 34 | |||||
| N.D. | |||||
| F26-1B10 | 51, 53 | N.D. | N.D. | HPV53-[MBP]-E6/ | subcutaneous/Adjuvant: |
| F26-1B11 | 53 | N.D. | N.D. | HPV53-[GST]-E6 | complete/incomplete |
| F26-1D9 | 53 | N.D. | N.D. | Freund's (initial/follow up | |
| F26-1D11 | 53 | N.D. | N.D. | injections) | |
| F26-2B12 | 53 | N.D. | N.D. | ||
| F26-2G5 | 53 | N.D. | N.D. | ||
| F26-3A8 | 30, 53, 66 | N.D. | N.D. | ||
| F26-5H5 | 53 | N.D. | N.D. | ||
| F26-6D10 | 53 | N.D. | N.D. | ||
| F26-8B7 | 53 | N.D. | N.D. | ||
| F26-8H9 | 53 | N.D. | N.D. | ||
| F26-9C2 | 53 | N.D. | N.D. | ||
| F26-9C7 | 53 | N.D. | N.D. | ||
| F26-9D8 | 53 | N.D. | N.D. | ||
| F26-9G5 | 53, 73, 82 | N.D. | N.D. | ||
| F27-3A4 | 59 | N.D. | N.D. | HPV59-[MBP]-E6/ | subcutaneous/Adjuvant: |
| HPV59-[GST]-E6 | complete/incomplete | ||||
| Freund's (initial/follow up | |||||
| injections) | |||||
| 6F4 | 16 | 16, 35, 69 | recognizes 16 | HPV16- | poly-I/poly-C adjuvant/three |
| and 69, 35 N.D. | [GST]E6/HPV16- | immunizations | |||
| [GST]E6 | |||||
| 4C6 | 16 | 16 | N.D. | HPV16- | poly-I/poly-C adjuvant/three |
| [GST]E6/HPV16- | immunizations | ||||
| [GST]E6 | |||||
| 3F8 | 16 | 16, 35, 51, | N.D. | HPV16-[MBP]E6-C- | poly-I/poly-C adjuvant/three |
| 82, 31, 33 | terminal | immunizations | |||
| and 58 | portion/HPV16- | ||||
| [MBP]E6-C-terminal | |||||
| portion | |||||
FIG. 3 shows results obtained from a slot western blot of recombinant E6 protein, probed with hybridoma supernatants.
Example 7
Selection of Antibodies for HPV Diagnostic Test
Supernatants from hybridomas reacting with E6 proteins are tested together with the oncogenic PL detector in a sandwich ELISA with recombinant E6 fusion protein.
Monoclonal antibodies are tested in HPV diagnostic ELISA for their ability to detect E6 from cervical cancer cell lines or cells transfected with E6 (if cell lines are unavailable).
It is evident from the above results and discussion that the subject invention provides an important new means for detecting HPV E6 proteins. In particular, the subject invention provides a system for detecting oncogenic strains of HPV. It is superior to current methods because the PDZ protein isolates the oncogenic E6 protein from other analytes of a complex biological sample, and the protein is detected using an antibody that cross-reacts with more than one E6 protein. The specificity of detection lies in the PDZ protein and the antibody does not need to bind only oncogenic E6 proteins, as currently required in conventional methods. Accordingly, the subject methods and systems find use in a variety of different diagnostic applications. Accordingly, the present invention represents a significant contribution to the art.
Claims
What is claimed is:1. An antibody composition comprising a mixture of monoclonal antibodies that specifically bind to E6 proteins of HPV strains 16, 18, 31, 33 and 45, wherein at least one of said monoclonal antibodies specifically binds to E6 proteins of at least three different oncogenic HPV strains.
2. The antibody composition claim 1, wherein said mixture of monoclonal antibodies specifically bind to E6 proteins of HPV strains 16, 18, 31, 33, 45, 52 and 58.
3. The antibody composition claim 1, wherein said mixture of monoclonal antibodies specifically bind to E6 proteins of HPV strains 16, 18, 31, 33, 45, 52, 58, 35 and 59.
4. The antibody composition of claim 1, wherein at least two of said monoclonal antibodies specifically bind to E6 proteins of at least six different oncogenic HPV strains.
5. A diagnostic kit for the detection of an HPV E6 polypeptide in a sample, comprising:
the antibody composition of claim 1.
6. The diagnostic kit of claim 5, wherein said monoclonal antibodies are labeled.
7. The diagnostic kit of claim 5, further comprising instructions for using said antibody composition to detect an oncogenic HPV E6 polypeptide in a sample.
8. The diagnostic kit of claim 5, further comprising a PDZ domain polypeptide that binds to an oncogenic HPV E6 polypeptide in a sample.
9. A method of detecting an HPV E6 protein in a sample, comprising:
contacting an antibody composition of claim 1 with said sample; and
detecting any binding of said antibody to said sample;
wherein binding of said antibody to said sample indicates the presence of an HPV E6 protein.
10. The method of claim 9, wherein said sample is suspected of containing an oncogenic strain of HPV.
11. A method of detecting the presence of an oncogenic HPV E6 protein in a sample, said method comprising:
contacting a sample with a PDZ domain polypeptide; and,
detecting any binding of said oncogenic HPV E6 protein in said sample to said PDZ domain polypeptide using an antibody composition of claim 1;
wherein binding of said oncogenic HPV E6 protein to said PDZ domain polypeptide indicates the presence of an oncogenic HPV E6 protein in said sample.
12. A system for detecting the presence of an oncogenic HPV E6 polypeptide in a sample, said method comprising:
a first and a second binding partner for an oncogenic HPV E6 polypeptide,
wherein said first binding partner is a PDZ domain protein and said second binding partner is an antibody that specifically binds to the E6 proteins of at least three different oncogenic HPV strains.
13. The system of claim 12, wherein at least one of said binding partners is attached to a solid support.
Images & Drawings included:
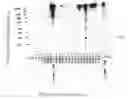


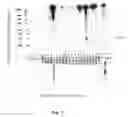

Sources:
- United States Patent and Trademark Office - verify current appl. status at the USPTO↗
Similar patent applications:
- » 20050142541
Antibodies for oncogenic strains of HPV and methods of their use - » 20100209904
Antibodies for oncogenic strains of HPV and methods of their use - » 20120164629
Antibodies For Oncogenic Strains Of HPV And Methods Of Their Use - » 20150093742
Antibodies for oncogenic strains of HPV and methods of their use
Recent applications in this class:
- » 20250051423 2025-02-13
POLYOMAVIRUS NEUTRALIZING ANTIBODIES - » 20240360202 2024-10-31
ANTI-HPV ANTIBODIES AND USES THEREOF - » 20240228590 2024-07-11
ANTI-BK VIRUS ANTIBODY MOLECULES - » 20240218053 2024-07-04
ENGINEERING BIOLOGICS TO HPV ONCOPROTEINS - » 20240158474 2024-05-16
ANTI-HPV6 L1 PROTEIN ANTIBODY AND DETECTION METHOD USING THE ANTIBODY - » 20240132575 2024-04-25
ANTI-BK VIRUS ANTIBODY MOLECULES - » 20230399382 2023-12-14
Polyomavirus neutralizing antibodies - » 20230295272 2023-09-21
Canine parvovirus nanobody CPV-VHH-E3 and application thereof - » 20230272049 2023-08-31
BINDING PROTEINS RECOGNIZING HPV16 E7 ANTIGEN AND USES THEREOF - » 20230220051 2023-07-13
DOSING OF POLYOMAVIRUS NEUTRALIZING ANTIBODIES