MOENOMYCIN BIOSYNTHESIS-RELATED COMPOSITIONS AND METHODS OF USE THEREOF
US20170081690A1
2017-03-23
14/833,905
2015-08-24
Abstract:
The methods and compositions described herein relate to the identification, isolation, and characterization of genes which encode proteins useful for the biosynthesis of transglycosylase inhibitors such as moes. The methods and compositions also relate to the production of such proteins, and their use in the synthesis of moes, the expression of moes, and the production of modified moes.
Inventors:
- Suzanne Walker Kahne 15 🇺🇸 Brookline, MA, United States
- Bohdan Omelyanovich Ostash 3 🇺🇦 L'viv, Ukraine
Assignee:
- President and Fellows of Harvard College 3,163 🇺🇸 Cambridge, MA, United States
Interested in similar patents?
Get notified when new applications in this technology area are published.
Classification:
C12P19/44 » CPC main
Preparation of compounds containing saccharide radicals Preparation of O-glycosides, e.g. glucosides
C12N15/52 » CPC further
Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor; Recombinant DNA-technology; DNA or RNA fragments; Modified forms thereof Genes encoding for enzymes or proenzymes
A61K31/7028 » CPC further
Medicinal preparations containing organic active ingredients; Carbohydrates; Sugars; Derivatives thereof Compounds having saccharide radicals attached to non-saccharide compounds by glycosidic linkages
Description
CROSS-REFERENCE TO RELATED APPLICATIONS
This application is a continuation of and claims priority under 35 U.S.C. §120 to U.S. application, U.S. Ser. No. 12/377,117, filed May 18, 2010, which is a national stage filing under 35 U.S.C. §371 of international PCT application, PCT/US2007/017999, filed Aug. 13, 2007, which claims priority under 35 U.S.C. §119(e) to U.S. Provisional application, U.S. Ser. No. 60/837,047, filed Aug. 11, 2006, the entire contents of which are incorporated herein by reference.
FIELD OF THE INVENTION
The invention provides polynucleotides and polypeptides related to moe biosynthesis and methods of use thereof. The invention also relates to derivatives of moe A having antibacterial activity.
BACKGROUND
The following discussion of the background of the invention is merely provided to aid the reader in understanding the invention and is not admitted to describe or constitute prior art to the invention.
The bacterial genus Streptomyces is an important natural source of many antibiotics, which include streptomycin, tetracycline, chloramphenicol, macrolides (e.g., erythromycin, carbomycin) and moenomycins (“moes”).
Moes are complex mixtures of phosphoglycolipid compounds produced by many Streptomyces strains as well as other Actinomyces. Streptomyces ederensis, Streptomyces geysiriensis, and Streptomyces bambergiensis (exemplary American Type Culture Collection deposits include ATCC15304, ATCC15303, ATCC13879, respectively) have all been shown to produce moes. See Wallhausser et al., 1965; Lindner et al., 1961. There have also been reports of an unidentified Actinomyces strain which produces compound AC326-alpha, a close relative of one of the moes in the mixture, moe A (He et at, 2000). Additionally, there are reports of Streptomyces strains producing compounds similar to moe A, however the exact chemical structure of these compounds has not yet been established (Weisenborn et al., 1967; Slusarchyk et al., 1969; Takahashi et al., 1970; Meyers et al., 1969).
Although the mixture of moes (e.g., the mixture produced by the strain Streptomyces ghanaensis) has not been thoroughly analyzed, it has been found to contain moe A (FIG. 1) and several other moes, including A12, C1, C3 and C4. Moes A12, C1, C3 and C4 have been shown to represent either shunt products or intermediates of common biosynthetic pathway operating in the producer strain. Additionally, compounds which are thought to be novel moes (Eichhorn, P. et al., 2005; Liu et al., 2003) have also been discovered.
The chemical structure for some moes (e.g., pholipomycin and AC326α) has been established, while the chemical nature of other members of the mixture (e.g., prasinomycins, macarbomycin, teichomycin A1, 11837RP, 8036RP (quebemycin), 19402RP, ensanchomycin, prenomycin) remains to be determined.
Moe A, a major component of the moe mixture, belongs to a unique family of phosphorus-containing secondary metabolites. Moe A is a pentasaccharide decorated with a C25 isoprene chain on one end and a chromophore on the other. The structure of moe A is shown below in Formula I:
Moe A is active against many bacterial strains and is the only antibiotic known to bind directly to and inhibit bacterial transglycosylase (“TG”), enzymes involved in peptidoglycan biosynthesis (FIG. 2). Because peptidoglycan biosynthesis is essential for bacterial survival, the inhibition of transglycosylase is an attractive and as-yet unexploited drug target. Moe A has potent antibiotic activity, with minimum inhibitory concentrations against many Gram positive organisms (“MICs”) in the range of 0.01 to 0.1 μg/mL (Chen L et al., 2003) or greater than 0.1 μg/mL. For example, moe A is an effective inhibitor of cell wall biosynthesis in Gram-positive cocci, including glycopeptide-resistant strains (Goldman, 2000).
It is assumed that the outer membrane of Gram-negative bacteria prevents moe A from reaching the enzymatic target; however, there are several studies showing selective toxicity of moe A and macarbomycin to Gram-negative bacteria carrying conjugative R-plasmids (Iyobe 1973; Ridel 2000). Additionally, some moe A producing Streptomyces strains and various strains not known to produce moe A (or structurally related compounds) are resistant to high concentrations of moe A. Therefore, some general and widely distributed resistance mechanism may exist which is not necessarily associated with moe A biosynthesis. Perhaps some Streptomyces transglycosylases are intrinsically resistant to moe A, or an unusually thick cell wall prevents moe A from reaching its target, or both. Additionally, or alternatively, by analogy to vancomycin resistance genes in S. coelicolor (Hong 2002), there could be a specific, as-yet unidentified moe A resistance gene or gene cluster in Streptomycetes.
The structure-activity relationships of moe A and its derivatives have been studied by Welzel and coworkers. For example, various domains involved in bioactivity and target interactions (Welzel, 1992) have been identified (labeled A through H) (FIG. 1). It has been shown that the C-E-F trisaccharide portion of moe retains inhibitory activity both in vitro and in vivo, while the E-F disaccharide shows activity only in vitro. The phospholipid moiety appears essential for in vivo activity, but the lipid chain can be manipulated to some extent (e.g., hydrogenation of the double bonds does not significantly alter activity). The lipid may be responsible either for anchoring moe to the cell membrane and/or interacting with hydrophobic regions of TGs. Moe analogs containing neryl chains have enzyme inhibitory activity but no biological activity. The carbamoyl group at C3′, the hydroxyl group at C4′, and the carboxamide entity at C5′ of the F ring, as well as the acetyl group at C2′ of the E ring, are all thought to define the moe pharmacophore (Ostash 2005). Unlike many other natural product antibiotics, moe does not contain structural elements of polyketide or non-ribosomal polypeptide origin. However, moes do contain a phosphoglycerate lipid moiety, a structural element not found in any other secondary metabolites. Moe A has been used as a growth promoter in animal feed under the trademark Flavomycin®.
SUMMARY OF THE INVENTION
The present invention provides polynucleotide and/or polypeptide compositions involved in moe biosynthesis and methods of use. For example, polypeptides encoded by nucleic acid sequences such as SEQ ID NOs: 3-25, or fragments, or natural or an artificial variants thereof are contemplated, as are the polypeptides of SEQ ID NOS. 26-48. Compositions including one or more nucleic acid sequences, such as SEQ ID NOs: 3-25, or fragments, or natural or artificial variants thereof are also contemplated. In other embodiments, the nucleic acid sequences or fragments may include an open reading frame. In some embodiments, these nucleic acid compositions may be inserted into expression vectors, and expressed, for example in mammalian, insect, yeast or bacterial cells. Composition comprising one or more polypeptides such as SEQ ID NOs: 26-48, natural or artificial variants, or fragments thereof are also provided.
The methods and compositions also relate to one or more proteins that participate in or are activated for moe biosynthesis. By way of example, but not by way of limitation, these polypeptides may include a composition comprising one or more of the polypeptides selected from the group consisting of: moe A4, moeB4, moeC4, moeB5, moe A5, moeD5, moeJ5, moeE5, moeF5, moeH5, moeK5, moeM5, moeN5, moeO5, moeX5, moeP5, moeR5, moeS5, moeGT1, moeGT2, moeGT3, moeGT4, moeGT5, fragments thereof, or a natural or artificial variant thereof. In one embodiment, the invention provides a composition comprising a one or more of the genes encoding the polypeptides recited above.
The methods and compositions also relate to moe A molecule, derivative or intermediate produced by an organism, such as a bacterial, insect, yeast or mammalian cell, wherein the organism carries one or more mutant or inactivated genes. In some embodiments, the mutant or inactivated gene may be one or more of moe A4, moeB4, moeC4, moeB5, moe A5, moeD5, moeJ5, moeE5, moeF5, moeH5, moeK5, moeM5, moeN5, moeO5, moeX5, moeP5, moeR5, moeS5, moeGT1, moeGT2, moeGT3, moeGT4, and moeGT5. In some embodiments, bacteria may be a Streptomyces strain, such as for example, S. ghanaensis. In other embodiments, the bacteria may be S. ghanaensis ATCC14627, S. lividans TK24, S. albus J1074.
The methods and compositions also relate to enzymatic methods of synthesizing moe, a moe derivative, or a moe intermediate wholly or partially in vitro. In some embodiments, the method includes reacting a one or more moenomycin precursor, derivative and/or moenomycin intermediate with a one or more polypeptide selected from the group consisting of: moeA4, moeB4, moeC4, moeB5, moe A5, moeD5, moeJ5, moeE5, moeF5, moeH5, moeK5, moeM5, moeN5, moeO5, moeX5, moeP5, moeR5, moeS5, moeGT1, moeGT2, moeGT3, moeGT4, and moeGT5, under conditions wherein the moenomycin, the moenomycin derivative, or the intermediate is wholly or partially synthesized. In some embodiments of the method, the method further comprises reacting the moenomycin, moenomycin derivative and/or moenomycin intermediate with a one or more reactants selected from the group consisting of: UDP-sugars, prenyl-pyrophosphates, phosphoglycerate, amino acids, cabamoyl phosphate, ATP and biological cofactors.
The methods and compositions also enzymatic of modifying a moenomycin wholly or partially in vitro. In some embodiments, the method includes reacting a moenomycin, a moenomycin derivative or a moe intermediate with a one or more polypeptide selected from the group consisting of: moeA4, moeB4, moeC4, moeB5, moe A5, moeD5, moeJ5, moeE5, moeF5, moeH5, moeK5, moeM5, moeN5, moeO5, moeX5, moeP5, moeR5, moeS5, moeGT1, moeGT2, moeGT3, moeGT4, and moeGT5, under conditions wherein the moenomycin, the moenomycin derivative, or the intermediate is modified. In some embodiments, the method further comprises reacting the moenomycin, moenomycin derivatives and/or moenomycin intermediates with a one or more reactants selected from the group consisting of: UDP-sugars, prenyl-pyrophosphates, phosphoglycerate, amino acids, carbamoyl phosphate, ATP and biological cofactors.
The methods and compositions described herein also relate to pharmaceutically acceptable compositions of moes, and the treatment of mammals, such as humans, by administering such compositions in a therapeutically effective amount. In some embodiments, the pharmaceutical composition may include a moe synthesized or modified by the methods of the present disclosure.
In another embodiment, the present invention provides an isolated Streptomyces strain selected from the group consisting of: Streptomyces ghanaensis, Streptomyces ederensis, Streptomyces geysiriensis, and Streptomyces bambergiensis strain which carries a one or more mutant or inactivated genes, wherein the mutant or inactivated genes are selected from the group consisting of: moeA4, moeB4, moeC4, moeB5, moe A5, moeD5, moeJ5, moeE5, moeF5, moeH5, moeK5, moeM5, moeN5, moeO5, moeX5, moeP5, moeR5, moeS5, moeGT1, moeGT2, moeGT3, moeGT4, and moeGT5. For example, the Streptomyces ghanaensis strain may be Streptomyces ghanaensis ATCC14627.
In another embodiment, the present invention relates to an isolated recombinant cell expressing one or more polypeptides or fragments, or natural or artificial variants thereof selected from the group consisting of: moeA4, moeB4, moeC4, moeB5, moeA5, moeD5, moeJ5, moeE5, moeF5, moeH5, moeK5, moeM5, moeN5, moeO5, moeX5, moeP5, moeR5, moeS5, moeGT1, moeGT2, moeGT3, moeGT4, and moeGT5. In some embodiments, the cell is selected from the group consisting of: Streptomyces lividans TK24, E. coli, mammalian cells, yeast and insect cells.
In another embodiment, the compositions described herein further relate to a moenomycin A molecule derivative or intermediate produced by an isolated recombinant cell expressing one or more polypeptides or fragments, or natural or artificial variants thereof selected from the group consisting of: moeA4 moeB4, moeC4, moeB5, moe A5, moeD5, moeJ5, moeE5, moeF5, moeH5, moeK5, moeM5, moeN5, moeO5, moeX5, moeP5, moeR5, moeS5, moeGT1, moeGT2, moeGT3, moeGT4, and moeGT5.
In one embodiment, the present invention provides a moenomycin derivative having the structure:
wherein Ac refers to acetyl;
R and R1 independently are selected from the group consisting of hydroxyl and —NHR2 where R2 is selected from the group consisting of hydrogen, alkyl, cycloalkyl, and substituted cycloalkyl;
X is hydrogen, or
where R3 is selected from the group consisting of hydrogen and hydroxyl; and
X1 is hydrogen,
where R4 is selected from the group consisting of hydrogen and hydroxyl;
R5 is selected from the group consisting of hydroxyl and —NHR6 where R6 is hydrogen, alkyl, cycloalkyl, or substituted cycloalkyl, and
R7 is hydrogen or methyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R and R1 independently are —NH2. In some embodiments, X is hydrogen. In other embodiments, X is
where R3 is selected from the group consisting of hydrogen and hydroxyl.
In some embodiments, X1 is hydrogen. In other embodiments, X1 is
In still other embodiments, X1 is
where R4 is selected from the group consisting of hydrogen and hydroxyl and R5 is selected from the group consisting of hydroxyl and —NH2.
In some embodiments, the structure of the moenomycin derivative is:
where R3 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R3 is hydrogen. In other embodiments, R3 is hydroxyl.
In some embodiments, the structure of the moenomycin derivative is:
where R4 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R4 is hydrogen. In other embodiments, R4 is hydroxyl.
In some embodiments, the structure of the moenomycin derivative is:
where R4 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R4 is hydrogen. In other embodiments, R4 is hydroxyl.
In some embodiments, the structure of the moenomycin derivative is:
where R4 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R4 is hydrogen. In other embodiments, R4 is hydroxyl.
In some embodiments, the structure of the moenomycin derivative is:
where R4 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments R4 is hydrogen. In other embodiments, R4 is hydroxyl.
In some embodiments, the structure of the moenomycin derivative is:
wherein R4 is hydrogen or hydroxyl and R6 is selected from the group consisting of hydrogen, alkyl, cycloalkyl, and substituted cycloalkyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R4 is hydrogen. In other embodiments, R4 is hydroxyl.
In some embodiments, R6 is hydrogen or substituted cycloalkyl. In some preferred embodiments, substituted cycloalkyl is
In some embodiments, R4 is hydroxyl and R6 is
In some embodiments, the invention provides a pharmaceutical composition comprising the moenomycin derivative as defined above and a pharmaceutically acceptable carrier.
In another embodiment, the present invention provides a moenomycin derivative having the structure:
wherein
R7 and R8 independently are selected from the group consisting of hydroxyl and —NHR9 where R9 is hydrogen, alkyl, cycloalkyl, or substituted cycloalkyl; and
R10 is hydrogen or hydroxyl;
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R7 and R8 independently are —NH2. In some embodiments, R10 is hydroxyl.
In some embodiments, the structure of the moenomycin derivative is:
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, invention provides a pharmaceutical composition comprising the moenomycin derivative as defined above and a pharmaceutically acceptable carrier.
BRIEF DESCRIPTION OF THE DRAWINGS
FIG. 1 shows the structure of moe A with the domains A-H involved in bioactivity and target interactions indicated in capital letters.
FIG. 2 shows interaction of moe A with the targets on the cell membrane.
FIGS. 3A-3B show schematics of the moe gene clusters 1 (FIG. 3A) and 2 (FIG. 3B), and the relative positions of the identified ORFs and genes along the clusters.
FIGS. 4A-4D show schematics of the moe A biosynthetic pathway. Dotted arrow line represents multiple biosynthetic steps (omitted on the scheme) leading from compound 8 to 22/23
FIGS. 5A-5B show Southern blots demonstrating the integration of vectors pSET52 (FIG. 5A) and pSOK804 (FIG. 5B) in the S. ghanaensis genome.
FIG. 6 shows a schematic for the generation of a conjugative plasmid that may be used for insertional gene inactivation.
FIG. 7 shows a schematic describing an approach for in silico screening involving classes of enzymes directed to producing different domains of moes.
FIGS. 8A-8B show schematics for the possible role of the moeO5 protein in moe biosynthesis. FIG. 8A shows biosynthesis of intermediate of archael membrane lipid. FIG. 8B shows biosynthesis of phosphoglyceric acid incorporation into moenomycin.
FIGS. 9A-9B show schematics for the insertional inactivation of the moeM5 gene (FIG. 9B) and confirmation of specific integration of the disruption sequences by Southern analysis (FIG. 9A).
FIGS. 10A-10B show schematics of the insertional inactivation of the moeGT1 gene (FIG. 10B) and confirmation of specific integration of the disruption sequences by Southern analysis (FIG. 10A).
FIGS. 11A-11D show bioassays (FIG. 11A), BioTLC (FIG. 11B) and liquid chromatography and mass spectrometry (“LC-MS”) data (FIG. 11C and FIG. 11D) indicating that in the moeGT1 mutant, moe A production appears to be reduced or abolished.
FIGS. 12A-12D show bioassays (FIG. 12A), BioTLC (FIG. 12B) and LC-MS data (FIG. 12C and FIG. 12D) of the moe A analog in the moeM5 mutant.
FIGS. 13A-13B show graphs of LC-MS analysis of moe extracts from wild-type (FIG. 13A) and moeM5 deficient strain OB20a (FIG. 13B).
FIG. 14 shows a bioassay of methanol extracts from 2 g of mycelia of strains S. lividans J1725 38-1+ (2) and S. lividans J1725 38-1+ plJ584+ (3). (1)—standard (moe A, 4 mcg).
FIG. 15A shows a Southern analysis of BamHI and XhoI digests of total DNA of wild type S. ghanaensis (lanes 2 and 4, respectively) and MO12 strain with disrupted moeGT3 (lanes 3 and 5). Lane 1—mixture of plasmids pMO12, pMO14 and pOOB58 underdigested with PstI. FIG. 15B shows the results of a bioassay of semipurified extracts from 1 g (wet weight) of mycelia of wild type strain (WT) and MO12. FIG. 15C presents a scheme of moeGT3 disruption in the S. ghanaensis genome. X, H, E mark XhoI, HindIII, EcoRI sites, respectively.
FIGS. 16A-16B show graphs of LC-MS analysis of moenomycin metabolites accumulated by S. ghanaensis MO12 strain. The final product is moenomycin C4 (1m) having Rt 9.2 min (FIG. 16A). The strain also accumulates its precursor lacking chromophore unit (2m; Rt 10.0 min) (FIG. 16B). Peaks corresponding to trisaccharide and disaccharide precursors of moenomycin C4 (3m and 4m, respectively) are observed. 5m is decarbamoylated derivative of 4m. 2m(dc) and 1m(dc) are doubly charged ions of 2m and 1m, respectively.
FIGS. 17A-17B show graphs of LC-MS analysis of moenomycin metabolites accumulated by S. lividans TK24 ΔmoeN5 strain (FIG. 17A). The final product is compound 23 having Rt 4.2 min (FIG. 17B). The strain also accumulates its monosaccharide precursors 2 and 3 (Rt 4.7-4.8 min). Structures of compounds 2, 3, 4, 8 and 23 are shown on FIGS. 4A-4D. Compounds 5 and 25d are decarbamoylated derivatives of 8 and 25, respectively. 23(dc) is doubly charged ion of 23.
FIGS. 18A-18B show LC-MS spectra of Mixed (−)-ESI-MS2 spectrum of compounds 22 and 23 produced by the S. lividans ΔmoeN5 strain (FIG. 18A) and the proposed fragmentation pathway of the compounds (FIG. 18B).
FIG. 19 shows the results of a disc diffusion assay of antibacterial activity of moe a intermediates against B. cereus. Spots 1 and 2—moe A (100 and 10 nM per disc, respectively); 3—compound 15 (100 nM); 4—compound 16 (100 nM), 5—compound 17 (100 nM), 6—compound 24 (100 nM), 7—mixture of compounds 22 and 23 (200 nM), 8—compound 11 (100 nM), 9—mixture of compounds 22 and 23 (50 nM), 10—mixture of compounds 2 and 3 (200 nM), 11—compound 1 (200 nM), 12—extract from 5 g S. lividans TK24 mycelial cake.
DETAILED DESCRIPTION
Definitions
The definitions of certain terms as used in this specification are provided below.
As used herein, the “administration” of an agent or drug to a subject or subject includes any route of introducing or delivering to a subject a compound to perform its intended function. Administration can be carried out by any suitable route, including orally, intranasally, parenterally (intravenously, intramuscularly, intraperitoneally, or subcutaneously), rectally, or topically. Administration includes self-administration and the administration by another. It is also to be appreciated that the various modes of treatment or prevention of medical conditions as described are intended to mean “substantial”, which includes total but also less than total treatment or prevention, and wherein some biologically or medically relevant result is achieved.
As used herein, the term “alkyl” refers to monovalent saturated aliphatic hydrocarbyl groups having from 1 to 6 carbon atoms. This term includes, by way of example, linear and branched hydrocarbyl groups such as methyl (CH3—), ethyl (CH3CH2—), n-propyl (CH3CH2CH2—), isopropyl ((CH3)2CH—), n-butyl (CH3CH2CH2CH2—), isobutyl ((CH3)2CHCH2—), sec-butyl ((CH3)(CH3CH2)CH—), t-butyl ((CH3)3C—), n-pentyl (CH3CH2CH2CH2CH2—), and neopentyl ((CH3)3CCH2—).
As used herein, the term “amino” refers to the group —NH2.
As used herein, the term “amino acid” includes naturally-occurring amino acids and synthetic amino acids, as well as amino acid analogs and amino acid mimetics that function in a manner similar to the naturally-occurring amino acids. Naturally-occurring amino acids are those encoded by the genetic code, as well as those amino acids that are later modified, e.g., hydroxyproline, γ-carboxyglutamate, and O-phosphoserine. Amino acid analogs refers to compounds that have the same basic chemical structure as a naturally-occurring amino acid, i.e., an α-carbon that is bound to a hydrogen, a carboxyl group, an amino group, and an R group, e.g., homoserine, norleucine, methionine sulfoxide, methionine methyl sulfonium. Such analogs have modified R groups (e.g., norleucine) or modified peptide backbones, but retain the same basic chemical structure as a naturally-occurring amino acid. Amino acid mimetics refers to chemical compounds that have a structure that is different from the general chemical structure of an amino acid, but that functions in a manner similar to a naturally-occurring amino acid. Amino acids can be referred to herein by either their commonly known three letter symbols or by the one-letter symbols recommended by the IUPAC-IUB Biochemical Nomenclature Commission. Nucleotides, likewise, can be referred to by their commonly accepted single-letter codes.
As used herein, “cycloalkyl” refers to a saturated or partially saturated cyclic group of 5 carbon atoms and no ring heteroatoms. The term “cycloalkyl” includes cycloalkenyl groups. Example of cycloalkyl group includes, for instance, cyclopentyl or cyclopentenyl.
As used herein, “substituted cycloalkyl” refers to a cycloalkyl group, as defined herein, having from 1 to 3 substituents selected from the group consisting of oxo and hydroxy, wherein said substituents are as defined herein. The term “substituted cycloalkyl” includes substituted cycloalkenyl groups.
As used herein, the term “ester” include formate, acetate, propionate, butyrate, acrylate, and ethylsuccinate derivatives of the compounds of the invention.
As used herein, “expression” includes but is not limited to one or more of the following: transcription of the gene into precursor mRNA; splicing and other processing of the precursor mRNA to produce mature mRNA; mRNA stability; translation of the mature mRNA into protein (including codon usage and tRNA availability); and glycosylation and/or other modifications of the translation product, if required for proper expression and function.
A “gene” includes a polynucleotide containing at least one open reading frame that is capable of encoding a particular polypeptide or protein after being transcribed and translated. Any of the polynucleotide sequences described herein may be used to identify larger fragments or full-length coding sequences of the gene with which they are associated. Methods of isolating larger fragment sequences are known to those of skill in the art, some of which are described herein.
A “gene product” includes an amino acid (e.g., peptide or polypeptide) generated when a gene is transcribed and translated.
As used herein, “hybridization” includes a reaction in which one or more polynucleotides react to form a complex that is stabilized via hydrogen bonding between the bases of the nucleotide residues. The hydrogen bonding may occur by Watson-Crick base pairing, Hoogstein binding, or in any other sequence-specific manner. The complex may comprise two strands forming a duplex structure, three or more strands forming a multi-stranded complex, a single self-hybridizing strand, or any combination of these. A hybridization reaction may constitute a step in a more extensive process, such as the initiation of a PCR reaction, or the enzymatic cleavage of a polynucleotide by a ribozyme.
Hybridization reactions can be performed under conditions of different “stringency”. The stringency of a hybridization reaction includes the difficulty with which any two nucleic acid molecules will hybridize to one another. Under stringent conditions, nucleic acid molecules at least 60%, 65%, 70%, 75% identical to each other remain hybridized to each other, whereas molecules with low percent identity cannot remain hybridized. A preferred, non-limiting example of highly stringent hybridization conditions are hybridization in 6× sodium chloride/sodium citrate (SSC) at about 45° C., followed by one or more washes in 0.2×SSC, 0.1% SDS at 50° C., preferably at 55° C., more preferably at 60° C., and even more preferably at 65° C.
When hybridization occurs in an antiparallel configuration between two single-stranded polynucleotides, the reaction is called “annealing” and those polynucleotides are described as “complementary”. A double-stranded polynucleotide can be “complementary” or “homologous” to another polynucleotide, if hybridization can occur between one of the strands of the first polynucleotide and the second. “Complementarity” or “homology” (the degree that one polynucleotide is complementary with another) is quantifiable in terms of the proportion of bases in opposing strands that are expected to hydrogen bond with each other, according to generally accepted base-pairing rules.
As used herein, “hydroxy” or “hydroxyl” refers to the group —OH.
As used herein, the terms “identical” or percent “identity”, when used in the context of two or more nucleic acids or polypeptide sequences, refers to two or more sequences or subsequences that are the same or have a specified percentage of amino acid residues or nucleotides that are the same (i.e., about 60% identity, preferably 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, or higher identity over a specified region (e.g., nucleotide sequence encoding a moeA biosynthetic polypeptide of the invention as described herein or amino acid sequence of an moeA biosynthetic polypeptide described herein), when compared and aligned for maximum correspondence over a comparison window or designated region) as measured using a BLAST or BLAST 2.0 sequence comparison algorithms with default parameters described below, or by manual alignment and visual inspection (see, e.g., NCBI web site). Such sequences are then said to be “substantially identical.” This term also refers to, or can be applied to, the compliment of a test sequence. The term also includes sequences that have deletions and/or additions, as well as those that have substitutions. As described below, the preferred algorithms can account for gaps and the like. Preferably, identity exists over a region that is at least about 25 amino acids or nucleotides in length, or more preferably over a region that is 50-100 amino acids or nucleotides in length.
An “isolated” or “purified” polypeptide or biologically-active portion thereof is substantially free of cellular material or other contaminating polypeptide or non-moeA-related agents from the cell from which the is derived, or substantially free from chemical precursors or other chemicals when chemically synthesized.
As used herein, the term “nucleotide pair” means the two nucleotides bound to each other between the two nucleotide strands.
As used herein, the term “oxo” refers to the atom (═O).
As used herein, the term “pharmaceutically-acceptable carrier” is intended to include any and all solvents, dispersion media, coatings, antibacterial and antifungal compounds, isotonic and absorption delaying compounds, and the like, compatible with pharmaceutical administration.
As used herein, the term “polynucleotide” means any RNA or DNA, which may be unmodified or modified RNA or DNA. Polynucleotides include, without limitation, single- and double-stranded DNA, DNA that is a mixture of single- and double-stranded regions, single- and double-stranded RNA, RNA that is mixture of single- and double-stranded regions, and hybrid molecules comprising DNA and RNA that may be single-stranded or, more typically, double-stranded or a mixture of single- and double-stranded regions. In addition, polynucleotide refers to triple-stranded regions comprising RNA or DNA or both RNA and DNA. The term polynucleotide also includes DNAs or RNAs containing one or more modified bases and DNAs or RNAs with backbones modified for stability or for other reasons. In a particular embodiment, the polynucleotide contains polynucleotide sequences from a moeA biosynthetic gene of the invention.
As used herein, the terms “polypeptide”, “peptide” and “protein” are used interchangeably herein to mean a polymer comprising two or more amino acids joined to each other by peptide bonds or modified peptide bonds, i.e., peptide isosteres. Polypeptide refers to both short chains, commonly referred to as peptides, glycopeptides or oligomers, and to longer chains, generally referred to as proteins. Polypeptides may contain amino acids other than the 20 gene-encoded amino acids. Polypeptides include amino acid sequences modified either by natural processes, such as post-translational processing, or by chemical modification techniques that are well known in the art. Such modifications are well described in basic texts and in more detailed monographs, as well as in a voluminous research literature. In a particular embodiment, the polypeptide contains polypeptide sequences from a polypeptide encoded by a moeA biosynthetic gene of the invention.
As used herein, the term “recombinant” when used with reference, e.g., to a cell, or nucleic acid, protein, or vector, indicates that the cell, nucleic acid, protein or vector, has been modified by the introduction of a heterologous nucleic acid or protein or the alteration of a native nucleic acid or protein, or that the material is derived from a cell so modified. Thus, e.g., recombinant cells express genes that are not found within the native (non-recombinant) form of the cell or express native genes that are otherwise abnormally expressed, under expressed or not expressed at all.
As used herein, the term “small molecule” means a composition that has a molecular weight of less than about 5 kDa and more preferably less than about 2 kDa. Small molecules can be, e.g., nucleic acids, peptides, polypeptides, glycopeptides, peptidomimetics, carbohydrates, lipids, lipopolysaccharides, combinations of these, or other organic or inorganic molecules.
As used herein, the term “subject” means that preferably the subject is a mammal, such as a human, but can also be an animal, e.g., domestic animals (e.g., dogs, cats and the like), farm animals (e.g., cows, sheep, pigs, horses and the like) and laboratory animals (e.g., monkey, rats, mice, rabbits, guinea pigs and the like).
As used herein, the term “substitution” is one of mutations that is generally used in the art. Those substitution variants have at least one amino acid residue in the polypeptides encoded by the moeA biosynthetic genes of the invention replaced by a different residue. The sites of greatest interest for substitutional mutagenesis include the active sites or regulatory regions of the polypeptides encoded by the moeA biosynthetic genes of the invention. “Conservative substitutions” are shown in the Table below under the heading of “preferred substitutions”. If such substitutions result in a change in biological activity, then more substantial changes, denominated “exemplary substitutions” in Table 1, or as further described below in reference to amino acid classes, may be introduced and the products screened.
| TABLE 1 |
| Amino Acid Substitutions |
| Preferred | ||
| Original Residue | Exemplary Substitutions | Substitutions |
| Ala (A) | val; leu; ile | val |
| Arg (R) | lys; gln; asn | lys |
| Asn (N) | gln; his; asp, lys; arg | gln |
| Asp (D) | glu; asn | glu |
| Cys (C) | ser; ala | ser |
| Gln (Q) | asn; gln | asn |
| Glu (E) | asp; gln | asp |
| Gly (G) | ala | ala |
| His (H) | asn; gln; lys; arg | arg |
| Ile (I) | leu; val; met; ala; phe; norleucine | leu |
| Leu (L) | norleucine; ile; val; met; ala; phe | ile |
| Lys (K) | arg; gln; asn | arg |
| Met (M) | leu; phe; ile | leu |
| Phe (F) | leu; val; ile; ala; tyr | tyr |
| Pro P) | ala | ala |
| Ser (S) | thr | thr |
| Thr (T) | ser | ser |
| Trp (W) | tyr; phe | tyr |
| Tyr (Y) | trp; phe; thr; ser | phe |
| Val (V) | ile; leu; met; phe; ala; norleucine | leu |
Once such variants are generated, the panel of variants is subjected to screening as described herein and variants with similar or superior properties in one or more relevant assays may be selected for further development.
As used herein, the term “effective amount” or “pharmaceutically effective amount” or “therapeutically effective amount” of a composition, is a quantity sufficient to achieve a desired therapeutic and/or prophylactic effect, e.g., an amount which results in the prevention of, or a decrease in, the symptoms associated with a disease or condition that is being treated, e.g., the conditions associated with a bacterial infection. The amount of a composition of the invention administered to the subject will depend on the type and severity of the disease and on the characteristics of the individual, such as general health, age, sex, body weight and tolerance to drugs. It will also depend on the degree, severity and type of disease. The skilled artisan will be able to determine appropriate dosages depending on these and other factors. The compositions of the present invention can also be administered in combination with one or more additional therapeutic compounds. For example, a “therapeutically effective amount” of moe A derivatives is meant levels in which effects of bacterial infection are, at a minimum, ameliorated.
As used herein, the term “pharmaceutically acceptable salt” refers to pharmaceutically acceptable salts derived from a variety of organic and inorganic counter ions well known in the art and include, by way of example only, sodium, potassium, calcium, magnesium, ammonium, and tetraalkylammonium, and when the molecule contains a basic functionality, salts of organic or inorganic acids, such as hydrochloride, hydrobromide, tartrate, mesylate, acetate, maleate, and oxalate. Suitable salts include those described in P. Heinrich Stahl, Camille G. Wermuth (Eds.), Handbook of Pharmaceutical Salts Properties, Selection, and Use; 2002.
As used herein, the term “tautomer” refers to alternate forms of a compound that differ in the position of a proton, such as enol-keto and imine-enamine tautomers.
As used herein, the terms “treating” or “treatment” or “alleviation” refers to both therapeutic treatment and prophylactic or preventative measures, wherein the object is to prevent or slow down (lessen) the targeted pathologic condition or disorder. A subject is successfully “treated” for a disorder characterized by bacterial infection if after receiving a therapeutic amount of a moe A derivative according to the methods of the present invention, the subject shows observable and/or measurable reduction in or absence of one or more signs and symptoms of a particular disease or condition. For example, for infection, inhibition (i.e., slow to some extent and preferably stop) of bacterial growth; and/or relief to some extent, of one or more of the symptoms associated with the specific infection; reduced morbidity and mortality, and improvement in quality of life issues.
General
The methods and compositions described herein relate to the identification, isolation, and characterization of genes which encode proteins useful for the biosynthesis of TG inhibitors such as moes, and their homologues. The methods and compositions also relate to the production of such proteins, and their use in the synthesis of moes, the production of modified moes, and the altered expression (e.g., overexpression) of moes. In one embodiment, the moe is moe A.
The methods and compositions also relate to the mutation, disruption, and expression of genes involved in the moe biosynthetic pathway. The present disclosure describes the isolation of gene clusters for moe biosynthesis from S. ghanaensis ATCC14672 (a.k.a., “moe biosynthesis-related genes”) as well as the insertional inactivation of certain moe biosynthetic genes as evidence of (i) cloning of moe biosynthesis gene clusters and (ii) the potential for generating bioactive moe derivatives through mutagenesis. The present disclosure also describes manipulations of regulatory genes to improve moe production in S. ghanaensis ATCC14672. The present disclosure also describes the heterologous expression of moe biosynthesis related genes in S. lividans TK24.
The moe biosynthesis-related genes of the present invention are useful for the chemoenzymatic generation of clinically valuable moe derivatives. For example, the moe biosynthesis-related genes of the invention are useful for the development of analogs suitable for use in humans. They are valuable tools for the chemoenzymatic synthesis of novel bioactive molecules and chemical probes. Additionally, manipulation of the moe biosynthesis-related genes of the present invention in cellular expression systems is useful for the generation of moe production and enrichment. In one embodiment, the moe biosynthesis-related genes of the invention are manipulated for overexpression of moes in a prokaryote.
The moe biosynthesis-related genes of the present invention may be selected from the group consisting of moeA4 moeB4, moeC4, moeB5, moe A5, moeD5, moeJ5, moeE5, moeF5, moeH5, moeK5, moeM5, moeN5, moeO5, moeX5, moeP5, moeR5, moeS5, moeGT1, moeGT2, moeGT3, moeGT4, and moeGT5. Exemplary polynucleotide sequences of moe biosynthesis-related genes include SEQ ID NOS: 3-25. Exemplary polypeptide sequences of moe biosynthesis-related genes include SEQ ID NOS: 26-48.
In one embodiment, the moe biosynthesis-related genes encode polypeptide fragments or variants of a natural moe biosynthesis-related polypeptide, wherein the variants comprise one or more conservative or non-conservative amino acid substitutions, additions or deletions compared to the natural moe biosynthesis-related polypeptide. A moe polypeptide (a.k.a., moe biosynthesis-related polypeptide”) in its native state is related to the biosynthesis of moes (e.g., moenomycin A), intermediates, derivatives or homologues, thereof. Variant polypeptides can be prepared by altering the sequence of polynucleotides that encode the natural moe biosynthesis-related polypeptide sequence. This is accomplished by methods of recombinant DNA technology well know to those skilled in the art. For example, site directed mutagenesis can be performed on recombinant polynucleotides encoding the moe biosynthesis-related polypeptide sequence to introduce changes in the polynucleotide sequence so that the altered polynucleotide encodes the peptides of the invention.
In some embodiments, the variants are at least about 85% identical, at least about 90% identical, or at least about 95% identical to the corresponding natural moe biosynthesis-related polypeptide. Typically, the variant moe biosynthesis-related polypeptides retain at least about 25%, at least about 50%, at least about 75%, at least about 80%, at least about 90%, or at least about 95% of the the biological activity of the natural polypeptide. The biological activity of the variant polypeptides and the natural polypeptide may be assayed according to the methods described herein, e.g. the type and/or quantity of moes or moe derivatives/intermediates produced by a heterologous host expressing the variant sequence may be compared to the type and/or quantity of moes or moe derivatives/intermediates produced by the same organism expressing the natural polypeptide.
As used herein the term “moe intermediate” or “moenomycin intermediate” encompasses moe-related biosynthesis precursor molecules and/or metabolites of moe biosynthesis. Alternatively, the variant polypeptides may possess a biological activity different from the natural polypeptide. For example, variations in the primary amino acid sequence may affect the binding of a moe biosynthesis-related polypeptide to one or more substrates, thereby providing moe derivatives different from those produced by the natural polypeptide. Assessing whether variant polypeptides have activity different from the natural polypeptide may also be performed according to the methods described herein. For instance, the variant polypeptide may be expressed in a heterologous host and the appearance of a new moes or moe derivatives may be observed using LC-MS analysis.
Although some portions of the discussion and examples focus on S. ghanaensis ATCC14672 or S. lividans TK24, it is understood that any bacterial strain or mammalian cell line which produces moe, moe-like compounds, or which includes homologues of the genes identified for moe biosynthesis, may also be used. Thus, using the teachings described herein, moe biosynthesis related genes may be expressed in heterologous systems including, but not limited to bacterial (e.g., Streptomyces sp., E. coli), mammalian (e.g., mouse, human, rat, hamster, etc., such as NIH-3T3, HeLa, HEK 293, etc.), yeast (e.g., Saccharomyces cerevisiae, Pichia pastoris) and insect cells (e.g., Drosophila melanogaster Schneider cells to generate moes and moe derivatives.
In preparing the recombinant expression constructs to express moe biosynthesis-related genes in heterologous hosts, the various polynucleotides of the present invention may be inserted or substituted into a bacterial plasmid-vector. Any convenient plasmid may be employed, which will be characterized by having a bacterial replication system, a marker which allows for selection in a bacterium and generally one or more unique, conveniently located cloning sites. Numerous plasmids, also referred to as vectors, are available for transformation. Suitable vectors include, but are not limited to, the following: viral vectors, such as lambda vector system gt11, Charon 4, and plasmid vectors such as pBR322, pBR325, pACYC177, pACYC1084, pUC8, pUC9, pUC18, pUC19, pLG339, pR290, pKC37, pKC101, SV40, pBluescript II SK+/−. or KS+/− (Stratagene, La Jolla, Calif.), and any derivatives thereof. Also suitable are yeast expression vectors, which may be highly useful for cloning and expression. Exemplary yeast plasmids include, without limitation, pPICZ, and pFLD. (Invitrogen, Carlsbad, Calif.). The selection of a vector will depend on the preferred transformation technique and target host cells.
The nucleic acid molecules encoding moe biosynthesis-related genes are inserted into a vector in the 5′ to 3′ direction, such that the open reading frame is properly oriented for the expression of the encoded protein under the control of a promoter of choice. In this way, the moe biosynthesis structural gene is said to be “operably linked” to the promoter. Single or multiple nucleic acids may be inserted into an appropriate vector in this way, each under the control of suitable promoters, to prepare a nucleic acid construct of the present invention.
Certain regulatory sequences may also be incorporated into the expression constructs of the present invention. These include non-transcribed regions of the vector, which interact with host cellular proteins to carry out transcription and translation. Such elements may vary in their strength and specificity. Depending on the vector system and host utilized, any number of suitable transcription and/or translation elements, including constitutive, inducible, and repressible promoters, as well as minimal 5′ promoter elements may be used.
A constitutive promoter is a promoter that directs constant expression of a gene in a cell. Examples of some constitutive promoters that are widely used for inducing expression of heterologous polynucleotides include the ADH1 promoter for expression in yeast, those derived from any of the several actin genes, which are known to be expressed in most eukaryotic cell types, and the ubiquitin promoter, which is the promoter of a gene product known to accumulate in many cell types. Examples of constitutive promoters for use in mammalian cells include the RSV promoter derived from Rous sarcoma virus, the CMV promoter derived from cytomegalovirus, β-actin and other actin promoters, and the EF1α promoter.
Also suitable as a promoter in the plasmids of the present invention is a promoter that allows for external control over the regulation of gene expression. One way to regulate the amount and the timing of gene expression is to use an inducible promoter. Unlike a constitutive promoter, an inducible promoter is not always optimally active. An inducible promoter is capable of directly or indirectly activating transcription of one or more DNA sequences or genes in response to an inducing agent (or inducer). Some inducible promoters are activated by physical means, such as the heat shock promoter (HSP), which is activated at certain temperatures. Other promoters are activated by a chemical means, for example, IPTG. Other examples of inducible promoters include the metallothionine promoter, which is activated by heavy metal ions, and hormone-responsive promoters, which are activated by treatment of certain hormones. In the absence of an inducer, the nucleic acid sequences or genes under the control of the inducible promoter will not be transcribed or will only be minimally transcribed. Promoters of the nucleic acid construct of the present invention may be either homologous (derived from the same species as the host cell) or heterologous (derived from a different species than the host cell).
Once the nucleic acid construct of the present invention has been prepared, it may be incorporated into a host cell. This is carried out by transforming or transfecting a host or cell with a plasmid construct of the present invention, using standard procedures known in the art, such as described by Sambrook et al., Molecular Cloning: A Laboratory Manual, Third Edition, Cold Spring Harbor: Cold Spring Harbor Laboratory Press, New York (2001). Suitable hosts and cells for the present invention include, without limitation, bacterial cells, virus, yeast cells, insect cells, plant cells, and mammalian cells, including human cells, as well as any other cell system that is suitable for producing a recombinant protein. Exemplary bacterial cells include, without limitation, E. coli and Mycobacterium sp. Exemplary yeast hosts include without limitation, Pichia pastoris, Saccharomyces cerevisiae, and Schizosaccharomyces pombe. Methods of transformation or transfection may result in transient or stable expression of the genes of interest contained in the plasmids. After transformation, the transformed host cells can be selected and expanded in suitable culture. Transformed cells are first identified using a selection marker simultaneously introduced into the host cells along with the nucleic acid construct of the present invention. Suitable markers include markers encoding for antibiotic resistance, such as resistance to kanamycin, gentamycin, ampicillin, hygromycin, streptomycin, spectinomycin, tetracycline, chloramphenicol, and the like. Any known antibiotic-resistance marker can be used to transform and select transformed host cells in accordance with the present invention. Cells or tissues are grown on a selection medium containing an antibiotic, whereby generally only those transformants expressing the antibiotic resistance marker continue to grow. Additionally, or in the alternative, reporter genes, including, but not limited to, β-galactosidase, β-glucuronidase, luciferase, green fluorescent protein (GFP) or enhanced green fluorescent protein (EGFP), may be used for selection of transformed cells. The selection marker employed will depend on the target species.
Expression is induced if the coding sequences is under the control of an inducible promoter. To isolate the protein, the host cell carrying an expression vector is propagated, homogenized, and the homogenate is centrifuged to remove bacterial debris. The supernatant is then subjected to sequential ammonium sulfate precipitation. The fraction containing the protein of the present invention is subjected to gel filtration in an appropriately sized dextran or polyacrylamide column to separate the proteins. If necessary, the protein fraction may be further purified by HPLC. Alternative methods of protein purification may be used as suitable. See J. E. Coligan et al., eds., Current Protocols in Protein Science (John Wiley & Sons, 2003). Upon obtaining the substantially purified recombinant protein, the protein may be administered to a subject as described herein.
Unless defined otherwise, all technical and scientific terms used herein generally have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs. As used in this specification and the appended claims, the singular forms “a”, “an” and “the” include plural referents unless the content clearly dictates otherwise. For example, reference to “a cell” includes a combination of two or more cells, and the like. Generally, the nomenclature used herein and the laboratory procedures in cell culture, molecular genetics, organic chemistry, analytical chemistry and nucleic acid chemistry and hybridization described below are those well known and commonly employed in the art. Standard techniques are used for nucleic acid and peptide synthesis. Standard techniques, or modifications thereof are used for chemical syntheses and chemical analyses.
It will be readily apparent to one skilled in the art that varying substitutions and modifications may be made to the invention disclosed herein without departing from the scope and spirit of the invention. The invention illustratively described herein suitably may be practiced in the absence of any element or elements, limitation or limitations which is not specifically disclosed herein. The terms and expressions which have been employed are used as terms of description and not of limitation, and there is no intention that in the use of such terms and expressions of excluding any equivalents of the features shown and described or portions thereof, but it is recognized that various modifications are possible within the scope of the invention. Thus, it should be understood that although the present invention has been illustrated by specific embodiments and optional features, modification and/or variation of the concepts herein disclosed may be resorted to by those skilled in the art, and that such modifications and variations are considered to be within the scope of this invention.
In addition, where features or aspects of the invention are described in terms of Markush groups or other grouping of alternatives, those skilled in the art will recognize that the invention is also thereby described in terms of any individual member or subgroup of members of the Markush group or other group.
Also, unless indicated to the contrary, where various numerical values are provided for embodiments, additional embodiments are described by taking any 2 different values as the endpoints of a range. Such ranges are also within the scope of the described invention.
All references, patents, and/or applications cited in the specification are incorporated by reference in their entireties, including any tables and FIGS., to the same extent as if each reference had been incorporated by reference in its entirety individually.
Moe Biosynthesis-Related Genes of the Invention
The candidate S. ghanaensis moe biosynthetic genes were identified by in silico scanning of shotgun sequenced fragments of the S. ghanaensis genome. As a result of genome scanning, 4 neighboring contigs were identified. Two of the identified genes, moeD5 and moeGT3, were used as a hybridization probes to retrieve additional overlapping cosmids from a genomic library of S. ghanaensis that cover one of the moe gene clusters. Physical mapping and partial sequencing of the cosmids confirmed that the in silico assembly of contigs coincided with their localization on the chromosome. A detailed discussion of the methods and procedures outlined above is provided in the Experimental Examples, Sections II and III.
Two gene clusters (e.g., gene cluster 1 and gene cluster 2) were identified which contain the moe biosynthesis-related genes of the invention. Sequence data indicated at least 1.3 Mbp separate gene cluster 1 from cluster 2. The polynucleotide sequence of gene cluster 1 (SEQ ID NO: 1) is shown in Table 2. The polynucleotide sequence of gene cluster 2 (SEQ ID NO: 2) is shown in Table 3.
| TABLE 2 |
| Complete DNA sequence of S. ghanaensis ATCC14672 |
| moe (moe) biosynthesis gene cluster 1. |
| CGCGCCCCTCCGGAGGCTGTCCGGAAGGGCGCGGCACGGGTGGGGGCGGGTCGGCCGGGTTCCGCCGGCCGGGTCGGGTC |
| AGCCGACGACGGCCGGCTGTGCGGGCGCCTCCCGCGGGCCGCCGCTGATCGGCAGGACCTCGGCGTCCGAGGTCCGCACG |
| AAGCGGGGACCGTCCGGCCCGTACACCCCGCGCGGCTCCGGGAACAGGGTGAGCAGGACGAGGTAGAGCACCGCCGCCAG |
| GGCCAGGCCGACCGGCAGCGAGACGTCCATGCCGTCGGCCAGGTCGCCGAGCGGTCCGACGAACTGACCGGGCAGGTTGG |
| TGAAGAGCAGGGCCACGGCGGCGGAGACCAGCCAGGTGGCCAGGCCGCGCCAGTTCCACCCGTGGGCGAACCAGTAGCGG |
| CCGCCGGTGCGGCGCTGGTTGAAGACCTGGAGCGCCTCCGGGTCGTACCAGCCCCGGCGGGTGACGTAGCCGAGGATCAT |
| CACGACCATCCACGGCGCGGTGCAGGTGATGATCAGGGTGGCGAAGGTGGAGATCGACTGCGTGAGGTTCAGCCAGAAGC |
| GGCCGGCGAAGATGAACACGATGGACAGCACGCCGATGAAGATCGTCGCCTGAACGCGGCTGAAGCGGGTGAAGACGCTG |
| CAGAAGTCCAGTCCGGTGCCGTACAGCGCGGTCGTGCCGGTGGACAGGCCGCCGATCAGCGCGATGAGGCAGAGCGGCAG |
| GAAGTACCAGCCGGGCGCGATCGCGAGCAGGCCGCCGACGTAGTTGGGCGCGTCGGGGTCGAGGTACGCCCCGGCCCGGG |
| TGGCGATGATCGACGCGGTGGCCAGGCCGAAGACGAACGGCAGCAGCGTGGCGATCTGGGCCAGGAACGCCGCGCCCATC |
| ACCCGGCGGCGGGGGGTCGCGGCCGGGATGTAGCGGGACCAGTCGCCGAGGAACGCGCCGAAGGAGACCGGGTTGGAGAG |
| CACGATCAGTGCGGACCCGATGAAGGACGGCCAGAAGAGCGGGTCCGCGGTCGAGGCGAAGGTGCCCGCGTAACCGGGGT |
| CGAAGTCGCCGGCGAAGGCGAAGGCGCCCAGCACGAACAGGGCCGAGGCCGCCACCACGGCGATCTTGTTGACCAGCAGC |
| ATGAAGCGGAAGCCGTAGATGCAGACCACCAGCACGAGACCGGCGAAGACCGCGTAGGCCAGGGCGTACGTCACCGTCGA |
| CTCGGGGACTCCCAGCAACCGGTGCGCGCCGCCGACCAGGGCGTCCCCCGAGGACCACACCGAGATCGAGAAGAAGGCGA |
| TCGCGGTGAGCAGCGCGAGGAAGGAGCCGACGACCCTTCCGTGCACCCCCAGGTGGGCGGAGGAGGAGACGGAGTTGCTG |
| GTGCCGTTCGTGGGCCCGAAGAGCGCCATGGGCGCGAGCAGCAGCGCGCCCGCGACCAGGCCGAGCAGCGTCGCCGCGAG |
| CCCCTGCCAGAAGGAGAGGCCGAACAGGATGGGGAAGGTGCCCAGCACACAGGTGGCGAAGGTGTTGGCGCCGCCGAAGG |
| CGAGGCGGAACAGATCGAGCGGACGGGCCGTGCGGTCCTCGTCCGGAATCTGCTCGACACCGTATGTCTCGATGTCGGTG |
| ACCGCGGTCTTCACGGGATCTCCTCCTTCTGTTCACGCCCCGGGGGATGGCCCCACAGTCTGAATCCCCCCACTGACCTG |
| CGACAACTGTGTCAATCACAGAGAGGTAGCCTGCTTTATGTGGCCACCAACAAACTGACCGTCGAGGATCTGCTCTCCTT |
| CCCCGCCCTCCAGCTGACGCTGCGGGCGGGGAAGAGTGGACTCTCACGCTCCGTTTCCTGGGCCCACACCAGCGAGTTGG |
| CCGATCCGACCCCCTGGCTGCTGGGGGCCGAGGTGATCATGACGACGGGGCTCGCGATCCCCCGCACCGCGACCGGGCAG |
| CGCCGCTATCTGGAGCGGCTGGACGACGCCGGGGTCTCCGCGCTGGCCCTGTCGGCGCAGCTGCACATGCCGCCGCTGCA |
| CGACGCGTTCTTCAAGGCGGCCGAGGAACGGGGCTTCCCCGTCCTGGAGGTGCCGCTCGCCGTTCCGTTCATCGCGGTCT |
| CCCAGGAGGTCGCCGCCGCGGTGCAGGAGGACGCCCGGCACCGGCTGGGCGCGCAGCTGCAGGTCTTCGGCTCGCTGCGC |
| TGGATGGTCGCCGAGGACCTCGACACCCCGACCCTCCTGCGCCGCCTCGAGCGCCTGTCCGGGTACAACGTCTTCCTCTG |
| CACCCCGCAGGGCCGCCCGCTGCTGCCCGGGGTGCCCACCCCCGACCCGGGCGTGCTGCCCGCCTCGGTGGACGCCCCGC |
| CGACCGTCCCCGGCGGTTTCGTCCTGCCCGTGCCGGCACCGGGCGGTCCGGCCGGTTTCCTGGTGGCGTACGAGAGGCAG |
| GGCGCCCAGCCCGCCGGGCTCGCGGTCGTCCAGCACATCGCCACGGTGGCGGCGCTGCGGCTGGCGATGGTGCGCAACGA |
| ACGCGAGACGCTGCGCCGCGAGGGCGCCGAGACCCTCGCCGAACTGCTCCGGGAGGTGCTCGACCCGGACGCCGCCCGCC |
| GCCGGCTCGCCCGGCACGCGATCGAGGGCGAGACCGTGCTGCTCGTGGTCCGGAACACCACCGACGAGGCACTGCTGCAC |
| TGCCTGGAGGACCGCCCCCACCTGCTGCTCACCCGGGGCGACGACCGGTACGTGCTCGGGGCCCCGGAGCTGGCCCCGGC |
| GATCGGCGAACTGCCCGGGGTGGCGGCCGGGATGAGCCGCGCCCTTCCGCCGGGCGCGGCCCTGAAGGTCGCCGAGCGCG |
| AGGCCCTGTGGGCGCTGAGCAAGGCGGTCGAGTCGGGCCGCCCCCTGGTCCGCTACGGCGACGACGCGACGGGCCGCTGG |
| CTGCCGGAGGACCCCGCGGTGCTGAGCGCGCTGGTCGAGCACGTCCTCGGCGAGGTGCTGCGCTACGACCTGGCCCACGG |
| CTCCCAGCTCCTGGTCTCCGTGCGCACCTGGCTGGAGCGCGACCGCCGTACGGAGACCGCCGCGGCCGCCCTCCACATCC |
| ACCCCAACACGCTCGCCTACCGGCTGCGCCGCTTCGGCGCCCTCTCCCGGCGCGACCTGTCCTCGACCGGCGCGCTGGCG |
| GAGGTCTGGCTGGCGATCCAGGCGGCCGGGACGCTGGGGCTCACCGACTGAGCGCGCCGGACACCGGCCCCGGGCGGGGA |
| CACGGACCGGGCGGCGCGCACCGCCTCCGAGGCGTTCGTCCGGGCCGGGCCGCCCCCGCCGGCGGGGAACCGGCCGGGGC |
| CGTCACCCCTCGGCCGGGCCGCCCCCGCCTCGTCGGACGACCGGAGCCGGACGGCCGGCTCCCCCTTGAGGACCTTGCCG |
| CCGGGTCCCAGGGGAAGCCGGTCGGGGAGGACCACCCGCCGCGGACGCCGGTACGCCGCGATGTGCCGCTCACCCCACGC |
| CACGACGGAATCCGCCAGTGCCCCGTCCGGTGTCGGGCCGTCCCGTGGCACCACCACCGCGCACACCTCCTGGCCGTACA |
| CCGGGTCGGGGAGCCCCACCACCGCGACCCGGGCGACCGCCGGATGGCGGAGCAGCGCTTCCTCGACCTCACGGGGATGG |
| ACGTCGTACCCGCCCCGCAGGATCACGTCCTTCTCGCGGTCGACGGCGGTGGGGTACCCCTCCTCGTCCAGCAGCCCTAG |
| ATCGCCGGTGCGGAACCAGCCGTCCACGAACGCGGCGGCCGTGGCGCGGGGGGCGTCGACGTACCCGGCCATCAGGTTGT |
| GCCCGCGGACGACGATCTCGCCCACCTCGCCGGAGGGAGCGGCCCGACGGCGTCCTCCGCCTCGGACCGGGGCTGTCGCG |
| ACCTCCACGCCCCAGAGGTGATCCGCTCGGCGCCCGCGACCACCGCGGTGCGCTCCGGCCACCGGCCCGCGGAGTCCGAG |
| AGGATCGTGGCCGCCGAGAGGGTCGCCCCCGGGCCCGCCCACGTGTTCCCGCCGTCGGTGACGGCTCCGGAATCCGTCGT |
| GAACGGCCCTGCCGGAGGTTTTCGTACGCGCTCGTCGCGACTCCGCCTCGCTTGCCGGTAATCGGCTTCCATCGGCCGGA |
| CGACAGCATGAGACGTCTTCTGTGCAAGACCCGCGGTGGATCCCAGGATGAGACCGGCCCGAAGGGTAGCGAAAGGAGCG |
| GACCTTGGACATCTCCTCGTCCATGGACTTCTTCGTGCGACTCGCCCGCGAAACCGGTGACCGGAAGAGGGAGTTTCTCG |
| AACTCGGCCGCAAGGCGGGTCGGTTCCCCGCGGCGAGCACCTCGAATGGCGAGATTTCCATCTGGTGCAGCAACGACTAC |
| CTGGGTATGGGGCAGCACCCGGACGTCCTCGACGCCATGAAGCGCTCCGTGGACGAATACGGCGGAGGATCCGGGGGTTC |
| GCGGAACACAGGCGGAACCAACCACTTCCATGTGGCTCTGGAGCGGGAGCCGGCCGAGCCGCACGGAAAGGAGGACGCCG |
| TTCTCTTCACCTCGGGGTATTCCGCCAATGAGGGATCCCTGTCGGTTCTGGCCGGGGCCGTCGACGACTGCCAGGTCTTC |
| TCGGATTCGGCGAACCACGCGTCCATCATCGACGGTTTACGGCACAGCGGCGCCCGCAAGCACGTATTCCGGCACAAGGA |
| CGGGCGGCATCTGGAGGAGTTGCTGGCCGCGGCCGACCGGGACAAGCCGAAGTTCATCGCCCTGGAGTCCGTGCATTCGA |
| TGCGGGGCGACATCGCGCTCCTGGCCGAGATCGCCGGCCTGGCCAAGCGGTACGGAGCGGTCACCTTCCTCGACGAGGTG |
| CACGCGGTCGGCATGTACGGCCCGGGCGGAGCGGGCATCGCGGCCCGGGACGGCGTGCACTGCGAGTTCACGGTGGTGAT |
| GGGGACCCTCGCCAAGGCCTTCGGCATGACCGGCGGCTACGTGGCGGGACCGGCCGTGCTCATGGACGCGGTGCGCGCCC |
| GGGCCCGTTCCTTCGTCTTCACCACGGCGCTGCCGCCGGCGGTCGCGGCGGGCGCGCTCGCCGCGGTGCGGCACCTGCGC |
| GGCTCGGACGAGGAGCGGCGGCGGCCGGCGGAGAACGCGCGGCTGACGCACGGCCTGCTCCGCGAGCGGGACATCCCCGT |
| GCTGTCGGACCGGTCCCCCATCGTCCCGGTGCTGGTCGGCGAGGACCGGATGTGCAAGCGCATGTCGGCCCTGCCGCTGG |
| AGCGGCACGGCGCGTACGTCCAGGCCATCGACGCGCCCAGCGTCCCGGCCGGCGAGGAGATCCTGCGGATCGCGCCCTCG |
| GCGGTGCACGAGACCGAGGAGATCCACCGGTTCGTGGACGCCCTGGACGGCATCTGGTCCGAACTGGGGGCCGCCCGGCG |
| CGTCTGACGCCCCGCAGTGTCACCCCGCGGGAGGGCTCTGCGGAGCGGGCCCGGCGTCCCCGCCCCCCGGACCCGCACCC |
| GTCCAGATCCGGCCCATCTCGGCGGAGACCGCCATGACCTCCTCGAAGGTGCCCGAGGCCTCCACCCGCCCGCCCTCGAG |
| CACCACCACGCGGTCGGCCGCGCGCAGCAGAGCGGGCCGGTGGGAGACCGCGAGCACGGTCCGCGTCCCGTCCAGCAGCC |
| TCTCCCACAGCAGGTGCTCGGTCTCCGGGTCCAGGGCACTGGAGACGTCGTCCAGCACCACGAGTTCGGGGTCGCCGACC |
| AGCATGCGGGCGATCGCGACCCGCTGGATCTGCCCGCCCGAGAGGCGCAGGCCCCGCGGGCCCACCACGGTGTCCGGGCC |
| GTCCTGCATCGCCGCCAGGTCGGGCTCCGCCACGGCGAGGCGCACGGCCTCGTCGAAGGCCGCGCCGTCCCGGCCCAGCA |
| GGACGTTCTCCCGCACCGTCCCGCTGAACAGACACGGGACCTGCGGGGTGTACCCGCAGCGCGGCGCCACCAGGAACGAC |
| GCGGGGTCGGCGATCGGTTCGCCGTTCCACAGCACGGTGCCCCGCTCGTGCGGGAGCAGTCCGAGGACGGCCCGGACCAG |
| GGTGCTCTTGCCGGAACCGACCCGGCCGGTGACCACGGTGACGGTGTGCCGCTCCACCACCAGGTCCACGTCCTCTATGC |
| CGTGCCCCGCCCCGGGGTGGCGGGCCGTCAGCCCGCGCACGGCCAGTTCCCGCAGGGGCGGGGCGGGCTCCGGCCCGGCG |
| TCCGGGGCGGCGGCCCCCTCGCCGGTCCCTCCCGGCGCGTCGGACGCGATCGGCGGACTGGCCCGCTCCAGGGACCGCCG |
| CAGCCGGCAGCCGAGGTTGTTGGTGATCCGGCCGAGCGCCACCGAGACCCGCTGCAACCGCACGGACAGCATGCCGATCG |
| ACCCCAGGGCCTCGGTCAGGATCTGCAGGTAGAAGGCGAACAGGGCGAGATCGCCGACGCTGAAGGTCCCCTCGTCCATC |
| CGCCCCGCGACCAGCAGCAGCACCACGCCGACCCCGATCGGGGCCGGGTTGCCGATCACCGTGCGCTGGACGACGGCGTA |
| CAGCTCCTCCCGCACCGCGGCTTCGGCACGGGCGCCGTTCAGCCCGGCGACGTGCGCGGCGACCTGCGGCTCGGCGGCGG |
| CGGCCTGCACCGCGCCCACCGCGCCCACCATCTCCCGCAGGGCTCCCGCCACCTCCCCGGACGCGGCCCGGGTGGCCCGC |
| CGGTGCCGCAGGAACCGGCTGTGGGCCAGCGCGGTGACCAGCGTCAGCAGGACGAGGAGGGCGAGGAGGGCGCCGGTGAC |
| CACGGCGTCGATCCGCATCATCACCGTGACCGACGCGGCGACGAACAGCCAGTGGGCGAGGTTCGTCGGCGCCCAGGCGA |
| CGAAGAACCCCGTCTCGTCGACGTCCTCGCCCACCGTTCGCAGGGACTCGCCGGGGCTGGTGCGGGCCGTCACCTCCGAC |
| CCGCGCAGGGCCGATCCCAGCAGGGCGTGCCGCAGCCGCGCCGTGGTGCCGTACTGGACCCGCGGCTCCAGCCTGTTGAT |
| CATCACGCCGAACTGGAGGAACAGCCGTCCCGCCTCGATCGCGGCCACCAACGCGATGATCAGCCACACGCCCCCGCCCG |
| CGCCCAGCGCGTCGAACAGCCGCTGGAACAGCAGGCCCACCACCAGGGTTCCCGCCCGCAGCAGGACCCACAGACCGGTG |
| AGGGTCCAGTAGGTGCGGGCCGAGCCGCGCAGCACGTCCGCGAGCCGTCCCAGGACGGACTGCCGCCCCGCTCCGTCGTC |
| CGCCCGCCTCGCTCTCCCTCCTGCCCGCTCCGCTCCGTCGTCCGCCCGCCTCGCTCTCCCCCCTGCCCGCTCCGCTCCGT |
| CGTCCGCCCGCTCCACTCCTGGCACCCCGCTCCCCCTCCCGTCCCCGTTCCTCACCGGGTGGCTCCGGCCGTGCGGAGGA |
| GTGCGTGGAAGCGCGACCCGGGATCGGCGGCGAGGACCCTCCGCTCCCCCTCCTCGGCGACCTTCCCCTCCTCCAGCACC |
| AGGATCCGGTCGACGTTCCGGAGCAGGTGCGGGCGGTGCTCCACCACGACGGCGGTGCGGCCCTCGAGCAGCCGCTCCAG |
| CGCGGGCATCAGGAGCCGCTCGCTGTACGGATCCAGCCGGGCCGTCGGCTCGTCCATCAGGACCAGCCCCGGATCGCGCA |
| GGAACACCCTGGCCAGCGCGAGCTGCTGCTCCTCGCCCGCGGACATGCCGCGGGCCCCGGCGCCGAGCGGCGTGTCCAGA |
| CCGTCGGGCAGGGTGCGCAGCCAGGGGCCGAGCCCGGCCTCGCCGAGAGCGGCGCGCAGCCGGTCGTCGGGGACGGAGCG |
| GTCGAAGAAGGTGAGGTTGTCCCGCAGCGAGGCGTGGAAGACGTGCACCTCCTGGGTGACCAGCGCGACCCGGCTGCGCA |
| GCGCCCGGGGATCGATCTCCGTCAGGTCCAGGCCGCCTGCCGAGACCGAGCCCGCCCCCGGGTGGTGGAGCCCGAACAGC |
| AGCCGGACCACGGTGGACTTGCCGCTGCCGGTGCGTCCCACGACGCCGAGGCGTTCGCCGGGGCGCAGGGTGAAGGAGAC |
| GTCCCGCAGCACCGGCTCGTCGGGCTCGTAGCCGAAGGAGACCCCGTCGAAGCGGACTCCGGGCAGTCCGGCCGGCAGCG |
| TCCCGCGTCCCGTGCGGGGCGCCGCCGTCCCGTGGCCCAGCAGGTCCCTCAGCCGCTGGGCGCTCGCGGCGGCGTCCTCG |
| AGTTCGCGGAAGCGGGTGGTGACCGCGAGCAGGGGGCGGCGCAGCAGCATCGCGTAGGACAGGGAGGCGAAGGCCGTCCC |
| CGTGGAGAGCTGTCCGCGGGCGTGCAGCCAGGCGCTGACCGCCAGGGCCAGGACGACGCTGACGGCGGACAGGCCCTGCA |
| CCGTGGCGGGCCAGCGGACCGAGGCCCGCGCCGCGTCGCGGGCCTTCCGGTACAGGTCGTCCTGCCGGTCGCCGAGTTCC |
| CGCAGGGTGTACCGCGAGGCCCCGTTGACGCGGAGGTCCTCCGCCGCCGCGAGGCGCTCCTCGAGGAAGCCCTGCAGGTC |
| CGCCGCGACCCGCTGCCGCGCGGTGACGAAGGGCATGGCGCGGCCCACCAGGGTCCGCAGCAGCAGGAGGGTGCCTGCCG |
| CGAACGGGGCGACCACCAGGGCCAGCCGCCATTCCAGCCGGAACAGGGCGACGAGGATGCCGACGATCAGCAGTGCCTGC |
| GCCAGCAGTTCCAGCAGCAGCGTCGACATCACCGCGGCGAGCCGGGTGACGTCGCCGTCCATCCGCTCGACGAGTTCGCC |
| GGGCGGATGCTTGCGGTAGAAGCCCGGCGGCCGGCTCAGGCAGTGCTCGACCAGGTCCGCGCGCAACCGGTTGGTGCTGC |
| GCCAGGCGACCCGTGAGGACAGCGCCTCGGTGCCCGCGGTGACCACGAGCGTCCCGACGGCGGCCGCCAGGGACCAGGCG |
| GCGAGGTCCAGCAGCGTCTTCCGGGAGTCGCCGGAGAGCGCCCCGTCGATGAATCCGCGCAGCAGGTAGGGCGCCACCAG |
| CTGGAGCCCCATCCCCGCGGGGACCAGGAGGGCGAGCAGCGCCACGGCGGTCCGTTCACCGCGCAGGTAGCGGACAAACG |
| TGGAGAGATGCCGCAACGGACTGTCTGCCAACGCGCCCCTCCCCCGTTCGCCCGGCGGCGAGCGGCCAGCATAAAGTCCT |
| GTGCGCCTCCTTGTGAATGACGCCTCGTCAACGGCGGCCGGAGCACGCCCTTTCTGCGGGAATGCCGATAGCGGACGCCG |
| CTCCGGGAGGGGGCGAAGCACACCATTGCTCGTGATTGACGCATGCTGTTAGACTCCCCACGTCTCTTGGTCCGGACATG |
| CGTTTCTCAACGCCGAAAGCCTGGTCAACCGCACTTTCGGCACCGCACAGTCCCACGGCGTCCGAGCGGTCGCGCGAGTC |
| GGCCCGGTCGAGCCAGAGGCAGCCACACGAACGTGCACCGCAATGCACCGCCTTGATCAGCCAGTTGTGAGCGAAACAAG |
| GGGGATTCGTGTCGAGCGATACACACGGAACGGACTTAGCGGACGGCGACGTTTTGGTCACCGGTGCGGCCGGCTTCATC |
| GGGTCGCACCTGGTGACGGAACTGAGGAATTCCGGCAGAAACGTTGTGGCGGTGGACCGGAGACCCCTTCCGGACGACTT |
| GGAGAGTACGTCCCCGCCCTTTACCGGTTCGCTCCGGGAGATACGCGGTGACCTCAACTCATTGAATCTGGTGGACTGCC |
| TGAAAAACATCTCGACGGTCTTCCACTTGGCCGCGTTACCCGGAGTCCGCCCGTCCTGGACCCAATTCCCCGAGTACCTC |
| CGGTGCAATGTACTGGCGACCCAGCGCCTGATGGAGGCCTGTGTGCAGGCCGGCGTGGAACGCGTGGTGGTCGCCTCGTC |
| CTCCAGCGTCTACGGCGGCGCGGACGGCGTGATGAGCGAGGACGACCTGCCCCGTCCGCTCTCCCCCTACGGGGTCACCA |
| AACTCGCCGCGGAGCGGCTGGCCCTGGCCTTCGCGGCCCGCGGCGACGCCGAGCTCTCGGTCGGCGCCCTGAGGTTCTTC |
| ACCGTCTACGGCCCCGGCCAGCGCCCGGACATGTTCATCTCCCGGCTGATCCGGGCGACGCTCCGGGGCGAACCCGTCGA |
| GATCTACGGCGACGGGACCCAGCTCCGCGACTTCACCCATGTGTCCGACGTGGTGCGGGCGCTGATGCTGACCGCGTCGG |
| TGCGGGACCGGGGCAGCGCGGTGCTGAACATCGGCACCGGGAGCGCCGTCTCGGTCAACGAAGTGGTCTCCATGACCGCG |
| GAGCTGACCGGTCTGCGCCCGTGCACCGCGTACGGTTCCGCCCGCATCGGCGACGTCCGCTCGACCACCGCCGACGTGCG |
| GCAGGCCCAGAGCGTCCTGGGCTTCACGGCCCGGACGGGTCTGCGGGAAGGTCTCGCCACCCAGATCGAGTGGACCCGGC |
| GGTCACTGTCCGGCGCCGAGCAGGACACCGTCCCGGTCGGCGGCTCCTCGGTGTCCGTGCCGCGGCTGTAGGCGGCATGT |
| GCGGCTTCGTCGGATTCAGTGACGCCGGCGCCGGGCAGGAGGACGCCCGTGTCACGGCCGAGCGCATGCTCGCCGCCGTG |
| GCGCACCGCGGCCCCGACGGCTCGGACTGGTGCCACCACCGGGGCGTCACCCTCGCGCACTGCGCCCTGACCTTCACCGA |
| TCCGGACCACGGCGCGCAGCCGTTCGTCTCCGCGTCGGGAGCCACCGCCGTGGTGTTCAACGGCGAGCTCTACAACCACG |
| CCGTGCTGGGCGACGGGGCGTTGCCCTGCGCACCCGGAGGCGACACAGAAGTTCCTGGTGGAACTCTACGAGTTGCTGGG |
| CATGCGGATGCTCGACCGGCTGCGGGGCATGTTCGCCTTCGCGCTGCAGGACGCCCGCACCGGCACCACGGTGCTGGCCG |
| CGACCGATGGGGAAGAGCCCCTCTACTAACACCCGCGTGCGAGACGGACATCGCTTTCGCGTCGGAACTCACGTCTCTGC |
| TGCGGCACCCCGCCGCGCCGCGCACACCGGAGGTGCGGGCGCTCGCCGACTACCTGGTGCTCCAGGCGTTCTGCGCCCCC |
| GCCTCGGCCGTGTCGGGGGTGTGCAAGGTGCGCCCCGGCAGCTACGTGACCCACCGGCACGGCGCGTTGGACGAGACCGA |
| GTTCTGGCGGCCCCGCCTGACCCCCGACCGGGGGGCGGGCCGCGGCCCCGGACGGCGGGAGGCCGCGCGGCGGTTCGAGG |
| AGCTCTTCCGCGCCGCGGTCGCCCGCCGGATGACCAGCACCGACCGCCGCCTCGGCGTACTGCTCAGCGGCGGCCTGGAC |
| TCCAGCGCGGTCGCCGCGGTGGCCCAGCAGCTCCTGCCGGGACGGCCGGTGCCCACCTTCAGCGCGGGGTTCGCGGACCC |
| GGACTTCGACGAGAGCGACCACGCACGGGCGGTGGCGCGCCACCTCGGCACCGAGCACCATGTGGTGCGGATCGGCGGGG |
| CCGACCTCGCCGGTGTGGTGGAGTCCGAACTCGCCGTGGCCGACGAGCCGTTGGCCGATCCCTCCCTGCTGCCCACACGT |
| CTGGTCTGCCGGGCGGCGCGCGAGCACGTCCGCGGCGTGCTCACCGGTGACGGCGCGGACGAACTGCTCCTGGGCTACCG |
| CTACTTCCAGGCCGAGCGGGCGATCGAGCTGCTGCTGCGCGTGCTGCCGGCCCCCCGGCTGGAGGCCCTCGTCCGGCTGC |
| TGGTGCGCCGGCTGCCGGCCCGTTCCGGCAACCTCCCCGTGACCCACGCCCTCGGTCTGCTGGCCAAGGGCCTGCGCGCG |
| GCACCGGAGCACCGGTTCTACCTCTCGACGGCGCCCTTCGGCCCGGGCGAGCTGCCACGGCTGCTCACCCCCGAGGCCGG |
| GGCCGAACTGACCGGGCACGACCCGTTCACCGAGGTGTCGCGCCTCCTGCGGGGACAGCCGGGCCTGACCGGTGTCCAGC |
| GCAGCCAGCTCGCCGTGGTGACCCACTTCCTGCGGGACGTGATCCTCACCAAGACGGACCGGGGCGGCATGCGCAGCTCC |
| CTCGAGCTGCGTTCCCCCTTTCTCGACCTGGACCTGGTCGAGTAGGGCAACTCCCTGCCCACCGGCCTGAAGCTGCACCG |
| GTTCACCGGCAAGTACCTGCTGCGGCAGGTCGCCGCCGGCTGGCTGCCCCCTTCCGTCGTCCAGCGGACGAAGCTGGGTT |
| TCCGCGCGCCGGTGGCGGCCCTGCTCCGCGGCGAGCTGCGGCCCCTGCTCCTGGACACCCTCTCCCCGTCGTCCCTGCGC |
| CGCGGCGGCCTGTTCGACACCGGGGCGGTGCGCCTGCTGATCGACGACCACCTCGGCGGCCGGCGCGACACCTCCCGCAA |
| GCTGTGGGCGCTGCTGGTCTACCAGCTCTGGTTCGAGAGCCTGACGGCCGGACCCCGCGCCCTCGAGTCCCCCGCGTACC |
| CGGCCCTCTCCTAGGAGACCCATGGCTGCCCCCGACCGACCGCTCGTCCAGGTGCTCTCCCCCCGGACCTGGGGCGAGTT |
| CGGCAACTACCTCGCCGCGACGCGCTTCTCCCGCGCGCTCCGGAGCGTGATCGACGCGGAAGTGACCCTGCTGGAGGCGG |
| AGCCGATCCTCCCGTGGATCGGCGAGGCCGGGGCGCAGATCCGGACCATCTCCCTGGAGAGCCCCGACGCCGTCGTCCGC |
| AACCAGCGGTACATGGCCCTCATGGACCGCCTCCAGGCACGCTTCCCGGAGGGGTTCGAGGCGGACCCCACCGCCGCCCA |
| GCGGGCGGACCTGGAACCGCTCACCCGGCACCTGCGGGAGAGCGCCCCCGACGTGGTGGTCGGCACGAAGGGGTTCGTGG |
| CGAGGCTGTGCGTGGCCGCCGTCCGGCTCGCCGGGACGTCCACCAGGGTCGTCAGCCACGTGACCAACCCCGGGCTGCTG |
| CAGCTGCCGCTGCACCGCAGCCGGTACCCGGACCTGACACTCGTCGGCTTCCCCCGGGCGAAGGAGCACCTGCTGGCCAC |
| GGCCGGCGGCGACCCGGAGCGCGTCCAGGTGGTGGGCCCGCTCGTCGCCCAGCACGACCTGCGGGACTTCATGACCAGTG |
| AGACGGCCGTCTCCGAGGCGGGGCCCTGGGGCGGCGACTCGGGCCCGGACCGGCCACGGGTGATCATCTTCTCCAACCGC |
| GGCGGGGACACCTACCCCGAGCTGGTGCGGCGCCTCGCCGACCGCCACCCCGGCATCGACCTCGTCTTCGTCGGCTACGG |
| CGACCCGGAGCTCGCCCGCCGCACCGCTGCGGTCGGGCGGCCCCACTGGCGGTTCCACAGCGTCCTCGGCCAGAGCGAGT |
| ACTTCGACTACATCCGGCGTGCCTCCCGGTCCAGGTACGGGCTCCTCGTCTCGAAGGCGGGGCCCAACACCACCCTGGAG |
| GCGGCCTACTTCGGCATACCGGTCCTGATGCTCGAGTCGGGGCTGCCCATGGAGCGGTGGGTGCCGGGACTGATCCACGA |
| GGAGGGGCTGGGCCACGCCTGCGCCACCCCCGAGGAGCTGTTCCGCACGGCGGACGACTGGCTGACCCGCCCGTCGGTGA |
| TCGAGGTGCACAAGAAGGCCGCGGTCTCCTTCGCCGCTTCCGTACTGGACCAGGACGCGGTGACGGCCAGGATCAAGGCC |
| GCCCTCCAGCCCCTGCTGGACGCCCGATGACGGTCCGCCGCCCGGCCGCGTCCGCCCCCCGCGTCCTCCTGACCGCGGGC |
| CCCGACGGGGTGCGCGTGGAGGGCGACGGGGAGGCGCGCCTCGGGCACCCCCTCACCGGTGACCACCTGGACCCGGGCCC |
| GCCGGCCGAAGGCGTCTTCGCCGGGTGGAGGTGGGACGGCGAGCGCCTGGTGGCCCGCAACGACCGCTACGGCGTCTGCC |
| CCCTCTTCTACCGGGCCGGCGGCGGCTCACTCGCGCTCTCCCCCGACCCGCTCGCCCTGCTGCCGGAGGACGGGCCCGTC |
| GAGCTGGACCACGACGCGCTCGCCGTCTTCCTGCGGACGGGGTTCTTCCTCGCCGAGGACACGGCCTTCGCACAGGTCCG |
| CGCACTGCCCCCGGCGGCCACGCTCACCTGGGACACCGGCGGGCTGCGGCTGCGGTCCGACGGGCCGCCGCGCCCCGGGG |
| CCGCCGCGATGACCGAGGCGCAGGCGGTCGACGGCTTCGTCGACCTGTTCCGCGCCTCGGTGGCCCGCCGGCTGCCCGGC |
| GAACCGTACGACCTGCCGCTCAGCGGCGGCCGGGACTCGCGGCACATCCTGCTCGAGCTGTGCCGCCGCGGCGCACCGCC |
| GCGGCGGTGCGTCAGCGGCGCCAAGTTCCCTCCCGACCCGGGGGCCGACGCGCGCGTGGCGGCCGCCCTGGCGGGCCGGC |
| TCGGTCTGCCGCACACGGTGGTGCCGCGCCCCCGTTCGCAGTTCCGCGCGGAGCTCGCCGCCCTGCCGGCCCAGGGCATG |
| ACCACCCTGGACGGCGCGTGGACCCAGCCGGTCCTGGCCCACCTGCGCCGCCACAGCCGCATCTCGTACGACGGTCTCGG |
| CGGCGGGGAGCTCGTCCAGAACCCGAGCGTGGAGTTCATCCGGGCCAACCCCTACGACCCCGCGGACCTGCCCGGCCTGG |
| CGGACCGGTTGCTGGCCGCGAGCCGGACCGGCCCCCACGTGGAGCACCTGCTGAGCCCCCGGACGAACGCCCTGTGGAGC |
| AGGCAGGCGGCGCGGCGGCGCCTCGTCACCGAGCTGGCCCGGCACGCCGACAGCGCCAGCCCGCTCAGTTCCTTCTTCTT |
| CTGGAACCGGACCCGGCGCTCCATCTCCGCGGCTCCGTTCGCCCTGGGGGACGGACGGGTCCTGACGCACACCCCCTACC |
| TCGACCACGCCCTCTTCGACCACCTCGCCTCGGTGCCGCACCGCTTCCTGGTCGACGGGACGTTCCACGACCGGGCGCTG |
| CACCGGGCCTTCCCCGAGCACGCGGACCTGGGGTTCGCCTCGTCGGTGCCCCAGCGGCACGGACCCGTGCTGGTCGCGCA |
| CCGACTGGCGTACCTGCTCCGGTTCCTCGCCCACGCGACGGTCGTGGAACCGGGCTGGTGGCGCGGCCCCGACCGCTTCC |
| TGCAACGGCTGCTGGCCGCCGGCCGGGGGCCCGGGGCCCCGCAGCGCGTCAGCAGGCTGCAGCCCCTGGCGCTCTACCTG |
| CTGCAGTTGGAGGACCTCGCCGTCCGAAGGGCCCGCCGCCGGCCGTAGCGGGGCCGGACCGCCGCAGACCCCCACTTCAC |
| GAGACATCAGCCGCAGGGCCCAGAAGGAGCACATCGCATGCGGAAGACATTGCCCGTGATCAGCACAGGTCCCGCCGCGG |
| GAGCGACGTCGGGCGGATGCTCCGCCCCGGCCGAGACCCCGGCCCGGTCGGGAATACCGCTGTGGCGCAAGCGCAAACTG |
| CGGATCGCCCTGGTGCGCCATCACGACCTGTGCCTGAACACCCGTCAGATAGCGCGGGTCCAGAAGCGGGCCGGCGTGCT |
| GCCGCACCTCGGGGCTGGGTTACATCCACACCGCGCTCAAGTCGGCCGGGTTCCACCACGTCATCCAGGTCGACACCCCC |
| GCCCTGGGCCTCGACAGCGAGGGGCTGCGCAAGCTGCTCGCGGACTTCGAGCCGGACCTGGTCGGGGTGAGCACCACGAC |
| ACCCGGTCTGCCCGGCGCCATCGAGGCGTGCGAGGCGGCCAAGAGCACCGGGGCGAAGGTGATCCTGGGCGGGCCGCACA |
| CGGAGGTGTACGCGCACGAGAACCTGGTCCACGAGTCCATCGACTACGTGGGCGTCGGCGAAGGCGTCACGATCATGCCG |
| GAACTGGCGGAGGCGATGGAGCGGGGCGAGGAGCCGGAGGGCATCCGCGGCCTGGTGACCCGCAAGCACGACGGCGGTGC |
| CGCGCCGATGGTGAACCTGGAGGAGGTCGGCTGGCCCGAACGCGCCGGGCTCCCGATGGACCGCTACTACTCGATCATGG |
| CTCCGCGGCCGTTCGCGACGATGATCTCCAGCCGCGGCTGCCCCTTCAAGTGCAGCTTCTGCTTCAAGCAGGCCGTGGAC |
| AAGAAGTCCATGTACCGCAGTCCCGAGGACGTCGTCGGTGAGATGACGGAGCTCAAGGAGCGGTGGGGGGTGAAGGAGAT |
| CATGTTCTACGACGACGTGTTCACCCTGCACCGCGGCCGGGTGCGGGAGATCTGCGGGCTCATCGGGGAGACCGGCCTCA |
| AGGTCCGCTGGGAGGCGCCCACCCGCGTCGACCTGGTGCCCGAGCCGCTGCTGGAGGCGATGGCCGGGGCCGGGTGCGTG |
| CGCCTGCGGTTCGGCATCGAGCACGGTGACAGCGAGATCCTCGAGCGGATGCGCAAGGAGAGCGACATCCAGAAGATCGA |
| GAAGGCCGTCACCTCCGCCCACGAGGCCGGGATCAAGGGCTTCGGGTACTTCATCGTCGGCTGGCTCGGGGAGACCCGGG |
| AGCAGTTCCGCAGGACCGTCGACCTCGCCTGCCGCCTCCCGCTGGACTACGCCAGCTTCTACACCGCGACGCCCCTGCCG |
| GGCACCCCCCTGCACACGGAGTCCGTGGCCGCCGGCCAGATCCCGCCCGACTACTGGGACCGCTTTTCGTGCGGGGCGAG |
| TTCGACGCGCGGATCGGGTACCTGGTGCCGGACGCGCAGGAGCGCGCCCAGTGGGCGTACCGCTCCTTCTTCATGCGCCG |
| CTCCATGGTCAAGCCGCTGCTGTCGCACATGGCGGTGACCGGCCAGTGGCGCAACACGCTGGACGGCCTGCACAGCCTGT |
| ACCGGTCGACCTCCAACACCGACCGTGACTTCTGAGCCCGCCGCCCCGGCCGTCCCGCACCCGCCGGTGCGTCCGGGGCC |
| GCCGGTCCGTCTCAACCGGCCGCTGGCGCGGCGCAGGCGGCGGCCGGCCGGGGAGGGGTTCGTGACGCACCACCTGCGGA |
| GCACCATGGCCCGCGGGTTCCGCCCCCCGGAGTCCTGGGAGGTCCCCGTCCGGCACGTCCTGCCCGGTCTGCCGGCCGAC |
| GGGACTCCGCGCGCCGAGGAGGCCGCTCAGGCGCTGCGCACGCCCGCCGGGCGGCCGGGCATCGCCCTCGTCGTGCCGAC |
| CTACGTCTCCCGGGTGAGCCTGGCGCGGCAGCGGGAGTGGTTCGACGCGCTGCTGGACCAGGCGGCCGCGGTGACGCGGG |
| ACCACCCCCTGGTGCCCCTGGTGCTGTTCGTCGGCATGCAGTGGTCGTCGGCCGAGGAGGAGCGGGAGGCGCTGCGGCGC |
| CTGCGTGTGCTGCTGGACGACGCCCGCACCCGGCTGCCCGGACTGCGGATCTGCGGTCTCGCGCTGCCCGGGCCGGGCAA |
| ACCCCGCACCCTCAACGGGGCGATCGCCGTCGCCGAGCTCCTCGGCTGTGCGGGCGTCGGGTGGACCGACGACGACGTGA |
| CCCTGGAGGAGGACTGCCTGTCCCGGCTGGTGCGGGACTTCCTGGCGGCGGGCTGCCGCGGGGCGGTGGGCGCGACCAAG |
| GTTGCGCACACCCATGAGTACGCCACCTCCCGGCTGCTGTCCCGGGCCAAGGCGATCGCCGCCCCGGCCACGAACTACCC |
| GCACGGCTGCTGCATCCTGGTGGCCACCGACGTGGTGGCCGGTGGTCTGCCGGGACGCTACGTATCCGACGACGGCTACG |
| TGTGCTTCCGCCTCCTCGACCCCGCGCTGCCCGACCCGCTGGCCCGGCTGCGGCTGGTTCCGGACGCCCGGTGCCACTAC |
| TACGTGGCGGGGCCGGCCGGCGAGACCCGCCGCAGGATCCGCAGGCTGCTGCTCAACCACCTCGTCGACCTCGCCGACTG |
| GCCCCTGCCGGTGGTCCGTCACTACTTCCGCCACGTCCTGTTCGGCGGCATGTGGCCGCTGACCGGCTTCGACTCCTCCC |
| GCGGTGCCCGCCGCGGTGTGCAGAAGGCGCTCATCAAGTGGCTCTACTTCGCCTGGTTCGCGGGCATCGGGGGCGAACTC |
| TACGTGCGCGGGCTGTCCGGCAGGCCACTGCGCCGCATCGAGTGGGCTCCCTACTCGGACATCCGCAGGCTCACTCCGTC |
| GTCCTCACCCACGCGTCAGGAGAGCTGATGAAGGTACTGTCGCTCCACTCCGCCGGCCACGACACCGGCGTCGCCTACTT |
| CGAGGACGGGCGGCTGGTCTTCGCGGTCGAGACCGAACGGCTCACCCGGGTCAAGCACGACCACCGCTCCGACGTCGCCC |
| TGCGGCACGTGCTCGAGCAGGAGTGCGTGGACACCGACGGGATCGACCTGGTGGCCGTCAGCACCCCGGTCCGCAGCGGG |
| CTGCTGCGCATACCCGACCTGGACCGGGCCATGGAGCGGATCGGGGCGGGCGCCCTCCACCACCGGACCGTCTGCGAGAT |
| GCTGGGGCGGCGGGTGGAGTGCGTCGTGGTCACCCACGAGGTCTCCCACGCGGCGCTGGCCGCCCACTACGCGGACTGGG |
| AGGAAGGCACCGTCGTCCTCGTCAACGAGGGCCGCGGCCAGCTCACCCGCAGCTCCCTGTTCCGGGTGACCGGCGGGGCC |
| CTGGAGTGGGTCGACAAGGACCCGCTGCCCTGGTACGGCAACGGCTTCGGGTGGACGGCGATCGGGTACCTCCTCGGCTT |
| CGGCCCGAGCCCCAGCGTGGCGGGCAAGGTGATGGCCATGGGCGGCTACGGGCAGCCGGACCCGCGCATCCGCGAACAGC |
| TGCTGTCGGTGGATCCGGAGGTGATGAACGACCGGGAACTCGCCGAGCGGGTGCGCGCGGACCTGGCCGGCCGGCCCGAG |
| TTCGCCCCCGGGTTCGAGACGGCGTCGCAGGTGGTGGCGACGTTCCAGGAGATGTTCACCGAGGCCGTCCGGGCGGTGCT |
| CGACCGGCATGTGACGCGCACGGACGCCGGGGTGGGCCCGATCGCCCTGGGCGGCGGGTGCGCCCTGAACATCGTGGCCA |
| ACTCGGCGCTGCGGGAGGAGTACGGGCGGGACGTCGCCATCCCGCCCGCCTGCGGGGACGCGGGTCACCTGACGGGCGCC |
| GGCCTCTACGCCCTCGCGCAGGTGGCCGGGGTGAAGCCGGAGCCGTTCAGCGTGTACCGCAACGGCGGGGGCGAGGCCCG |
| GGCCGCCGTCCTGGAGGCGGTGGAGGGCGCGGGGTTGCGGGCCGTTCCCTACGACCGGTCCGCGGTCGCCGGGGTGCTGG |
| CCGGGGGCGGGGTGGTGGCGCTGACGCAGGGAGCGGCGGAACTGGGGCCGCGGGCGCTGGGGCACCGGTCGCTGCTGGGC |
| AGTCCCGCGGTGCCGGGCATGCGCGAGCGGATGAGCGAGAAGCTCAAGCGGCGCGAGTGGTTCCGGCCGCTGGGCGCCGT |
| GATGCGCGACGAGCGCTTCGCCGGGCTGTACCCGGGGCGGGCGCCGTCGCCGTACATGCTCTTCGAGTACCGGCTGCCGG |
| ACGGGATCGCGCCCGAGGCCCGGCACGTCAACGGCACCTGCCGGATCCAGACCCTGGGCCCCGAGGAGGACCGGCTGTAC |
| GGTCTGCTCGCCGAGTTCGAGGAGCTGAGCGGTGTGCCGGCGCTGATCAACACGTCGCTCAACGGCCCGGGCAAGCCCAT |
| CGCGCACACCGCCCGGGACGTGCTCGACGACTTCGCGCGCACCGACGTCGACCTCTTCGTGTTCGACGACCTGATGGTGC |
| GGGGCGCCGCCGCGCGGTAGCCCCCGGGGTGGGGCGGGACGGCCGGCCGGAGACGCTCCGGCCGGCCGTCGGTCACTCCC |
| CCAGGTGCCGGGGAAGCAGCCGTACCAGCACGTCGTCCGTGTAGAGGTGGACGACCGGCACCAGACCGGGCGCGCCGGGC |
| GGTGCCGCCACCGCGGCGAGGGCCCGCCCGCGCAGCTCCTCCAGCAGGTCCACGACGTCCTGGCCGGCCACGGCCCCGGT |
| CCGCATCAGATGGGCGAGGTTGCCGTCCCGCTCGCCGTTGCGGTCGTAGTCGGTCAGGTCGTCCGCCATGGTGATGGTCA |
| TGGCGAAAGCCTCTGCGAACTCCCTTACGGAGTCCGCCGGTTGGCCTTCCCCCCCGCAGGCGGCCGCGAGTGCCCCGTAG |
| CGGCCCAGGAAGGTGGAGCCGTAGGTGCTCGCATGGGCGCGCCACTCCCGGAGGTTCGTCGCCCGAGAGCGTTTGGTGCG |
| TATCTGGCCGCCGCAGAGGTGGACGGCGTCCTGCTCCAGGATGTCCGTCACCGCCTTGGGGTCCCGGGCGAGGGATTCCA |
| GTTCGTGCAGCGCCCGCAGGTGGAGGCGGAGGCAGACACAGGCGAGTTCGACCCGGTCGAGTCCGGTGTCGTCGTCCATC |
| AGGTCGTCGAGGAGCTTCATGGAGACGATGTCGAGGGCCAGCGCGCGGGACACCGCGGCCCGCCGGTCCGGGTCGGTCGT |
| CCACTCGGTGAGGAAGTGGGGCACCCTCAGGTACAGGCGCAGGGCGGCGGTGTGCGCCACCAGGTCCGGCGACCCACCGG |
| TCTGCGCGACGCACCGCGTGACATGGTCGCGGTTGGCGGCCTCGGCGGCGAGCATGGTCTCCGTGTAGTCCGCCGGCAGG |
| GCCGTGGCCGGGGCGGCCGTCACCGCCCGCTCCCCGGACGGGCCGGGGCGGCGGGCCGCCTCCCGGCGATCTCGGCGAGG |
| GCGGACCGCCAGTCCGGCTGTTCCAGGGCTCCGGCGAACCCCACGTAGTCCGCCCCGCTGTCGAGGTACTCGGTGACCTG |
| CCGCCCGGAGCGGACGTTGCCGCTCACGAAGAGCACCTGGTCGGGGCCGAGCCCCTTGCGGAAGTGGCGTACGACCTCGG |
| GCGGCACGTGCTCGTTGCGCGAGTACAGGTACACCATGTGGAAACCGAAGGCACGGGCGACGTGGAGGTACCGGTCGATC |
| TCCTCGGTGGAGGCCGTGCTCACCGGCACGGTGCCGAGCAGGTCCCCGGTGCGGGGGTCCTCGCCGAAGGTGAGGGCGAC |
| GGTGAGGAGCAGCTCGGGCCACTCCTCGCGGGGTATTCGGCCGGGGAAGGCGGCCAGCGTCTCGAGGAAGCTCTTCCAGA |
| CGAAGTAGTCGTCGCCCGAGCCCAGCAGCGCGGGCAGCAGGAGCGCGTCCGCGCCGCGGACCACCGGGAAGCCGGCCCCC |
| GGGCGGGGCGGGAAGTGCAGGACGACCGGTAACGGGGTGGCCGCCTTCACCGCCGCCACGTACGGCTCCATGTGCGACTC |
| GAACGACTCGTAGTCGGTGCTGGCCAGAAGGACGGCGGCGAAGCCCAGCCGCGTGAGCTCCGCCGCCTTCTCGACCGCTT |
| CCGTCACCGGGACCTTGAAGGGGTCGATGATGTGGACGGGGCCCGGTTGGTGCTCGCGCAGCCGGGCGAGCACGCGTCCC |
| GGCCGCCAGAGCGGTGGTGCGGCGTGGAGTTCCGTGTGGTGGTCCAGTTGCGGTGAGGCGTTCACCAGCGTCTTCCCCCT |
| TGTCGTCCGGCTCGTCGTCCGGCTTGTCGTCCGGTCGGGTCACGCGACGGGGTGCCGGCCGCGTCGCACGTGCGGATCGC |
| GTCCGGATGAGGTGTCGCGCGTTCGGATGGAGGTGCGGGGCGCCCTGGTCGCCGAGGCCGTTCCCGGCCGGCCGGGAGTG |
| TTCCTCCCGGTGTGCCGCGCCGGCGCGAAAGCCGTGGTCCGGCGCCGTCGCGCGGTTTCCTTCAGACCCGCCCGGGGAAC |
| TGCGTGACCGTTCCGGCACACGCCGCGGTCGAGGGAGTGCGGAAGTGCTCGGAAATCCTTCGGCGGGCCCGTCCGGCGGA |
| TTCACCGGCGGACGGACGAAAAGCGTCGTTCACGTACTCCCCTTCCACTGGAGAGACGAACAGCGGGTCCACCGGGCCGC |
| CTCGAGGACAGGGTGCGGCAGGGCGGTTGCCGATACTACACGCGTTCGTTTCCGTGGGGTAGGGAGACTTTGTGCGGCGG |
| TTATGCATTCCTGCCGGACGGAAGAAGGCACGCCCCGACGGTTTCGCGCCGTGCGGGGCGTTCTCGGCGGTGTCCGGCGT |
| ATTTCACGCGAATTGCAGATGGCGCCGGCGGCGCAATCGGCCCGCCGTCACGCAACCGCTCACCGCGACCAGCAGCAGCG |
| TCACTCCGACGGCGTGGGCCACCCCGGAGTCGAACGACCCGCTGTCCGCGCCGTCGACCGCGTAGGTGATGATCTCCCGG |
| GTCGACCAGAAGGGAAGCACCTTGGCCGAATCCTTGGCCGGATCCATCACCATCTGGGCGCCGATGACGGAGATCAGCAG |
| CAGGGCGCCCTCCATGTCCCGTGGCACGGCCGCCCCGAGCAGCAGTCCCAGCGGCACCGCCACCAGTGTGGTCAGCGCCA |
| GTTCCACCGCGACGGCCCGCGGGTGCGCCACGTCCTGCCCGACCAGGATGATCACGGCGTAGAGGGCGGACACGCCCATG |
| CCGGCGGTGAGGAGGGCCAGCAGGCGGCCCAGGAAGAGCTGGAGCGGGCGGAACCCGGAGAGGGCCAGGAGCGGTTCGAT |
| CTCCCGGCCGCCGACCGCGGAGAAGAGGGCCGCGGCGCTGACCGCGAAGCCCACCCCGAGGCTGGCGAACCGGACCGCCT |
| GGCCGGTCTGGTCGTAACGCCCGAGGTAGAAGACGAGCGGGACCAGGAGCAGCAGGCCCAGCACGCCCCGCCGGCGCAGC |
| AGTTCGCGGAAGGTCATCTCCGCCATCCGCAGGGTGGCCGTCATCGGTTGCCCCTTCCTTTGCCGGGGGTGAGGTCCAGC |
| ACCTGGTCCACCCGGTCGAGCTGGTTGAGCATGTGCGTCACCACGACGACGGCCTTGCCCGCCTCGCGCCACTCCCAGAC |
| GCTCTGCCAGAAGTCCACGTAGGAGCCGTGGTCGAAGCCCTGGTAGGGCTCGTCGAGCAGCAGCAGGTCCGGGTCTCCCA |
| GGGCCGACAGGACGACGTTCAGCTTCTGGCGGGTTCCTCCCGACAGGTCCTTGGCAAGGACGCCCTCCGCGGGGGCCCAG |
| TCGAGCTCTCCCGCGAGTCTCCGGCCGCGGCGGTCGGACTCCCGGCGGCTCAGGCCCCGGCCGGTGCCGAAGAGGGTGAA |
| GTGCTCCCGGGGGGTCAGGAAGCCCATGACCCCCGCGTTCTGCGGGCAGTAGCCGAGGTGGCCGGAGACGGTGACCCGTC |
| CTTTGTCGGGGGAGAGCAGACCGGCGCAGATCTTGAGCAGGGTGGACTTGCCCGTCCCGTTGCTGCCGACGATCGCGGCG |
| ACCTCGCCCGCGTGCACGACAAGATCGACCCCGGTCAGGACGCGGCGGCGCTTGTAGCGTTTCACGACGCCGCGCGCCTG |
| CAGGAGAATCTTGCGGTCGGCGGGCTCGGACATGCCGTGGTACCCCTCTCGGGCACCGACGGAATGGCCCATGACTGCCA |
| CCTTTCTGCCGACCGCGACGAAGGGCACGCATTGTCGGCCTCAATGGTCAGGATGCGTGATCCGGTCGGGTTCATCGCCC |
| CGGCCGCACGCGCACGGCTCAGCCTGCCACACGGCCTGCCCCACATAGCGCGTATCGGTCGGGCCCCCACTTCCCCGAAA |
| GTCCGGGCCCCCGGCCGGTGTTCCGGGGATCCTACGGGGCGACCGGGCGAAGGACTGAAGCCGGGCATCCGCGTTTCGGC |
| CATCTCTCGCCGATACCCGGGGCGCCCTTGTAGGCCGGCCCGGGGCTGGTTAGCGTACCGACCGACCGCAATTCACCGCT |
| CACTCGTGCGTCGCCCGCACCAGCTTTTCCCTTCTTCCGGAGTCCGCCGCCGGGGCGGGAGCGGGCGGGACCGCACCCCG |
| TTCAGGCAAGAGGGAAATCCGCTCGGAATCGACGAAGGGGACGTGCATGCGCGGGGGGACCGTGGACCGTCGTGTCTGGT |
| GGCAACGGGCCGTGGCCCGCGGTTTCGCGCCCACCGCCGGCGCGGCCCACCCCGTTCGTCCTGGTGGGACCCGAGGGACC |
| GGACTCGGACGTCCGGGCGAGGTGCGCGCGGACGGCGTGATCGGCGCGCGGCCGGGCGGGGCGGCGTTCCGCTGCGTCCG |
| GCGGGCTCGGGGTGCTGCTGCCACTACGTCGGCAGTGCGACGCGAGCGCACGAGCAGACGTCGTCATGTGCTGCGCCGTC |
| TGGCCGAGGTGCGGGAAGCGCACCCGTCCCTGCCGCTGACCGTCTGGGTGGGCATGCAGTACGGCCCCGGGGAGGACGAG |
| GAGGCGCTGCGCAGGCTGCGCCGGCTGTGCGCCCCGGTGCCCGGGGGCCCGGCCCTCACCGTGGTCGGCCTGGCCCTGCC |
| CGGGCCGGGCAAGCTCCGCACGGTGAGCACGGTCCTGCGGCTCTCCGAGGACCTCGGCTACGCCGGCTGGCTCTGGACGG |
| ACGACGACATCGAGATCGCCCCCCACTGCCTCGCCCTGCTGGTCTCCCGTTTCCGGGAGCGGGGGGAGCGGGGCGCGGTC |
| GGGGCGCATTCGGTCGCGCTGGCCAGGGAGACGGTCACCTCACAGGCCATGGACCGGGTCTCCGGGGTCACCGCCCCGCC |
| GAAGGCCTGCCCGGCGGCGGCCTGCCTGGTCGTCGCGACGGACGTGCTGGGCACCGGCATTCCGGTCAGGCGCCTGACCG |
| ACGACGGGTACGTGGTGTTCGAACTGCTCGACGCCGGGGCGCCCGATCCGCTGCACGACCTGGAGGTGCTGCCCGAGGCC |
| CGGATCAGCTTCTACCGCGTCAGCCGCACCCACGACACGTTCCAGCGCCTGCGCCGCTCCCTCTACAGCCATGTGACCTG |
| CGTCGCCGACTATCCCTGGCCCACCGCGCGGGTCTACCTCACCCGGGTCCTCTTCCACGGTCTGTGGCCGCTCGCGGCGT |
| GGGACGGCAGCCGGGGGCCGGTGCACGGGCTGCAGCGCTGGCTGGTCAAGGGCCTGCACTTCACCTGGTTCTGCGGGGTG |
| GCCGGCTCGCTGGCGGTCCGGGGCGCGGTGGGACGGCCCCTTCGCCGGGTGGCGTGGGGCGACGAGGGGGACTTCCGCAG |
| CCCCACCGTCGAGGAGCCCGCCGCGGGAGCGGCCGCCGGGCGCTGACACACGAGGTCACCCCGAGGGGCGGCCCGGAAGG |
| AGACGCGATGGTGACAGCGGGGCCGGCCGGGGCGGCGGTGACCGTCGTCCTGCCTCACTACGACTGCGCGGCGTACCTGG |
| GTGCGGCCGTCGGATCGGTGCTCTCCCAGGACCGCCCGGACCTGCGCCTGACGGTGGTGGACGAATGCTCGCCCGAAGAG |
| AAGTGGGCCCGCGCACTCCACCCGTACGCCGGCGACCCCCGGCTGACCGTGGTCCGCACCTCCCGCAACGTCGGCCACCT |
| GCGGATCAAGAACAAGGTCCTGGAATCGGTGGACACCCCCTACGTGGCCTTCCAGGACGCCGACGACATCAGCCTGCCGG |
| GCCGGCTGCGCCACCAGCTGGCCCTCCTGGAGAGCGGCGGCGCCGATCTGGTCGGCTGCGCCTACTCCTACATCGACGAG |
| GCGGGCCGTACGACGGGACACCGGCGGATGCCCCGCAACGGCAACCTCTGGATGCGGCTGGGGCGGACGACCGTGCTCCT |
| GCACCCGTCCTCGGTGGTGCGGCGCTCGGTGCTCGAGAGGCTCGGCGGCTTCGACGGCACCGCGCGCCTGGGGGCCGACA |
| CCGACTTCCACCTGCGGGCCGCCCGCCTGTACCGGCTGCGCAGTGTGCGCAAGGTGCTCTACCGGTACCGGATCTGGCCC |
| AAGTCGCTCACCCAGGCGCCGGACACCGGGTTCGGGTCCGCGGAGCGCCGGGCCTACACCGAGGCGATGACCGCGCAGGA |
| GGAGCGGCGGCGACGGGCGCGGACCCGTGAGGAGCTGCTGCCGCTGCTGGTCGCCCCGCCCAACGACGTCGACTTCACCC |
| TGACCCGGGTCGACCTCGACTAGCCGACGGAGGGGGAACGGCGTGGACGGCACCTCGGCGAGGACCGCGGACGAGGCGTT |
| GCCCGGGGTCGCGGTGGTGGTGGTCGATCCGGACGGCGACGGGCGGCGCGCCGTGCGCGGCCTCCTCGCCCAGACGGTGC |
| GTCCCGTCTCGATCACCCTGGTGACGGCGGCCGGCCCGACGGCCGGCGGCACCCGGTCCCCCGGGCCGGCCGTGCCCTTC |
| GACGACCCGGCGGTGAAAGCCCGTACGGGTCGTCCGGTGCGCTCGCGGGGACCTCGGGCCGGCTTTGCGTCGACGCGGCC |
| AGGAACGCGGGGGCGCCGTACGTGGCCGTCCTCCGCGGTGACGACGAGGCGCTCCCCCACTGGCTGTGGCACCTGGCGCG |
| GGCGGTCTGGTACGGCGGCGGGGACGGCACCGGGCCGGTCGGCCTGGTGCAGTGCGGCGCCCTGCGGCTGAGGGACGACG |
| GCCTGGTGGACGGGTTCGCCCTGCCGCCCGCGTCCCCGCGGACCCGGCCCTCCCCCTCGGACCTCCTCGAGGGCGCCTAC |
| GCGGTGCGGCGCGAACTGCTGGACGCGGACGGCGGTACGGCGCCCTGGGTCGCCCTGCCCATGCCGCTGGTCCGCCGCCG |
| GTCCGGCGGCGCCGGGGACCCGGCCGCGGTCCTGGCCCCCGGGACGCGCGTCGCGCGACGCACCCGCCTGGTCCGGCACG |
| GGTACCGGCCGCCCGCCGCGAGGCCGCGGAACGGGAGCACTCCCCGGCTGGTGTCGGTGGTCGTCCCGGTGCGCAACGGC |
| GCCCGCACGCTCGCCGCCCAGCTGACCGCCCTGGCCCGGCAGACCGGAGCCGTCGCCTACGAGGTGCTGGTCGTCGACAA |
| CGGCTCGACGGACACCACCCGCGAGGTCGCCGAACGGGCCCGCGCCGAGCTGCCGGACCTGCGGATCGTGGACGCGTCCG |
| ACCGTGCCGGTGAGAGCTGTGCCCGCAACCGGGGAATCGCCGCGGCGCGCGGCGACTTCGTCGCGTTCTGCGACGCGGAC |
| GACGTCGCCGACACCGGCTGGCTGGCCGCGATGGCCCAGGCGGCCAAGGAGGCCGATCTGGTGGGAGGCGGACTGGAGAC |
| CTCCGTGCTCAGTCCCGGCCGCGTCGACGAGCAGCCCCTGCCGATGGACGCCCAGACCGATTTCCTGCCGTTCGCCCGGG |
| GGGCGAACTGCGGTGCCTGGAAGGACGTCCTGACCGCGCTGGGCGGCTGGGACGAGCGCTACCGGGGCGGCGGGGAGGAC |
| ATGGACCTCTCCTGGCGCGCCCAGCTCTGCGGTTACCTCGTCCGCTACGCGGACGACGCCCGGATGCACTACCGGTTGCG |
| GGACGGACTGCCGGCGCTGGCACGGCAGAAGTGGAACTACGGCCGTTCCGGGGCCCAGTTGTACGCCGCGTACCGGCGCG |
| CCGGGTTCGAACGGCGCGACGGCCGGGTGGTCGTCAGGAACTGGTGCTGGCTGCTGCTGCACGTTCCGAACCTGGTCCGG |
| TCCACCGGACCCTGCGGCCACGCTGAGTCCGCTACGCGCCCGGCTGGCCGGTTTCCTGGTTTGTGAACGTGCGGCAGGGC |
| GTCAGGTCCTTGTTGGTGGGCGGGCGTCCGGCGCCCGCGGGACGCCGGGCCGGCACCGCGGTGGCCCGGCGCGCCGCTCC |
| CGGGTTCAGACCAGCCGGTGGCCGGGGTCCTGCGCCACCGGGTCGTCGCCCGCCATGGCGAGGCAGGTGGCGCGCAGGGC |
| GGCGACGACGGCCTGGTCCTCGCCCCAGGCGTCGAGTTCCGGGCCGTCCCCCGCCTTCAGGGCCGGCACCGGCACTTCCA |
| TGATCTTCGGATGCCCGTGCCGGACCGGGGACTCGGAAGGGGCCACCAGCGCCTCGGTGAGCTTCTCCCCCGGCCGCAGC |
| CCGACGTAGCGGACCGGGAGCTCCGCACCGGCGTGCGCGATGAGCCTTCTGGCGATGTCGAGGATCCGGACCTGTTCCCC |
| CATGTCCAGGACCAGGGCGTGGCCGACGCTGCCCAGCGCGACCGACTGGATGACCAGTTCCACGGCCTCCTGGACGGTCA |
| TCAGATAGCGCGTCACCTCGGGGTGGGTGACCGTCACCGGTCTGCCGGCCGCGATCTGCCGGGCGAAGACGTCGAGGAAG |
| GACCCCTGGCAACCGAGCACGTTGCCGAAGCGCACGCTCACGTACGGTCTGCCCGCCTGGATCGCGGCCGCCGCGGTGAG |
| TCCTTCGGCTATGCGTTTCGAGTATCCGAGCACCCCGACCGGATCGACCGCCTTGTCGGTCGAGATGTTCACCAGGAACG |
| CGACGTCCGCGGCCAGGGCCGCCTCGAGCACCGCTCGGGTGCCGAAGACATTCGTCTTGACGGCTTCCCCGGGGAACTTC |
| TCCAGGATGGGCACCCATTTGAGGGCCGCCGCGTGGAAGACGGTGTCCGGCCGGCACTGCTGGAACAGCCGGGCGAGCCC |
| TCTGGAGTCCCTGATGTCCGCGAGGAGGATGGAGGTCCGCACCGACGGGGAGACGTTCCCGATGCTGGTGGCCGCCAGGT |
| GGAGGGCCGTCTCGTTCCGGTCGAGCATCATGAGGCTCTCGGGTTCCCACCGGCTGAGCTGCCGGCACAGTTCCGATCCG |
| ATGTAGCCGCCGGCTCCGGTGACCAGGATCCGTCGGCCGCGCAGTAATCCGGCGCTGCTCTCGAGACCGGTCCTTATTCG |
| TTGGCGGCCGATAATCCTCTCGAGGTCCAAgGTGAGAGGTCCACCGGCCGGAAAGTTCGCGTCGTACCCCACGGAATTAT |
| CGCCAAACATGCAGTCACACTTCCTTTTTGACAAGAGTCATGACTGACGTGCCGACCCACACGACGAACGGGACCGACGT |
| ATCGTCTTGGTGCTTTCCTCACCGGCACCACCGCGTTCCCCCACCGGTGCCTGCGCACGGGGATCACATTCCGGCGGCCG |
| GGTCGCCACCCGCTGCGCCGGCTCCGCCGACGTCGGACGTGTCCTCTTCCGACACCCCAGGACGACCGCGAAAATCACTT |
| TATCGAGGCGCGGCGCGGTGCGGGCGGGTTTTCTCAACGGACGCCCCGCGTCACCGGAACGCCGGGGCCGAGGAATTCGC |
| GCGCGCCCCGCAACCGGGTCCGGAGCCGGGCCCGCGTGGCATCGGTGACGAGACGGATGTCGAGGTTCCCCGGCGGGGCC |
| ACCTCGCTCCGCAGACCGGCCGGCAGCCGGGCCGGGTCCAGTCCGTCCCGCCGGGCTATGAGGACACCCAGGTCGTGACG |
| GTTCATCGCGTCCGGTCCCGCCACGTGGAACACCCCGGACCCGTCCGACGCCGCGATCTCCAAAAGCGCGGAGGCCAGAT |
| CGTCGACGTGGACCGGACAGCGGACGTCGTCCGTGAACAGGACGCCGGCGCGCCGGCCGGCCGCCAGGGCGTGCACCGCC |
| TCCTCGTGGGCGGACCGGTTGTGCCCCACGATGAGCGAGGTGCGCACCACGGCGGCCTCGGGCACGGCCACCCTGACGGC |
| CGTCTCCGCCGCGGCCTTGGCCGCGCCGTACGGGGAGACGGGGTCGGGGAGGGCCTCCTCCGGGTAGTGGACGTCGGCTC |
| CGGAGAACACGGCGTCGGAGGAGACGTGGACTAGTCGGCAGCCGGCGCGCGCCGCCTCCAGGGCGAGGCGGGCCGCGCCG |
| TCGGCCGTGACCGCCCAGTCGGCGTGTCCGCTCGACGCGTTGATCACCGCGGCCGGCCGGGTCCGGGCCAGCACCTCTCC |
| CATCCGCCCCGGGTCACGGAGGTCGGCCCGGTACCAGGTGACCGGCGGCAGTTCCTCGGGGCGGGTCCGGTAGGTCGCGG |
| CCACGTCCCACCCGGCGGCCACGGCCCGGCGGAGCACCTCGTACCCGAGGAAGCCGCTCCCGCCGACGACAAGAACTCTC |
| ACGCACCGCCCCCCTGACGTCCGGCCCGCCCCCGATCGCGCCCCAGAAGTACGGGGACGACGGCCTGTGCGGCCGTGTCG |
| AGCCGTGGTTCCTGTGGGCCCGATGCTACTGAAGGCCACCGAGCGGCGGGGAGAGTGAGTGCTTTCCGTCTTCGGTCCGA |
| ACCGGCCGGGGAGGCTCCGCAACGGCTCCCGCGGGCAGGAGGGCGGCGGCCCCGAGCGGCCTTGCGCACGGCGGGACGCC |
| GGGCCCGCGGTCCGAGGCGTTCCCCCGGGGCGCGCAGCCGGTGCCACCGGCGGGGCGGCGACGGCCCGTCCCGCTCCTGG |
| TCCCGGGGCGGGCGGCGTGTGACCCGCCCGCCCCGGCCGAGCGGGTGCGTCCCCGTCAGGCACGGCGGGGTGCGCCCCGT |
| CAGGTACGACAGGGAGCCGGGTTCTCCGGCCGGGCGGGGATCCCCGCCCGCACACGGGCGAGCAGGGCGGCCGGGTCCGG |
| GTCCGCCTGCAGGGACCGCAGCACCAGCGTCCACCACTGCTCCAGTCGCTCCCTCCAGTCCAGCCCGCCCGGCATCTCGT |
| CGGTCAGGGTGCAGAGTCCGAAGAACGCGCAGACGAGCGTCACGGCCGCGGCCGACGGCTCGACCCCTTCCGCGAGTTCG |
| CCCCCGGCGCGGGCCTCGGCGAGGAGCCGGGTGGCAGCCGCCGCCCAGGCGTCGAACGGCGGGGGCACGGCGGCCTCGAT |
| GGTGTGGCGCTCCGCCCACAGCCGGGCACCGGCACGTGCCACGACGTCCTCGCTGAGGGACTGCGCGACCCGGAAGCTGA |
| GGCCGACCAGCTTCTCCAGCGGAGGAACGCCGGGCGTGGTGTAGGCGGCGGCGAGTTGCGGCCAGGTGGCGAACTGCTCG |
| CGGACCACGGCCAATGCCAGCTTCTCCTTGCTGGAGTAATGGAAATAGATCGCCCCGCTGGTTCTTCCCGAGTGATCGCT |
| TATGTCATTGACGCTCGTTCCGGCATATCCCTGTTCAACGAACAGATGTGCCGCTGTTTCCAGCAGCACTTTGCGGGTTG |
| CACGCGCCCTGTCCTGCACTTCTGCTCCACCTTCGCTCACACACGCCGACGCCACGACGGAAAAGTCCAGGCGCCCCCGG |
| AGGCAGGGTCGCAGCGCGCGAAGATCTTATTATTCTTCGGCCGTGTGCGCCGCAGGGGCGACTTCACACAACACGCCCCT |
| CTGTCCGGCCGAATCGATTCGGGCGGGCGCGGGAACTCCGCCCCGATCAATGCCGCGGCACCCCGGAGGAGCCTCCCACC |
| AGGCCCGTTGGCCGCGTTCCGGGCGCTGCGGCCCCTCCTCCCGTTCCGTGTGCGGGAGTCGGCCGCCTTCGGCCGCGGCA |
| TGCACATACACCCGAATCGGTGATTGTGGAAATCGAAGAAGCGAAATTAACATAACGGGCACGATGTTTTTCGGCGTGGT |
| CGAAAGCGACGACCCGCGCCCGCCATGACGCGCCCACGGCGCGCTCAGCCGTGTCCACGTGGCCGCAAACGGCCGTGCGA |
| CATCACCCGTTTCCGCTCATTTCCGCGAGTGGACCACCCGCATCCCTGCACCCGCCTGCGCCCGTGCACCGAACCGGTCG |
| ACGCAGCCTCCCAGAACGGCAGTCACATGACAGCTCACCGCATCCTTTCCTGGTCCCCCTCCGCCATCGTCTTCGACTGC |
| GACGGAACCCTGATGGACACGGAACGACACTGGCAGGAGGCCCGGAACCTCACCTTCCGGGCGTTCGGCCTGAAACCGCC |
| GGCCGGGTTCGCCGACCGCGCCAAGGGCATGCACTACACCGAGTGCGGAGCGCTCATGGCCGAAGAGACCGGGAAACCGG |
| GCCTCGTCGGGGAGTTGACCGACACGCTCCTCGGCACCTTCACCACCCTGGTCGACCAGGACCCCGTCACCATGCCGGGG |
| GCCGCCTCGCTGGTCCGGCTGGCCTCTCGCCACCGCCCTCTCGCGGTGGCGAGCAACTGCCCCCGGGAGGTGGTGGAATC |
| ATGCCTCTACCGGGCCGGGCTCCTCGACTGCTTCGGCCACGTCGTGGTCGCCGGCGGGGAGGTACGGCCGAAGCCGGAAC |
| CCGACGTCTACGCGGTGGCCGCCCGCCTCTGCGGCGTCCCTCCCGAGGAGGCTCTGGCCGTGGAGGACTCGCTCACCGGT |
| ATGGAGTCGGCCCGCCGGGCGGGCCTTCGCGTCATCGGCATCGGACCGTGCCCACCGGGGCCGGAGGCGGAGAAGGCCGA |
| TCTGTGGGTCGCGAGCCTCGCCGACGGCGAGCTGCTGTCGTGGGCCCGCACCCGGATCGGCGAGTAGGACACCCGGGGCC |
| CCGTCGCACGGGGCCCGGGCGGGAGGGGCGGACCGCGGTTCCGTCAGCGGAGCCGGGCGGCGAACGCCGCGTACGCCTGC |
| TCGTCGAAGAGGACGAACCGGATCTCCTCCACCGCGGTTTCGGCGTCGCGCACCGTCTGCACCGCGATGCGCGCGGCGTC |
| CTCCATCGGCCAGCCGTAGACACCGGTGGAGACGGCCGGGAACGCGACGGTGCGCGCGCCGAGTCCGTCGGCGACCCGCA |
| GCGACTCCCGGTAGCAGGAGGCCAGCAGCGCCGAGCGGTCCTCCTCGCGGCTGAACACCGGGCCGACGGTGTGGATCACC |
| CAGCGGGCGTCCAGGTCGCCGGCGGTGGTGGCGACGGCCCGGCCGGTGGGCAGGCCCTCGCCGTACCGAGAAGCGCGCAG |
| GCGGCGGCACTCCTCCAGGATCGCCGGGCCGCCCCGGCGGTGGATCGCGCCGTCGACGCCGCCTCCGCCGAGCAGGGACG |
| AGTTCGCCGCGTTGACGATCGCGTCGGCGCTCTGGCGGGTGATGTCGCCCCGGACGAGGGTGAGGGTGGCGCTCATGTCT |
| GCCGCAGCCTCCTCCAGACGGCCTTCGCCGCGTTGTGTCCCGACATGCCGTGCACCCCGGGGCCGGGCGGGGTGGCCGAG |
| GAGCAGATGAAGACCGCGGGGTGCGGGGTTGCGTACGGGAACAGGGACGGTCTGGGGCGCAGCAGGAGCTGGAGTCCGGA |
| GGCCGCGCCGGTGCCGATGTCGCCGCCGACGTAGTTGGCGTTGCGGGCGGCGAGTTCGGGCGGGCCGGCGGTGGCGCGGG |
| CCAGGACGCGGTCGCGGAAGCCCGGTGCGTAGCGCTCCAGCTGGCGCTCGATGGCGTCGGTGAGGTCTCCGGTCCAGCCG |
| TGCGGGACGTGGCCGTAGGCCCAGAAGACGTGCTGGCCCGCCGGTGCCCGGGTGGGGTCGGCGACGCCGGGCTGCACGGT |
| GATGAGGAACGGCGCGTCGGGGGCCCGGCCCTCCCGGGAGGCGGCGCGCAGGGCGGCGCCGATCTCCCCGCTGTCCGCGC |
| CGATCTGCACGGTCCCGGCGACGCGGGCCTCGGGCGCGGTCCACGGCACCGGGCCGTCCAGCGCGTAGTCGATCTTGAAG |
| ACGCCGGGGCCGTACCGGTAGTTCGCGTAGGTGCCGCCGAAGCCGGCGATGCGGGCCAGGGCGGTGGGCGAGGTGTCGAA |
| GACGTAGGCGCGGGCGGGCGGCAGGTCGTCGAGGCGCTTGACCTCGTAGTCGGTGTGGACGCTGCCGCCGAGGTCCTTCA |
| GGTACGCGGCGAGGGCGTCGGAGAGCGCATGGAGCCGCCGCGGCCACGGCCAGCCGCGGGCGTGCGCGGCGAGGGCGAAG |
| ACGAGGCCGACGGCGCCGGTGGCGAGACCACCGAGGGGGGCCATCACATGGGCGACGAGCCCCGCGAACAGGGTCCTGGC |
| CCGCTCGTCGCGGAAGCGGCGCATGAGCCAGGTCGAGGGGGGCAGGCCGACCAGGCCGAAGCGGGCGAGGGTGACCGGGT |
| CGCGGGGCAGCGCGGTCAGCGGCAGGGACATGAAGTCGCGGACCAGGGTGTCCCACCTGGACAGGAAGGGTGCGACGAGC |
| CGTCGGTACGGGCCGGCGTCGCGCGGGCCGAAGGAGGCGGCCGTCTCGCCGACCGACCGGGACAGCACGGCCGCGGTGCC |
| GTCCGGGAAGGGGTGCGCCATGGGGAGCCGGGGGTGCATCCACTCCAGCCCGTAGCGCTCCAGCGGGAGGGCGCGGAAGG |
| CGGGCGAGTTGATGCCGAGGGGGTGCGCGGCGGAGCACGGGTCGTGCCGGAAGCCGGGCAGGGTGAGCTCCTCGGTGCGG |
| GCGCCGCCGCCCACGGTGTCCCTGGCCTCGAACAGGGCCACCGAGAAGCCGCGCCGGGCCAGCTCCACGGCAGCGGTCAG |
| CCCGTTCGGCCCCGCACCCACCACGACCGCGTCGAGCATCGACGGCACCTTCGGACTCCTTCGTCAGCCGACGGCCACTG |
| GCATCAGGATATGCCGGGGCGCCGGTACCGGGAGATCAGGCTCCTTCCGACAGCAGCCCCACCACCCGCTGTGCCGTGGC |
| CGCGTCGCGGGCCGCGGTGAAGGGGAGGGTGTTGCCGCCGGTGATGCGGAAGGGCTCGCCCGCGCGGGTCAGATGGGTGC |
| CGCCCGCCTCCTCGACCAGGAGCAGACCGGCCGCGTGGTCCCAGGCGGCTTCCCAGGAGAAGGCGGTGGCGTCGGACTCG |
| CCGCGGGCGACGGCCAGGTACTCCAGGCCGGCCGAGCCGCAGGGACGGGGTGCCACGCCCTCGGTCCGCAGGGCGAGCAG |
| GGACCGCTTCTGTTCGTCCGTGGTGAAGTCCGGGTGGGAGGTGGCCACGCGCAGGTCGCGGCCGGGTTCCGGGGAGCCCG |
| CGCGGAGCCGTTCGCCGTCGAGGTGGGCGCCCTTGCCCCGTACGGCCGTGGCGAATTGGTGGCGGGCCGGGGCGAAGGTC |
| CAGGAGGCGTACAGGACTCCGCGCCGGGCAAGGGCGACCAGGGTGCAGAAACCGGTGTCTCCGTGCACGAACTGCCGGGT |
| GCCGTCGACGGGGTCGACTATCCAGACCGGCGCCTCGCCCCGAACCGCCTCGTACGACGTCGGGTTGGCGTGCACGGCCT |
| CCTCGCCCACCACGACCGAGCCGGGCAGCAGGGCGGTGAGCGCCTCCGTGAGGTACAGCTCCGCCTTGCGGTCGGCGTCG |
| GTCACGAGGTCGTGCGGGCCGCTCTTCAGGTCCACCTCGTGTTCGGCGAGCCGGCGCCAGCGCGGCATGATCTCCTGCGC |
| GGCGGCCTTGCGGACGGCTTCCTCCACGTCGACGGCGTGCCGGTCGAGAAACTCTTCGATGGTTTCGTTGTCCTTGATCA |
| TGCCTCCATGAGACCACGCCCGGCCGACGTTCCCCACCGTCCCGGTGCACTGCGGGGGGAATCGGCATGAATATGGGGTG |
| CCGGACCACGGGCGGGTGGGCTCAGCGGCCCACCGCGTAG (SEQ ID NO: 1) |
| TABLE 3 |
| Sequence of Moe Cluster 2 |
| GACGAGAACGGAGTGCGCTGTTTCGGACGGGCGCGTCCGTCAGCGCGACGGAATGGACGGATCACGTGACCGACTTGCTG |
| GAGCCGAGGCAACACTGGGTTAGGCGGTTACACCCTTCACCGGACAGCGATGTCACGGTGGTCTGCTTCCCGCACGCGGG |
| TGGATCGGCCAGCTACTTCCACCCGTTGTCCGCTCGGCTGACGCCCCGTGCCGAGGTGCTGGCGCTGCAGTATCCGGGCC |
| GCCAGGACCGCCGGTTCGAGCCTGCGCTCACCAGTATCGACGAGCTGGTGGAGGGAATCACCGAGGCGCTGCGCGAGCAC |
| GTCGACCGGCCCCTCGTGTTCTTCGGGCACAGCATGGGCGGGACGCTCGCCTTCGAGACCGCGCGGCGCATGGAGCCGGA |
| GCTCGACGGGCGGTTGCTGGGGCTGGTCGTGTCGGGGCGCAGGTCGCCCGGCAGCGTGCGCCGGACGACGGTGCATCTGC |
| GGGACGACGCGGGGCTCATCGCGGAAATACGCGAACTGCAGGGGACCGCCTCGACGTTGCTGGACGACGAAGACGTGGTG |
| CGGATGATCCTGCCGTCCCTCCGCGCCGACTACACCGCGGTGGAGCGGTACGTGTACCGGCCGGGACCGGCACTGAGTTG |
| CCCCCTGTACGTCTACACCGGTGACGCCGATCCCCAGGTGAACGAGGAGGAGGCGGCGGGATGGGCGGAGCACACCCGCG |
| CGGACTTCCGGATCCGCACTTTCAGCGGCGGTCACTTCTACCTCGCCGAGCAGAGCGAGCAGGTGATCGCGGCACTGCGT |
| GAGGACGTGACGGGCTTCCAGGAGCGTTCCCGGACCGGCGCCGAGCGCTGATCCGGGCCCGGGAAGGGTGCACGCACCGG |
| ACGTGAGGCCGTGCAGTTCAGCCACCGCCGGCGAAGCGGGCGGCGAGTTCGCGTTTCAGTACCTTGCCGCTCGGCCCGAG |
| GGGGAAGTCCTCGACGAACTCCACCCGGCGCGGGTACTTGTACGCGGCGATTCGCTGCCTGCTCCAGGACACGATGTGCG |
| CGGCCAGCGCCGCGTCCGGATCCGTGCCCGGCCGCGTCCGCACCACGGCGCACACCTCCTCGCCGTACTTGTCGTCGGGG |
| ACACCGATGACGGCAACCTGGGCGACGGCCGGGTGACGCATCAGCACCTCCTCCACCTCGCGTGGATAGACGTTGTAGCC |
| ACCGCGCAGCACCATGTCCTTCTTGCGGTCGACGATGGTCAGATAGCCGTCGGCGTCCTTCATCCCCAGGTCGCCCGAGC |
| GGAACCAGCCGTCGACCAGCACGGCTGCGGTGGCTTCCGGCCGGTTGAGGTAGCCGGCCATGACGTTGTGGCCGCGTACG |
| ACGATCTCCCCGATCTCCCCGGCCGGCAGCAGCTCGATACGGTCCTCCACGTCGGCGGCGGCGATCTCCGCCTCCACGCC |
| CCAGATGGGGCGCCCCACGGTGCCGGGCCTGCGCGGCCACGCCTTCTGGTTGTACGCCACCACCGGCGAGGTCTCCGTGA |
| GGCCGTACCCCTCGTAGATCGGGCAGCCGTAGACCTCCTGGAACTCCTCGAGCACCTTGACCGGTAGCGCCGAACCGCCG |
| GAGAAGGCGCGGTCGAGCACGGGGCGGCGGGCGTCGTGAGCGGCGGCGTCGAGGAGGGCCAGGTACATGGTCGGGACGCC |
| CATGAACACCGTGCAGCCCTCGGTGACCATGAGGTCGAGCGCGCCGGGGCCGTCGAAGCGGTTCATGAGCACCAGGGTGC |
| CGCCGGCCAGGAAACAGGCGCTCATGCCGCAGGTCTGGCCGAAGGTGTGGAACAGCGGCAGACAGCCCAGCAGCACGTCC |
| TCGGGGCCGAGGTCGAACGGCGAGCGCATCGTGGTGCTGACGTTCATCACCAGGTTGAGGTGGGTGATCATCGCGCCCTT |
| GGGCCGGCCGGTGGTGCCCGAGGTGTACAGCACCAAGGCCAAGTCGTCGGGCGCGCGCGGCACCAGACCGTCCAGGGGCT |
| CCGCCCGTTCGGCGAGCACGTCGAGGCGTGCCGGGCCGTCGTCGTCCTCGCCGTTCTCGACCATGACGGTGAGCAGCGGA |
| ACCCCGGCCGTCCCGGCCGCCTTGGCGCCCTCGGTCAGCATCGGGGCCGCGCACACCATGGCCTTCGCCTCGGAGTCGCC |
| CAGCACGTGGACGATCTCGTCGGCACGCAGCAGGCCGTGCACCGGGACCACCACGGCACCGAGCGCCAGCACGCCGTAGT |
| ACACCATCGGGAAGTGCGGTGTGTTCGGCAGCAGCAGGGCGATCCGGTCGCCCGGGCGCACACCGCGGTCCCTCAGCACC |
| GCCGCGTACCGGCGGGTTGCGAGCCAGAGCTCGGCGTAGGTGATGCGTTCGGAGCCGAAGACGAGCGCGGGGTGGTCGGG |
| GCGTCGCCCGGCGGACTCGGCCAGTACGGACGCGGCGGTCAGGGTCATGCCGCACCGTTGTGCCGTGCGGCCAGCGCCGG |
| CTTGTCCGGTTTTCCGGCACGGGTGAGGGGCAGCGCGTCGTGGAACGTCACCACGGCCGGTACGTGCTTCGGAGACAGCT |
| CGGCGGCGACGTGGCCGATCAGCGTCCCGGAGTCGGCGGTGCCGCCCGGCCGTACCACGACGGCGGCGTGGATGTGCTCC |
| ACGCGGTCCTCGTCGACCACGCAGTACACAGCGGCCTGGGTGACCTCCGGATGGGTCAGCAGCGCGTTCTCCACATCGGT |
| GGGATGGACCTTGATGCCGTTGGTCTTCATCACCTCGCCCATGCGGCCGTGCAGGCGCAGAAAGCCGTTCTCGTCGAGGG |
| AACCGAGGTCGCCGGTGTGCACCCAGCCGTCGCGGATGATCGCGGCGGTCAGCTCCGGTTCGCCCCAGTAGCCGAGCATG |
| GTGGACGGGCTCTGCACGCACACCTCGCCGATCTCGCCGGGCGGCAGGTCGCGGTCGTCGTCCACGTCGCGGATGCGTAT |
| CTCCGTGGTCGGAGGTCCGACGGTCCGGCGCAGTTCCGGGTCGAAGTGGTCCTGCGGCATCAGCATGCTGATGCCGTTGA |
| CTTCCGTGGTCCCGTAGAGCTGGAGCAACACCGGGCCGAACACCTCGACCGCCTCGGCCAGTCGGGCGGGGGCCGCGGGG |
| GAACCGAGGTAGGTGATGAGCCTGATGCTCGAACGGTCGGTGGTGGCGGTGTCGGGGTGGTCGATCAGCATGTACAGCTG |
| CGGCGGGGTGATGGTCAGCGTGGAGACGCGGTGCTGTTCCACGGCCCGCAGCACTTCGCCCGCCTCGAACCCGTCGTGCA |
| GGACGACCGTTCCGCCGGAGGCGAGCGCGACGTCGACGGCGGAGCCGCTGGAGTTGCTCACCGGCAGGGTCGACAGGTAC |
| ACGATGGGTTCGGGGGACTGGAGGGCCACTTGGAGGTTGGCACGGCGAAGGCGGTACGGCTGCGTGACACCCTTGGGACG |
| TCCGCTGGTACCGCTGGTGTAGATCACCACGGCCGGCTGTTCGGGGTCGGCCTCGACGGCGTCGTGGCCGAAGGCGTCCG |
| GGTCGCCCGACGAGAGGTCCAGGACATCGGGGCCGAGGGCACCGAGAGCGGCGAGACGCGGTGGCTCGGGCAGCCGGTCG |
| CACAGCTCTCGGGCCGCGTCGAGGTTCTCCTTGTCGACGGCGAGGAAGGTCGCCCCGGTCTTGCTGAGAATGTCCAGCCG |
| GGCGGCGGCGGCCAGCTGGTCGGTGGGGTCCACCGCGTTCGTGGAGTGCAGGTGGACCAGGGTGGCCCCGGCCAGGTTGG |
| CCGCGTAGCGGAGGATGATGGTCGCCGGGCTGTTGGTGACGGTCAGCACCGCCACAACCGGGGCCTTGCCTTCCGCACTC |
| GGGTCTCGATGTTCCGTGAAGTGCCGGAGGAGAAGTTCCGCTGCCGTGAGAACCGCCCTGGAGACCTGGCCCGCGGTGAT |
| TTCTTCACCATCCGCCCACAGGGCAATCCGGTCGGGGTCGGAGGCCAGCGCCTCAAGCACCCGGCGGACGTAATTCTCGT |
| TCGAGGACATCGTTCCCCCACCATGCTGGTTCGTTTATCGGTCAGTGCAGACTTACATGATCGCGCGAAAGCGCGACAAC |
| CCGCTCTCGGTAACCATTGGGCGTGCGGCCGGTGAGCACGGCTGCCGTCGGCCAGTTCTCAACACCCGGCAGCCTTGGGC |
| GAGTTGAATGCCTGCCGGAGTCGATGATATACAGACGTTACCTTCATGCCCTTCCCCTGTGTTGCGAATGGTGAGGCCGC |
| TCCCGCGCGATTTCGCCAGTGACACGTTCGCACCGGCGCCGGGGACAAGCAGAATCCAGTCATGGCCGTGCGATTTCAGC |
| CAGTTATGCGCGGTTGCCCGTAGTTGCATGTAGCCTCAGACGGCCTGGAACGAAGCGAGTAGACGTGACGACCCAATATC |
| TGGATCTCTTTGCACGCCTCACAGAAAACTCCGACGGGGGAAAGAGGGAGTTCCTGGAGATCGGACGGCTCGCCGGGAGC |
| TTCCCCGCGGCCAGCGTCCGCAGCAGTGGACCCGTGACCGGCCGGGACAGCATCAGCGTCTGGTGCAGCAACGACTACCT |
| CGGCATGGGCCAGCATCCCGCAGTGCTCAAAGCCATGAAGGACGCGATCGACGAGTACGGCGCCGGCGCCGGCGGCTCAC |
| GCAACATCGGCGGCACCAACCACTACCACGTGCTGCTGGAGAGAGAGCTCGCCGCGCTCCACGGCAAGGACGAGGCCCTG |
| CTGTTCACCTCCGGTTACACCGCCAACGACGGTGCGCTGTCCGTCATCGCCGGCCGCATGGAGAAGTGTGTCGTCTTCTC |
| CGACGCACTCAACCACGCGTCCATCATCGACGGCCTGCGCCACAGCCGCGCCCAGAAGCAGATCTTCCGCCACAACGACC |
| CCGCTCACCTGGAAGAACTGATAGCGGCGGCCGACCCCGACGTCCCCAAGCTCATCGTCGCCGAGTCCGTGTACTCGATG |
| AACGGCGACATCGCCCCGCTGTCCGAAATCGCCGACATCGCCAAGCGCCACGGGGCGATGACGTACCTCGACGAGGTGCA |
| CGCGGTGGGCATGTACGGCCCGGAGGGTGCCGGCATCGCGGCCCGGGAGGGCATCGCCGACGACTTCACCGTCATCATGG |
| GCACCTTGGCCAAGGGTTTCGGCACCACCGGCGGCTACATCGCAGGGCCCGCCGAAATCATCGAGGCGGTGCGCATGTTC |
| TCCCGCTCCTTCGTCTTCACCACCGCGCTGGCGCCGGCCGTGGCCGCCGGCGCCCTGGCAGCCGTACACCATCTGCGGTC |
| CTCCGAGGTCGAGCGGGAACAGCTCTGGTCGAACGCGCAGTTGATGCACCGGCTGCTGAACGAGCGTGGCATCCCCTTCA |
| TTTCGGACCAGACGCACATCGTGTCCGTCATGGTGGGGGACGAGGCCGTGTGCAAGCGGATGTCCGCGCTGCTGCTCGAC |
| CGGCACGGAATCTAGGTGCAGGCGATCAACGCGCCGAGCGTGCGGGTCGGTGAGGAGATCCTGCGGGTCGCCCCCGGAGC |
| CGTGCACACCGCCGACGACGTACGCGAATTCGTCGACGCTCTGAGCCAGGTCTGGGAGGAAGTGGGCTCCGCCCGCGTGC |
| CGGCGACCCCGGCCGCTCTCTGATCCGTCCACGTCAAGATGTGCGGGCCACGGCTACGCCGGCCAGATGTGCGGACTCCG |
| GTTCTCGGGGAGGGCGGTGTGTCTTTGACGTGTCACGCACGTACGGCGGAAACGAACGGCGCTTTCCTCACGGACCATGG |
| ACAGGGACCCTGCCCCACGGTCAGGACACGGACAATGTCGAAAGGCTGCCGGAAGGCTCGCAGGACATGCGCCTCGGCCG |
| AAGACAAGTCCGGCCGGTCCCTCATACTCGACCCACAGGTCCCGGAACCCCGCGCATCCGGAGAACGGGCCGGACACCCG |
| TGGAGTGCCCGGCCCGTCACGGTGCCGCGTACCTACGTGTCTGCTCGGAGAACGCCGTCTACCTCGCCATGGCCGTGCTC |
| CTGGTGCGTCGCCTCACGAGACCAGTCCGCTGAGAGGCTTTTCAGACGCCCTCTAGGGTGCGGGCTCCCAGATCCTGACC |
| GCACCGCAACCGCACGACTGGACCGAGATCGGCGGCCGGGTGCTCCTGGAGTGCTGAGCCTGCGCTCAGCCCATCTCCTC |
| CAACGTCCTGCCCTTGGTCTCCGGCACCCACTTGAGGATGAACGGGACCGCCAGCGTGGCGAAGATCGCGTAGATCACGT |
| ACGAACCGGACAGGTTCCACTCCGCCATGCTCGGGAACGTCGCGGTGACCAGCCAGTTGGCGACCCACTGCGCGCAGGCG |
| GCGACGCCGAGCGCGGCCGCGCGGATGCGGCTGGGGAACATCTCGCCCAGCAGCACCCAGGCCGCCACGCCCAGCGACAT |
| GGCGAAGAAGAGGACGAAGGCGTGGGCGGCGACCAGCGCGACGGTGGCCTGGGTGTCGGGCAGCGAGATGTCGTCACCCG |
| TTCCGGTCTTGTAGGAGAAGGCCCAGGCGACGGCGGCGAGGGAGACCGCCATACCGGCGGAACCGGTCGCGGCCAGCGGC |
| TTGCGGCCGACCCGGTCGATGAGCACCATCGCGATCACCGTGCCCACGATGTTGATGACCGAGGTGGTGAACGAGTAGAA |
| GAACGAGCTCGACGGGTCGATGCCCACCGACTGCCACAGCGAGGAGCTGTAGTAGAAGATCACGTTGATACCGACGAACT |
| GCTGGAAGACCGACAGGCCGACACCGACCCAGACGATCGGCAGCAGGCCGAAACGGCCGCGGAGGTCCTTGAACCGCGGT |
| GCCTTGTCGCTGCGCGCGGCGTGCTCGATCTCGGCCACCCGGGCATCGAGATCGACCTGCGCGCCTTCGAGGGTGCGCAG |
| CACCTCCTTGGCCTCGCCGGTCCTGCCGACTGAGACCAGGTAGCGCGGCGACTCCGGGATGCGCAACGCCAGCAGACCGT |
| AGACCAGGGCGGGAACGGCCGCGATGCCGAGCATGACCTGCCACGCCTCCAGTCCGAGCAGGCTGCCGCGCTGGTCCCCG |
| TCGGCGAGGGAGAGCACCATCCAGTTGACCAACTGGGAGACGGCGATGCCCAGCACGACGGCGGCCTGCTGGAAGGAGAC |
| GAGCCGGCCGCGGTACTCGGTGGGCGCGACCTCGGCGATGTACGTGGGGCCGATCACGGAGGCCATGCCGATGGCCACGC |
| CGCCCACGATGCGCCAGAAGGACAGGTCCCACGCCGTGAACGGCAGCATCGAGCCGATACTGCTGGCCAGGAAGAGCAGG |
| GCGGCCAACTGCATCACCCGGAGGCGGCCGACGCGGTCGGCGAGCCGTCCCGCGAGCATGGCGCCGGCGGCCGCGCCGAG |
| CAGGGCGATGGCGATGACGGCTCCGAGCGTGGCGGCGCCGACGTCGAACCGTCCCCTGATGCCCTCGACGGCGCCGTTGA |
| TCACGGCGCTGTCGTAGCCGAAGAGGAAGCCGCCCATGGCGGCGGACGCCGCGATGAAGACGACGTGAGGCAGCTGGTTC |
| GGCCGGGCCGCGAGGCCCCCGGCGGCGGGTTGTTGTGCTGTGCTCGTCACCTAAGGACTCCTGTGGTGATGTGTGTCGTT |
| (SEQ ID NO: 2) |
The clusters, and relative positions of the genes are shown in FIGS. 3A-3B. In general, the genes for chromophore biosynthesis appear to be in cluster 2; all other moe biosynthetic genes appear to be in cluster 1.
Constant rearrangements of chromosomal markers located in the ends of linear streptomycete chromosome is well documented (Redenbach 1993, Bentley 2002, Hopwood 2006). This may account for the duplication and divergence of the moe chromophore biosynthetic genes in S. ghanaensis, thus leading to the two-cluster organization. Such clusters are not unique. For example, the ansamitocin and clavam biosynthetic pathways from Actinosynnema pretiosum and S. clavuligerus, respectively, are also encoded by unlinked groups of genes (Yu 2002, Tahlan 2004). These findings suggest that a multi-clustered organization of secondary metabolism genes might be more common than it is anticipated.
A summary of the identified genes and their proposed function is presented below in Table 4. A detailed discussion of each gene and its function is presented in the Experimental Examples, Section III. In total, twenty-three open reading frames (ORFs) were found to be related to moe A biosynthesis (i.e. moe biosynthesis-related genes). The function of the encoded proteins was determined via bioinformatic and genetic analysis. The identified genes are sufficient for the biosynthesis of all four structurally different parts of moe; that is, the genes encoding the proteins necessary to form a structurally complete moe A molecule were identified.
| TABLE 4 |
| Deduced functions for genes in moe gene clusters 1 and 2 |
| Amino | ID %/ | Acc. No. of | ||||
| Cluster | ORF | Acids | Homologue | SI % | homologue | Proposed function |
| 1 | MoeB5* | 301 | Putative acyl CoA ligase | 58/76 | AAX98210.1 | Nonfunctional acyl |
| (S. aizunensis) | CoA ligase | |||||
| 1 | Moe A5 | 394 | As in case of MoeC4 | 64/78 | AY240962 | Nonfunctional |
| Aminolevulinate | ||||||
| synthase | ||||||
| 1 | MoeD5 | 638 | Putative ABC transporter | 41/55 | YP075256.1 | ABC transporter |
| (Symbiobacterium thermophilum) | ||||||
| 1 | MoeJ5 | 564 | As above | 45/61 | YP075255.1 | ABC transporter |
| 1 | MoeE5 | 340 | Putative UDP-glucose 4-epimerase | 46/58 | YP074610.1 | NDP-hexose |
| (Symbiobacterium thermophilum) | 4-epimerase | |||||
| 1 | MoeF5 | 645 | WbpS | 29/43 | AAF24002.1 | Unit F |
| (Pseudomonas aeruginosa) | Amidotransferase | |||||
| 1 | MoeGT1 | 402 | Putative glycosyltransferase | 28/40 | EAM38951.1 | Glycosyltransferase |
| (Polaromonas sp) | (transfers unit F) | |||||
| 1 | MoeH5 | 513 | AsnB-like amidotransferase | 32/48 | CAI08539.1 | Unit B |
| (Azoarcus sp) | Amidotransferase | |||||
| 1 | MoeK5 | 407 | Putative methyltransferase | 34/52 | NP142754.1 | Methyltransferase |
| (Pyrococcus horikoshii) | ||||||
| 1 | MoeGT4 | 427 | Putative glycosyltransferase | 27/38 | EAS23724.1 | Glycosyltransferase |
| (Mycobacterium vahbaalenii) | (transfers unit E) | |||||
| 1 | MoeM5 | 530 | GdmN | 29/44 | AAO06921.1 | Carbamoyltransferase |
| (Streptomyces hygroscopicus) | ||||||
| 1 | MoeN5 | 260 | Putative prenyltransferase | 30/58 | NP220145 | Prenyltransferase |
| (Chlamydia trachomatis) | ||||||
| 1 | MoeO5 | 281 | GGGPS | 27/43 | JC7965 | Farnesyl-3- |
| (Thermoplasma acidophilum) | phosphoglycerate | |||||
| synthase | ||||||
| 1 | MoeX5 | 266 | Putative membrane protein | 26/40 | EAS99725.1 | ABC transporter |
| (Mycobacterium sp) | membrane protein | |||||
| 1 | MoeP5 | 233 | ABC transporter ATPase | 43/58 | EAS11435.1 | ABC transporter |
| (Mycobacterium flavescens) | ATP-binding protein | |||||
| 1 | MoeGT5 | 312 | MoeGT4 (see above) | 45/59 | Glycosyltransferase | |
| (transfers unit C) | ||||||
| 1 | MoeGT2 | 286 | Putative glycosyltransferase | 35/51 | AAU93096.1 | Glycosyltransferase |
| (Methylococcus capsulatus) | (transfers unit B) | |||||
| 1 | MoeGT3 | 414 | Putative glycosyltransferase | 44/56 | ZP_00616987.1 | Glycosyltransferase |
| (Kineococcus radiotolerans) | (transfers unit D) | |||||
| 1 | MoeR5 | 374 | CapD (Nocardioides sp) | 53/68 | EAO07657.1 | Hexose-4,6-dehydratase |
| 1 | MoeS5 | 282 | SCO7194 | 62/75 | CAC01594.1 | Hexose-4-ketoreductase |
| (Streptomyces coelicolor) | ||||||
| 2 | Moe A4 | 516 | Putative acyl CoA ligase | 63/73 | AAX98210.1 | Acyl CoA ligase |
| (Streptomyces aizunensis) | ||||||
| 2 | MoeB4 | 521 | SimL | 45/62 | AAG34163.1 | Amide synthetase |
| (Streptomyces antibioticus) | ||||||
| 2 | MoeC4 | 412 | HemA-AsuA | 70/83 | AY240962 | Aminolevulinate |
| (Streptomyces asukaensis) | synthase | |||||
EXAMPLES
Genes involved in the synthesis of moe A were cloned and characterized from S. ghanaensis ATCC14672. This was followed by bioinformatic and genetic analysis of the identified moe sequences via a combination of gene disruption and heterologous expression approaches. Although not wishing to be bound by any theory, a likely moe A biosynthetic pathway has been elucidated (discussed below in section V). This pathway (see FIGS. 4A-4D) appears to explain the mechanism of phosphoglycerate incorporation into bacterial secondary metabolites. Furthermore, the pathway provides a basis to generate and identify bioactive derivatives and intermediates of moe A, which may have clinical use as peptidoglycan glycosyltransferase inhibitors.
This section is divided into five main parts. Part I describes exemplary materials and methods used in many of the examples that follow. It will be clear to those skilled in the art that in some aspects of the experimental examples, other methods, reaction conditions, protocols, etc. may be used with comparable results. Part II describes the cloning of moe A genes from S. ghanaensis ATCC14672, and Part III describes the bioinformatic and genetic analysis of each gene identified in Part II. Part IV describes the characterization of several moe A intermediates. Part V describes a theoretical, overall assembly scheme for moe A based on the information from Parts II and III. Finally, Part VI includes additional experimental examples to show the diversity and utility of the methods and compositions disclosed herein. All experimental examples, whether actual or prophetic, are presented to be instructive and not limiting.
I. Materials and Methods
A. Bacterial Strains and Vector DNAs
Moes producers S. ghanaensis ATCC14672 and S. bambergiensis NRRL-B12101 were obtained from American Type Culture Collection (“ATCC”) and the U.S. Department of Agriculture, respectively. S. lividans TK24, S. coelicolor M145 (Kieser 2000), S. cyanogenus S136 (Westrich 1999) were used in studies on moe A resistance in Streptomyces. Bacillus cereus ATCC19637 was used as a moe-sensitive test culture.
Escherichia coli NovaBlue (Novagen, San Diego, Calif.) was used as a general cloning host. E. coli XL1 Blue MR and cosmid SuperCos1 (Stratagene, La Jolla, Calif.) were used for generation of the S. ghanaensis genomic library. Methylation-deficient strain E. coli ET12567 carrying conjugative driver plasmid pUB307 (Flett 1997) was used for intergeneric E. coli-Streptomyces conjugations. E. coli BW25113 (pLU790) was from John Innes Centre (Norwich, UK). S. lividans J1725 (bidA mutant) and pIJ584 plasmid harboring intact bidA gene were donated by B. Leskiw (University of Alberta, Canada). Strains S. ghanaensis MO12, LH1, OB20a, OB21e with disrupted moeGT3, moeA4, moeM5, moeGT1 genes and S. lividans strains expressing various subsets of moe genes were constructed as described below.
Conjugative shuttle vector pKC1139 with temperature-sensitive pSG5 replicon (Muth 1989, Bierman 1992) was used for gene disruption and expression in S. ghanaensis. Vector pMKI9 is a derivative of pKC1139 with the ermE promoter inserted into a polylinker (provided by I. Ostash, Dept. of Genetics, Ivan Franko National University, L'viv, Ukraine). Vectors pKC1139, pSET152, pMKI9, pOOB40 are described in Ostash 2007. Integrative vector pSOK804 (Sekurova 2004) was from S. Zotchev (Norwegian University of Science and Technology, Trondheim, Norway). Expression vector pAF1 (oripIJ101 bla tsr, PermE*, 6His tag) was provided by A. Bechthold (Freiburg University, Germany). Plasmids pKD4 and pCP20 (Datsenko 2000) were from J. Beckwith (Harvard Medical School, USA). Spectinomycin resistance cassette pHP45 was from J.-L. Pernodet (Université Paris-Sud, France). Apramycin resistance marker aac(3)IV in integrative conjugative vector pSET152 (Bierman 1992) was replaced with a spectinomycin resistance gene aadA to yield plasmid pOOB5. Plasmid pOOB40 carrying hygromycin resistance marker (“hyg”) was generated in the same way.
B. Media and Culture Conditions
LB and LA media were used for cultivation of E. coli strains and Bacillus cereus ATCC19637. For moe A production, S. ghanaensis was grown on solid YMA medium (yeast extract: 4 g/L; malt extract: 10 g/L; glucose: 4 g/L; agar: 18 g/L; pH prior to autoclaving was adjusted to pH 7.5) or in liquid medium (LM) described in Subramaniam-Neihaus (1997) or in mTSB (tryptic soy broth supplemented with 0.5 g MgCl2 and 2.5 mL of trace elements solution (Kieser 2000) per 1 L of medium). For abundant sporulation, Streptomyces strains were grown on OM agar (Gromyko 2004). E. coli-S. ghanaensis conjugative mixtures were plated onto either MS agar (Kieser 2000) or OM agar supplemented with 10 mM MgCl2. For chromosomal DNA isolation S. ghanaensis was grown in TSB. E. coli strains were cultivated at 37° C. B. cereus and Streptomyces strains were grown at 30° C. for 2-3 days unless otherwise stated in a description of specific procedures.
C. DNA Manipulations
Table 5 summarizes the primers used for PCR. Plasmid preparation from E. coli was carried out using Qiagen nucleic acid isolation kits according to the manufacturer's instructions (Qiagen, Valencia, Calif.). Total DNA from S. ghanaensis was isolated using a salting out method (procedure B; Kieser 2000). For genome sequencing, chromosomal DNA of S. ghanaensis was isolated from a strain passed through three 4-day rounds of growth at 40° C. (to obtain a strain free of endogenous plasmid pSG5) and additionally purified using Qiagen Genomic-tip 500/G (Qiagen, Valencia, Calif.). Ultracentrifugation experiments and in silico genome analysis showed that the total DNA submitted to the Broad Institute (Cambridge, Mass.) for genome sequencing did not contain pSG5 or other small (e.g., 10-50 kb) plasmids.
For recovery of shuttle E. coli-Streptomyces plasmids from S. ghanaensis, E. coli was transformed with the total DNA of recombinant, plasmid-containing S. ghanaensis strains and then selected for appropriate resistance markers. Plasmid DNA from E. coli clones was then isolated and mapped with restriction endonucleases to confirm their identity.
Restriction enzymes and other molecular biology reagents were obtained from commercial sources and used according to the manufacturer's instructions. DNA treatment with endonucleases, Klenow fragment, T4-polymerase, phosphatase and T4-ligase was performed using standard methods (e.g., Sambrook 1989). Southern analysis, digoxigenin labeling of DNA probes, hybridization and detection were performed according to the manufacturer's protocols (Roche, Alameda, Calif.). PCR was performed using KOD Hot Start DNA polymerase (EMD Biosciences, San Diego, Calif.) with addition of DMSO to reaction mixture (10% of final volume).
| TABLE 5 |
| Oligonucleotide Primers for PCR Analysis |
| Name | Primer Sequence (5′ to 3′) | SEQ ID NO. |
| ligup1HindIII | AAAAAGCTTGACGACTTGGCCTTGGTGCTGT | 49 |
| ligrp1EcoRI | AAAGAATTCCGTTTCAGTACCTTGCCGCTCG | 50 |
| CTcon73for | AAAAAGCTTGACCGGGAACTCGCCGAG | 51 |
| CTcon73rev | AAAGAATTCGTCGTAGGGAACGGCCCG | 52 |
| GTcon72for | AAAAAGCTTGACCTGACACTCGTCGGCTTC | 53 |
| GTcon72rev | AAAGAATTCTCGAGACGAGGAGCCCGTAC | 54 |
| GT2con73up | AAAAAGCTTGTTCTGCGACGCGGACGAC | 55 |
| GT2con73rp | AAAGAATTCAGGTTCGGAACGTGCAGCA | 56 |
| moeM5nEcoRXbaup | AAGAATTCTAGATCGAGTGGGCTCCCTACTC | 57 |
| moeM5nEcoRIrp | AAAGAATTCACCTGGGGGAGTGACCGAC′ | 58 |
| moeGT5up_P1 | GCAGTGCGACGCGAGCGCACGAGCAGACGTCGTCATGT | 59 |
| GTAGGCTGGAGCTGCTTC | ||
| moeGT5rp_P2 | TCGGGGTGACCTCGTGTGTCAGCGCCCGGCGGCCGCTCC | 60 |
| ATATGAATATCCTCCTTAG | ||
| moeGT2up_P1 | CGAGGAGCCCGCCGCGGGAGCGGCCGCCGGGCGCTGAC | 61 |
| AGTGTAGGCTGGAGCTGCTTC | ||
| moeGT2rp_P2 | GCCGAGGTGCCGTCCACGCCGTTCCCCCTCCGTCGGCTA | 62 |
| CATATGAATATCCTCCTTAG | ||
| moeGT2up_check | ACGAGGGGGACTTCCGCAG | 63 |
| 38start_KD4 | CGTGCGCAGCGCGGTCTTCGGCTTCGACGGGGTACGGAT | 64 |
| GAATATCCTCCTTAGTTC | ||
| moeA5_P3 | AGACGCGCCGGGCGGCCCCCAGTTCGGACCAGATGCCG | 65 |
| TAGGCTGGAGCTGCTTCG | ||
| P2_KD4 | CATATGAATATCCTCCTTAGTTC | 66 |
| alsrev1 | AAATCTAGATCAAGAGCGGCCGGGGTC | 67 |
| moeF5up_P3 | CGGCTCCTCGGTGTCCGTGCCGCGGCTGTAGGCGGCATG | 68 |
| TAGGCTGGAGCTGCTTC | ||
| moeF5rp_P2 | TGGACGAGCGGTCGGTCGGGGGCAGCCATGGGTCTCCT | 69 |
| ACATATGAATCTCCTTAGTTC | ||
| F5check_up | GTCTCGGTCAACGAAGTGGTC | 70 |
| F5_check_rp | CTCTCCAGGGAGATGGTCCG | 71 |
| moeGT4up_P3 | TGCACAGCCTGTACCGGTCGACCTCCAACACCGACCGTG | 72 |
| TAGGCTGGAGCTGCTT | ||
| moeGT4rp_P2 | TCAGCTCTCCTGACGCGTGGGTGAGGACGACGGAGTGA | 73 |
| GCATATGAATCTCCTTAGTTC | ||
| moeK5-P1 | TCCAGAAGCGGGCCGGCGTGCTGCCGCACCTCGGGGCT | 74 |
| GTAGGCTGGAGCTGCTTCG | ||
| moeK5-P2 | TGTGCAGGCCGTCCAGCGTGTTGCGCCACTGGCCGGTCA | 75 |
| TATGAATATCCTCCTTAG | ||
| GT2con72up | AAAAAGCTTGTTCTGCGACGCGGACGAC | 76 |
| GT2con73rp | AAAGAATTCAGGTTCGGAACGTGCAGCA | 77 |
| moeH5up_P1 | AGGCCGCCCTCCAGCCCCTGCTGGACGCCCGATGACGGT | 78 |
| GTAGGCTGGAGCTGCTTC | ||
| moeH5rp_P2 | TCTCGTGAAGTGGGGGTCTGCGGCGGTCCGGCCCCGCTA | 79 |
| CATATGAATATCCTCCTTAG | ||
| moeN5up_P1 | CCGGCCACGGCCCTGCCGGCGGACTACACGGAGACCAT | 80 |
| GTAGGCTGGAGCTGCTTCG | ||
| moeN5rp_P2 | GGACGGCCGGCCGGAGACGCTCCGGCCGGCCGTCGGTC | 81 |
| ATATGAATATCCTCCTTAG | ||
| moeGT3intMfeI | AAACAATTGTTCTGCGACGCGGACGAC | 82 |
| orf1intXbaI | AAATCTAGAGGACTCTGCACCCTGAC | 83 |
| moeR5XbaIup | AAATCTAGACGCGATGAACCGTCACG | 84 |
| moeGT3XbaIup | AAATCTAGACGTGCCCTTCGACGACCCG | 85 |
| moeGT3EcoRIrp | AAAGAATTCCCACGCCCTGGTCCTGGAC | 86 |
| moeN5XbaIup | AAATCTAGACAGGTCACCGAGTACCTCGA | 87 |
| moeN5EcoRIrp | AAAGAATTCCGCTGATCAACACGTCGCTC | 88 |
| moeF5XbaIup | AAATCTAGACACCCAGATCGAGTGGACC | 89 |
| moeF5EcoRIrp | AAAGAATTCATGGGTCTCCTAGGAGAG | 90 |
| moeGT4XbaIup | AAATCTAGAGTACCGCTCCTTCTTCATGC | 91 |
| moeGT4EcoRIrp | AAAGAATTCAGTGGAGCGACAGTACCTTC | 92 |
| moeH5XbaIup | AAATCTAGACTGGACCAGGACGCGGTG | 93 |
| moeH5EcoRIrp | AAAGAATTCGCTGATGTCTCGTGAAGTGG | 94 |
| moeGT5XbaIup | AAATCTAGAGGGACCGGACTCGGACGT | 95 |
| moeGT5EcoRIrp | AAAGAATTCGGTGACCTCGTGTGTCAGC | 96 |
| moeGT2XbaIup | AAATCTAGAAGGGCCTGCACTTCACCT | 97 |
| moeGT2EcoRIrp | AAAGAATTCGCCGTCCGGATCGACCA | 98 |
| moeK5XbaIup | AAATCTAGATCCAGCGTGTTGCGC | 99 |
| moeK5EcoRIrp | AAAGAATTCACGAGACATCAGCCG | 100 |
| moeO5HinDIIIup | AAAAAGCTTCGGGGCGTGCCTTCTTC | 101 |
| moeO5XbaIrp | AAATCTAGACCGCCCGCTCCCCGGAC | 102 |
| moe2HindIII-up | AAAAAGCTTGACGTGAGGCCGTGCAGTTC | 103 |
| moe2MfeI-rp | AAACAATTGGCACATCTTGACGTGGACGG | 104 |
The plasmid and cosmid libraries for S. ghanaensis ATCC14672 genome sequencing were created at Broad Institute (Cambridge, Mass.). The cosmid library used for the retrieval of moe clusters 1 and 2 was constructed using the SuperCosI Vector system (Stratagene, La Jolla, Calif.) according to manufacturer's instructions. Sequencing of cosmids moeno5, 38, 40 and their subclones was done at Biopolymers Facility of Harvard Medical School using standard (M13, T4, T7, T3) and custom designed primers.
D. DNA and Protein Sequence Analysis
The generation, assembly and analysis of S. ghanaensis genomic sequences will be described separately. Briefly, the draft assembly yielded 1018 contigs containing 7.4 Mbp of S. ghanaensis genome (at 6.6× coverage) and about 1.2 Mbp are estimated to lie in the gap. BLAST search tools (on the server of the National Center for Biotechnology Information, Bethesda, Md.), FramePlot2.3.2 (Ishikawa 1999), CUPplot1.0 and Lasergene software package were used for S. ghanaensis sequences assembly, analysis and annotation. Homologues of moe gene translation products were found through BLASTP. Pair-wise amino acid sequence alignment was performed using the sequence analysis program on the server of European Bioinformatics Institute (Cambridge, UK). CDD search engine (BLAST server) and a set of programs (HHPred, Pfam, TMHHM) on ExPaSy proteomics server were utilized for identification of topology and conserved domains of the moe proteins.
E. Identification and Cloning of Moe Gene Clusters 1 and 2
Using BLASTX, all contigs provided by the Broad Institute were scanned in silico for the presence of clustered genes for glycosyltransferases, sugar tailoring genes and genes involved in isoprene metabolism. Seventy contigs containing at least some of the expected genes were then analyzed in more details using FramePlot and BLASTP programs. One stand-alone contig, contig 908, and three adjacent contigs 71, 72, 73 were identified as most likely carrying all or most of the genes involved in moe biosynthesis. On the basis of contig 908, sequence primers ligup1HindIII and ligrp1EcoRI were designed to amplify 1039 base-pair internal fragment of the moe A4 gene (which spans the moe A4 coding region from amino acid 160 to 506) from the S. ghanaensis ATCC14672 genome. Primers GTcon72for and GTcon72rev (designed base on the contig 72 sequence) were used to clone a 424 base-pair internal fragment of the moeGT1 gene (amino acids 164-305). A 489 base-pair fragment of the moeGT3 gene (amino acids 228-390) was amplified with primers GT2con73up and GT2con73rp (designed based on contig 73 sequence). DIG-labeled fragments of the moeA4, moeGT1, and moeGT3 genes were used to probe a S. ghanaensis cosmid library. Positive cosmids moeno38 and moeno40 were found to carry overlapping segments of S. ghanaensis genome that cover contigs 71, 72, 73. Cosmid moeno5 was found to cover contig 908. The aforementioned cosmids were used to finish sequencing moe clusters 1 and 2 (e.g., fill gaps of poor sequence resolution). One cosmid, moeno5, carried 3 moe biosynthetic genes, moe A4, moeB4, and moeC4 (moe cluster 2); the other two cosmids carried the rest of the identified moe genes (moe cluster 1). (See, e.g., FIGS. 3A-3B).
F. DNA Introduction into E. coli and Streptomyces Strains
Introduction of plasmids and cosmid library sequences into E. coli was done as described in Sambrook 1989. A slightly modified procedure of Streptomyces-E. coli conjugation (Kieser 2000) was employed to introduce plasmids into S. ghanaensis strains. Particularly, heat shocked ungerminated spores were used for matings, and conjugation mixtures were overlaid with selective antibiotics after 10 hours of growth. Conjugations with S. ghanaensis disruption mutants, aimed at obtaining complemented strains, were performed at 37° C. and overlaid after 7-8 hours of growth to avoid the excision of disruption plasmid from the mutated moe gene. The average frequency of appearance of S. ghanaensis pKC1139+ transconjugants was 6.6×10−5. Plasmid pSET152 was transferred into S. ghanaensis ATCC14672 at frequency 1.0×10−3. There was one attBφC31 site in the S. ghanaensis chromosome (as judged from Southern analysis of the transconjugants, see e.g., FIGS. 5A-5B). Also, free copies of pSET152 exist in S. ghanaensis cells as evident from Southern analysis and plasmid DNA analysis of Amr clones of E. coli obtained after transformation with total DNA of pSET152+ transconjugants. S. ghanaensis pSETIS2+ and pKC1139+ transconjugants did not differ from wild type in their ability to grow, sporulate and produce moe A. The introduction of plasmid and cosmid DNA into S. lividans was carried out according to published procedures described in Kieser 2000.
G. Construction of Plasmids for Moe Gene Disruptions and Expression
Internal fragments of moe A4 and moeGT1 genes used for screening the S. ghanaensis cosmid library were cloned as HindIII-EcoRI fragments into the HindII and EcoRI sites of pKC1139 to yield pKC1139lig3 and pOOB21e, respectively. An EcoRV fragment carrying hygromycin resistance cassette hyg (Kieser 2000) was excised from pHYG1 (Zhu 2005) and inserted into blunt-ended BamHI site of pKC1139lig3. In this way plasmid pLH1 was generated with internal moe A4 fragment being divided into two “arms” of 1 and 0.1 kb in length.
A 462 base pair internal fragment of moeM5 gene (corresponding to amino acid region 214-356 of the moeM5 protein) was amplified from cosmid moeno38 with primers CTcon73for and CTcon73rev. The PCR product was then digested with HindIII and EcoRI and cloned into the corresponding sites of conjugative E. coli-Streptomyces vector pKC1139 to yield plasmid pOOB20a. E. coli ET12567 (pUB307) was transformed with pOOB20a and the resulting strain was used as a donor in E. coli ET12567 (pUB307, pOOB20a)—S. ghanaensis ATCC14672 intergeneric conjugation. In this way, plasmid pOOB20a was transferred into S. ghanaensis. Under permissive conditions (growth at 30° C.) pKC1139-based plasmids replicate in Streptomyces hosts, but at temperatures higher then 34° C., these plasmids are either eliminated from the cells or forced to integrate into host's genome via homologous recombination (Muth 1989).
A 5 kb EcoRI fragment carrying 3′-truncated moeC4 gene and entire moeB4 genes was retrieved from cosmid moeno5 and cloned into EcoRI site of pOOB5 resulting in pKC11395-8 plasmid.
Gene moeGT1 along with its putative ribosome binding site (“RBS”) was amplified from cosmid moeno38 with primers moeGT1XbaIup and moeGT1EcoRIrp, treated with XbaI and EcoRI and cloned into XbaI-EcoRI digested pMKI9 in order to fuse moeGT1 with ermE promoter. From this intermediate construct (named pOOB32) PermE-moeGT1 was excised as a HindIII-EcoRI fragment, treated with T4 DNA polymerase and cloned into EcoRV site of pOOB40 to give pOOB41c.
Gene moeM5 along with its RBS was amplified from cosmid moeno38 with primers moeM5nEcoRXbaup and moeM5nEcoRIrp. The final pOOB40-based construct pOOB43a carrying PermE-moeM5 was generated in a two-step manner, similar to the construction of pOOB41c.
Genes moeD5 and J5 along with their putative promoter region were cloned from cosmid moeno38 with primers con71end and con72start, treated with XbaI and EcoRI and inserted into pMKI9 to yield pOOB38.
Additionally, gene moeM5 along with its ribosomal binding site was amplified from cosmid moeno38 with primers moeM5nEcoRXbaup and moeM5nEcoRIrp, treated with XbaI and EcoRI and cloned into XbaI-EcoRI digested pMKI9 (pKC1139 derivative with strong constitutive Streptomyces ermE promoter) in order to fuse moeM5 with ermE promoter. From this intermediate construct (named pOOB42) PermE-moeM5 was excised as a HindIII-EcoRI fragment, treated with T4 DNA polymerase and cloned into EcoRV site of pOOB40 (actinophage φC31-base integrative E. coli-Streptomyces vector) to give pOOB43a. This plasmid was introduced into S. ghanaensis OB20a strain for pOOB20a introduction into S. ghanaensis ATCC14672. The introduction of an intact copy of the moeM5 gene into S. ghanaensis OB20a strain was performed to demonstrate the restoration of moe A production in the mutant.
Genes moeF5, moeH5, moeGT4, moeGT5, moeGT2, moeGT3, moeN5, moeK5 were amplified via PCR using cosmid moeno38-1 as a template and respective primers listed in Table 4. Restriction sites for endonucleases XbaI and EcoRI were engineered into the primers to facilitate the cloning of the moe genes into XbaI-EcoRI digested vector pMKI9. The following plasmids were constructed: pOOB48a (moeF5), pOOB51 (moeH5), pOOB50 (moeGT4), pOOB52 (moeGT5), pOOB56c (moeGT2), pMOl13 (moeGT3), pMO17 (moeN5), pKC1139EmoeK5 (moeK5). Genes moeO5moeN5 plus moeO5-moeX5 intergenic region were amplified using primers moeO5HindIII and moeN5EcoRI. The amplicon was digested with restriction endonucleases HindIII and EcoRI and cloned into respective sites of pSOK804 yielding pOOB63a. Gene moeO5 was amplified with primers moeO5HindIII and moeO5XbaIrp and cloned into HindIII-XbaI-digested vector pAF1 to give pMoeO5extra. Plasmids pOOB63a and pMoeO5extra were used for complementation of ΔmoeN5 strain. Genes moeA4moeB4moeC4 (moe cluster 2) were amplified with primers moe2HindIII and moe2MfeI. The resulting PCR product was treated with HindIII and MfeI and cloned into HindIII-EcoRI digested pSOK804 thus giving pOOB64b. A 1.5 kb HindIII-EcoRI fragment containing moeGT3 fused to PermE was excised from pMO13, treated with Klenow enzyme and cloned into EcoRV site of pOOB40 (Hy) to give pMO14. This plasmid was used to complement moeGT3-deficient S. ghanaensis MO12 strain and to construct plasmid pOOB58 (see next chapter). Gene moeB4 has been subcloned from pOOB12 (Ostash 2007) as a XbaI-EcoRI fragment into respective sites of pMKI9, giving pOOB46e. This plasmid was coexpressed with various moeno38-1 derivatives to study the chromophore (unit A) biosynthesis. The fragment of moe cluster 1 containing moeR5moeS5 genes and putative moeS5 promoter (PmoeS5) was amplified with primers moeGT3intMfeI and orf1intXbaI, treated with MfeI and XbaI and cloned into XbaI-EcoRI digested pMKI9 to yield pOOB49f. PmoeS5-moeS5 fragment was retrieved from pOOB49f via XbaI-EcoRI digestion and cloned into pMKI9 to give pOOB55. Gene moeR5 was amplified from moeno38-1 with primers moeR5XbaIup and moeGT3intMfeI and cloned into XbaI-EcoRI digested pMKI9 to yield pOOB59. Plasmids pOOB49f, pOOB55, pOOB59 were coexpressed with the rest of moe cluster 1 to study the roles of moeR5 and moeS5 in moe A biosynthesis.
The internal fragment of moeGT3 was amplified with primers GT2con73up and GT2con73rp, digested with HindIII and EcoRI and cloned into respective sites of pKC1139. The resulting plasmid was named pMO12 and used to insertionally inactivate moeGT3 gene within S. ghanaensis ATCC14672 chromosome following the described protocol (Ostash 2007).
There is unique XhoI site in plasmid pMO14 located 205 bp downstream of moeGT3 start codon. Plasmid pMO14 was digested with XhoI, treated with Klenow fragment and ligated to spectinomycin resistance gene aadA (retrieved as DraI fragment from pHP45). The resulting plasmid pOOB58 was used as a source of 3.3 kb XbaI-EcoRI linear moeGT3::aadA fragment to replace the intact moeGT3 in cosmid moeno38-91 (derivative of moeno38-1 with deleted moeGT5; see below) via A-RED approach.
H. Generation of S. ghanaenss and S. lividans Disruption Mutants and their Analysis
The same procedure was applied for all four gene knockouts described below in Section III (moeM5, moe A4, moeGT1 and moeGT3; see e.g., FIG. 6 for an exemplary schematic). Strains carrying pKC1139-based disruption plasmids in replicative form were grown for 3 days in TSB at 30° C. (e.g., strain S. ghanaensis carrying moeM5 disruption plasmid pOOB20a in replicative form). The biomass was then washed three times with water to remove apramycin used for plasmid selection, and approximately 105 colony forming units (“cfu”) were inoculated into fresh TSB (25 mL) without antibiotic. The culture was incubated for 6 days at 40° C. (to eliminate free plasmid), plated onto YMA supplemented with apramycin and grown for 4-5 days at 37° C.
In this way colonies with disruption plasmids integrated into genes of interest—via recombination between regions of homology in the chromosome (full copy of gene of interest) and on the plasmid (the internal fragment of the gene)—were obtained. This integration disrupted the coding region of the gene, leading to deficient strains of S. ghanaensis.
Ten independent colonies for each gene disruption experiment were assayed for moe A production, and in no case was the moe A+ phenotype detected due to possible non-specific integration of plasmid into S. ghanaensis genome. Additionally, the reversions to moe A+ phenotype was not detected when the strains were grown in presence of apramycin at 37° C. indicating that under the stated conditions the insertional inactivation mutants are stable. Passage of wild-type strains under cultivation conditions used to generate moe mutants did not negatively affect moe A production.
The site-specific integration of the disruption sequences was also confirmed by Southern analysis. For moeM5 confirmation, a moeM5 fragment (either radioactively or non-radioactively labeled) was used as a probe. A 2.8 kb XhoI fragment of wild-type digest hybridized with the moeM5 probe, whereas there were two different hybridizing bands in case of moeM5 mutant total DNA XhoI digest. This corresponded to integration of pOOB20a plasmid into the moeM5 gene and introduction of an additional XhoI site into this chromosomal region (See FIGS. 9A-9B).
For moe A4 plasmid pLH1 in S. ghanaensis LH1 strain was confirmed by Southern analysis using DIG-labeled moe A internal fragment as a probe. In wild-type strains, the moe A4 gene resides in a 10 kb BamHI fragment, whereas in the LH strain, the corresponding hybridizing band is absent and a new 19 kb band was present. The latter corresponded to integration of 9 kb pLH1 plasmid into 10 kb BamHI moe A-containing fragment of S. ghanaensis chromosome.
Likewise the integration of the 7 kb moeGT1 disruption plasmid pOOB21e into 10 kb moeGT1-containing BamHI fragment of S. ghanaensis genome was demonstrated (See FIGS. 10A-10B). For moeGT3 disruption, the plasmid pm012 was transferred into S. ghanaensis via conjugation and homologous integration. The integration was verified by Southern analysis.
Derivatives of moeno38-1 carrying the deletions of moe genes were generated via λ-RED approach. The following procedure was used for all λ-RED-assisted deletions of moe genes within cosmid moeno38-1 (except for moeGT3). Briefly, the entire open reading frame(s) was replaced with kanamycin resistance cassette (pKD4). Then the mutated cosmid was introduced into strain DH5a (pCP20) to evict kanR as described (Datsenko 2000). The presence of expected deletions within the cosmids was checked by PCR. λ-RED recombination was used to replace moeGT3 with disrupted allele moeGT3::aadA in ΔmoeGT5 derivative of moeno38-1.
For moeno38-5 (deletion of moeA5moeB5 genes), the kanamycin resistance gene from plasmid pKD4 was amplified with primers 38start-KD4 and moeA4-P3. The resulting amplicon was used to replace moeA4moeB5 gene pair as well as the entire nonessential “left arm” of moeno38-1 (FIGS. 3A-3B). Our previous studies showed that deletion of this arm did not alter moe A production (data not shown). We did not evict kanR gene region from moeno38-5 because it did not exert any negative effects on moe A production. The replacement of moeA5moeB5 genes with kanR in moeno38-5 was confirmed via diagnostic PCR (primers P2-KD4 and alsrev1).
For moeno38-91 (deletion of moeGT5 gene), gene kanR was amplified with primers moeGT5up-P1 and moeGT5rp-P2. This amplicon was used to replace moeGT5 gene. The resulting cosmid moeno38-9 was introduced into E. coli DH5a (pCP20) to excise the kanR in FLP-mediated reaction (Datsenko 2000). The cosmid carrying 81 bp “scar” sequence instead of moeGT5 was named moeno38-91. Deletion of moeGT5 in moeno38-91 was confirmed via PCR (primers moeGT5XbaIup and moeGT5EcoRIrp).
For moeno38-31 (deletion of moeGT4), the cosmid moeno38-31 was constructed in the same way moeno38-91 was. The deletion of moeGT4 was checked by PCR (primers moeGT4XbaIup and moeGT4EcoRIrp).
For moeno38-81 (deletion of moeGT2), the cosmid moeno38-81 was constructed in the same way moeno38-91 was. Deletion of moeGT2 was confirmed via PCR (primers moeGT2XbaIup and moeGT2EcoRIrp).
For moeno38-911 (deletion of moeGT5 and disruption of moeGT3), a 3 kb XbaI-EcoRI fragment containing moeGT3::aadA allele was retrieved from pOOB58 and used to replace moeGT3 in cosmid moeno38-91. The replacement of moeGT3 with moeGT3::aadA in moeno38-911 was verified by PCR (primers moeGT3XbaIup and moeGT3EcoRIrp).
For moeno38-41 (deletion of moeF5), the cosmid moeno38-41 was constructed in the same way moeno38-91 was. The deletion of moeF5 was checked by PCR (primers moeF5check-up and moeF5check-rp).
For moeno38-61 (deletion of moeH5), the cosmid moeno38-61 was constructed in the same way moeno38-91 was. The deletion of moeH5 was checked by PCR (primers moeH5XbaIup and moeH5EcoRIrp).
For moeno38-21 (deletion of moeK5), the cosmid moeno38-21 was constructed in the same way moeno38-91 was. The deletion of moeK5 was checked by PCR (primers moeK5XbaIup and moeK5EcoRIrp).
For moeno38-7 (deletion of moeN5), the gene moeN5 was replaced with the kanR cassette as described above for moeno38-5 construction. We did not excise the kanR cassette from moeno38-7 because it did not exert any polar effects on moe A production.
Gene moeGT3 was insertionally inactivated in S. ghanaensis genome according to established procedure (Ostash 2007). All constructs carrying moe genes were transferred into S. lividans via intergeneric conjugation. Plasmids pUJ584 and pMoeO5extra were introduced via protoplast transformation. Integration of moeno38-1 and its derivatives into S. lividans genome was checked as described in Ostash 2007.
I. Chemicals
Organic solvents, salts, sugars, ITPG, X-Gal and antibiotics were purchased from standard commercial suppliers. The purified samples of moe A have been kindly provided by J. Taylor and S. Fuse (Dept. of Chemistry and Chemical Biology, Harvard University). For recombinant strains selection following commercially available antibiotics were used (mg/mL): ampicillin (100), chloramphenicol (35), kanamycin (50), apramycin (50), hygromycin (100), spectinomycin (200), streptomycin (100), thiostrepton (50), nalidixic acid (50).
J. Moe Production and Resistance Analysis
1. Moe Production in S. ghanaensis
For all moe production analysis procedures, equal amounts of biomass (wet weight) and fermentation medium were used. For moes production, S. ghanaensis strains with disrupted moe genes were grown at 37° C. for 4-5 days in mTSB and for 10 days in LM. For antibiotic disc diffusion assays, fermentation medium and concentrated methanol extracts of moe A from mycelium of S. ghanaensis strains were applied to antibiotic assay discs (diam. 10 mm, Sigma, St. Louis, Mo.) and stacked onto LA plates overlaid with soft agar containing B. cereus. Semipurified samples of moe A and its derivatives were obtained by methanol extraction of mycelium of S. ghanaensis strains and further C18 solid phase extraction as described in (Eichhorn 2005) and then used for LC-MS analysis (Eichhorn 2005) and biochromatography. For the latter, dried silica gel aluminum TLC plate (mobile phase—methanol:acetonitrile:water 40:40:20) with separated moes were overlaid with soft agar containing B. cereus, incubated overnight at 30° C. and then visualized with UV light (254 nm).
For moeM5, S. ghanaensis OB20a was incubated in TSB medium supplemented with apramycin (to select for pOOB20a integration in moeM5) for 4 days at 37° C. and the moes were extracted from mycelium with methanol. The methanol extract was evaporated, and dry residue was dissolved in water and analyzed as noted above, by antibiotic disc diffusion assay, biochromatography and LC-MS.
2. Moe Production in lividans
Heterologous expression of moe biosynthetic genes in S. lividans TK24 leads to the production of moe derivatives and intermediates. Small-scale fermentation and purification of moenomycins was performed according to Ostash 2007. To obtain pure (>90 as judged by TLC) moenomycin intermediates from recombinant S. lividans strains, the following procedure was used. TSB medium (30 mL in 250 mL flask containing 70 glass beads (Ø 5 mm)) was inoculated with 100 μL (approx. 104-105 cfu) of stock culture (kept in 10.3% sucrose at −20° C.). The flask was incubated on orbital shaker (240 rpm) for 2 days at 37° C. and then used as a preculture to start the fermentation. R5 medium (Kieser 2000) in a slightly modified form (sucrose: 6% instead of 10.3%; 1 mg/L CoCl2 was added after autoclaving) was used as a fermentation medium. 8 4 L flasks (500 mL of medium per each one) containing beads were grown for 6 days at 37° C. The mycelium was harvested by centrifugation and extracted exhaustively with methanol-water (9:1) at 37° C. (when necessary, the pH of extraction mixture was adjusted to 7-7.5 with Tris-HCl). The extract was concentrated in rotovapor, reconstituted in water and extracted with dichloromethane. Aqueous phase was loaded on XAD-16 column (30×400 mm), washed with water (300 mL) and eluted with methanol (500 mL). Methanol fractions containing the desired compound were combined, concentrated and purified on Sep-Pak C18 SPE cartridge (Waters) as described (Eihchorn 2005). Further silica gel flash chromatography or preparative TLC of the obtained extract according to (Adachi 2006) yielded pure compound 0.1-0.4 mg/4 L, depending on strain. Antibiotic disc diffusion assay, LC-MS, MS/MS and determination of accurate mass spectra of moenomycins were carried out as described in (Ostash 2007). 1H NMR spectra of compound 11 (FIGS. 4A-4D) were recorded on a Varian Inova 500 (500 MHz) instrument in D2O (4.80 ppm). Chemical shifts are reported in parts per million (ppm) units.
100 μL (approx. 2×106 cfu) of 48 hour liquid cultures of Streptomyces strains were mixed with 4 mL of soft agar and spread on YMA plates. Then 5 mm antibiotic assay discs with different amounts of moe A were placed on top of soft agar. The moe A growth inhibition was monitored after 12, 24, 48, 72 and 96 hours of cultivation at 30° C.
II. Cloning of Moe Biosynthetic Genes from S. ghanaeasis ATCC14672
“Reverse genetics” strategies (Weber 2003) became popular for identification of antibiotic biosynthesis gene clusters which share conserved motifs such as the polyketide synthase or nonribosomal peptide synthase genes. Moe A, too, contains structural elements for which dedicated biosynthetic enzyme activity may be ascribed (See e.g., FIG. 7). Using degenerate primers homologous to conserved regions of aforementioned genes (Decker 1996, Rascher 2003, Kawasaki 2003), a set of DNA fragments encoding candidate moe genes was amplified. However, disruption of these cloned genes in the S. ghanaensis genome showed that none of them is involved in moe production.
As PCR-based approaches did not lead to moe biosynthetic genes, an in silico, whole-genome scanning strategy was used. The genome of S. ghanaensis ATCC14672 (approximately 8.6Mbp) was shot-gun sequenced to 6.6× coverage and partially assembled yielding 1018 contigs ranging from 1 to 95 Kbp in size. (this phase of the investigation was performed in collaboration with Broad Institute; see the trace sequences at “Traces” on the NCBI website). The structure of moe A suggests that clustered glycosyltransferase, sugar production and prenyltransferase genes as well as unknown genes for chromophore and phosphoglycerate unit incorporation would be identified (FIG. 7). Using BLASTX, all contigs provided by Broad Institute were scanned in silico for the presence of such genes and gene clusters. 70 contigs containing at least some of the expected genes were then analyzed in more detail using FramePlot and BLASTP programs. One stand-alone contig, 908, and three adjacent contigs, 71, 72 and 73 were identified as those most probably carrying all or most of the genes required for moe biosynthesis. These contigs were assigned to two different chromosomal locations or clusters (cluster 1 and cluster 2).
On the basis of the contig 908 sequence, primers ligup1HindIII and ligrp1EcoRI were designed to amplify 1039 bp internal fragment of the moe A4 gene (which spans moe A4 coding region from 160aa to 506aa) from S. ghanaensis ATCC14672 genome. Primers GTcon72for and GTcon72rev (designed on the basis of contig 72 sequence) were used to clone a 424 bp internal fragment of moeGT1 gene (164-305aa). A 489 bp fragment of moeGT3 gene (228-390aa) was amplified with primers GT2con73up and GT2con73rp (designed on basis of contig 73 sequence). For primer sequences, see Table 5. DIG-labeled fragments of moe A4, moeGT1, moeGT3 genes were used to probe a S. ghanaensis cosmid library. Positive cosmids moeno38 and moeno40 were found to carry overlapping segments of the S. ghanaensis genome that covered contigs 71, 72, 73; cosmid moeno5 was found to cover contig 908. One cosmid, moeno5, carried 3 moe biosynthetic genes, moe A4, moeB4, and moeC4 (moe cluster 2); the other two cosmids carried the rest of the moe genes (moe cluster 1), see FIGS. 3A-3B.
In total, 43 Kb of the S. ghanaensis chromosome has been sequenced, and 30 open reading frames have been identified. The sequences of cluster 1 and cluster 2 are shown in Table 1 and Table 2, respectively. The open reading frames were found to contain the typical (for Streptomyces) GC bias in the third codon position of around 90%, and typical codon usage. On the basis of homology searches and functional analysis (see Bioinformatics and Genetic Analysis, Part III, below) 23 of the open reading frames were identified as likely to participate in moe biosynthesis (see Table 4 for predicted function).
III. Bioinformatics and Genetic Analysis
The function of each gene and the role it is likely to play in moe synthesis was determined based on both bioinformatics study and genetic analysis. An NCBI Database BLAST search of the protein sequence was performed. The closest homologue alignment, as determined by this search, is presented in the Tables associated with each open reading frame. In the alignment tables, “QUERY” indicates the moe protein sequence and “SUBJECT” indicates the homologue protein sequence. SeQ ID NOS corresponding to each contiguous stretch of amino acids are indicated in the table of above the respective sequence. The genes identified as likely to be material to moe biosyntheses are described below in seven groups (A-G) based on their function: (A) genes for 2-amino-3-hydroxycyclopent-2-enone moiety (CsN unit) biosynthesis and attachment to pentasaccharide moiety of Moe A; (B) glycosyltransferase genes; (C) sugar tailoring genes; (D) genes for phosphoglycerate-lipid moiety biosynthesis; (E) transport genes; (F) genes flanking moe clusters 1 and 2; (G) regulatory genes.
We also used a genetic approach to decipher the moe A biosynthetic pathway. The major moe cluster 1 minus the moeR5moeS5 genes is located on the hygromycin resistant cosmid moeno38-1 (FIG. 3), which directs the production of precursor 19 in S. lividans TK24 (FIGS. 4A-4D) (Ostash 2007). We also constructed a set of moeno38-1 derivatives carrying λ-Red-induced deletions (Datsenko 2000, Gust 2003) of individual moe genes; one double mutant cosmid (ΔmoeGT5ΔmoeGT3) was also created. Gene moeGT3 was disrupted in the moe A producer S. ghanaensis ATCC14672 (strain MO12) as well. Genes moeR5moeS5 are located within the pKCl 139-based plasmid pOOB49f (FIG. 2). Plasmid pOOB64b (based on vector pSOK804 (Sekurova 2004) carries moe cluster 2, an apramycin resistance marker and an actinophage VWB attP-int fragment. Derivatives of moeno38-1 were integrated into the S. lividans attPφC31 site and then certain strains were further supplemented with either pOOB49f or pOOB64b, or their truncated versions. The mutations in individual moe genes were complemented with exact copies of the genes, thus ruling out any polar effects. All recombinant S. lividans strains were analyzed following purification by a set of spectroscopic methods and bioassays, which guided our prediction of the structures of moe A derivatives. We abbreviate the names of recombinant S. lividans strains. For example, S. lividans strain carrying moeno38-1 derivative with deleted moeF5 is referred to as ΔmoeF5; expression of moeR5 in ΔmoeH5 strain is marked as moeR5+ΔmoeH5; strains carrying the parental cosmid moeno38-1 are marked as 38-1+ strains.
A. Genes for 2-Amino-3-Hydroxycyclopent-2-Enone Moiety (C5N Unit) Biosynthesis and Attachment to Pentasaccharide Moiety of Moe A
Five different genes were identified that fit this functional category; two in cluster 1 (moe A5 and moeB5) and 3 in cluster 2 (moe A4, moeB4 and moeC4). Both moe clusters 1 and 2 carry a copy of putative aminolevulinate synthase gene (moeC4 and moeA5; FIGS. 3A-3B), which is proposed to direct the production of 5-aminolevulinic acid, the putative precursor to the proposed aminocyclopentadione A ring (Ostash 2007).
1. moe A5 (Cluster 1)
The biosynthetic studies led by Floss, Welzel and Felsberg showed that 5-aminolevulinic acid (5-ALA) is a linear precursor of the C5N chromophore (Nakagawa 1985, Schuricht 2000, Petricek 2006). In moe cluster 1, the moeA5 gene, which displays end-to-end homology to known and putative 5-ALA synthases from various bacteria, was identified. The nucleotide and polypeptide sequences are shown in Tables 6 and 7, respectively.
| TABLE 6 |
| DNA Sequence of moeA5. |
| ATGGACTTCTTCGTGCGACTCGCCCGCGAAACCGGTGACCGGAAGAGGGA |
| GTTTCTCGAACTCGGCCGCAAGGCGGGTCGGTTCCCCGCGGCGAGCACCT |
| CGAATGGCGAGATTTCCATCTGGTGCAGCAACGACTACCTGGGTATGGGG |
| CAGCACCCGGACGTCCTCGACGCCATGAAGCGCTCCGTGGACGAATACGG |
| CGGAGGATCCGGGGGTTCGCGGAACACAGGCGGAACCAACCACTTCCATG |
| TGGCTCTGGAGCGGGAGCCGGCCGAGCCGCACGGAAAGGAGGACGCCGTT |
| CTCTTCACCTCGGGGTATTCCGCCAATGAGGGATCCCTGTCGGTTCTGGC |
| CGGGGCCGTCGACGACTGCCAGGTCTTCTCGGATTCGGCGAACCACGCGT |
| CCATCATCGACGGTTTACGGCACAGCGGCGCCCGCAAGCACGTATTCCGG |
| CACAAGGACGGGCGGCATCTGGAGGAGTTGCTGGCCGCGGCCGACCGGGA |
| CAAGCCGAAGTTCATCGCCCTGGAGTCCGTGCATTCGATGCGGGGCGACA |
| TCGCGCTCCTGGCCGAGATCGCCGGCCTGGCCAAGCGGTACGGAGCGGTC |
| ACCTTCCTCGACGAGGTGCACGCGGTCGGCATGTACGGCCCGGGCGGAGC |
| GGGCATCGCGGCCCGGGACGGCGTGCACTGCGAGTTCACGGTGGTGATGG |
| GGACCCTCGCCAAGGCCTTCGGCATGACCGGCGGCTACGTGGCGGGACCG |
| GCCGTGCTCATGGACGCGGTGCGCGCCCGGGCCCGTTCCTTCGTCTTCAC |
| CACGGCGCTGCCGCCGGCGGTCGCGGCGGGCGCGCTCGCCGCGGTGCGGC |
| ACCTGCGCGGCTCGGACGAGGAGCGGCGGCGGCCGGCGGAGAACGCGCGG |
| CTGACGCACGGCCTGCTCCGCGAGCGGGACATCCCCGTGCTGTCGGACCG |
| GTCCCCCATCGTCCCGGTGCTGGTCGGCGAGGACCGGATGTGCAAGCGCA |
| TGTCGGCCCTGCCGCTGGAGCGGCACGGCGCGTACGTCCAGGCCATCGAC |
| GCGCCCAGCGTCCCGGCCGGCGAGGAGATCCTGCGGATCGCGCCCTCGGC |
| GGTGCACGAGACCGAGGAGATCCACCGGTTCGTGGACGCCCTGGACGGCA |
| TCTGGTCCGAACTGGGGGCCGCCCGGCGCGTCTGA (SEQ ID NO: 3) |
| TABLE 7 |
| Amino Acid Sequence of moeA5 |
| MDFFVRLARETGDRKREFLELGRKAGRFPAASTSNGEISIWCSNDYLGMG |
| QHPDVLDAMKRSVDEYGGGSGGSRNTGGTNHFHVALEREPAEPHGKEDAV |
| LFTSGYSANEGSLSVLAGAVDDCQVFSDSANHASIIDGLRHSGARKHVFR |
| HKDGRHLEELLAAADRDKPKFIALESVHSMRGDIALLAEIAGLAKRYGAV |
| TFLDEVHAVGMYGPGGAGIAARDGVHCEFTVVMGTLAKAFGMTGGYVAGP |
| AVLMDAVRARARSFVFTTALPPAVAAGALAAVRHLRGSDEERRRPAENAR |
| LTHGLLRERDIPVLSDRSPIVPVLVGEDRMCKRMSALPLERHGAYVQAID |
| APSVPAGEEILRIAPSAVHETEEIHRFVDALDGIWSELGAARRV |
| (SEQ ID NO: 26) |
Two of the closest moe A5 homologues are found in streptomycetes-producers of the C5N-containing antibiotics asukamycin and ECO-02301 (64% identity and 78% similarity) (Petricek 2006, McAlpine 2005). The sequence alignment is shown in Table 8. No moe A5-like genes were identified in the completely sequenced S. coelicolor and S. avermitilis genomes, suggesting that in Streptomyces, 5-ALA synthases control 5-ALA supply strictly for C5N anabolism.
| TABLE 8 |
| Sequence Homology of moeA5 |
| gi|37932054|gb|AAO62615.1| aminolevulinate synthase [Streptomyces nodosus |
| subsp. asukaensis] |
| Length = 409 |
| Score = 460 bits (1183), Expect = 3e−127 |
| Identities = 258/398 (64%), Positives = 313/398 (78%), Gaps = 6/398 (1%) |
| Frame = +3 |
| SEQ ID NO: 107 SEQ ID NO: 108 | |||
| Query | 375 | ISSSMDFFVRLARETGDRKREFLELGRKAGRFPAASTSNG------EISIWCSNDYLGMG | 536 |
| ++ +||| | | | |+|||||+||+|||||+| | |||+|||||||||| | |||
| Sbjct | 1 | MNKHLDFFAREMEEFGARRREFLEIGRRAGRFPSAVARQGQDGTDVEISVWCSNDYLGMG | 60 |
| SEQ ID NO: 109 | |||
| Query | 537 | QHPDVLDAMKRSVDEYgggsggsrntggtnHFHVALEREPAEPHGKEDAVLFTSGYSANE | 716 |
| |+| ||+|+| +|| +| ||||||| |||||+|| || | | ||||+|++| ||++||+ | |||
| Sbjct | 61 | QNPFVLEAVKNAVDAFGAGSGGSRNIGGTNHYHVLLENELAALHGKEEALIFPSGFTAND | 120 |
| Query | 717 | GSLSVLAGAVDDCQVFSDSANHASIIDGLRHSGARKHVFRHKDGRHLEELLAAADRDKPK | 896 |
| |+|+|||| ||| |||||||||||||| | +||| | |||||||||| ++|| | |||
| Sbjct | 121 | GALTVLAGRAPGTLVFSDELNHASIIDGLRHSGAEKRIFRHNDMAHLEELLAAADPERPK | 180 |
| Query | 897 | FIALESVHSMRGDIALLAEIAGLAKRYGAVTFLDEVHAVGMYGPGGAGIAARDGVHCEFT | 1076 |
| | ||||+|| |||| ||| | ||+|+|| ||+||||||||||| |||||||+|+ ||| | |||
| Sbjct | 181 | LIVLESVYSMSGDIAPLAETAALARRHGATTFIDEVHAVGMYGPQGAGIAAREGIADEFT | 240 |
| Query | 1077 | VVMGTLAKAFGMTGGYVAGPAVLMDAVRARARSFVFTTalppavaagalaavRHLRGSDE | 1256 |
| |||||||| || |||+|||| |+|||| +| |+ |+|||++||| ||||||||+||| |+ | |||
| Sbjct | 241 | VVMGTLAKGFGTAGGYIAGPAALIDAVRNFSRGFIFTTSIPPATAAGALAAVQHLRASEG | 300 |
| Query | 1257 | ERRRPAENARLTHGLLRERDIPVLSDRSPIVPVLVGEDRMCKRMSALPLERHGAYVQAID | 1436 |
| || | | || | | ||+||||| +||+| || | ||+| +|++ ||| ||||| ||| |+ | |||
| Sbjct | 301 | ERTRLAANAGLLHRLLKERDIPFVSDQSHIVSVFVGDDGLCRQASALLLERHGIYVQPIN | 360 |
| Query | 1437 | APSVPAGEEILRIAPSAVHETEEIHRFVDALDGIWSEL | 1550 |
| |||| |||||||+|||| | | ++ +| +|++||| +| | |||
| Sbjct | 361 | APSVRAGEEILRVAPSATHTTGDVEKFAEAVEGIWRDL | 398 |
Coexpression of different truncated variants of moe clusters 1 and 2 has revealed that moeA5 is nonfunctional and that the moe cluster 2 genes are sufficient to convert the precursor 19 into pholipomycin 21 (FIGS. 4A-4D). To probe whether unit A (FIG. 1) originates from 5-aminolevulinate produced by moeC4, as suggested, we fed 5-aminolevulinate to the moeB4+moeA4+ 38-1+ strain. Pholipomycin was not detected in cell extracts in our assay (data not shown). It was reported recently that similar supplementation of mutant asukamycin producers with aminolevulinate failed to yield unit A-tailored antibiotics (Petricek 2006). Perhaps 5-aminolevulinate is not the precursor for C5N units in secondary metabolites such as asukamycin and moenomycin. In any event, although the genes for unit A biogenesis have been identified, the biochemistry of synthesis and attachment remains obscure.
2. moeB5 (Cluster 1)
The moeB5 gene is located near the moe A5 gene. MoeB5 appears to have homology to the C-terminal portion of an acyl-CoA ligase gene (56% identity and 71% similarity to S. coelicolor homologue SCO6968). However, due to a large deletion of the central portion of the moeB5 gene (relative to a full-length acyl-CoA ligase gene) it is unlikely that moeB5 encodes a functional ligase, even though all the features of open reading frame are present. The nucleotide and polypeptide sequences are shown in Tables 9 and 10, respectively. A sequence alignment between moeB5 and the closest homolog identified in the BLAST search is shown in Table 11.
| TABLE 9 |
| DNA Sequence of moeB5. |
| GTGGGCGGGCCCGGGGGCGACCCTCTCGGCGGCCACGATCCTCTCGGACT |
| CCGCGGGCCGGTGGCCGGAGCGCACCGCGGTGGTCGCGGGCGCCGAGCGG |
| ATCACCTCTGGGGCGTGGAGGTCGCGACAGCCCCGGTCCGAGGCGGAGGA |
| CGCCGTCGGGCCGCTCCCTCCGGCGAGGTGGGCGAGATCGTCGTCCGCGG |
| GCACAACCTGATGGCCGGGTACGTCGACGCCCCCCGCGCCACGGCCGCCG |
| CGTTCGTGGACGGCTGGTTCCGCACCGGCGATCTAGGGCTGCTGGACGAG |
| GAGGGGTACCCCACCGCCGTCGACCGCGAGAAGGACGTGATCCTGCGGGG |
| CGGGTACGACGTCCATCCCCGTGAGGTCGAGGAAGCGCTGCTCCGCCATC |
| CGGCGGTCGCCCGGGTCGCGGTGGTGGGGCTCCCCGACCCGGTGTACGGC |
| CAGGAGGTGTGCGCGGTGGTGGTGCCACGGGACGGCCCGACACCGGAGGG |
| GGCACTGGCGGATTCCGTCGTGGCGTGGGGTGAGCGGCACATCGCGGCGT |
| ACCGGCGTCCGCGGCGGGTGGTCCTCCCCGACCGGCTTCCCCTGGGACCC |
| GGCGGCAAGGTCCTCAAGGGGGAGCCGGCCGTCCGGCTCCGGTCGTCCGA |
| CGAGGCGGGGGCGGCCCGGCCGAGGGGTGACGGCCCCGGCCGGTTCCCCG |
| CCGGCGGGGGCGGCCCGGCCCGGACGAACGCCTCGGAGGCGGTGCGCGCC |
| GCCCGGTCCGTGTCCCCGCCCGGGGCCGGTGTCCGGCGCGCTCAGTCGGT |
| GAGCCCCAGCGTCCCGGCCGCCTGGATCGCCAGCCAGACCTCCGCCAGCG |
| CGCCGGTCGAGGACAGGTCGCGCCGGGAGAGGGCGCCGAAGCGGCGCAGC |
| CGGTAG (SEQ ID NO: 4) |
| TABLE 10 |
| Amino Acid Sequence of moeB5 |
| VGGPGGDPLGGHDPLGLRGPVAGAHRGGRGRRADHLWGVEVATAPVRGGG |
| RRRAAPSGEVGEIVVRGHNLMAGYVDAPRATAAAFVDGWFRTGDLGLLDE |
| EGYPTAVDREKDVILRGGYDVHPREVEEALLRHPAVARVAVVGLPDPVYG |
| QEVCAVVVPRDGPTPDGALADSVVAWGERHIAAYRRPRRVVLPDRLPLGP |
| GGKVLKGEPAVRLRSSDEAGAARPRGDGPGRFPAGGGGPARTNASEAVRA |
| ARSVSPPGAGVRRAQSVSPSVPAAWIASQTSASAPVEDRSRRERAPKRRS |
| R (SEQ ID NO: 27) |
| TABLE 11 |
| Sequence Homology of moeB5 |
| gb|AAX98210.1|acyl CoA ligase [Streptomyces aizunensis] |
| Length = 506 |
| Score = 197 bits (502), Expect = 3e−49 |
| Identities = 98/175 (56%), Positives = 122/175 (69%), Gaps = 0/175 (0%) |
| SEQ ID NO: 110 | |||
| Query | 38 | GVEVATAPVRGGGRRRAAPSGEVGEIVVRGHNLMAGYVDAPRATAAAFVDGWFRTGDLGL | 97 |
| || || | || | |++||||| |||+||||+ |+ || |||||||||+|+ | |||
| Sbjct | 330 | GVRVAIADAELEGRIRLLKQGDIGEIVVSGHNVMAGYLGRPQETAEVLVDGWFRTGDMGV | 389 |
| SEQ ID NO: 111 | |||
| Query | 98 | LDEEGYPTAVDREKDVILRGGYDVHPREVEEALLRHPAVARVAVVGLPDPVYGQEVCAVV | 157 |
| ||+|| + |||+||+|+||||+|+|||||+ ||||||| |||+| +|+||||| | |||
| Sbjct | 390 | QDEDGYLSIVDRKKDMIVRGGYNVYPREVEDVLLRHPAVDGACVVGVPSVKHGEEVCAVV | 449 |
| Query | 158 | VPRDGPTPDGALADSVVAWGERHIAAYRRPRRVVLPDRLPLGPGGKVLKGEPAVR | 212 |
| + | | ||+ +||| |+|||+ |||| + ||| ||||| | | | | |||
| Sbjct | 450 | RVKPGQRASGLLAEEIVAWSRVHMAAYKYPRRVEFVETFPLGSSGKVLKRELAHR | 504 |
Like moe A5, moeB5 was shown to be nonfunctional in the course of heterologous expression of engineered moe cosmids. Thus, the likely lack of function of moeB5, along with the absence of dedicated amide synthase gene for C5N unit transfer to pentasaccharide moiety in moe cluster 1 led to additional in silico searches. In these additional searches, a three-gene operon (named moe cluster 2) similar to that found in genomes of asukamycin and ECO-02301 producers (McAlpine 2005, Petricek 2006) was identified.
3. meeC4 (Cluster 2)
A second 5-ALA synthase encoding gene, moeC4, was identified in the moe cluster 2 (76.7% similarity between translation products of moe A5 and moeC4). The nucleotide and polypeptide sequences are shown in Tables 12 and 13, respectively. A sequence alignment between moeC4 and the closest homolog identified in the BLAST search is shown in Table 14. As described in Section III.A.1 above, moeC4 is involved in the production of 5-aminolevulinate.
| TABLE 12 |
| DNA Sequence of moeC4 |
| GTGACGACCCAATATCTGGATCTCTTTGCACGCCTCACAGAAAACTCCGA |
| CGGGGGAAAGAGGGAGTTCCTGGAGATCGGACGGCTCGCCGGGAGCTTCC |
| CCGCGGCCAGCGTCCGCAGCAGTGGACCCGTGACCGGCCGGGACAGCATC |
| AGCGTCTGGTGCAGCAACGACTACCTCGGCATGGGCCAGCATCCCGCAGT |
| GCTCAAAGCCATGAAGGACGCGATCGACGAGTACGGCGCCGGCGCCGGCG |
| GCTCACGCAACATCGGCGGCACCAACCACTACCACGTGCTGCTGGAGAGA |
| GAGCTCGCCGCGCTCCACGGCAAGGACGAGGCCCTGCTGTTCACCTCCGG |
| TTACACCGCCAACGACGGTGCGCTGTCCGTCATCGCCGGCCGCATGGAGA |
| AGTGTGTCGTCTTCTCCGACGCACTCAACCACGCGTCCATCATCGACGGC |
| CTGCGCCACAGCCGCGCCCAGAAGCAGATCTTCCGCCACAACGACCCCGC |
| TCACCTGGAAGAACTGATAGCGGCGGCCGACCCCGACGTCCCCAAGCTCA |
| TCGTCGCCGAGTCCGTGTACTCGATGAACGGCGAGATCGCCCCGCTGTCC |
| GAAATCGCCGACATCGCCAAGCGCCACGGGGCGATGACGTAGCTCGACGA |
| GGGAGGGCATCGCCGACGACTTCACCGTCATCATGGGCACCTTGGCCAAG |
| GGTTTCGGCACCACCGGCGGCTACATCGCAGGGCCCGCCGAAATCATCGA |
| GGCGGTGCGCATGTTCTCCCGCTCCTTCGTCTTCACCACCGCGCTGGCGC |
| CGGCCGTGGCCGCCGGCGCCCTGGCAGCCGTACACCATCTGCGGTCCTCC |
| GAGGTCGAGCGGGAACAGCTCTGGTCGAACGCGCAGTTGATGCACCGGCT |
| GCTGAACGAGCGTGGCATCCCCTTCATTTCGGACCAGACGCACATCGTGT |
| CCGTCATGGTGGGGGACGAGGCCGTGTGCAAGCGGATGTCCGCGCTGCTG |
| CTCGACCGGCACGGAATCTACGTGCAGGCGATCAACGCGCCGAGCGTGCG |
| GGTCGGTGAGGAGATCCTGCGGGTCGCCCCCGGAGCCGTGCACACCGCCG |
| ACGAGGTACGCGAATTCGTCGAGGCTCTGAGCCAGGTCTGGGAGGAAGTG |
| GGCTCCGCCCGCGTGCCGGCGACCCCGGCCGCTCTCTGA |
| (SEQ ID NO: 5) |
| TABLE 13 |
| Amino Acid Sequence of moeC4 |
| VTTQYLDLFARLTENSDGGKREFLEIGRLAGSFPAASVRSSGPVTGRDSI |
| SVWCSNDYLGMGQHPAVLKAMKDAIDEYGAGAGGSRNIGGTNHYHVLLER |
| ELAALHGKDEALLFTSGYTANDGALSVIAGRMEKCVVFSDALNHASIIDG |
| LRHSRAQKQIFRHNDPAHLEELIAAADPDVPKLIVAESVYSMNGDIAPLS |
| EIADIAKRHGAMTYLDEVHAVGMYGPEGAGIAAREGIADDFTVIMGTLAK |
| GFGTTGGYIAGPAEIIEAVRMFSRSFVFTTALAPAVAAGALAAVHHLRSS |
| EVEREQLWSNAQLMHRLLNERGIPFISDQTHIVSVMVGDEAVCKRMSALL |
| LDRHGIYVQAINAPSVRVGEEILRVAPGAVHTADDVREFVDALSQVWEEV |
| GSARVPATPAAL (SEQ ID NO: 28) |
| TABLE 14 |
| Sequence Homology of moeC4 |
| |AAO62615.1|aminolevulinate synthase; Streptomyces nodosus |
| subsp. asukaensis |
| Length = 409 |
| Score = 570 bits (1470), Expect = 3e−161 |
| Identities = 283/401 (70%), Positives = 336/401 (83%), Gaps = 1/401 (0%) |
| SEQ ID NO: 112 | |||
| Query | 4 | QYLDLFARLTENSDGGKREFLEIGRLAGSFPAASVRSSGPVTGRDSISVWCSNDYLGMGQ | 63 |
| ++|| ||| | +|||||||| || ||+| | | + |||||||||||||| | |||
| Sbjct | 3 | KHLDFFAREMEEFGARRREFLEIGRRAGRFPSAVARQGQDGTDVE-ISVWCSNDYLGMGQ | 61 |
| SEQ ID NO: 113 SEQ ID NO: 239 | |||
| Query | 64 | HPAVLKAMKDAIDEYGAGAGGSRNIGGTNHYHVLLERELAALHGKDEALLFTSGYTANDG | 123 |
| +| ||+|+|+|+| +|||+||||||||||||||||| ||||||||+|||+| ||+||||| | |||
| Sbjct | 62 | NPFVLEAVKNAVDAFGAGSGGSRNIGGTNHYHVLLENELAALHGKEEALIFPSGFTANDG | 121 |
| Query | 124 | ALSVIAGRMEKCVVFSDALNHASIIDGLRHSRAQKQIFRHNDPAHLEELIAAADPDVPKL | 183 |
| ||+|+||| +|||| ||||||||||||| |+|+|||||| ||||||+|||||+ ||| | |||
| Sbjct | 122 | ALTVLAGRAPGTLVFSDELNHASIIDGLRHSGAEKRIFRHNDMAHLEELLAAADPERPKL | 181 |
| Query | 184 | IVAESVYSMNGDIAPLSEIADIAKRHGAMTYLDEVHAVGMYGPEGAGIAAREGIADDFTV | 243 |
| || ||||||+||||||+| | +|+|||| |++|||||||||||+||||||||||||+||| | |||
| Sbjct | 182 | IVLESVYSMSGDIAPLAETAALARRHGATTFIDEVHAVGMYGPQGAGIAAREGIADEFTV | 241 |
| Query | 244 | IMGTLAKGFGTTGGYIAGPAEIIEAVRMFSRSFVFTTALAPAVAAGALAAVHHLRSSEVE | 303 |
| +|||||||||| |||||||| +|+||| ||| |+|||++ || |||||||| |||+|| | | |||
| Sbjct | 242 | VMGTLAKGFGTAGGYIAGPAALIDAVRNFSRGFIFTTSIPPATAAGALAAVQHLRASEGE | 301 |
| Query | 304 | REQLWSNAQLMHRLLNERGIPFISDQTHIVSVMVGDEAVCKRMSALLLDRHGIYVQAINA | 363 |
| | +| +|| |+|||| || |||+|||+||||| |||+ +|++ |||||+||||||| ||| | |||
| Sbjct | 302 | RTRLAANAGLLHRLLKERDIPFVSDQSHIVSVFVGDDGLCRQASALLLERHGIYVQPINA | 361 |
| Query | 364 | PSVRVGEEILRVAPGAVHTADDVREFVDALSQVWEEVGSAR | 404 |
| |||| ||||||||| | || || +| +|+ +| ++| | | |||
| Sbjct | 362 | PSVRAGEEILRVAPSATHTTGDVEKFAEAVEGIWRDLGIPR | 402 |
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeC4 gene is an aminolevulinate synthase which participates in the conversion of Moe intermediate compound 18 or 19 in the course of moenomycin biosynthesis to yield a Moe compound MmA or 21, as shown in FIGS. 4A-4D.
4. moe A4 (Cluster 2)
Also identified in cluster 2 was the moe A4 gene, the translation product of which shows end-to-end homology to acy-CoA ligases (63% identity and 73% similarity to hypothetical acyl-CoA ligase from S. aizunensis). The nucleotide and polypeptide sequences are shown in Tables 15 and 16, respectively. A sequence alignment between moe A4 and the closest homolog identified in the BLAST search is shown in Table 17. The moe A4 protein may be involved in the formation of 5-ALA coenzyme A ester, a putative prerequisite for its intramolecular cyclization.
| TABLE 15 |
| DNA Sequence of moeA4 |
| ATGACCCTGACCGCCGCGTCCGTACTGGCCGAGTCCGCCGGGCGACGCCC |
| CGACCACCCCGCGCTCGTCTTCGGCTCCGAACGCATCACCTACGCCGAGC |
| TCTGGCTCGCAACCCGCCGGTACGCGGCGGTGCTGAGGGACCGCGGTGTG |
| CGCCCGGGCGACCGGATCGCCCTGCTGCTGCCGAACACACCGCACTTCCC |
| GATGGTGTACTACGGCGTGCTGGCGCTCGGTGCCGTGGTGGTCCCGGTGC |
| ACGGCCTGCTGCGTGCCGACGAGATCGTCCACGTGCTGGGCGAGTCCGAG |
| GCGAAGGCCATGGTGTGCGCGGCCCCGATGCTGACCGAGGGCGCCAAGGC |
| GGCCGGGACGGCCGGGGTTCCGCTGCTCACCGTCATGGTCGAGAACGGCG |
| AGGACGACGACGGCCCGGCACGCCTCGACGTGCTCGCCGAACGGGCGGAG |
| CCCCTGGACGGTCTGGTGCCGCGCGCGCCCGACGACTTGGCCTTGGTGCT |
| GTACACCTCGGGCACCACCGGCCGGCCCAAGGGCGCGATGATCACCCACC |
| TCAACCTGGTGATGAACGTCAGCACCACGATGCGCTCGCCGTTCGACCTC |
| GGCCCCGAGGACGTGCTGCTGGGCTGTCTGCCGCTGTTCCACACCTTCGG |
| CCAGACCTGCGGCATGAGCGCCTGTTTCCTGGCCGGCGGCACCCTGGTGC |
| TCATGAACCGCTTCGACGGCCCCGGCGCGCTCGACCTCATGGTCACCGAG |
| GGCTGCACGGTGTTCATGGGCGTCCCGACCATGTACCTGGCCCTCCTCGA |
| CGCCGCCGCTCACGACGCCCGCCGCCCCGTGCTCGACCGCGCCTTCTCCG |
| GCGGTTCGGCGCTACCGGTCAAGGTGCTCGAGGAGTTCCAGGAGGTCTAC |
| GGCTGCCCGATCTACGAGGGGTACGGCCTCACGGAGACCTCGCCGGTGGT |
| GGCGTACAACCAGAAGGCGTGGCCGCGCAGGCCCGGCACCGTGGGGCGCC |
| CCATCTGGGGCGTGGAGGCGGAGATCGCCGCCGCCGACGTGGAGGACCGT |
| ATCGAGCTGCTGCCGGCCGGGGAGATCGGGGAGATCGTCGTACGCGGCCA |
| CAACGTCATGGCCGGCTACCTCAACCGGCCGGAAGCCACCGCAGCCGTGC |
| TGGTCGACGGCTGGTTCCGCTCGGGCGACCTGGGGATGAAGGACGCCGAC |
| GGCTATCTGACCATCGTCGACCGCAAGAAGGACATGGTGCTGCGCGGTGG |
| CTACAACGTCTATCCACGCGAGGTGGAGGAGGTGCTGATGCGTCACCCGG |
| CCGTCGCCCAGGTTGCCGTCATCGGTGTCCCCGACGACAAGTACGGCGAG |
| GAGGTGTGCGCCGTGGTGCGGACGCGGCCGGGCACGGATCCGGACGCGGC |
| GCTGGCCGCGCACATCGTGTCCTGGAGCAGGCAGCGAATCGCCGCGTACA |
| AGTACCCGCGCCGGGTGGAGTTCGTCGAGGACTTCCCCCTCGGGCCGAGC |
| GGCAAGGTACTGAAACGCGAACTCGCCGCCCGCTTCGCCGGCGGTGGCTG |
| A (SEQ ID NO: 6) |
| TABLE 16 |
| Amino Acid Sequence of moeA4 |
| MTLTAASVLAESAGRRPDHPALVFGSERITYAELWLATRRYAAVLRDRGV |
| RPGDRIALLLPNTPHFPMVYYGVLALGAVVVPVHGLLRADEIVHVLGDSE |
| AKAMVCAAPMLTEGAKAAGTAGVPLLTVMVENGEDDDGPARLDVLAERAE |
| PLDGLVPRAPDDLALVLYTSGTTGRPKGAMITHLNLVMNVSTTMRSPFDL |
| GPEDVLLGCLPLFHTFGQTCGMSACFLAGGTLVLMNRFDGPGALDLMVTE |
| GCTVFMGVPTMYLALLDAAAHDARRPVLDRAFSGGSALPVKVLEEFQEVY |
| GCPIYEGYGLTETSPVVAYNQKAWPRRPGTVGRPIWGVEAEIAAADVEDR |
| IELLPAGEIGEIVVRGHNVMAGYLNRPEATAAVLVDGWFRSGDLGMKDAD |
| GYLTIVDRKKDMVLRGGYNVYPREVEEVLMRHPAVAQVAVIGVPDDKYGE |
| EVCAVVRTRPGTDPDAALAAHIVSWSRQRIAAYKYPRRVEFVEDFPLGPS |
| GKVLKRELAARFAGGG (SEQ ID NO: 29) |
| TABLE 17 |
| Sequence Homology of moeA4 |
| gb|AAX98210.1|acyl CoA ligase [Streptorayces aizunensis] |
| Length = 506 |
| Score = 624 bits (1610), Expect = 3e−177 |
| Identities = 326/513 (63%), Positives = 379/513 (73%), Gaps = 7/513 (1%) |
| SEQ ID NO: 114 | |||
| Query | 1 | MTLTAASVLAESAGRRPDHPALVFGSERITYAELWLATRRYAAVLRDRGVRPGDRIALLL | 60 |
| || + |+|||||||| | ||| |+|||+|| || ||||| || +|+ | |++|||+ | |||
| Sbjct | 1 | MTRSVAAVLAESAGRWPSRTALVCGAERISYARLWDRARRYAAALRGQGIGPDDKVALLM | 60 |
| SEQ ID NO: 115 | |||
| Query | 61 | PNTPHFPMVYYGVLALGAVVVPVHGLLRADEIVHVLGDSEAKAMVCAAPMLTEGAKAAGT | 120 |
| |||| | ||+ |||||||||||| ||+ |+ |+| || |+|+| | + | |+ || | |||
| Sbjct | 61 | PNTPEFAAVYFAVLALGAVVVPVHTLLKPAEVSHLLRDSGARALVWAGTLPQETARDAGE | 120 |
| Query | 121 | AGVPLLTVMVENGEDDDGPARLDVLAERAEPLDGLVPRAPDDLALVLYTSGTTGRPKGAM | 180 |
| || |||| || | || + ||+| | | |||||||||||||||||||| | |||
| Sbjct | 121 | TGVLLLTV----GEALHGSVLLD---DGVEPIDTYVERGADDLALVLYTSGTTGRPKGAM | 173 |
| SEQ ID NO: 116 SEQ ID NO: 117 | |||
| Query | 181 | ITHLNLVMNVSTTMRSPFDLGPEDVLLGCLPLFHTFGQTCGMSACFLAGGTLVLMNRFDG | 240 |
| +|| |+ |++ | ||| | +||||| ||| ||||| |||+ | || |||+| ||+ | |||
| Sbjct | 174 | LTHGNVATNIAVTAVSPFAFGEDDVLLGALPLSHTFGQICGMAVTFHAGATLVVMERFEA | 233 |
| Query | 241 | PGALDLMVTEGCTVFMGVPTMYLALLDAAAHDARRPVLDRAFSGGSALPVKVLEEFQEVY | 300 |
| || || |||||||||||| |||+| | | | | | +|||||||| ||+ + + | |||
| Sbjct | 234 | HDALRLMREHGCTVFMGVPTMYHALLEAVAAGAPAPRLTRVYSGGSALPVPVLDRVRAAF | 293 |
| Query | 301 | GCPIYEGYGLTETSPVVAYNQKAWPRRPGTVGRPIWGVEAEIAAADVEDRIELLPAGEIG | 360 |
| || +||||||||||| ||||| | +||||| || || || |++| || || |+|| | |||
| Sbjct | 294 | GCEVYEGYGLTETSPCVAYNQPGIPCKPGTVGLPIDGVRVAIADAELEGRIRLLKQGDIG | 353 |
| Query | 361 | EIVVRGHNVMAGYLNRPEATAAVLVDGWFRSGDLGMKDADGYLTIVDRKKDMVLRGGYNV | 420 |
| |||| ||||||||| ||+ || ||||||||+||+|++| ||||+||||||||++|||||| | |||
| Sbjct | 354 | EIVVSGHNVMAGYLGRPQETAEVLVDGWFRTGDMGVQDEDGYLSIVDRKKDMIVRGGYNV | 413 |
| Query | 421 | YPREVEEVLMRHPAVAQVAVIGVPDDKYGEEVCAVVRTRPGTDPDAALAAHIVSWSRQRI | 480 |
| ||||||+||+||||| |+||| |+||||||||| +|| || ||+||| + | |||
| Sbjct | 414 | YPREVEDVLLRHPAVDGACVVGVPSVKHGEEVCAVVRVKPGQRASGLLAEEIVAWSRVHM | 473 |
| Query | 481 | AAYKYPRRVEFVEDFPLGPSGKVLKRELAARFA | 513 |
| ||||||||||||| |||| |||||||||| |+| | |||
| Sbjct | 474 | AAYKYPRRVEFVETFPLGSSGKVLKRELAHRYA | 506 |
To evaluate the function of moe A4 and to show that the genes in cluster 2 are used in moe biosynthesis, a moe A4 knockout strain of S. ghanaensis was generated. The mutant S. ghanaensis, termed LH1, did not produce moe A. Instead, it accumulated an antibacterially active moe intermediate. Testing via TLC, UV absorption and mass-spectrometry showed that the intermediate is identical to previously described moe A lacking the chromophore unit (Zehl 2006; see Materials & Methods).
The introduction of a functional copy of the moe A4 gene in trans into the LH1 mutant strain restored moe A production. Thus, the moe A4 knockout did not appear to alter the expression of other genes in the mutant. In sum, the data confirm that the moe A gene is used for C5N unit formation during moes biosynthesis.
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeA4 gene is an acyl CoA ligase which participates in the conversion of Moe intermediate compound 18 or 19 in the course of moenomycin biosynthesis to yield a Moe compound MmA or 21, as shown in FIGS. 4A-4D.
5. moeB4 (Cluster 2)
The moeB4 gene has been identified as a putative amide synthase gene, and is homologous to different AMP-dependent synthetases and ligases, particularly to aminocoumarin ligase SimL (45% identity and 62% similarity), The nucleotide and polypeptide sequences are shown in Tables 18 and 19, respectively. A sequence alignment between moeB4 and the closest homolog identified in the BLAST search is shown in Table 20. The stop codon of the moeB4 gene overlaps the start codon of moe A4 by one nucleotide, and these two genes are transcribed divergently with respect to the moeC4 transcriptional direction. It is probable that moeB4 can transfer a CsN unit onto the saccharide scaffold of moe A, similarly to the amide synthases involved in aminocoumarin antibiotics biosynthesis.
| TABLE 18 |
| DNA Sequence of moeB4 |
| ATGTCCTCGAACGAGAATTACGTCCGCCGGGTGCTTGAGGCGCTGGCCTC |
| CGACCCCGACCGGATTGCCCTGTGGGCGGATGGTGAAGAAATCACCGCGG |
| GCCAGGTCTCCAGGGCGGTTCTCACGGCAGCGGAACTTCTGCTCCGGCAC |
| TTCACGGAACATCGAGACCCGAGTGCGGAAGGCAAGGCCCCGGTTGTGGC |
| GGTGCTGACCGTCACCAACAGCCCGGCGACCATCATCCTCCGCTACGCGG |
| CCAACCTGGCCGGGGCCACCCTGGTCCACCTGCACTCCACGAACGCGGTG |
| GACCCCACCGACCAGCTGGCCGCCGCCGCCCGGCTGGACATTCTCAGCAA |
| GACCGGGGCGACCTTCCTCGCCGTCGACAAGGAGAACCTCGACGCGGCCC |
| GAGAGCTGTGCGACCGGCTGCCCGAGCCACCGCGTCTCGCCGCTCTCGGT |
| GCCCTCGGCCCCGATGTCCTGGACCTCTCGTCGGGCGACCCGGACGCCTT |
| CGGCCACGACGCCGTCGAGGCCGACCCCGAACAGCCGGCCGTGGTGATCT |
| ACACCAGCGGTACCAGCGGACGTCCCAAGGGTGTCACGCAGCCGTACCGC |
| CTTCGCCGTGCCAACCTCCAAGTGGCCCTCCAGTCCCCCGAACCCATCGT |
| GTACCTGTCGACCCTGCCGGTGAGCAACTCCAGCGGCTCCGCCGTCGACG |
| TCGCGCTCGCCTCCGGCGGAACGGTCGTCCTGCACGACGGGTTCGAGGCG |
| GGCGAAGTGCTGCGGGCCGTGGAACAGCACCGCGTCTCCACGCTGACCAT |
| CACCCCGCCGCAGCTGTACATGCTGATCGACCACCCCGACACCGCCACCA |
| CCGACCGTTCGAGCATCAGGCTCATCACCTACCTCGGTTCCCCCGCGGCC |
| CCCGCCCGACTGGCCGAGGCGGTCGAGGTGTTCGGCCCGGTGTTGCTCCA |
| GCTCTACGGGACCACGGAAGTCAACGGCATCAGCATGCTGATGCCGCAGG |
| ACCACTTCGACCCGGAACTGCGCCGGACCGTCGGACGTCCGACCACGGAG |
| ATACGCATCCGCGACGTGGACGACGACCGCGACCTGCCGCCCGGCGAGAT |
| CGGCGAGGTGTGCGTGCAGAGCCCGTCCACCATGCTCGGCTACTGGGGCG |
| AACCGGAGCTGACCGCCGCGATCATCCGCGACGGCTGGGTGCACACCGGC |
| GACCTCGGTTCCCTCGACGAGAACGGCTTTCTGCGCCTGCACGGCCGCAT |
| GGGCGAGGTGATGAAGACCAACGGCATCAAGGTCCATCCCACCGATGTGG |
| AGAACGCGCTGCTGACCCATCCGGAGGTCACCCAGGCCGCTGTGTACTGC |
| GTGGTCGACGAGGACCGCGTGGAGCACATCCACGCCGCCGTCGTGGTACG |
| GCCGGGCGGCACCGCCGACTCCGGGACGCTGATCGGCCACGTCGCCGCCG |
| AGCTGTCTCCGAAGCACGTACCGGCCGTGGTGACGTTCCACGACGCGCTG |
| CCCCTCACCCGTGCCGGAAAACCGGACAAGCCGGCGCTGGCCGCACGGCA |
| CAACGGTGCGGCATGA (SEQ ID NO: 7) |
| TABLE 19 |
| Amino Acid Sequence of moeB4 |
| MSSNENYVRRVLEALASDPDRIALWADGEEITAGQVSRAVLTAAELLLRH |
| FTEHRDPSAEGKAPVVAVLTVTNSPATIILRYAANLAGATLVHLHSTNAV |
| DPTDQLAAAARLDILSKTGATFLAVDKENLDAARELCDRLPEPPRLAALG |
| ALGPDVLDLSSGDPDAFGHDAVEADPEQPAVVIYTSGTSGRPKGVTQPYR |
| LRRANLQVALQSPEPIVYLSTLPVSNSSGSAVDVALASGGTVVLHDGFEA |
| GEVLRAVEQHRVSTLTITPPQLYMLIDHPDTATTDRSSIRLITYLGSPAA |
| PARLAEAVEVFGPVLLQLYGTTEVNGISMLMPQDHFDPELRRTVGRPTTE |
| IRIRDVDDDRDLPPGEIGEVCVQSPSTMLGYWGEPELTAAIIRDGWVHTG |
| DLGSLDENGFLRLHGRMGEVMKTNGIKVHPTDVENALLTHPEVTQAAVYC |
| VVDEDRVEHIHAAVVVRPGGTADSGTLIGHVAAELSPKHVPAVVTFHDAL |
| PLTRAGKPDKPALAARHNGAA (SEQ ID NO: 30) |
| TABLE 20 |
| Sequence Homology of moeB4 |
| gb|AAK06803.1|putative aminocoumarin ligase SimD5 |
| [Streptomyces antibioticus] |
| Length = 519 |
| Score = 424 bits (1089), Expect = 7e−117 |
| Identities = 236/517 (45%), Positives = 322/517 (62%), Gaps = 12/517 (2%) |
| SEQ ID NO: 118 | |||
| Query | 1 | MSSNENYVRRVLEALASDPDRIALWADGEEITAGQVSRAVLTAAELLLRHFTEHRDPSAE | 60 |
| | ||+|||++| | +|| +|| + || ++ ++ +||| + | | |||
| Sbjct | 1 | MEGNEHYVRQILNTLRADPSGVALVHRDTPVIAGDLADSITSAAEAMRG--------SGV | 52 |
| SEQ ID NO: 119 | |||
| Query | 61 | GKAPVVAVLTVTNSPATIILRYAANLAGATLVHLHSTNAVDPTDQLAAAARLDILSKTGA | 120 |
| | || +|| |+|||++ |||||| |||+||| || +|+| |+| |+ |+++ | |||
| Sbjct | 53 | GVGSVVGILTDPNTPATLVARYAANLLGATVVHLFGVNAANPSDLLSAEAQGGIVAEALP | 112 |
| SEQ ID NO: 120 | |||
| Query | 121 | TFLAVDKENLDAARELCDRLPEPPRLAALGALGPDVLDLSSGDPDAFGHDAVEADPEQPA | 180 |
| + || ||+ || + + | |+ || || ||+||+ || || | | | |||
| Sbjct | 113 | AMVVVDAANLERARAIREVPSVRPVLSGLGELGHDVIDLTDSPAGAFRPDA--ARDGDTA | 170 |
| Query | 181 | VVIYTSGTSGRPKGVTQPYRLRRANLQVALQSPEPIVYLSTLPVSNSSGSAVDVALASGG | 240 |
| || ++||++||||| +|++ + + + + | | |+++|+| | | ||| | |||
| Sbjct | 171 | VVTFSSGSTGRPKGTAWSFRVKADMVAASARRAQKATALVTAPLTHSNGFVADDVLVSGG | 230 |
| SEQ ID NO: 121 | |||
| Query | 241 | TVVLHDGFEAGEVLRAVEQHRVSTLTITPPQLYMLIDHPDTATTDRSSIRLITYLGSPAA | 300 |
| |||| ||+ ||||+| +++|+ | ++ |||| | |||+| || ||+| + | | |+ | |||
| Sbjct | 231 | TVVLLPGFDETEVLRSVARYQVNRLAVSAPQLYALADHPETTRTDLSSVRDLFYTGVAAS | 290 |
| Query | 301 | PARLAEAVEVFGPVLLQLYGTTEVNGISMLMPQDHFDPELRRTVGRPTTEIR--IRDVDD | 358 |
| | |+| | +||| ||+|+|||+| | || |+ +| | || ||||| +| ||| | | |||
| Sbjct | 291 | PERVAVAEKVFGSVLMQVYGTSETNIISWLIAGEHTDAGLRATVGRPLEWLRVTIRDPQD | 350 |
| SEQ ID NO: 122 | |||
| Query | 359 | DRDLPPGEIGEVCVQSPSTMLGYWGEPELTAAIIRDGWVHTGDLGSLDENGFLRLHGRMG | 418 |
| +| || || ||| | || | || +|| || +||||+ |||+| ||+ |+| ||||+ | |||
| Sbjct | 351 | ERVLPTGETGEVWVNSPWRMDHYWNDPEQTARTVRDGWIRTGDVGHLDDAGYLHLHGRLA | 410 |
| Query | 419 | EVMKTNGIKVHPTDVENALLTHPEVTQAAVYCVVDEDRVEHIHAAVVVRPGGTADSGTLI | 478 |
| |+|||||||+| || +|| ||+| +|||+ | + |||| ||| ||+| | | | | |||
| Sbjct | 411 | GVIKTNGIKVYPVAVERSLLDHPDVAEAAVFGVENSDRVERIHAVVVLREGAGAGPEDLR | 470 |
| Query | 479 | GHVAAELSPKHVPAVVTFHDALPLTRAGKPDKPALAA | 515 |
| ||+ ||| | || + +||| ||||| | | | |||
| Sbjct | 471 | QHVSSHLSPNHAPADIELRSSLPLIGFGKPDKLRLRA | 507 |
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeB4 gene is an amide synthetase which participates in the conversion of Moe intermediate compound 18 or 19 in the course of moenomycin biosynthesis to yield a Moe compound MmA or 21, as shown in FIGS. 4A-4D.
B. Glycosyltransferase Genes
Five putative glycosyltransferase (GT) genes were identified within moe cluster 1, moeGT1 through moeGT5. Five moe GT genes were proposed to govern the assembly of moe A pentasaccharide moiety, but the functions of these genes was not established. Based on sequence analysis, we have suggested that moeGT1 controls the attachment of the second sugar (unit E) during moe A production. However, we were unable to isolate any monosaccharide intermediates from the producing organism, S. ghanaensis, when moeGT1 was disrupted. However, we have found that a recombinant ΔmoeGT4 S. lividans TK24 strain accumulates two new compounds having LC characteristics and exact masses consistent with monosaccharide intermediates 2 and 3 (Table 21, FIGS. 4A-4D), indicating that moeGT4 controls the attachment of the E ring. Notably, 2 and 3 contain C15 chains and we did not detect any monosaccharides having C25 chains. Strain ΔmoeGT was found to produce a trisaccharide, 11, which contained the complete C25 chain; the double mutant strain, ΔmoeGT5ΔmoeGT3, accumulated a disaccharide moe A intermediate 4 having a C15 chain (Table 21, FIGS. 4A-4D).
| TABLE 21 |
| MoeA pathway products found in S. lividans TK24 |
| strains carrying subsets of moe genes |
| Mutation(s) |
| moeno38-1/ | Mass ((M-H)−) |
| eoexpression type | Mt. | Min1 | Caled | Obsvd |
| ΔmoeN5 | 23 | 4.2 | 1364.5026 | 1364.5023 |
| 22 | 4.1 | 11365.4867 | 1365.4884 | |
| ΔmoeGT4 | 2 | 4.7 | 564.2215 | 564.2210 |
| 3 | 4.8 | 578.2372 | 578.2374 | |
| ΔmoeF5 | 1 | 3.9 | 565.2056 | 565.2054 |
| ΔmoeGT5GT3 | 4 | 4.8 | 781.3166 | 781.3143 |
| ΔmoeGT5 | 11 | 10.4 | 1122.5004 | 1122.5004 |
| ΔmoeGT2 | 15 | 10 | 1325.5797 | 1325.5789 |
| ΔmoeH5 | 17 | 9.3 | 1501.6118 | 1501.6115 |
| ΔmoeK5 | 242 | 9.6 | 1486.6122 | 1486.6116 |
| ΔmoeB5A5 | 19 | 9.9 | 1500.6278 | 1500.6273 |
| 5-1+ ΔmoeB5A5 | 21 | 9.3 | 1596.6490 | 1596.6492 |
| 5-1+ ΔmoeH5 | 17 | 9.7 | 1501.6118 | 1501.6122 |
| moeR5+ ΔmoeB5A5 | 18 | 10.0 | 1484.6329 | 1484.6326 |
| moeR5+ ΔmoeH5 | 16 | 9.4 | 1485.6169 | 1485.6195 |
| 1250 × 4.6 mm Agilent C18 column, under LC conditions used for accurate mass determination (Ostash 2007) | ||||
| 2proposed structure of this compound is shown in SI |
The isolation of the farnesylated mono- and disaccharides 2, 3, and 4 and the moenocinylated trisaccharide 11 strongly suggests that MoeN5 converts C15-linked precursors into C25-linked intermediates after at least three glycosylation steps. Since moenomycins without the branching glucose unit D are naturally produced by S. ghanaensis (Welzel 2005), and accumulate when moeGT3 is disrupted in this strain, we propose that moe A biosynthesis can follow two branches from precursor 4, depicted on FIG. 4, which merge at the stage of tetrasaccharide 14/15. In one branch, MoeGT3 attaches the D ring glucose; in the other, MoeGT5 attaches the C ring, which can be either GlcNAc or chinovosamine (see below). Trisaccharides 8 and 9/10 from both branches of the biosynthetic pathway must be acceptor substrates for MoeN5-catalyzed lipid chain elongation. Strain ΔmoeGT2 accumulates the tetrasaccharide moe A precursor 15 (Table 21, FIGS. 4A-4D), showing that moeGT2 controls the attachment of the B ring sugar. Thus, the gene disruption studies have allowed us to propose functions for all of the glycosyltransferases except MoeGT1 based on the identification of moe A intermediates. By a process of elimination, we propose that moeGT1 controls the first glycosylation to attach the F ring precursor to the farnesylated phosphoglycerate, which is consistent with our inability to detect any glycosylated moe A intermediates in the moeGT1-deficient S. ghanaensis mutant OB21e (Ostash 2007).
Each of the moe glycosyltransferase (GT) genes will be discussed in further detail below.
1. moeGT1
The closest homologues of the moeGT1 gene product are MurG-like UDP-N-acetylglucosamine: LPS-acetylglucosamine transferases from various bacteria (27% identity and 40% similarity to putative GT from Polaromonas sp JS666). Conserved domain database (CDD) search revealed presence of GT group 1 domain (pfam 00534) in C-terminal portion of moeGT1, as well as incomplete MurG and RfaG domains (COG0707 and COG0438, respectively). The nucleotide and polypeptide sequences are shown in Tables 22 and 23, respectively. A sequence alignment between moeGT1 and the closest homolog identified in the BLAST search is shown in Table 24. GTs having these domains have been shown to be involved in the synthesis of lipopolysaccharides. For example, in peptidoglycan biosynthesis, MurG transfers N-acetylglucosamine onto monoglycosylated carrier Lipid I, thus forming Lipid II (Men 1998, Heijenoort 2001).
| TABLE 22 |
| DNA Sequence of moeGT1. |
| ATGGCTGCCCCCGACCGACCGCTCGTCCAGGTGCTCTCCCCCCGGACCTG |
| GGGCGAGTTCGGCAACTACCTCGCCGCGACGCGCTTCTCCCGCGCGCTCC |
| GGAGCGTGATCGAGGCGGAAGTGACCCTGCTGGAGGCGGAGCCGATCCTC |
| CCGTGGATCGGCGAGGCCGGGGCGCAGATCCGGACCATCTCCCTGGAGAG |
| CCCCGACGCCGTCGTCCGCAACCAGCGGTACATGGCCCTCATGGACCGCC |
| TCCAGGCACGCTTCCCGGAGGGGTTCGAGGCGGACCCCACCGCCGCCCAG |
| CGGGCGGACCTGGAACCGCTCACCCGGCACCTGCGGGAGAGCGCCCCCGA |
| CGTGGTGGTCGGCACGAAGGGGTTCGTGGCGAGGCTGTGCGTGGCCGCCG |
| TCCGGCTCGCCGGGACGTCCACCAGGGTCGTCAGCCACGTGACCAACCCC |
| GGGCTGCTGCAGCTGCCGCTGCACCGCAGCCGGTACCCGGACCTGACACT |
| CGTCGGCTTCCCCCGGGCGAAGGAGCACCTGCTGGCCACGGCCGGCGGCG |
| ACCCGGAGCGCGTCCAGGTGGTGGGCCCGCTCGTCGCCCAGCACGACCTG |
| CGGGACTTCATGACCAGTGAGACGGCCGTCTCCGAGGCGGGGCCCTGGGG |
| CGGCGACTCGGGCCCGGACCGGCCACGGGTGATCATCTTCTCCAACCGCG |
| GCGGGGACACCTACCCCGAGCTGGTGCGGCGCCTCGCCGACCGCCACCCC |
| GGCATCGACCTCGTCTTCGTCGGCTACGGCGACCCGGAGCTCGCCCGCCG |
| CACCGCTGCGGTCGGGCGGCCCCACTGGCGGTTCCACAGCGTCCTCGGCC |
| AGAGCGAGTACTTCGACTACATCCGGCGTGCCTCCCGGTCCAGGTACGGG |
| CTCCTCGTCTCGAAGGCGGGGCCCAACACCACCCTGGAGGCGGCCTACTT |
| CGGCATACCGGTCCTGATGCTCGAGTCGGGGCTGCCCATGGAGCGGTGGG |
| TGCCGGGACTGATCCACGAGGAGGGGCTGGGCCACGCCTGCGCCACCCCC |
| GAGGAGCTGTTCCGCACGGCGGACGACTGGCTGACCCGCCCGTCGGTGAT |
| CGAGGTGCACAAGAAGGCCGCGGTCTCCTTCGCCGCTTCCGTACTGGACC |
| AGGACGCGGTGACGGCCAGGATCAAGGCCGCCCTCCAGCCCCTGCTGGAC |
| GCCCGATGA (SEQ ID NO: 8) |
| TABLE 23 |
| Amino Acid Sequence of moeGTI |
| MAAPDRPLVQVLSPRTWGEFGNYLAATRFSRALRSVIDAEVTLLEAEPIL |
| PWIGEAGAQIRTISLESPDAVVRNQRYMALMDRLQARFPEGFEADPTAAQ |
| RADLEPLTRHLRESAPDVVVGTKGFVARLCVAAVRLAGTSTRVVSHVTNP |
| GLLQLPLHRSRYPDLTLVGFPRAKEHLLATAGGDPERVQVVGPLVAQHDL |
| RDFMTSETAVSEAGPWGGDSGPDRPRVIIFSNRGGDTYPELVRRLADRHP |
| GIDLVFVGYGDPELARRTAAVGRPHWRFHSVLGQSEYFDYIRRASRSRYG |
| LLVSKAGPNTTLEAAYFGIPVLMLESGLPMERWVPGLIHEEGLGHACATP |
| EELFRTADDWLTRPSVIEVHKKAAVSFAASVLDQDAVTARIKAALQPLLD |
| AR (SEQ ID NO: 31) |
| TABLE 24 |
| Sequence Homology of moeGT1 |
| gi|84696063|gb|EAQ21850.1|similar to UDP-N- |
| acetylglucosaraine:LPS N-acetylglucosamine transferase |
| [Polaromonas naphthalenivorans CJ2] |
| Length = 599 |
| Score = 36.6 bits (83), Expect = 2.3, Method: Composition-based stats. |
| Identities = 68/246 (27%), Positives = 100/246 (40%), Gaps = 17/246 (6%) |
| SEQ ID NO: 123 | |||
| Query | 160 | SRYPDLTLVGFPRAKEHLLATAGGDPERVQVVGPLVAQHDLRDFMTSETAVSEAGPWGGD | 219 |
| |+ | | + + || || |++| | + + | | |||++ | | |||
| Sbjct | 144 | SKRIDRTFLAHTDLESRWLA-AGVPPDKVTTSG-MPVRAPAADGATRETALTALG----- | 196 |
| SEQ ID NO: 124 SEQ ID NO: 240 SEQ ID NO: 241 | |||
| SEQ ID NOS: 125 126 127 | |||
| Query | 220 | SGPDRPRVIIFSNRGG-DTYPELVRRLADRHPG-IDLVFV-GYGDPELARRTAAVGR-PH | 275 |
| || | |+| | + | | +| || ||| + ++ | | + | || | | | |||
| Sbjct | 197 | LAPDAPTVLITSGKEGVGDYALVVESLARHHPGPLQIIAVCGANARQQALLTALQKRLPE | 256 |
| SEQ ID NO: 128 | |||
| SEQ ID NO: 129 | |||
| Query | 276 | WRFHSVLGQSEYFDYIRRASRSRYGLLVSKAGPNTTLEAAYFGIPVLMLESGLPMERWVP | 335 |
| | | + | + | ||++||| | || | | ++|+ || | |||
| Sbjct | 257 | PVALKVCGLVPHADLL--AWMRAADLLITKAGGMTPAEAFAVGTPTILLDVVSGHERENA | 314 |
| SEQ ID NO: 130 | |||
| Query | 336 | GLIHEEGLGHACATPEELFRTADDWLTRPSVIEVHKKAAVSFAASVLDQDAVTARIKAAL | 395 |
| | |+ | + | | | ++| ++| |+ + + || | |||
| Sbjct | 315 | ALFVRLGVADLADTLAQAGELAAAVLASPQRQTAMRRAQLAFH----DRAGLGRIARFAL | 370 |
| SEQ ID NO: 131 | |||
| Query | 396 | QPLLDA | 401 |
| | | | | |||
| Sbjct | 371 | DPALPA | 376 |
To evaluate the function of moeGT1 with respect to moe biosynthesis, a recombinant S. ghanaensis strain, termed OB21e, was generated (see Materials and Methods, see FIGS. 10A-10B). OB21e included an insertionally inactivated moeGT1 gene. The moeGT1 deficient OB21e mutant did not produce moe A or any of its antibiotically active precursors as determined by bioassays and LC-MS analysis (see FIGS. 11A-11D). To exclude the possibility of polar effects of the moeGT1 knockout on downstream genes expression, we introduced a functional copy of the moeGT1 gene under the control of the ermE promoter (plasmid pOOB41c) into OB21e strain. This complemented the moe A nonproducing phenotype of the OB21e mutant, yielding a full-size, functional moe A product. The trisaccharide degradation product of moe A (units C-E-F-G-H, FIG. 1) is known to display, in vivo, the full antibacterial activity of parent compound (Welzel 1987). Based on the studies of the present invention, it is propose that the polypeptide encoded by moeGT1 gene is a glycosyl transferase that attaches the first sugar (e.g., glucuronic acid; GalA) to the phosphoglycerate-farnesyl moiety of Moe intermediate compound 1P in the course of moenomycin biosynthesis to yield a Moe intermediate compound 1, as shown in FIGS. 4A-4D.
2. moeGT2, moe GT3, moeGT4 and moe GT5
The putative translation product of the moeGT2 gene shows homology to known GTs involved in lipopolysaccharide O-antigen biosynthesis in Yersinia enterocolitica, Escherichia coli and Streptococcus agalactiae (28% identity and 47% similarity) (Zhang 1997, Paton 1999, Chaffin 2002). The nucleotide and polypeptide sequences are shown in Tables 25 and 26, respectively. A sequence alignment between moeGT2 and the closest homolog identified in the BLAST search is shown in Table 27. MoeGT2 also contains a conserved GT domain (pfam00535) present in very diverse family-2 GTs, which transfer sugars to a range of substrates including cellulose, dolichol phosphate and teichoic acids.
| TABLE 25 |
| DNA Sequence of moeGT2 |
| CTGACACACGAGGTCACCCCGAGGGGCGGCCCGGAAGGAGACGCGATGGT |
| GACAGCGGGGCCGGCCGGGGCGGCGGTGACCGTCGTCCTGCCTCACTACG |
| ACTGCGCGGCGTACCTGGGTGCGGCCGTCGGATCGGTGCTCTCCCAGGAC |
| CGCCCGGACCTGCGCCTGACGGTGGTGGACGAATGCTCGCCCGAAGAGAA |
| GTGGGCCCGCGCACTCCACCCGTACGCCGGCGACCCCCGGCTGACCGTGG |
| TCCGCACCTCCCGCAACGTCGGCCACCTGCGGATCAAGAACAAGGTCCTG |
| GAATCGGTGGACACCCCCTACGTGGCCTTCCAGGACGCCGACGACATCAG |
| CCTGCCGGGCCGGCTGCGCCACCAGCTGGCCCTCCTGGAGAGCGGCGGCG |
| CCGATCTGGTCGGCTGCGCCTACTCCTACATCGACGAGGCGGGCCGTACG |
| ACGGGACACCGGCGGATGCCCCGCAACGGCAACCTCTGGATGCGGCTGGG |
| GCGGACGACCGTGCTCCTGCACCCGTCCTCGGTGGTGCGGCGCTCGGTGC |
| TCGAGAGGCTCGGCGGCTTCGACGGCACCGCGCGCCTGGGGGCCGACACC |
| GACTTCCACCTGCGGGCCGCCCGCCTGTACCGGCTGCGCAGTGTGCGCAA |
| GGTGCTCTACCGGTACCGGATCTGGCCCAAGTCGCTCACCCAGGCGCCGG |
| ACACCGGGTTCGGGTCCGCGGAGCGCCGGGCCTACACCGAGGCGATGACC |
| GCGCAGGAGGAGCGGCGGCGACGGGCGCGGACCCGTGAGGAGCTGCTGCC |
| GCTGCTGGTCGCCCCGCCCAACGACGTCGACTTCACCCTGACCCGGGTCG |
| ACCTCGACTAG (SEQ ID NO: 9) |
| TABLE 26 |
| Amino Acid Sequence of moeGT2 |
| LTHEVTPRGGPEGDAMVTAGPAGAAVTVVLPHYDCAAYLGAAVGSVLSQD |
| RPDLRLTVVDECSPEEKWARALHPYAGDPRLTVVRTSRNVGHLRIKNKVL |
| ESVDTPYVAFQDADDISLPGRLRHQLALLESGGADLVGCAYSYIDEAGRT |
| TGHRRMPRNGNLWMRLGRTTVLLHPSSVVRRSVLERLGGFDGTARLGADT |
| DFHLRAARLYRLRSVRKVLYRYRIWPKSLTQAPDTGFGSAERRAYTEAMT |
| AQEERRRRARTREELLPLLVAPPNDVDFTLTRV |
| DLD (SEQ ID NO: 32) |
| TABLE 27 |
| Sequence Homology of moeGT2 |
| gb|AAU93096.1|glycosyl transferase, group 2 family protein |
| [Methylococcus capsulatus str. Bath] |
| Length = 367 |
| Score = 104 bits (260), Expect = 4e−21 |
| Identities = 80/228 (35%), Positives = 117/228 (51%), Gaps = 7/228 (3%) |
| SEQ ID NO: 132 SEQ ID NO: 133 | |||
| Query | 7 | PRGGPEGDAMVTAGPAGAA--VTVVLPHYDCAAYLGAAVGSVLSQDRPDLRLTVVDECSP | 64 |
| | | | + | | | ||+++| |+ || ||+ |+| | | | ++|+ | | |||
| Sbjct | 11 | PHHVPHRDMTHHSRPPGHAPRVTILMPVYNGEKYLAAAMESILDQTFRDFILLIIDDGSS | 70 |
| SEQ ID NO: 242 | |||
| Query | 65 | EEKWARALHPYAGDPRLTVVRTSRNVGHLRIKNKVLESVDTPYVAFQDADDISLPGRLRH | 124 |
| + | | ||||+ | | +|+| ++ |+ |+ | | +|| | |||+|| || | |||
| Sbjct | 71 | DSSLAIARS--FGDPRVQVERNPKNLGLVKTLNRGLDLVQTEFVARMDCDDIALPDRLEK | 128 |
| SEQ ID NO: 134 | |||
| SEQ ID NO: 135 | |||
| Query | 125 | QLALL-ESGGADLVGCAYSYIDEAGRTTGHRRMPRNGNLWMRLGRTTVLLHPSSVVRRSV | 183 |
| |+| | |+ + | || |+ | | | |+ + | | || | +|| | | |||
| Sbjct | 129 | QIAFLDENPDIGMCGTAYELFHESLRQT-IRPPCRHEEIVYGLLDDNVFLHSSVIVRMEV | 187 |
| SEQ ID NO: 136 | |||
| SEQ ID NO: 137 | |||
| Query | 184 | LERLG-GFDGTARLGADTDFHLRAARLYRLRSVRKVLYRYRIWPKSLT | 230 |
| | | | + || | + | || + ++ +|| ||| |++++ | |||
| Sbjct | 188 | LNRHGLRYREDYRLAEDYELWARLARYTHIGNLPQVLVRYRSHPENVS | 235 |
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeGT2 gene is a glycosyltransferase that attaches a sugar moiety (e.g., glucuronic acid (GalA)) to the Moe intermediate compound 14 or 15 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 16 or 17, respectively, as shown in FIGS. 4A-4D.
The product of the moeGT3 gene is similar to family-2 GTs involved in antibiotic production (32% identity and 45% similarity to AprG1 GT from S. tenebrarius apramycin gene biosynthetic cluster) (Du 2004), and biofilm and antigen biosynthesis (23% identity and 44% similarity) (Kaplan 2004, Wang 2004). It also has homology to putative GTs involved in cell wall biogenesis. The moeGT3 gene includes a putative conserved GT domain (COG1216) which is present in many GTs. The nucleotide and polypeptide sequences are shown in Tables 28 and 29, respectively. A sequence alignment between moeGT3 and the closest homolog identified in the BLAST search is shown in Table 30.
| TABLE 28 |
| DNA Sequence of moeGT3 |
| GTGGCCGTCCTCCGCGGTGACGACGAGGCGCTCCCCCACTGGCTGTGGCA |
| CCTGGCGCGGGCGGTCTGGTACGGCGGCGGGGACGGCACCGGGCCGGTCG |
| GCCTGGTGCAGTGCGGCGCCCTGCGGCTGAGGGACGACGGCCTGGTGGAC |
| GGGTTCGCCCTGCCGCCCGCGTCCCCGCGGACCCGGCCCTCCCCCTCGGA |
| CCTCCTCGAGGGCGCCTACGCGGTGCGGCGCGAACTGCTGGACGCGGACG |
| GCGGTACGGCGCCCTGGGTCGCCCTGCCCATGCCGCTGGTCCGCCGCCGG |
| TCCGGCGGCGCCGGGGACCCGGCCGCGGTCCTGGCCCCCGGGACGCGCGT |
| CGCGCGACGCACCCGCCTGGTCCGGCACGGGTACCGGCCGCCCGCCGCGA |
| GGCCGCGGAACGGGAGCACTCCCCGGCTGGTGTCGGTGGTCGTCCCGGTG |
| CGCAACGGCGCCCGCACGCTCGCCGCCCAGCTGACCGCCCTGGCCCGGCA |
| GACCGGAGCCGTCGCCTACGAGGTGCTGGTCGTCGACAACGGCTCGACGG |
| ACACCACCCGCGAGGTCGCCGAACGGGCCCGCGCCGAGCTGCCGGACCTG |
| CGGATCGTGGACGCGTCCGACCGTGCCGGTGAGAGCTGTGCCCGCAACCG |
| GGGAATCGCCGCGGCGCGCGGCGACTTCGTCGCGTTCTGCGACGCGGACG |
| ACGTCGCCGACACCGGCTGGCTGGCCGCGATGGCCCAGGCGGCCAAGGAG |
| GCCGATCTGGTGGGAGGCGGACTGGAGACCTCCGTGCTCAGTCCCGGCCG |
| CGTCGACGAGCAGCCCCTGCCGATGGACGCCCAGACCGATTTCCTGCCGT |
| TCGCCCGGGGGGCGAACTGCGGTGCCTGGAAGGACGTCCTGACCGCGCTG |
| GGCGGCTGGGACGAGCGCTACCGGGGCGGCGGGGAGGACATGGACCTCTC |
| CTGGCGCGCCCAGCTCTGCGGTTACCTCGTCCGCTACGCGGACGACGCCC |
| GGATGCACTACCGGTTGCGGGACGGACTGCCGGCGCTGGCACGGCAGAAG |
| TGGAACTACGGCCGTTCCGGGGCCCAGTTGTACGCCGCGTACCGGCGCGC |
| CGGGTTCGAACGGCGCGACGGCCGGGTGGTCGTCAGGAACTGGTGCTGGC |
| TGCTGCTGCACGTTCCGAACCTGGTCCGGTCCACCGGACCCTGCGGCCAC |
| GCTGAGTCCGCTACGCGCCCGGCTGGCCGGTTTCCTGGTTTG |
| TGA (SEQ ID NO: 10) |
| TABLE 29 |
| Amino Acid Sequence of moeGT3 |
| VAVLRGDDEALPHWLWHLARAVWYGGGDGTGPVGLVQCGALRLRDDGLVD |
| GFALPPASPRTRPSPSDLLEGAYAVRRELLDADGGTAPWVALPMPLVRRR |
| SGGAGDPAAVLAPGTRVARRTRLVRHGYRPPAARPRNGSTPRLVSVVVPV |
| RNGARTLAAQLTALARQTGAVAYEVLVVDNGSTDTTREVAERARAELPDL |
| RIVDASDRAGESCARNRGIAAARGDFVAFCDADDVADTGWLAAMAQAAKE |
| ADLVGGGLETSVLSPGRVDEQPLPMDAQTDFLPFARGANCGAWKDVLTAL |
| GGWDERYRGGGEDMDLSWRAQLCGYLVRYADDARMHYRLRDGLPALARQK |
| WNYGRSGAQLYAAYRRAGFERRDGRVVVRNWCWLLLHVPNLVRSTGPCGH |
| AESATRPAGRFPGL (SEQ ID NO: 33) |
| TABLE 30 |
| Sequence Homology of moeGT3 |
| ref|ZP_10616987.1| Glycosyl transferase, family 2 [Kineococcus radiotolerans |
| SRS30216] |
| Length = 289 |
| Score = 197 bits (500), Expect = 1e−48 |
| Identities = 122/277 (44%), Positives = 156/277 (56%), Gaps = 8/277 (2%) |
| SEQ ID NO: 138 | |||
| Query | 144 | VSVVVPVRNGARTLAAQLTALARQTGAVAYEVLVVDNGSTDTTREVAERARAELPD-LRI | 202 |
| ||||+| | | | ||| ||| |+ +||+| |||||| | | +| || | |||
| Sbjct | 5 | VSVVIPCFNATRDLPAQLEALAGQSTVCTFEVVVSDNGSTDGLAEFVEEWSRRVPFMLRR | 64 |
| SEQ ID NO: 139 | |||
| SEQ ID NO: 243 | |||
| Query | 203 | VDASDRAGESCARNRGIAAARGDFVAFCDADDVADTGWLAAMAQAAKEADLVGGGL---- | 258 |
| |||| | | + ||| | || | + |||||| ||+ |||+| ++|||||| | | |||
| Sbjct | 65 | VDASARRGVAHARNAGCRAALADVILVCDADDVVGVGWVDAMARALEQADLVGGTLVHGH | 124 |
| SEQ ID NO: 140 | |||
| Query | 259 | -ETSVLSPGRVDEQPLPMDAQTDFLPFARGANCGAWKDVLTALGGWDERYRGGGEDMDLS | 317 |
| |+++ | | + + ||+| ||| | ++| ||||||| + ||+|++ | | |||
| Sbjct | 125 | LNTALVQQWRPTSPPGVLPTKLSHLPYAVGANVGLRREVFDALGGWDEGFVAGGDDVEFS | 184 |
| Query | 318 | WRAQLCGYLVRYADDARMHYRLRDGLPALARQKWNYGRSGAQLYAAYRRAGFERRDGRVV | 377 |
| |||| |+ +| | || + ||+| | | +| + | || | | +| || || | + | |||
| Sbjct | 185 | WRAQHAGFCLRSAPDAVIAYRMRTTLSANVKQSYFYARSDALLMRTFRSAGVPRRGLRPL | 244 |
| SEQ ID NO: 141 | |||
| Query | 378 | VRNWCWLLLHVPNLVRSTGPCGH-AESATRPAGRFPG | 413 |
| + ||+ +|| | | | | |||| | | |||
| Sbjct | 245 | ITESKWLVRNVPR-TREPGFRGQWLRRAAMLAGRFVG | 280 |
| SEQ ID NO: 142 | |||
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeGT3 gene attaches is a glycosyltransferase that attaches a sugar moiety (e.g., glucose (Glc)) to the Moe intermediate compound 4, 12 or 13 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 5, 14 or 15, respectively, as shown in FIGS. 4A-4D.
Gene moeGT4 encodes putative 427 amino acid protein which N-terminal portion shows moderate homology (27% identity and 38% similarity) to putative family 2 GT from Mycobacterium vahbaalenii PYR-1. The nucleotide and polypeptide sequences are shown in Tables 31 and 32, respectively. A sequence alignment between moeGT4 and the closest homolog identified in the BLAST search is shown in Table 33. CDD search failed to locate conserved domain(s) within moeGT4. However, more careful inspection of moeGT4 sequence using the HHpred program (at ExPaSy proteomics server) showed that the C-terminus of moeGT4 exhibits a low degree of homology to chitin synthase and GT 2 conserved domains (accession numbers pfam03142 and COG1216, respectively).
| TABLE 31 |
| DNA Sequence of moeGT4. |
| GTGACTTCTGAGCCCGCCGCCCCGGCCGTCCCGCACCCGCCGGTGCGTCC |
| GGGGCCGCCGGTCCGTCTCAACCGGCCGCTGGCGCGGCGCAGGCGGCGGC |
| CGGCCGGGGAGGGGTTCGTGACGCACCACCTGCGGAGCACCATGGCCCGC |
| GGGTTCCGCCCCCCGGAGTCCTGGGAGGTCCCCGTCCGGCACGTCCTGCC |
| CGGTCTGCCGGCCGACGGGACTCCGCGCGCCGAGGAGGCCGCTCAGGCGC |
| TGCGCACGCCCGCCGGGCGGCCGGGCATCGCCCTCGTCGTGCCGACCTAC |
| GTCTCCCGGGTGAGCCTGGCGCGGCAGCGGGAGTGGTTCGACGCGCTGCT |
| GGACCAGGCGGCCGCGGTGACGCGGGACCACCCCCTGGTGCCCCTGGTGC |
| TGTTCGTCGGCATGCAGTGGTCGTCGGCCGAGGAGGAGCGGGAGGCGCTG |
| CGGCGCCTGCGTGTGCTGCTGGACGACGCCCGCACCCGGCTGCCCGGACT |
| GCGGATCTGCGGTCTCGCGCTGCCCGGGCCGGGCAAACCCCGCACCCTCA |
| ACGGGGCGATCGCCGTCGCCGAGCTCCTCGGCTGTGCGGGCGTCGGGTGG |
| ACCGACGACGACGTGACCCTGGAGGAGGACTGCCTGTCCCGGCTGGTGCG |
| GGACTTCCTGGCGGCGGGCTGCCGCGGGGCGGTGGGCGCGACCAAGGTTG |
| CGCACACCCATGAGTACGCCACCTCCCGGCTGCTGTCCCGGGCCAAGGCG |
| ATCGCCGCCCCGGCCACGAACTACCCGCACGGCTGCTGCATCCTGGTGGC |
| CACCGACGTGGTGGCCGGTGGTCTGCCGGGACGCTACGTATCCGACGACG |
| GCTACGTGTGCTTCCGCCTCCTCGACCCCGCGCTGCCCGACCCGCTGGCC |
| CGGCTGCGGCTGGTTCCGGACGCCCGGTGCCACTACTACGTGGCGGGGCC |
| GGCCGGCGAGACCCGCCGCAGGATCCGCAGGCTGCTGCTCAACCACCTCG |
| TCGACCTCGCCGACTGGCCCCTGCCGGTGGTCCGTCACTACTTCCGCCAC |
| GTCCTGTTCGGCGGCATGTGGCCGCTGACCGGCTTCGACTCCTCCCGCGG |
| TGCCCGCCGCGGTGTGCAGAAGGCGCTCATCAAGTGGCTCTACTTCGCCT |
| GGTTCGCGGGCATCGGGGGCGAACTCTACGTGCGCGGGCTGTCCGGCAGG |
| CCACTGCGCCGCATCGAGTGGGCTCCCTACTCGGACATCCGCAGGCTCAC |
| TCCGTCGTCCTCACCCACGCGTCAGGAGAGCTGA (SEQ ID NO: 11) |
| TABLE 32 |
| Amino Acid Sequence of moeGT4 |
| VTSEPAAPAVPHPPVRPGPPVRLNRPLARRRRRPAGEFVTHHLRSTMARG |
| FRPPESWEVPVRHVLPGLPADGTPRAEEAAQALRTPAGRPGIALVVPTYV |
| SRVSLARQREWFDALLDQAAAVTRDHPLVPLVLFVGMQWSSAEEEREALR |
| RLRVLLDDARTRLPGLRICGLALPGPGKPRTLNGAIAVAELLGCAGVGWT |
| DDDVTLEEDCLSRLVRDFLAAGCRGAVGATKVAHTHEYATSRLLSRAKAI |
| AAPATNYPHGCCILVATDVVAGGLPGRYVSDDGYVCFRLLDPALPDPLAR |
| LRLVPDARCHYYVAGPAGETRRRIRRLLLNHLVDLADWPLPVVRHYFRHV |
| LFGGMWPLTGFDSSRGARRGVQKALIKWLYFAWFAGIGGELYVRGLSGRP |
| LRRIEWAPYSDIRRLTPSSSPTRQES (SEQ ID NO: 34 |
| TABLE 33 |
| Sequence Homology of moeGT4 |
| gb|EAS23724.1| Glycosyl transferase, family 2 [Mycobacterium vanbaalenii PYR-1] |
| Length = 426 |
| Score = 35.8 bits (81), Expect = 3.9 |
| Identities = 49/181 (27%), Positives = 69/181 (38%), Gaps = 29/181 (16%) |
| SEQ ID NO: 143 | |||
| Query | 42 | HHLRSTMARGFRPPESWEVPVRHVLPGLPADGTPRAEEAAQALRTPAGRPGIALVVPTYV | 101 |
| || | + +| ||||| | ||| | +| | | ++| | | |||
| Sbjct | 52 | HHARVLVRHQGQPVAFVEVPVRDALIRLPACPLPEDLDAGQPAR----------LMPISV | 101 |
| SEQ ID NO: 244 SEQ ID NO: 144 | |||
| Query | 102 | SRVSLARQREWFDALLDQAAAVTRDHPLVPLVLFVGMQWSSAEEEREALRRLRVLLDDAR | 161 |
| + | + ||| + ++ |+| +|+ +| + | ||| | |||
| Sbjct | 102 | VLCTRDRPDQLADAL---KSILSLDYPEFEVVVV------DNAARTDATAGVVAQLGDAR | 152 |
| SEQ ID NO: 145 SEQ ID NO: 146 | |||
| Query | 162 | TRLPGLRICGLALPGPGKPRTLNGAIAVAELLGCAGVGWTDDDVTLEEDCLSRLVRDFLA | 221 |
| | +| | || | + | | +||||| ++ | | | | | |||
| Sbjct | 153 | VR-------RVAEPIPGLSTARNTGLRHA---AHPVVAFTDDDVVVDRQWLRGLARGFAR | 202 |
| SEQ ID NO: 147 SEQ ID NO: 148 | |||
| Query | 222 | A | 222 |
| | | |||
| Sbjct | 203 | A | 203 |
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeGT4 gene is a glycosyltransferase that attaches sugar moiety (e.g., N-acetylglucosamine (GlcNac)) to the Moe intermediate compound 2 or 3 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 4 as shown in FIGS. 4A-4D.
The 312 amino acid protein encoded by the moeGT5 gene is homologous to the central part of moeGT4 (45% identity and 59.1% similarity). HHpred results suggested that an incomplete COG1216 domain is also present in moeGT5. The nucleotide and polypeptide sequences of moeGT5 are shown in Tables 34 and 35, respectively.
| TABLE 34 |
| DNA Sequence of moeGT5 |
| GTGCTGCGCCGTCTGGCCGAGGTGCGGGAAGCGCACCCGTCCCTGCCGCT |
| GACCGTCTGGGTGGGCATGCAGTACGGCCCCGGGGAGGACGAGGAGGCGC |
| TGCGCAGGCTGCGCCGGCTGTGCGCCCCGGTGCCCGGGGGCCCGGCCCTC |
| ACCGTGGTCGGCCTGGCCCTGCCCGGGCCGGGCAAGCTCCGCACGGTGAG |
| CACGGTCCTGCGGCTCTCCGAGGACCTCGGCTACGCCGGCTGGCTCTGGA |
| CGGACGACGACATCGAGATCGCCCCCCACTGCCTCGCCCTGCTGGTCTCC |
| CGTTTCCGGGAGCGGGGGGAGCGGGGCGCGGTCGGGGCGCATTCGGTCGC |
| GCTGGCCAGGGAGACGGTCACCTCACAGGCCATGGACCGGGTCTCCGGGG |
| TCACCGCCCCGCCGAAGGCCTGCCCGGCGGCGGCCTGCCTGGTCGTCGCG |
| ACGGACGTGCTGGGCACCGGCATTCCGGTCAGGCGCCTGACCGACGACGG |
| GTACGTGGTGTTCGAACTGCTCGACGCCGGGGCGCCCGATCCGCTGCACG |
| ACCTGGAGGTGCTGCCCGAGGCCCGGATCAGCTTCTACCGCGTCAGCCGC |
| ACCCACGACACGTTCCAGCGCCTGCGCCGCTCCCTCTACAGCCATGTGAC |
| CTGCGTCGCCGACTATCCCTGGCCCACCGCGCGGGTCTACCTCACCCGGG |
| TCCTCTTCCACGGTCTGTGGCCGCTCGCGGCGTGGGACGGCAGCCGGGGG |
| CCGGTGCACGGGCTGCAGCGCTGGCTGGTCAAGGGCCTGCACTTCACCTG |
| GTTCTGCGGGGTGGCCGGCTCGCTGGCGGTCCGGGGCGCGGTGGGACGGC |
| CCCTTCGCCGGGTGGCGTGGGGCGACGAGGGGGACTTCCGCAGCCCCACC |
| GTCGAGGAGCCCGCCGCGGGAGCGGCCGCCGGGCGCTGA |
| (SEQ ID NO: 12) |
| TABLE 35 |
| Amino Acid Sequence of moeGT5 |
| VLRRLAEVREAHPSLPLTVWVGMQYGPGEDEEALRRLRRLCAPVPGGPAL |
| TVVGLALPGPGKLRTVSTVLRLSEDLGYAGWLWTDDDIEIAPHCLALLVS |
| RFRERGERGAVGAHSVALARETVTSQAMDRVSGVTAPPKACPAAACLVVA |
| TDVLGTGIPVRRLTDDGYVVFELLDAGAPDPLHDLEVLPEARISFYRVSR |
| THDTFQRLRRSLYSHVTCVADYPWPTARVYLTRVLFHGLWPLAAWDGSRG |
| PVHGLQRWLVKGLHFTWFCGVAGSLAVRGAVGRPLRRVAWGDEGDFRSPT |
| VEEPAAGAAAGR (SEQ ID NO: 35) |
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeGT5 gene is a glycosyltransferase that attaches a sugar moiety (e.g., N-acetylglucosamine) (GlcNac)) or chinovosamine (Ch) moiety to the Moe intermediate compound 4 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 6 or 7, respectively, as shown in FIGS. 4A-4D. Further, based on the studies of the present invention, it is propose that the polypeptide encoded by the moeGT5 gene is a glycosyltransferase that attaches a sugar moiety (e.g., N-acetylglucosamine) (GlcNac)) or chinovosamine (Ch) moiety to the Moe intermediate compound 11 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 14 or 15, respectively, as shown in FIGS. 4A-4D.
C. Sugar Tailoring Genes
Seven genes were identified in cluster 1 that fit this activity profile: moeF5, moeH5, moeK5, moeM5, moeS5, moeR5 and moeE5.
The moeF5 and moeH5 genes share significant homology at the nucleotide sequence level, suggesting that the pair arose via a gene duplication event. The proteins encoded by these genes resemble a large family of ATP-dependent amidotransferases that form amides from carboxylic acids, but neither protein appeared fully functional based on sequence analysis. Therefore, we previously speculated that carboxamidation of unit F resulted from the activity of a MoeFSMoeHS heterodimer, with MoeFS generating ammonia from glutamine in an ATP-dependent manner and MoeH5 acting as an amidotransferase (Ostash 2007).
1. moeF5
The product of moeF5 gene resembles putative and known asparagine synthase B related enzymes from various bacteria (36% identity and 46% similarity). The nucleotide and polypeptide sequences are shown in Tables 36 and 37, respectively. A sequence alignment between moeF5 and its closest homolog is shown in Table 38.
| TABLE 36 |
| DNA Sequence of moeF5. |
| ATGTGCGGCTTCGTCGGATTCAGTGACGCCGGCGCCGGGCAGGAGGACGC |
| CCGTGTCACGGCCGAGCGCATGCTCGCCGCCGTGGCGCACCGCGGCCCCG |
| ACGGCTCGGACTGGTGCCACCACCGGGGCGTCACCCTCGCGCACTGCGCC |
| CTGACCTTCACCGATCCGGACCACGGCGCGCAGCCGTTCGTCTCCGCGTC |
| GGGAGCCACCGCCGTGGTGTTCAACGGCGAGCTCTACAACCACGCCGTGC |
| TGGGCGACGGGGCGTTGCCCTGCGCACCCGGAGGCGACACAGAAGTTCCT |
| GGTGGAACTCTACGAGTTGCTGGGCATGCGGATGCTCGACCGGCTGCGGG |
| GCATGTTCGCCTTCGCGCTGCAGGACGCCCGCACCGGCACCACGGTGCTG |
| GCCGCGACCGATGGGGAAGAGCCCCTCTACTAACACCCGCGTGCGAGACG |
| GACATCGCTTTCGCGTCGGAACTCACGTCTCTGCTGCGGCACCCCGCCGC |
| GCCGCGCACACCGGAGGTGCGGGCGCTCGCCGACTACCTGGTGCTCCAGG |
| CGTTCTGCGCCCCCGCCTCGGCCGTGTCGGGGGTGTGCAAGGTGCGCCCC |
| GGCAGCTACGTGACCCACCGGCACGGCGCGTTGGACGAGACCGAGTTCTG |
| GCGGCCCCGCCTGACCCCCGACCGGGGGGCGGGCCGCGGCCCCGGACGGC |
| GGGAGGCCGCGCGGCGGTTCGAGGAGCTCTTCCGCGCCGCGGTCGCCCGC |
| CGGATGACCAGCACCGACCGCCGCCTCGGCGTACTGCTCAGCGGCGGCCT |
| GGACTCCAGCGCGGTCGCCGCGGTGGCCCAGCAGCTCCTGCCGGGACGGC |
| CGGTGCCCACCTTCAGCGCGGGGTTCGCGGACCCGGACTTCGACGAGAGC |
| GACCACGCACGGGCGGTGGCGCGCCACCTCGGCACCGAGCACCATGTGGT |
| GCGGATCGGCGGGGCCGACCTCGCCGGTGTGGTGGAGTCCGAACTCGCCG |
| TGGCCGACGAGCCGTTGGCCGATCCCTCCCTGCTGCCCACACGTCTGGTC |
| TGCCGGGCGGCGCGCGAGCACGTCCGCGGCGTGCTCACCGGTGACGGCGC |
| GGACGAACTGCTCCTGGGCTACCGCTACTTCCAGGCCGAGCGGGCGATCG |
| AGCTGCTGCTGCGCGTGCTGCCGGCCCCCCGGCTGGAGGCCCTCGTCCGG |
| CTGCTGGTGCGCCGGCTGCCGGCCCGTTCCGGCAACCTCCCCGTGACCCA |
| CGCCCTCGGTCTGCTGGCCAAGGGCCTGCGCGCGGCACCGGAGCACCGGT |
| TCTACCTCTCGACGGCGCCCTTCGGCCCGGGCGAGCTGCCACGGCTGCTC |
| ACCCCCGAGGCCGGGGCCGAACTGACCGGGCACGACCCGTTCACCGAGGT |
| GTCGCGCCTCCTGCGGGGACAGCCGGGCCTGACCGGTGTCCAGCGCAGCC |
| AGCTCGCCGTGGTGACCCACTTCCTGCGGGACGTGATCCTCACCAAGACG |
| GACCGGGGCGGCATGCGCAGCTCCCTCGAGCTGCGTTCCCCCTTTCTCGA |
| CCTGGACCTGGTCGAGTACGGCAACTCCCTGCCCACCGGCCTGAAGCTGC |
| ACCGGTTCACCGGCAAGTACCTGCTGCGGCAGGTCGCCGCCGGCTGGCTG |
| CCCCCTTCCGTCGTCCAGCGGACGAAGCTGGGTTTCCGCGCGCCGGTGGC |
| GGCCCTGCTCCGCGGCGAGCTGCGGCCCCTGCTCCTGGACACCCTCTCCC |
| CGTCGTCCCTGCGCCGCGGCGGCCTGTTCGACACCGGGGCGGTGCGCCTG |
| CTGATCGACGACCACCTCGGCGGCCGGCGCGACACCTCCCGCAAGCTGTG |
| GGCGCTGCTGGTCTACCAGCTCTGGTTCGAGAGCCTGACGGCCGGACCCC |
| GCGCCCTCGAGTCCCCCGCGTACCCGGCCCTCTCCTAG |
| (SEQ ID NO: 13) |
| TABLE 37 |
| Amino Acid Sequence of moeF5 |
| MCGFVGFSDAGAGQEDARVTAERMLAAVAHRGPDGSDWCHHRGVTLAHCA |
| LTFTDPDHGAQPFVSASGATAVVFNGELYNHAVLGDGALPCAPGGDTEVP |
| GGTLRVAGHADARPAAGHVRLRAAGRPHRHHGAGRDRWGRAPLLTPACET |
| DIAFASELTSLLRHPAAPRTPEVRALADYLVLQAFCAPASAVSGVCKVRP |
| GSYVTHRHGALDETEFWRPRLTPDRGAGRGPGRREAARRFEELFRAAVAR |
| RMTSTDRRLGVLLSGGLDSSAVAAVAQQLLPGRPVPTFSAGFADPDFDES |
| DHARAVARHLGTEHHVVRIGGADLAGVVESELAVADEPLADPSLLPTRLV |
| CRAAREHVRGVLTGDGADELLLGYRYFQAERAIELLLRVLPAPRLEALVR |
| LLVRRLPARSGNLPVTHALGLLAKGLRAAPEHRFYLSTAPFGPGELPRLL |
| TPEAGAELTGHDPFTEVSRLLRGQPGLTGVQRSQLAVVTHFLRDVILTKT |
| DRGGMRSSLELRSPFLDLDLVEYGNSLPTGLKLHRFTGKYLLRQVAAGWL |
| PPSVVQRTKLGFRAPVAALLRGELRPLLLDTLSPSSLRRGGLFDTGAVRL |
| LIDDHLGGRRDTSRKLWALLVYQLWFESLTAGPRALESPAYPALS |
| (SEQ ID NO: 36) |
| TABLE 38 |
| Sequence Homology of moeF5 |
| gi|20560076|gb|AAM27821.1| ORF_10; similar to Asparagine synthase [Pseudomonas |
| aeruginosa] |
| gi|6690135|gb|AAF24002.1| WbpS [Pseudomonas aeruginosa] |
| Length = 627 |
| Score = 198 bits (503), Expect = 1e−48 |
| Identities = 193/645 (29%), Positives = 279/645 (43%), Gaps = 35/645 (5%) |
| Frame = +1 |
| SEQ ID NO:149 SEQ ID NO:150 SEQ ID NO:151 | |||
| Query | 286 | MCGFVGFSD-AGAGQEDARVTAERMLAAVAHRGPDGSDWCHH-RGVTLAHCALTFTD-P | 453 |
| ||| || + | | | +| ||+ ||||| | + | | | | + | |||
| Sbjct | 1 | MCGIAGFWNITGTLLGDNARVARQMAAAIHHRGPDESGIWYEAPRAPILVHARLAVLELS | 60 |
| SEQ ID NO: 152 | |||
| SEQ ID NO: 245 SEQ ID NO:153 SEQ ID NO: 154 | |||
| Query | 454 | DHGAQPFVSASGATAVVFNGELYNH----AVLGDGALPCA--PGGDTEVPGGTLRVAG-H | 612 |
| |+|| | | +++|||+||| | | + + + | ||| | | |||
| Sbjct | 61 | PAGSQPMHSDCGRYVLIYNGEIYNHLALRARLSEAGVTHSWRGGSDTETLLACFAQWGVE | 120 |
| SEQ ID NO: 155 | |||
| Query | 613 | ADARPAAGHVRLRAAGRPHRHHGAGRDRWGRAPLLTPACETDIAFASELTSLLRHPAAPR | 792 |
| + + | | | + ||| | || + ||||| +| || | |||
| Sbjct | 121 | STLKLTVGMFALALWDRQEKTITLARDRMGEKPLYWGWQNGVLFFASELKALKEHPLFRG | 180 |
| SEQ ID NO: 156 | |||
| Query | 793 | TPEVRALADYLVLQAFCAPASAVSGVCKVRPGSYVTHRHGALDET----EFWRPRLTPDr | 960 |
| + ||| +| || | |+ |+| |||+ +|+|| +| + | |||
| Sbjct | 181 | DIDRDALALFLRYGYVPAPYSIYKGIGKLRAGSYLVLSERSLNETCEPAAYWSANAAIEE | 240 |
| Query | 961 | gagrgpgrreaarrfeelfraavarrMTSTDRRlgvllsggldssavaavaQQLLPGRPV | 1140 |
| +| + + | |+ | ||+ | |||
| Sbjct | 241 | ALSNPFQGTDAEAVDLLESQLRTSISDQMVSDVPLGAFLSGGVDSSTVVALMQQQSSRPI | 300 |
| Query | 1141 | PTFSAGFADPDFDESDHARAVARHLGTEHHVVRIGGADLAGVVESELAVADEPLADPSLL | 1320 |
| ||| || +| +||+ +|+||| |+||+| + + | |+ | + || | | + | |||
| Sbjct | 301 | RTFSIGFDEPGYDEAVYAKAVAEHIGTDHTELYVNSKDALDVIPSLPKIYCEPFGDSSQI | 360 |
| SEQ ID NO: 157 | |||
| Query | 1321 | PTRLVCRAAREHVRGVLTGDGADELLLGYRYFQ-AERAIELLLRVlpaprlealvrllvr | 1497 |
| || +| ||+ | |+||| ||| || +| | +| | + | | | |||
| Sbjct | 361 | PTLIVSGLARQQVTVALSGDGGDELFGGYNPYQFTPRVWRMLERFPHSMRRFASAFAQDL | 420 |
| Query | 1498 | rlparSGNLPVTHalgllakglraaPEHRFYLSTAPFGPGELPRLLTPEAGAELTGHDPF | 1677 |
| || + | | | || + + | | + ||+ || | |||
| Sbjct | 421 | PLPEKLGKL--------RDVFASRTAEELFYRLNSHWRNHEYPVI-----GAQ-GHTAL | 465 |
| SEQ ID NOS: 158 159 | |||
| SEQ ID NO: 254 | |||
| Query | 1678 | TEVSRLLRGQPGLTGVQRSQLAV-VTHFLRDVILTKTDRGGMRSSLELRSPFLDLDLVEY | 1854 |
| + | + | +|+ | ++ | || | || | +||| | | +| + | | |||
| Sbjct | 466 | LDTPERW---PRVDSFQHWMMAMDVQGYMPDDILVKVDRAAMANSLETRVPLIDHRVFEL | 522 |
| SEQ ID NO: 160 | |||
| Query | 1855 | GNSLPTGLKLHRFTGKYLLRQVAAGWLPPSVVQRTKLGFRAPVAAllrgelrpllldtls | 2034 |
| +| +|+ ||+|||+| + +++| | || ||+ ||| |+ | | |||
| Sbjct | 523 | AWRMPLHMKIRNGKGKWLLREVLYRHVSRELIERPKKGFSVPVSDWLRGPLKEWAESLLD | 582 |
| Query | 2035 | psslrrGGLFDTGAVRLLIDDHLGGRRDTSRKLWALLVYQLWFES | 2169 |
| |++ | |+ +| + +||| |||| ||+||++|++| | || | |||
| Sbjct | 583 | ERRLOQEGYLDSRLIRRIWNDHLAGRRDHSRRLWSVLMFQAWLES | 627 |
These synthases belong to the huge glutamine amidotransferase family whose members catalyze ATP-dependent amide nitrogen transfer from glutamine to acceptor substrates in different biosynthetic pathways (Zalkin 1998). Particularly, moeF5 appears similar to the WbpS proteins from Pseudomonas aeruginosa O4 and Shigella dysenteriae type 7 which are encoded by genes grouped in clusters for the biosynthesis of O antigens (29% identity and 43% similarity) (Feng 2004, Belanger 1999). The WbpS proteins appear to be responsible for carboxyl-amidation of deoxysugar moieties (Knirel 1988) during antigen biosynthesis in the aforementioned strains. A moeF5 CDD search revealed the presence of a glutaminase domain (AsnB; cd00712) and an interrupted asparagine synthase domain (Asn synthase BC; cd01991) in the N- and C-termini, respectively.
Strain ΔmoeF5 accumulated compound 1 (Table 21), which has a mass 1 Da higher than that of the monosaccharide moe A precursor 2 accumulated by the ΔmoeGT4 strain, consistent with the presence of a carboxyl moiety in unit F of 1 instead of the carboxamide group in 2/3 (FIGS. 4A-D). Our data agree with the prediction that the moeF5 gene is involved in F ring carboxamidation. We could not detect the formation of methylated monosaccharide precursors or of any larger moe A intermediates, implying that the absence of the carboxamide moiety abolishes unit F methylation and subsequent glycosylations. Therefore, MoeFS-catalyzed carboxamidation occurs prior to, and is required for, other modifications of 1 (FIGS. 4A-4D). That is, based on the studies of the present invention, it is propose that the polypeptide encoded by the moeF5 gene is a Unit F amidotransferase which participates in the conversion of Moe intermediate compound 1 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 2 or 3, respectively, as shown in FIGS. 4A-4D.
2. moeH5
The moeF5 translation product also displays local homology (27.1% identity and 34% similarity) to moeH5, another AsnB-like protein. The nucleotide and polypeptide sequences are shown in Tables 39 and 40, respectively. A sequence alignment between moeH5 and the closest homolog identified in the BLAST search is shown in Table 41. MoeH5 shows 32% identity, and 48% similarity to a putative amidotransferase of Azoarcus sp. EbN1. MoeH5 also possesses a truncated asparaginase domain and an entire amidotransferase domain.
| TABLE 39 |
| DNA Sequence of moeH5. |
| ATGACGGTCCGCCGCCCGGCCGCGTCCGCCCCCCGCGTCCTCCTGACCGC |
| GGGCCCCGACGGGGTGCGCGTGGAGGGCGACGGGGAGGCGCGCCTCGGGC |
| ACCCCCTCACCGGTGACCACCTGGACCCGGGCCCGCCGGCCGAAGGCGTC |
| TTCGCCGGGTGGAGGTGGGACGGCGAGCGCCTGGTGGCCCGCAACGACCG |
| CTACGGCGTCTGCCCCCTCTTCTACCGGGCCGGCGGCGGCTCACTCGCGC |
| TCTCCCCCGACCCGCTCGCCCTGCTGCCGGAGGACGGGCCCGTCGAGCTG |
| GACCACGACGCGCTCGCCGTCTTCCTGCGGACGGGGTTCTTCCTCGCCGA |
| GGACACGGCCTTCGCACAGGTCCGCGCACTGCCCCCGGCGGCCACGCTCA |
| CCTGGGACACCGGCGGGCTGCGGCTGCGGTCCGACGGGCCGCCGCGCCCC |
| GGGGCCGCCGCGATGACCGAGGCGCAGGCGGTCGACGGCTTCGTCGACCT |
| GTTCCGCGCCTCGGTGGCCCGCCGGCTGCCCGGCGAACCGTACGACCTGC |
| CGCTCAGCGGCGGCCGGGACTCGCGGCACATCCTGCTCGAGCTGTGCCGC |
| CGCGGCGCACCGCCGCGGCGGTGCGTCAGCGGCGCCAAGTTCCCTCCCGA |
| CCCGGGGGCCGACGCGCGCGTGGCGGCCGCCCTGGCGGGCCGGCTCGGTC |
| TGCCGCACACGGTGGTGCCGCGCCCCCGTTCGCAGTTCCGCGCGGAGCTC |
| GCCGCCCTGCCGGCCCAGGGCATGACCACCCTGGACGGCGCGTGGACCCA |
| GCCGGTCCTGGCCCACCTGCGCCGCCACAGCCGCATCTCGTACGACGGTC |
| TCGGCGGCGGGGAGCTCGTCCAGAACCCGAGCGTGGAGTTCATCCGGGCC |
| AACCCCTACGACCCCGCGGACCTGCCCGGCCTGGCGGACCGGTTGCTGGC |
| CGCGAGCCGGACCGGCCCCCACGTGGAGCACCTGCTGAGCCCCCGGACGA |
| ACGCCCTGTGGAGCAGGCAGGCGGCGCGGCGGCGCCTCGTCACCGAGCTG |
| GCCCGGCACGCCGACAGCGCCAGCCCGCTCAGTTCCTTCTTCTTCTGGAA |
| CCGGACCCGGCGCTCCATCTCCGCGGCTCCGTTCGCCCTGGGGGACGGAC |
| GGGTCCTGACGCACACCCCCTACCTCGACCACGCCCTCTTCGACCACCTC |
| GCCTCGGTGCCGCACCGCTTCCTGGTCGACGGGACGTTCCACGACCGGGC |
| GCTGCACCGGGCCTTCCCCGAGCACGCGGACCTGGGGTTCGCCTCGTCGG |
| TGCCCCAGCGGCACGGACCCGTGCTGGTCGCGCACCGAGTGGCGTACCTG |
| CTCCGGTTCCTCGCCCACGCGACGGTCGTGGAACCGGGCTGGTGGCGCGG |
| CCCCGACCGCTTCCTGCAACGGCTGCTGGCCGCCGGCCGGGGGCCCGGGG |
| CCCCGCAGCGCGTCAGCAGGCTGCAGCCCCTGGCGCTCTACCTGCTGCAG |
| TTGGAGGACCTCGCCGTCCGAAGGGCCCGCCGCCGGCCGTAG |
| (SEQ ID NO: 14) |
| TABLE 40 |
| Amino Acid Sequence of moeH5 |
| MTVRRPAASAPRVLLTAGPDGVRVEGDGEARLGHPLTGDHLDPGPPAEGV |
| FAGWRWDGERLVARNDRYGVCPLFYRAGGGSLALSPDPLALLPEDGPVEL |
| DHDALAVFLRTGFFLAEDTAFAQVRALPPAATLTWDTGGLRLRSDGPPRP |
| GAAAMTEAQAVDGFVDLFRASVARRLPGEPYDLPLSGGRDSRHILLELCR |
| RGAPPRRCVSGAKFPPDPGADARVAAALAGRLGLPHTVVPRPRSQFRAEL |
| AALPAQGMTTLDGAWTQPVLAHLRRHSRISYDGLGGGELVQNPSVEFIRA |
| NPYDPADLPGLADRLLAASRTGPHVEHLLSPRTNALWSRQAARRRLVTEL |
| ARHADSASPLSSFFFWNRTRRSISAAPFALGDGRVLTHTPYLDHALFDHL |
| ASVPHRFLVDGTFHDRALHRAFPEHADLGFASSVPQRHGPVLVAHRLAYL |
| LRFLAHATVVEPGWWRGPDRFLQRLLAAGRGPGAPQRVSRLQPLALYLLQ |
| LEDLAVRRARRRP (SEQ ID NO: 37) |
| TABLE 41 |
| Sequence Homology of moeH5 |
| ref|YP_159440.1| amidotransferase, similar to asparagine synthase (glutmine- |
| hydrolyzing) |
| [Azoarcus sp, EbN1] |
| Length-642 |
| Score = 70.1 bits (170), Expect = 2e−10 |
| Identities = 54/165 (32%), Positives = 80/165 (48%), Gaps = 5/165 (3%) |
| SEQ ID NO: 161 SEQ ID NO: 162 SEQ ID NO: 163 | |||
| Query | 48 | EGVFAGWRWDG--ERLVARNDRYGVCPLFYRAGGGSLALSPDPLALLPEDGPV-ELDHDA | 104 |
| +|+| || +||+ | || ||+ || + + ||| | ||||| | |||
| Sbjct | 121 | DGMFNFALWDARRKRLLIGRDPLGVKPLYVHRSASMLAFATEAKALLELPGVTRELDHDV | 180 |
| SEQ ID NO: 164 | |||
| SEQ ID NO: 165 | |||
| Query | 105 | LAVFLRTGFFLAEDTAFAQVRALPPAATLTWDTGGLR-LRSDGPPRPGAAAMTEAQAVDG | 163 |
| +| +| |+ | + | +| |||| |+ + | +| | | | +|||+ + | |||
| Sbjct | 181 | VADYLHLGYVAAPHSMFRDIRKLPPATLLSVENGEVRQWRYWRLPSSVARYVTEAEWIGR | 240 |
| SEQ ID NO: 246 | |||
| Query | 164 | FVDLFRASVARRLPGE-PYDLPLSGGRDSRHILLELCRRGAPPRR | 207 |
| | +| |++ + | |||| || ++ + + | | | | |||
| Sbjct | 241 | IRDGMERAVHRQMVSDVPIGAFLSGGVDSSAVVAFMAKHSAHPIR | 285 |
Gene moeH5 controls the carboxamidation of unit B (see compound 19), since strain ΔmoeH5 accumulated the moe A precursor 17 (Table 21, FIGS. 4A-4D). Expression of moeR5 in the ΔmoeH5 strain leads to the accumulation of the previously described compound 16 (Zehl 2006), supporting the structure assignment for 17 (FIG. 4). Apparently, underexpression of moeH5 in producing strains leads to the accumulation of moenomycins having the acid form of unit B (compounds 16, 17, 22). Thus, despite having high sequence homology, moeF5 and moeH5 have been shown via gene disruption to play quite different roles in moe A biosynthesis, and they cannot substitute for one another functionally in cross-complementation experiments.
The results described above have showed that MoeH5 amidates the B ring carboxyl group, but they do not explain why this modification occurs. That is, based on the studies of the present invention, it is propose that the polypeptide encoded by the moeH5 gene is a Unit B amidotransferase which participates in the conversion of Moe intermediate compound 16 or 17 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 18 or 19, respectively, as shown in FIGS. 4A-4D. The moeH5-controlled reaction could either be either a branch of moe A metabolism or an essential biosynthetic step prior to “decoration” of the moe A precursor with the unit A chromophore moiety. Unit A biogenesis was proposed to proceed via a MoeB4-catalyzed reaction between an amino cyclopentadione moiety and compound 16/17 (Ostash 2007). However, the presence of a gene dedicated to the conversion of the acid moe A precursor 16/17 into the amide precursor 18/19 (FIG. 4) raised questions about the proposed scheme. We coexpressed the genes for unit A biosynthesis (pOOB64b) in the 38-1+ recombinant strain, which directs the production of 19, and in its ΔmoeH5 derivative, which produces 17. Expression of pOOB64b in ΔmoeH5 yielded no new products (Table 21), while the pOOB64b+38-1+ strain produced the known compound pholipomycin 21 (Table 21, FIGS. 4A-4D), which contains the Unit A chromophore (Welzel 2005). The inability of pOOB64b+ΔmoeH5 strain to produce pholipomycin 21 implies that either 17 is not a precursor to 21 or the moeH5 is essential for moe A chromophore attachment for other reasons. (Schuricht 2000, Petricek 2006, Ostash 2007). At the moment, we propose that carboxamide 19 serves as a necessary intermediate to moe A (FIGS. 4A-4D).
3. moeK5
The putative protein encoded by moeK5 is homologous to radical SAM superfamily enzymes, particularly to a presumed methyltransferase from Pyrococcus horikoshii OT3 (34% identity and 52% similarity). The nucleotide and polypeptide sequences are shown in Tables 42 and 43, respectively. A sequence alignment between moeK5 and the closest homolog identified in the BLAST search is shown in Table 44. The MoeK5 putative translation product showed no apparent similarity to other known sugar C-methyltransferases, such as those exemplified by NovU and TylC3, which require keto group in a position adjacent to methylation site (Thuy 2005, Takahashi 2006). A CDD search revealed radical SAM vitamin B12 binding domain (cd02068) and radical SAM domain (pfam04055) in the N- and C-halves, respectively, of moeK5. Accordingly, moeK5 could function via a SAM radical mechanism, and may not require the transformation of a sugar into an anionic form before methylation.
| TABLE 42 |
| DNA Sequence of moeKS. |
| CTGGGTTACATCCACACCGCGCTCAAGTCGGCCGGGTTCCACCACGTCAT |
| CCAGGTCGACACCCCCGCCCTGGGCCTCGACAGCGAGGGGCTGCGCAAGC |
| TGCTCGCGGACTTCGAGCCGGACCTGGTCGGGGTGAGCACCACGACACCC |
| GGTCTGCCCGGCGCCATCGAGGCGTGCGAGGCGGCCAAGAGCACCGGGGC |
| GAAGGTGATCCTGGGCGGGCCGCACACGGAGGTGTACGCGCACGAGAACC |
| TGGTCCACGAGTCCATCGAGTACGTGGGCGTCGGCGAAGGCGTCACGATC |
| ATGCCGGAACTGGCGGAGGCGATGGAGCGGGGCGAGGAGCCGGAGGGCAT |
| CCGCGGCCTGGTGACCCGCAAGCACGACGGCGGTGCCGCGCCGATGGTGA |
| ACCTGGAGGAGGTCGGCTGGCCCGAACGCGCCGGGCTCCCGATGGACCGC |
| TACTACTCGATCATGGCTCCGCGGCCGTTCGCGACGATGATCTCCAGCCG |
| CGGCTGCCCCTTCAAGTGCAGCTTCTGCTTCAAGCAGGCCGTGGACAAGA |
| AGTCCATGTACCGCAGTCCCGAGGACGTCGTCGGTGAGATGACGGAGCTC |
| AAGGAGCGGTGGGGGGTGAAGGAGATCATGTTCTACGACGACGTGTTCAC |
| CCTGCACCGCGGCCGGGTGCGGGAGATCTGCGGGCTCATCGGGGAGACCG |
| GCCTCAAGGTCCGCTGGGAGGCGCCCACCCGCGTCGACCTGGTGCCCGAG |
| CCGCTGCTGGAGGCGATGGCCGGGGCCGGGTGCGTGCGCCTGCGGTTCGG |
| CATCGAGCACGGTGACAGCGAGATCCTCGAGCGGATGCGCAAGGAGAGCG |
| ACATCCAGAAGATCGAGAAGGCCGTCACCTCCGCCCACGAGGCCGGGATC |
| AAGGGCTTCGGGTACTTCATCGTCGGCTGGCTCGGGGAGACCCGGGAGCA |
| GTTCCGCAGGAGCGTCGAGCTCGCCTGCCGCCTCCCGCTGGAGTAGGCCA |
| GCTTCTACACCGCGACGCCCCTGCCGGGCACCCCCCTGCACACGGAGTCC |
| GTGGCCGCCGGCCAGATCCCGCCCGACTACTGGGACCGCTTTTCGTGCGG |
| GGCGAGTTCGACGCGCGGATCGGGTACCTGGTGCCGGACGCGCAGGAGCG |
| CGCCCAGTGGGCGTACCGCTCCTTCTTCATGCGCCGCTCCATGGTCAAGC |
| CGCTGCTGTCGCACATGGCGGTGA (SEQ ID NO: 15) |
| TABLE 43 |
| Amino Acid Sequence of moeK5 |
| LGYIHTALKSAGFHHVIQVDTPALGLDSEGLRKLLADFEPDLVGVSTTTP |
| GLPGAIEACEAAKSTGAKVILGGPHTEVYAHENLVHESIDYVGVGEGVTI |
| MPELAEAMERGEEPEGIRGLVTRKHDGGAAPMVNLEEVGWPERAGLPMDR |
| YYSIMAPRPFATMISSRGCPFKCSFCFKQAVDKKSMYRSPEDVVGEMTEL |
| KERWGVKEIMFYDDVFTLHRGRVREICGLIGETGLKVRWEAPTRVDLVPE |
| PLLEAMAGAGCVRLRFGIEHGDSEILERMRKESDIQKIEKAVTSAHEAGI |
| KGFGYFIVGWLGETREQFRRTVDLACRLPLDYASFYTATPLPGTPLHTES |
| VAAGQIPPDYWDRFSCGASSTRGSGTWCRTRRSAPSGRTAPSSCAAPWSS |
| RCCRTWR (SEQ ID NO: 38) |
| TABLE 44 |
| Sequence Homology of moeK5 |
| ref|NP_142754.1| methyltransferase [Pyrococcus horikoshii OT3] |
| Length = 459 |
| Score = 192 bits (489), Expect = 2e−47 |
| Identities = 128/375 (34%), Positives = 195/375 (52%), Gaps = 13/375 (3%) |
| SEQ ID NO: 166 | |||
| Query | 1 | LGYIHTALKSAGFHHVIQVDTPALGLDSEGLRKLLADFEPDLVGVSTTTPGLPGAIEACE | 60 |
| || + | | | +| | | + |++ |+||+||++ || + | + | |||
| Sbjct | 28 | LGLAYLASMVREEHDVKIIDGLAEDLTFSDIAKIIKKFDPDIVGITATTSAMYDAYTVAK | 87 |
| SEQ ID NO: 247 | |||
| SEQ ID NO: 167 SEQ ID NO: 168 | |||
| Query | 61 | AAKSTGAKV--ILGGPHTEVYAHENLVHES--IDYVGVGEGVTIMPELAEAMERGEEPEG | 116 |
| ||+ | ++|||| + | + | || | ||| || +|+ +| | +| | |||
| Sbjct | 88 | IAKNINENVFVVMGGPHV-TFTPELTMRECPCIDAVVRGEGELTFKELVDALSKGRELKG | 146 |
| SEQ ID NO: 248 | |||
| SEQ ID NO: 169 | |||
| Query | 117 | IRGLVTRKH----DGGAAPMV-NLEEVGWPERAGLPMDRYYSIMAPRPFATMISSRGCPF | 171 |
| | || +++ + |++ |++|+ | ||||+| + | | +++|||||| | |||
| Sbjct | 147 | ILGLSYKENGKVRNEPPRPLIQNVDEIPIPSYDLLPMDKYKADGVP--FGVVMTSRGCPF | 204 |
| SEQ ID NO: 170 | |||
| SEQ ID NO: 171 | |||
| Query | 172 | KCSFCFKQA-VDKKSMYRSPEDVVGEMTELKERWGVKEIMFYDDVFTLHRGRVREICGLI | 230 |
| | || |+ | | |+ |++ | +|+||| | || |||++ | +| | | |||
| Sbjct | 205 | NCVFCSSSLQFGKRWRGHSVERVIEELSILHYEYGIKEIEFLDDTFTLNKKRAIDISLRI | 264 |
| Query | 231 | GETGLKVRWEAPTRVDLVPEPLLEAMAGAGCVRLRFGIEHGDSEILERMRKESDIQKIEK | 290 |
| + || + | | +||+ | + +|| || + |||| ||| + | |+ | |||
| Sbjct | 265 | KQEGLDISWTASSRVNTFNEKVAKAMKEGGCHTVYFGIESASPRILEFIGKGITPQQSID | 324 |
| Query | 291 | AVTSAHEAGIKGFGYFIVGWLGETREQFRRTVDLACRLPLDYASFYTATPLPGTPLHTES | 350 |
| || +| + |+ | ||+|+ ||||+ |+ | +| +||| | ||| ||| | + | |||
| Sbjct | 325 | AVKTAKKFGLHALGSFIIGFPDETREEVEATIKFAKKLDIDYAQFTIATPYPGTRLWEYA | 384 |
| Query | 351 | VAAGQIPPDYWDRFS | 365 |
| +| + | +++ | |||
| Sbjct | 385 | IANNLLLTMNWRKYT | 399 |
Gene moeK5 encodes a protein homologous to putative SAM-radical, methyl-cobalamin-dependent methyl transferases involved in the biosynthesis of fortimycin and a handful of other secondary metabolites, and we have proposed that it controls the methylation of the first sugar (unit F) (Ostash 2007). Indeed, strain ΔmoeK5 accumulated a compound 24 having a mass 14 Da less than that of compound 19 from the parental 38-1+ strain (Table 21), indicative of the loss of a methyl group. Methylation of unit F most likely takes place after its attachment to farnesyl-phosphoglycerate since we detected a mixture of nonmethylated and methylated monosaccharides (compounds 2 and 3, respectively; Table 21) in the ΔmoeGT4 strain. Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeK5 gene is a methyltransferase which participates in the conversion of Moe intermediate compound 1 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 2 or 3, respectively, as shown in FIGS. 4A-4D.
4. moeM5
The predicted moeM5 translation product of moeM5 is similar to carbamoyltransferases from NodU family (33% identity and 45% similarity to putative carbamoyltransferase from Rubrobacter xylanophilus DSM9941) (Jabbouri 1995) as well as to those involved in antibiotic biosynthesis in various actinomycetes (29% identity and 44% similarity to GdmN involved in geldanamycin biosynthesis) (Hong 2004). The nucleotide and polypeptide sequences are shown in Tables 45 and 46, respectively. A sequence alignment between moeM5 and the closest homolog identified in the BLAST search is shown in Table 47. MoeK5 and moeM5 may govern the transfer of methyl and carbamoyl groups, respectively, on a moenuronamide precursor.
| TABLE 45 |
| DNA Sequence of moeM5. |
| ATGAAGGTACTGTCGCTCCACTCCGCCGGCCACGACACCGGCGTCGCCTA |
| CTTCGAGGACGGGCGGCTGGTCTTCGCGGTCGAGACCGAACGGCTCACCC |
| GGGTCAAGCACGACCACCGCTCCGACGTCGCCCTGCGGCACGTGCTCGAG |
| CAGGAGTGCGTGGACACCGACGGGATCGACCTGGTGGCCGTCAGCACCCC |
| GGTCCGCAGCGGGCTGCTGCGCATACCCGACCTGGACCGGGCCATGGAGC |
| GGATCGGGGCGGGCGCCCTCCACCACCGGACCGTCTGCGAGATGCTGGGG |
| CGGCGGGTGGAGTGCGTCGTGGTCACCCACGAGGTCTCCCACGCGGCGCT |
| GGCCGCCCACTACGCGGACTGGGAGGAAGGCACCGTCGTCCTCGTCAACG |
| AGGGCCGCGGCCAGCTCACCCGCAGCTCCCTGTTCCGGGTGACCGGCGGG |
| GCCCTGGAGTGGGTCGACAAGGACCCGCTGCCCTGGTACGGCAACGGCTT |
| CGGGTGGACGGCGATCGGGTACCTCCTCGGCTTCGGCCCGAGCCCCAGCG |
| TGGCGGGCAAGGTGATGGCCATGGGCGGCTACGGGCAGCCGGACCCGCGC |
| ATCCGCGAACAGCTGCTGTCGGTGGATCCGGAGGTGATGAACGACCGGGA |
| ACTCGCCGAGCGGGTGCGCGCGGACCTGGCCGGCCGGCCCGAGTTCGCCC |
| CCGGGTTCGAGACGGCGTCGCAGGTGGTGGCGACGTTCCAGGAGATGTTC |
| ACCGAGGCCGTCCGGGCGGTGCTCGACCGGCATGTGACGCGCACGGACGC |
| CGGGGTGGGCCCGATCGCCCTGGGCGGCGGGTGCGCCCTGAACATCGTGG |
| CCAACTCGGCGCTGCGGGAGGAGTACGGGCGGGACGTCGCCATCCCGCCC |
| GCCTGCGGGGACGCGGGTCACCTGACGGGCGCCGGCCTCTACGCCCTCGC |
| GCAGGTGGCCGGGGTGAAGCCGGAGCCGTTCAGCGTGTACCGCAACGGCG |
| GGGGCGAGGCCCGGGCCGCCGTCCTGGAGGCGGTGGAGGGCGCGGGGTTG |
| CGGGCCGTTCCCTACGACCGGTCCGCGGTCGCCGGGGTGCTGGCCGGGGG |
| CGGGGTGGTGGCGCTGACGCAGGGAGCGGCGGAACTGGGGCCGCGGGCGC |
| TGGGGCACCGGTCGCTGCTGGGCAGTCCCGCGGTGCCGGGCATGCGCGAG |
| CGGATGAGCGAGAAGCTCAAGCGGCGCGAGTGGTTCCGGCCGCTGGGCGC |
| CGTGATGCGCGACGAGCGCTTCGCCGGGCTGTACCCGGGGCGGGCGCCGT |
| CGCCGTACATGCTCTTCGAGTACCGGCTGCCGGACGGGATCGCGCCCGAG |
| GCCCGGCACGTCAACGGCACCTGCCGGATCCAGACCCTGGGCCCCGAGGA |
| GGACCGGCTGTACGGTCTGCTCGCCGAGTTCGAGGAGCTGAGCGGTGTGC |
| CGGCGCTGATCAACACGTCGCTCAACGGCCCGGGCAAGCCCATCGCGCAC |
| ACCGCCCGGGACGTGCTCGACGACTTCGCGCGCACCGACGTCGACCTCTT |
| CGTGTTCGACGACCTGATGGTGCGGGGCGCCGCCGCGCGGTAG |
| (SEQ ID NO: 16) |
| TABLE 46 |
| Amino Acid Sequence of moeM5 |
| MKVLSLHSAGHDTGVAYFEDGRLVFAVETERLTRVKHDHRSDVALRHVLE |
| QECVDTDGIDLVAVSTPVRSGLLRIPDLDRAMERIGAGALHHRTVCEMLG |
| RRVECVVVTHEVSHAALAAHYADWEEGTVVLVNEGRGQLTRSSLFRVTGG |
| ALEWVDKDPLPWYGNGFGWTAIGYLLGFGPSPSVAGKVMAMGGYGQPDPR |
| IREQLLSVDPEVMNDRELAERVRADLAGRPEFAPGFETASQVVATFQEMF |
| TEAVRAVLDRHVTRTDAGVGPIALGGGCALNIVANSALREEYGRDVAIPP |
| ACGDAGHLTGAGLYALAQVAGVKPEPFSVYRNGGGEARAAVLEAVEGAGL |
| RAVPYDRSAVAGVLAGGGVVALTQGAAELGPRALGHRSLLGSPAVPGMRE |
| RMSEKLKRREWFRPLGAVMRDERFAGLYPGRAPSPYMLFEYRLPDGIAPE |
| ARHVNGTCRIQTLGPEEDRLYGLLAEFEELSGVPALINTSLNGPGKPIAH |
| TARDVLDDFARTDVDLFVFDDLMVRGAAAR (SEQ ID NO: 39) |
| TABLE 47 |
| Sequence Homology of moeM5 |
| gb|AAO06921.1|GdmN [Streptomyces hygroscopicus] |
| Length = 682 |
| Score = 159 bits (401), Expect = 4e−37 |
| Identities = 167/557 (29%), Positives = 246/557 (44%), Gaps = 49/557 (8%) |
| SEQ ID NO: 172 SEQ ID NO: 173 | |||
| Query | 11 | HDTGVAYFEDGRLVFAVETERLTRVKHDHRSDV-ALRHVLEQECVDTDGIDLVAVSTP-- | 67 |
| ||+ + || || ||| ||| |+| + + |+| | + +| | | | |||
| Sbjct | 27 | HDSAASLIRDGELVAAVEEERLNRIKKTTKFPLNAVRECLALAGARPEDVDAVGYYFPEN | 86 |
| SEQ ID NO: 174 | |||
| SEQ ID NO: 175 SEQ ID NO: 235 SEQ ID NO: 176 | |||
| Query | 68 | -VRSGLLRI-PDLDRAMERIGAGALHHRTVCEMLGRRV---ECVVVTHEVSHAALAAHYA | 122 |
| + + | + + || | + | + | || + + | | | +|| +++ | |||
| Sbjct | 87 | HIDTVLNHLYTEYPRAPLRYSRELIRQR-LKEGLGWDLPDEKLVYVPHHEAHA-YSSYLH | 144 |
| SEQ ID NO: 177 SEQ ID NO: 178 | |||
| Query | 123 | DWEEGTVVLVNEGRGQLTRSSLFRVTGGALEWVDKDPLPWYGNGFGWTAIGYLLGFGPSP | 182 |
| + +||| +|||+| +++| | || + |+| | | ||||+| | |||
| Sbjct | 145 | SGMDSALVLVLDGRGELHSGTVYRAEGTRLEKLADYPVPKSLGGLYLNAT-YLLGYGFGD | 203 |
| SEQ ID NO: 236 | |||
| SEQ ID NO: 179 | |||
| Query | 183 | SVAGKVMAMGGYGQPDPRIREQLLSVDPEVMNDRELAERVRADLAGRPEF-APGF----- | 236 |
| ||| + +| |+ + + || + | | | || | |||
| Sbjct | 204 | EY--KVMGLAPWGNPETYRDTFAKLYTLQDNGEYELHGNIMVPNLVSPLFYAEGFRPRRK | 261 |
| SEQ ID NO: 180 | |||
| SEQ ID NO: 181 SEQ ID NO: 182 | |||
| Query | 237 | -ETASQVVATFQEMFTEAVRAVLDRHVTR---TDAGVGPIALGGGCALNIVANSA-LREE | 291 |
| | +| | | | ++ |+ +| + ||| | | | |+ | |||
| Sbjct | 262 | GEPFTQAHRDFAAALQETVEKIV-LHILEYWAKTSGHSRLCFGGGVAHNSSLNGLILKSG | 320 |
| SEQ ID NO: 237 | |||
| SEQ ID NO: 183 SEQ ID NO: 184 | |||
| Query | 292 | YGRDVAIPPACGDAGHLTGAGLYALAQVAGVKPEPFSVYRN-------GGGEARAAVLEA | 344 |
| +| + || ||| || || | | | + || | | | | |||
| Sbjct | 321 | LFDEVFVHPASHDAGAGEGAA-YAAAASLGTLERPGKRLLSASLGPALGGREQIRARL-- | 377 |
| SEQ ID NO: 249 | |||
| SEQ ID NO: 185 | |||
| Query | 345 | VEGAGLRAVPYDRSAV---AGVLAGGGVVALTQGAAELGPRALGHRSLLGSPAVPGMRER | 401 |
| + | | | + || ||+|| | |+ | +| |||||||||++ | | | |||
| Sbjct | 378 | ADWAPLIDVEFPDDAVETAAGLLAEGQVLGWAYGRSEFGPRALGHRSIVADARPEENRTR | 437 |
| SEQ ID NO: 238 | |||
| SEQ ID NO: 250 | |||
| Query | 402 | MSEKLKRREWFRPLGAVMRDERFAGLYP-GRAPSPYMLFEYRLPDGIAPEAR-------H | 453 |
| ++ +|+|| ||| |+ | + | + + +| + || | | | |||
| Sbjct | 438 | INAMVKKREGFRPFAPVVTAEAARDYFDLSGADGNHEFMSFVVP--VLPERRTELGAVTH | 495 |
| SEQ ID NO: 186 | |||
| SEQ ID NO: 187 SEQ ID NO: 188 | |||
| Query | 454 | VNGTCRIQTLGPEE-DRLYGLLAEFEELSGVPALINTSLNGPGKPIAHTARDVLDDFART | 512 |
| |+|| |+| + | +| + |+ | ||+| | |+||| | +|| + ||+ | | | |||
| Sbjct | 496 | VDGTARVQVVSAESGERFHRLVRRFGELTGTPVLLNTSFNNNAEPIVQSLDDVVTSFLTT | 555 |
| Query | 513 | DVDLFVFDDLMVRGAAA | 529 |
| |+|+ | +| +||| |+ | |||
| Sbjct | 556 | DLDVLVVEDCLVRGKAS | 572 |
To evaluate whether sugar tailoring reactions (particularly, O-carbamoylation of unit F) follow the formation of the lipid-phosphoglycerate-pentasaccharide scaffold of moe A, the carbamoyltransferase gene moeM5 was disrupted (see e.g., FIGS. 9A-9B). The mutant strain, termed OB20a, was then evaluated for moe A function; extracts from the moeMY mutant should contain less active moe A derivatives, lacking a carbomoyl group. Indeed, moeM5 deficient mutants have been shown to produce novel moe compounds with greatly reduced antibacterial activity. The molecular mass of such compounds (m/z 1538 Da; see e.g., FIGS. 12A-12D and 13A-13B) coincides with that of moe A lacking the carbamoyl group. Expression of a functional moeM5 gene in the OB20a mutant restored moe A biosynthesis. The purification of the intermediate accumulated in OB20a in quantities sufficient for more detailed structural elucidation has been hampered by its instability and very low levels.
Nevertheless, several conclusions may be drawn from the data obtained. First, moeM5 appears to govern carbamoylation of a moe A intermediate, which is one of several tailoring reactions involved in moes bioactivity.
Second, blocked carbamoylation does not appear to abolish the formation of pentasaccharide moiety of moe A. The ability to remove a certain chemical moiety from a given position of moe in order to obtain a more valuable derivative or to modify this position chemically would be very beneficial. For example, manipulations of genes responsible for introduction of carbamoyl, methyl, and amido groups into moe molecules and those involved in lipid-phosphoglycerate assembly are of interest since these functionalities contribute to moe bioactivity. However, it was not previously known whether the disruptions of a gene governing a certain catalytic step would lead to the production of desired intermediate. For instance, the absence of a specific chemical group on a first sugar might block the attachment of the second sugar, and thus the assembly of entire lipid-pentasaccharide scaffold would be interrupted.
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeM5 gene is a carbamoyltransferase which participates in the conversion of Moe intermediate compound 5, 6 or 7 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 8, 9 or 10, respectively, as shown in FIGS. 4A-4D.
Here, however, it was demonstrated that the generation of biologically active moe derivatives through genetic engineering is possible. In this instance, either carbamoyltransfer takes place after the glycoside scaffold of moe A is formed, or moe GTs possess a certain level of substrate flexibility allowing them to recognize sugars that have no specific functional groups. The result demonstrates that it is possible to switch off late steps of moe biosynthesis without disturbing the assembly of the complex pharmacophore scaffold.
5. moeR5
The putative translation product of the moeR5 gene resembles the C-terminal portion of the CapD-like NAD-dependent epimerases/dehydratases involved in capsular polysaccharide biosynthesis in various bacteria. (53% identity and 68% similarity to putative CapD protein from Nocardioides sp. JS614) (Lin 1994, Smith 1999). The nucleotide and polypeptide sequences are shown in Tables 48 and 49, respectively. A sequence alignment between moeR5 and the closest homolog identified in the BLAST search is shown in Table 50.
We have previously proposed that moeR5moeS5 encode a 4,6-dehydratase/ketoreductase pair that controls the conversion of UDP-GlcNAc into UDP-chinovosamine (Ostash 2007), the unit C sugar of moe A (FIG. 1). Consistent with this, the 38-1+ strain was shown to accumulate a moe A derivative containing GlcNAc in place of chinovosamine. A moeR5+moeS5+ 38-1+ strain accumulated a compound, 18, having an accurate mass and fragmentation pattern identical to a previously characterized moe A precursor (FIGS. 4A-4D and (Ostash 2007). While this result was expected, we were surprised to find that the moeR5+38-1+ strain also produces 18 (Table 21). There is a close moeS5 homolog in the S. coelicolor genome (Ostash 2007), and it is probable that a similar homolog exists in the S. lividans genome and complements the loss of moeS5 function in the moeR5+38-1+ strain. However, we cannot rule out the possibility that MoeR5 catalyzes both reactions. Co-expression of moeS5 and moeno38-1 yielded no new products (data not shown).
| TABLE 48 |
| DNA Sequence of moeR5 |
| ATGTTTGGCGATAATTCCGTGGGGTACGACGCGAACTTTCCGGCCGGTGG |
| ACCTCTCACCTTGGACCTCGAGAGGATTATCGGCCGCCAACGAATAAGGA |
| CCGGTCTCGAGAGCAGCGCCGGATTACTGCGCGGCCGACGGATCCTGGTC |
| ACCGGAGCCGGCGGCTACATCGGATCGGAACTGTGCCGGCAGCTCAGCCG |
| GTGGGAACCCGAGAGCCTCATGATGCTCGACCGGAACGAGACGGCCCTCC |
| ACCTGGCGGCCACCAGCATCGGGAACGTCTCCCCGTCGGTGCGGACCTCC |
| ATCCTCCTCGCGGACATCAGGGACTCCAGAGGGCTCGCCCGGCTGTTCCA |
| GCAGTGCCGGCCGGACACCGTCTTCCACGCGGCGGCCCTCAAATGGGTGC |
| CCATCCTGGAGAAGTTCCCCGGGGAAGCCGTCAAGACGAATGTCTTCGGC |
| ACCCGAGCGGTGCTCGAGGCGGCCCTGGCCGCGGACGTCGCGTTCCTGGT |
| GAACATCTCGACCGACAAGGCGGTCGATCCGGTCGGGGTGCTCGGATACT |
| CGAAACGCATAGCCGAAGGACTCACCGCGGCGGCCGCGATCCAGGCGGGC |
| AGACCGTACGTGAGCGTGCGCTTCGGCAACGTGCTCGGTTGCCAGGGGTC |
| CTTCCTCGACGTCTTCGCCCGGCAGATCGCGGCCGGCAGACCGGTGACGG |
| TCACCCACCCCGAGGTGACGCGCTATCTGATGACCGTCCAGGAGGCCGTG |
| GAACTGGTCATCCAGTCGGTCGCGCTGGGCAGCGTCGGCCACGCCCTGGT |
| CCTGGACATGGGGGAACAGGTCCGGATCCTCGACATCGCCAGAAGGCTCA |
| TCGCGCACGCCGGTGCGGAGCTCCCGGTCCGCTACGTCGGGCTGCGGCCG |
| GGGGAGAAGCTCACCGAGGCGCTGGTGGCCCCTTCCGAGTCCCCGGTCCG |
| GCACGGGCATCCGAAGATCATGGAAGTGCCGGTGCCGGCCCTGAAGGCGG |
| GGGACGGCCCGGAACTCGACGCCTGGGGCGAGGACCAGGCCGTCGTCGCC |
| GCCCTGCGCGCCACCTGCCTCGCCATGGCGGGCGACGACCCGGTGGCGCA |
| GGACCCCGGCCACCGGCTGGTCTGA (SEQ ID NO: 17) |
| TABLE 49 |
| Amino Acid Sequence of moeR5 |
| MFGDNSVGYDANFPAGGPLTLDLERIIGRQRIRTGLESSAGLLRGRRILV |
| TGAGGYIGSELCRQLSRWEPESLMMLDRNETALHLAATSIGNVSPSVRTS |
| ILLADIRDSRGLARLFQQCRPDTVFHAAALKWVPILEKFPGEAVKTNVFG |
| TRAVLEAALAADVAFLVNISTDKAVDPVGVLGYSKRIAEGLTAAAAIQAG |
| RPYVSVRFGNVLGCQGSFLDVFARQIAAGRPVTVTHPEVTRYLMTVQEAV |
| ELVIQSVALGSVGHALVLDMGEQVRILDIARRLIAHAGAELPVRYVGLRP |
| GEKLTEALVAPSESPVRHGHPKIMEVPVPALKAGDGPELDAWGEDQAVVA |
| ALRATCLAMAGDDPVAQDPGHRLV (SEQ ID NO: 40) |
| TABLE 50 |
| Sequence Homology of moeR5 |
| gi|71367042|ref|ZP_00657575.1|Polysaccharide biosynthesis protein CapD |
| [Nocardioides sp. JS614] |
| gi|71157263|gb|EAO07657.1|Polysaccharide biosynthesis protein CapD |
| [Nocardioides sp. JS614] |
| Length = 667 |
| Score = 322 bits (824), Expect = 2e−86, Method: Composition-based stats. |
| Identities = 185/346 (53%), Positives = 237/346 (68%), Gaps = 2/346 (0%) |
| SEQ ID NO: 189 | |||
| Query | 21 | LDLERIIGRQRIRTGLESSAGLLRGRRILVTGAGGYIGSELCRQLSRWEPESLMMLDRNE | 80 |
| +++ ++|| ++ | + | || | ||++||||||| ||||||||+ |++| ||||||+| | |||
| Sbjct | 317 | INITDVLGRNQLDTDVASIAGYLAGRKVLVTGAGGSIGSELCRQIYRYQPAELMMLDRDE | 376 |
| SEQ ID NO: 190 | |||
| Query | 81 | TALHLAATSIGNVSPSVRTSILLADIRDSRGLARLFOQCRPDTVFHAAALKWVPILEKFP | 140 |
| +||| || + ++| |||| + + +| ||| |||||| +|+||++| | |||
| Sbjct | 377 | SALHRVQLSIHGRALLDSDDVILCDIRDEKAVRTIFANRRPDVVFHAAALKHLPMLEQYP | 436 |
| Query | 141 | GEAVKTNVFGTRavleaalaadvaflvNISTDKAVDPVGVLGYSKRIAEGLTAAAAIQAG | 200 |
| ||||||| ||| ||+|| | |||||||| +| |||||||+|| +||| | +| | |||
| Sbjct | 437 | AEAVKTNVIGTRTVLDAADLVGVDRFVNISTDKAANPSSVLGYSKRVAERITAAQAREAS | 496 |
| Query | 201 | RPYVSVRFGNVLGCQGSFLDVFARQIAAGRPVTVTHPEVTRYLMTVQEAVELVIQSVALG | 260 |
| |+||||||||| +|| | |||||||| |+|||||+|+|+ ||++|| +||||+ |+| | |||
| Sbjct | 497 | GTYLSVRFGNVLGSRGSVLAAFARQIAAGGPITVTHPDVSRFFMTIEEACQLVIQAAAIG | 556 |
| SEQ ID NO: 191 | |||
| Query | 261 | SVGHALVLDMGEQVRILDIARRLIAHAGAELPVRYVGLRPGEKLTEALVAPSES-PVRHG | 319 |
| | |||||||| |+|+|+| +|| || +|+ | ||| |||| | | | || | |||
| Sbjct | 557 | GPGEALVLDMGEPVKIVDVAEQLIEQAGTPVPIEYTGLREGEKLHEELFGEGEPCDVRPR | 616 |
| SEQ ID NO: 192 | |||
| Query | 320 | HPKIMEVPVPALKAGDGPELDAWGEDQAVVAALRATCL-AMAGDDP 364 | |
| || + |||| + |+ | || | || || ++ ||| | |||
| Sbjct | 617 | HPLVSHVPVPPITDGEVLGLTLVGEPDDVRQALHDACLVSIEADDP | 662 |
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeR5 gene is a hexose-4,6-dehydratase which participates in the conversion of Moe intermediate compound 4 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 6 or 7, wherein chinovosamine is utilized as a donor, respectively, as shown in FIGS. 4A-4D. Furthermore, based on the studies of the present invention, it is propose that the polypeptide encoded by the moeR5 gene is a hexose-4,6-dehydratase which participates in the conversion of Moe intermediate compound 11 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 14 or 15, wherein chinovosamine is utilized as a donor, respectively, as shown in FIGS. 4A-4D.
6. moeS5
Gene moeS5, located upstream of moeR5, encodes a putative protein homologous to putative polysaccharide biosynthesis protein SCO7194 from S. coelicolor A3(2) (63% identity and 76% similarity). The nucleotide and polypeptide sequences are shown in Tables 51 and 52, respectively. A sequence alignment between moeS5 and the closest homolog identified in the BLAST search is shown in Table 53. A CDD search revealed an RfbD domain (COG1091) in moeS5. This domain is present in many known NDP-4-dehydrohexose reductases. It is possible that the moeR5 and moeS5 genes may govern two consecutive steps of NDP-Glc-Nac transformation into NDP-chinovosamine (unit C of moe A; FIG. 1). Particularly, the NDP-Glc-NAc-4, 6-dehydratase activity of moeR5 may convert NDP-Glc-NAc into NDP-4-keto-6deoxy-Glc-Nac, and the hexose-4-ketoreductase activity of moeS5 may reduce this intermediate to yield NDP-chinovosamine.
| TABLE 51 |
| DNA Sequence of moeS5 |
| GTGAGAGTTCTTGTCGTCGGCGGGAGCGGCTTCCTCGGGTAGGAGGTGCT |
| CCGCCGGGCCGTGGCCGCCGGGTGGGACGTGGCCGCGACCTACCGGACCC |
| GCCCCGAGGAACTGCCGCCGGTCACCTGGTACCGGGCCGACCTCCGTGAC |
| CCGGGGCGGATGGGAGAGGTGCTGGCCCGGACCCGGCCGGCCGCGGTGAT |
| CAACGCGTCGAGCGGACACGCCGACTGGGCGGTCACGGCCGACGGCGCGG |
| CCCGCCTCGCCCTGGAGGCGGCGCGCGCCGGCTGCCGACTAGTCCACGTC |
| TCCTCCGACGCCGTGTTCTCCGGAGCCGACGTCCACTACCCGGAGGAGGC |
| CCTCCCCGACCCCGTCTCCCCGTACGGCGCGGCCAAGGCCGCGGCGGAGA |
| CGGCCGTCAGGGTGGCCGTGCCCGAGGCCGCCGTGGTGCGCACCTCGCTC |
| ATCGTGGGGCACAACCGGTCCGCCCACGAGGAGGCGGTGCACGCCCTGGC |
| GGCCGGCCGGCGCGCCGGCGTCCTGTTCACGGACGACGTCCGCTGTCCGG |
| TCCACGTCGACGATCTGGCCTCCGCGCTTTTGGAGATCGCGGCGTCGGAC |
| GGGTCCGGGGTGTTCCACGTGGCGGGACCGGACGCGATGAACCGTCACGA |
| CCTGGGTGTCCTCATAGCCCGGCGGGACGGACTGGACCCGGCCCGGCTGC |
| CGGCCGGTCTGCGGAGCGAGGTGGCCCCGCCGGGGAACCTCGACATCCGT |
| CTCGTCACCGATGCCACGCGGGCCCGGCTCCGGACCCGGTTGCGGGGCGC |
| GCGCGAATTCCTCGGCCCCGGCGTTCCGGTGACGCGGGGCGTCCGTTGA |
| (SEQ ID NO: 18) |
| TABLE 52 |
| Amino Acid Sequence of moeS5 |
| VRVLVVGGSGFLGYEVLRRAVAAGWDVAATYRTRPEELPPVTWRADLRDP |
| GRMGEVLARTRPAAVINASSGHADWAVTADGAARLALEAARAGCRLVHVS |
| SDAVFSGADVHYPEEALPDPVSPYGAAKAAAETAVRVAVPEAAVVRTSLI |
| VGHNRSAHEEAVHALAAGRRAGVLFTDDVRCPVHVDDLASALLEIAASDG |
| SGVFHVAGPDAMNRHDLGVLIARRDGLDPARLPAGLRSEVAPPGNLDIRL |
| VTDATRARLRTRLRGAREFLGPGVPVTRGVR (SEQ ID NO: 41) |
| TABLE 53 |
| Sequence Homology of moeS5 |
| emb|CAC01594.1|putative polysaccharide biosynthesis protein [Streptomyces |
| coelicolor A3(2)] SCO7194 |
| Length = 271 |
| Score = 335 bits (860), Expect = 1e−90 |
| Identities = 171/269 (63%), Positives = 205/269 (76%), Gaps = 0/269 (0%) |
| SEQ ID NO: 193 | |||
| Query | 3 | VLVVGGSGFLGYEVLRRAVAAGWDVAATYRTRPEELPPVTWYRADLRDPGRMXEVLARTR | 62 |
| ||||||||||| |++|+| ||| ||||+ ||| + | ||+ |||| |+ ||+| | |||
| Sbjct | 3 | VLVVGGSGFLGTELVRQASAAGHRVAATFATRPCDGPEATWHEVDLRDGARVEEVVASLA | 62 |
| SEQ ID NO: 194 | |||
| Query | 63 | PAAVINASSGHADWAVTADGAARLALEAARAGCRLVHVSSDAVFSGADVHYPEEALPDPV | 122 |
| | ||||||| |||||||+|+ |||+ | + ||||||||||||||+ ||| | ||||| | |||
| Sbjct | 63 | PCVVINASSGSADWAVTAEGSVRLAMTAVKYDCRLVHVSSDAVFSGSRVHYDESCLPDPV | 122 |
| Query | 123 | SPYGAAKAAAETAVRVAVPEAAVVRTSLIVGHNRSAHEEAVHALAAGRRAGVLFTDDVRC | 182 |
| ||||+|||+||||+| + || |+|| ||++|| ||||||+||||| +||| |||+ + | |||
| Sbjct | 123 | TPYGAAKAAAETGIRLLAPAAVIARTSLIIGGIQSEHVRLVHDLATGSRTGALFTDDVRC | 182 |
| Query | 183 | PVHVDDLASALLEIAASDGSGVFHVAGPDAMNRHDLGVLIARRDGLDPARLPAGLRSEVA | 242 |
| ||||+|||+||||+| + || |+|| ||+++|| ||||||+||||| +||| |||+ + | |||
| Sbjct | 183 | PVHVEDLAAALLELAFTGACGVHHLAGKDAVSRHGLGVLIAQRDGLDASRLPEGLRAGTS | 242 |
| Query | 243 | PPGNLDIRLVTDATRARLRTRLRGAREFL | 271 |
| | |+|| + ||||+||||+|| ||| | |||
| Sbjct | 243 | LSGALDVRLDSRATRAKLRTRVRGVHEFL | 271 |
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeS5 gene is a hexose-4-ketoreductase which participates in the conversion of Moe intermediate compound 4 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 6 or 7, wherein chinovosamine is utilized as a donor, respectively, as shown in FIGS. 4A-4D. Further, based on the studies of the present invention, it is propose that the polypeptide encoded by the moeS5 gene is a hexose-4-ketoreductase which participates in the conversion of Moe intermediate compound 11 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 14 or 15, wherein chinovosamine is utilized as a donor, respectively, as shown in FIGS. 4A-4D.
7. moeE5
The putative protein encoded by the moeE5 gene appears the most similar to the putative NDP-hexose 4-epimerase from Symbiobacterium thermophilum IAM14863 (46% identity and 58% similarity) and other known epimerases. The nucleotide and polypeptide sequences are shown in Tables 54 and 55, respectively. A sequence alignment between moeE5 and the closest homolog identified in the BLAST search is shown in Table 56. S. ghanaensis produces moes A12 and C1 as minor components of moe complex in which unit F (moenuronamide) has D-galacto configuration (and not D-gluco as in Moe A) (Welzel 2005). Such a rearrangement requires epimerization of hydroxyl group in 4th position of hexose ring and moeE5 protein appears to fit this role.
| TABLE 54 |
| DNA Sequence of moeE5. |
| GTGTCGAGCGATACACACGGAACGGACTTAGCGGACGGCGACGTTTTGGT |
| CACCGGTGCGGCCGGCTTCATCGGGTCGCACCTGGTGACGGAACTGAGGA |
| ATTCCGGCAGAAACGTTGTGGCGGTGGACCGGAGACCCCTTCCGGACGAC |
| TTGGAGAGTAGGTCCCCGCCCTTTACCGGTTCGCTCCGGGAGATACGCGG |
| TGAGCTCAACTCATTGAATCTGGTGGAGTGCCTGAAAAACATCTCGACGG |
| TCTTCCACTTGGCCGCGTTACCCGGAGTCCGCCCGTCCTGGACCCAATTC |
| CCCGAGTACCTCCGGTGCAATGTACTGGCGACCCAGCGCCTGATGGAGGC |
| CTGTGTGCAGGCCGGCGTGGAACGCGTGGTGGTCGCCTCGTCCTCCAGCG |
| TCTACGGCGGCGCGGACGGCGTGATGAGCGAGGACGACCTGCCCCGTCCG |
| CTCTCCCCCTACGGGGTCACCAAACTCGCCGCGGAGCGGCTGGCCCTGGC |
| CTTCGCGGCCCGCGGCGACGCCGAGCTCTCGGTCGGCGCCCTGAGGTTCT |
| TCACCGTCTAGGGCCCCGGCCAGCGCCCGGACATGTTCATCTCCCGGCTG |
| ATCCGGGCGACGCTCCGGGGCGAACCCGTCGAGATCTACGGCGACGGGAC |
| CCAGCTCCGCGACTTCACCCATGTGTCCGACGTGGTGCGGGCGCTGATGC |
| TGACCGCGTCGGTGCGGGACCGGGGCAGCGCGGTGCTGAACATCGGCACC |
| GGGAGCGCCGTCTCGGTCAACGAAGTGGTCTCCATGACCGCGGAGCTGAC |
| CGGTCTGCGCCCGTGCACCGCGTACGGTTCCGCCCGCATCGGCGACGTCC |
| GCTCGACCACCGCCGACGTGCGGCAGGCCCAGAGCGTCCTGGGCTTCACG |
| GCCCGGACGGGTCTGCGGGAAGGTCTCGCCACCCAGATCGAGTGGACCCG |
| GCGGTCACTGTCCGGCGCCGAGCAGGACACCGTCCCGGTCGGCGGCTCCT |
| CGGTGTCCGTGCCGCGGCTGTAG (SEQ ID NO: 19) |
| TABLE 55 |
| Amino Acid Sequence of moeE5 |
| VSSDTHGTDLADGDVLVTGAAGFIGSHLVTELRNSGRNVVAVDRRPLPDD |
| LESTSPPFTGSLREIRGDLNSLNLVDCLKNISTVFHLAALPGVRPSWTQF |
| PEYLRCNVLATQRLMEACVQAGVERVVVASSSSVYGGADGVMSEDDLPRP |
| LSPYGVTKLAAERLALAFAARGDAELSVGALRFFTVYGPGQRPDMFISRL |
| IRATLRGEPVEIYGDGTQLRDFTHVSDVVRALMLTASVRDRGSAVLNIGT |
| GSAVSVNEVVSMTAELTGLRPCTAYGSARIGDVRSTTADVRQAQSVLGFT |
| ARTGLREGLATQIEWTRRSLSGAEQDTVPVGGSSVSVPRL |
| (SEQ ID NO: 42) |
| TABLE 56 |
| Sequence Homology of moeE5 |
| ref|YP_074610.1|UDP-glucose 4-epimerase [Symbiobacterium thermophilum IAM |
| 14863] |
| Length = 292 |
| Score = 230 bits (587), Expect = 6e−59 |
| Identities = 138/300 (46%), Positives = 175/300 (58%), Gaps = 18/300 (6%) |
| SEQ ID NO: 195 | |||
| Query | 16 | LVTGAAGFIGSHLVTELRNSGRNVVAVDRRPLPDDLESTSPPFTGSLREIRGDLNSLNLV | 75 |
| |||||||||||||| || +| +|| ||||| | + ||| +|+| | |||
| Sbjct | 5 | LVTGAAGFIGSHLVEALRAAGHDVVGVDRRPGAD---------------VVGDLLTLDLA | 49 |
| SEQ ID NO: 196 SEQ ID NO: 197 | |||
| Query | 76 | DCLKNISTVFHLAALPGVRPSWTQFPEYLRCNVLATQRLMEACVQAGVERVVVASSSSVY | 135 |
| | + | ||| |||| ||+||| || |+ ||||+|+ +++ |+||+|||| | |||
| Sbjct | 50 | PLLDGVEYVVHLAGQPGVRESWSQFPAYLAGNLQTTQRLLESLRDRPLKKFVLASTSSVY | 109 |
| Query | 136 | GGADGVMSEDDLPRPLSPYGVTKLAAERLALAFAARGDAELSVGALRFFTVYGPGQRPDM | 195 |
| | || |+||||+||||||+| + | + |||+|||||| ||||| | |||
| Sbjct | 110 | GEVPMPAREDGPAMPVSPYGLTKLAAEKLCDLYGR--TAGIPWVALRYFTVYGPRQRPDM | 167 |
| SEQ ID NO: 198 | |||
| Query | 196 | FISRLIRATLRGEPVEIYGDGTQLRDFTHVSDVVRALMLTASVRDRGSAVLNIGTGSAVS | 255 |
| || | | |||++|||||+||||||+|+| | | |++ +|+| ||||+ | |||
| Sbjct | 168 | AFSRWFNAALDGEPIQIYGDGSQLRDFTYVADAVTATQ-RAALNPVVGVPINVGGGSAVT | 226 |
| SEQ ID NO: 199 | |||
| Query | 256 | VNEVVSMTAELTGLRPCTAYGSARIGDVRSTTADVRQAQSVLGFTARTGLREGLATQIEW | 315 |
| | | + + | +|| ||+| | || + +|| | | ||| | | | |||
| Sbjct | 227 | VREAIRLIAAITGRPIRIRQLPPAPGDMRETRADTERLWREVGFRPSTPLEEGLWQQYRW | 286 |
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeE5 gene is a NDP-hexose 4-epimerase which participates in the conversion of Moe intermediate compound 1 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 2 or 3, as shown in FIGS. 4A-4D.
D. Genes for Phosphoglycerate-Lipid Moiety Biosynthesis
Two genes in cluster 1 were identified that fit this functional profile: moeN5 and moeO5. The phosphoglycerate-moenocinol chain of moenomycin is unusual in containing a cis-allylic ether linkage and an irregular isoprenoid chain of uncertain biosynthetic provenance. Two putative prenyltransferases, moeO5 and moeN5, were identified via in silico analysis of the moe genes and proposed to participate in the production of the phosphoglycerate-lipid moiety (Ostash 2007).
1. moeN5
The product of moeN5 gene translation shows local homology to putative geranylgeranyl pyrophosphate synthase from Chlamidia trachomatis (30% identity and 58% similarity over 56 amino acid fragment). The nucleotide and polypeptide sequences are shown in Tables 57 and 58, respectively. A sequence alignment between moeN5 and the closest homolog identified in the BLAST search is shown in Table 59.
| TABLE 57 |
| DNA Sequence of moeN5. |
| ATGCTCGCCGCCGAGGCCGCCAACCGCGACCATGTCACGCGGTGCGTCGC |
| GCAGACCGGTGGGTCGCCGGACCTGGTGGCGCACACCGCCGCCCTGCGCC |
| TGTACCTGAGGGTGCCCCACTTCCTCACCGAGTGGACGACCGACCCGGAC |
| CGGCGGGCCGCGGTGTCCCGCGCGCTGGCCCTCGACATCGTCTCCATGAA |
| GCTCCTCGACGACCTGATGGACGACGACACCGGACTCGACCGGGTCGAAC |
| TCGCCTGTGTCTGCCTCCGCCTCCACCTGCGGGCGCTGCACGAACTGGAA |
| TCCCTCGCCCGGGACCCCAAGGCGGTGACGGACATCCTGGAGCAGGACGC |
| CGTCCACCTCTGCGGCGGCCAGATACGCACCAAACGCTCTCGGGCGACGA |
| ACCTCCGGGAGTGGCGCGCCCATGCGAGCACCTACGGCTCCACCTTCCTG |
| GGCCGCTACGGGGCACTCGCGGCCGCCTGCGGGGGGGAAGGCCAACCGGC |
| GGACTCCGTAAGGGAGTTCGCAGAGGCTTTCGCCATGACCATCACCATGG |
| CGGACGACCTGACCGACTACGACCGCAACGGCGAGCGGGACGGCAACCTC |
| GCCCATCTGATGCGGACCGGGGCCGTGGCCGGCCAGGACGTCGTGGACCT |
| GCTGGAGGAGCTGCGCGGGCGGGCCCTCGCCGCGGTGGCGGCACCGCCCG |
| GCGCGCCCGGTCTGGTGCCGGTCGTCCACCTCTACACGGACGACGTGCTG |
| GTACGGCTGCTTCCCCGGCACCTGGGGGAGTGA (SEQ ID NO: 20) |
| TABLE 58 |
| Amino Acid Sequence of moeN5 |
| MLAAEAANRDHVTRCVAQTGGSPDLVAHTAALRLYLRVPHFLTEWTTDPD |
| RRAAVSRALALDIVSMKLLDDLMDDDTGLDRVELACVCLRLHLRSLHELE |
| SLARDPKAVTDILEQDAVHLCGGQIRTKRSRATNLREWRAHASTYGSTFL |
| GRYGALAAACGGEGQPADSVREFAEAFAMTITMADDLTDYDRNGERDGNL |
| AHLMRTGAVAGQDVVDLLEELRGRALAAVAAPPGAPGLVPVVHLYTDDVL |
| VRLLPRHLGE (SEQ ID NO: 43) |
| TABLE 59 |
| Sequence Homology of moeN5 |
| gb|EAQ07619.1|Geranylgeranyl pyrophosphate synthetase [Loktanella |
| vestfoldensis SKA53] |
| Length = 293 |
| Score = 40.0 bits (92), Expect = 0.097 |
| Identities = 35/119 (29%), Positives = 52/119 (43%), Gaps = 8/119 (6%) |
| SEQ ID NO: 200 SEQ ID NO: 201 | |||
| Query | 141 | HASTYGSTFLGRYGALAAACGGEGQP-ADSVREFAEAFAMTITMADDLTDYDRNGERDGN | 199 |
| | + |+ |+ | | | | +| |+ ||| + + | | | |+ | | |||
| Sbjct | 167 | HQAKTGALFIAATQMGAVAAGQEAEPWAELGARIGEAFQVADDLRDALCDDATLGKPAGQ | 226 |
| SEQ ID NO: 202 | |||
| SEQ ID NO: 203 | |||
| Query | 200 | LAHLMRTGAVAG---QDVVDLLEELRGRALAAVAAPPGAPGLVPVVHLYTDDVLVRLLP | 255 |
| | ||| | | +++ | |++++ | || | +| | | ||+| | |||
| Sbjct | 227 | DDLHGRPNAVAAYGVQGAVKRFDDILGGAISSIPACPGEAALAQMVRAYAD----RLVP | 281 |
| SEQ ID NO: 204 | |||
The low similarity of moeN5 to other known prenyltransferases can be explained by the intrinsically low sequence homology among different prenyltransferases and the uniqueness of the reactions catalyzed by moeN5 (e.g. the linkage of geranyl and farnesyl pyrophosphates to give C25 isoprene chain). No other genes were identified within the moe clusters which would govern the unusual rearrangement of the central part of moenocinol (Schuricht 2001, Neundorf 2003). Therefore, moeN5 is likely to control both prenyltransfer and C25 chain rearrangement, or the latter step may be controlled by a gene outside the moe cluster. Additionally or alternatively, the rearrangement may occur spontaneously after the formation of the C25 chain.
We disrupted moeN5 in a heterologous S. lividans TK24 host that was previously shown to produce moe A derivatives following integration of the appropriate genes in the chromosome. HPLC-MS analysis showed that the ΔmoeN5 strain accumulated two compounds, 22/23, having similar mass-spectral characteristics (Table 21). As is evident from LC-MS and MS2 analyses of ΔmoeN5 extracts (SD), compounds 22/23 differ from compound 19, which is produced by the parental 38-1+ strain (FIG. 4), primarily in the structure of the polyprenol chain. Whereas moe A and all reported derivatives, including 19, contain an irregular C25 isoprenoid chain, compounds 22/23 have a C15 cis-farnesyl chain. 22 and 23 differ from one another in the structure of unit B (moe A numbering; see FIG. 1), which contains either a carboxyl group (22) or a carboxamide moeity (23). Heterogeneity at this position with regard to the unit B structure has already been reported for other moenomycins (Zehl 2006). The aforementioned results show that moeN5 encodes a prenyltransferase involved in the coupling of a C10 isoprene unit to either the C15 chain of 22/23 or its precursor(s). Based on results presented below, we suggest that the farnesylated trisaccharide precursors 8 and 9/10 are the first possible substrates for the MoeN5-catalyzed reaction (FIGS. 4A-4D). That is, based on the studies of the present invention, it is propose that the polypeptide encoded by the moeN5 gene is a prenyltransferase which participates in the conversion of Moe intermediate compound 8, 9, or 10 in the course of moenomycin biosynthesis to yield a Moe intermediate compound 11, 12 or 13, respectively, as shown in FIGS. 4A-4D. The farnesylated trisaccharides precursors described above antibiotic biological activity.
2. moeO5
The presence of a phosphoglycerate moiety in moe-like antibiotics is without precedent in secondary metabolism, and mechanisms of phosphorus incorporation into moe A have puzzled researchers for years. Gene moeO5, located upstream of the prenyltransferase gene moeN5, was identified as having a translation product with homology to geranylgeranylglyceryl diphosphate synthases (GGGPSs) from various Archaea (27% identity and 43% similarity to GGGPS from Thermoplasma acidophylum) (Nemoto 2003). The nucleotide and polypeptide sequences are shown in Tables 60 and 61, respectively. A sequence alignment between moeO5 and the closest homolog identified in the BLAST search is shown in Table 62.
| TABLE 60 |
| DNA Sequence of moeO5. |
| GTGAACGCCTCACCGCAACTGGACCACCACACGGAACTCCACGCCGCACC |
| ACCGCTCTGGCGGCCGGGACGCGTGCTCGCCCGGCTGCGCGAGCACCAAC |
| CGGGCCCCGTCCACATCATCGACCCCTTCAAGGTCCCGGTGACGGAAGCG |
| GTCGAGAAGGCGGCGGAGCTCACGCGGCTGGGCTTCGCCGCCGTCCTTCT |
| GGCCAGCACCGACTACGAGTCGTTCGAGTCGCACATGGAGCCGTACGTGG |
| CGGCGGTGAAGGCGGCCACCCCGTTACCGGTCGTCCTGCACTTCCCGCCC |
| CGCCCGGGGGCCGGCTTCCCGGTGGTCCGCGGCGCGGACGCGCTCCTGCT |
| GCCCGCGCTGCTGGGCTCGGGCGACGACTACTTCGTCTGGAAGAGCTTCC |
| TCGAGACGCTGGCCGCCTTCCCCGGCCGAATACCCCGCGAGGAGTGGCCC |
| GAGCTGCTCCTCACCGTCGCCCTCACCTTCGGCGAGGACCCCCGCACCGG |
| GGACCTGCTCGGCACCGTGCCGGTGAGCACGGCCTCCACCGAGGAGATCG |
| ACCGGTACCTCCACGTCGCCCGTGCCTTCGGTTTCCACATGGTGTACCTG |
| TACTCGCGCAACGAGCACGTGCCGCCCGAGGTCGTACGCCACTTCCGCAA |
| GGGGCTCGGCCCCGACCAGGTGCTCTTCGTGAGCGGCAACGTCCGCTCCG |
| GGCGGCAGGTCACCGAGTACCTCGACAGCGGGGCGGACTACGTGGGGTTC |
| GCCGGAGCCCTGGAACAGCCGGACTGGCGGTCCGCCCTCGCCGAGATCGC |
| CGGGAGGCGGCCCGCCGCCCCGGCCCGTCCGGGGAGCGGGCGGTGA |
| (SEQ ID NO: 21) |
| TABLE 61 |
| Amino Acid Sequence of moeO5 |
| VNASPQLDHHTELHAAPPLWRPGRVLARLREHQPGPVHIIDPFKVPVTEA |
| VEKAAELTRLGFAAVLLASTDYESFESHMEPYVAAVKAATPLPVVLHFPP |
| RPGAGFPVVRGADALLLPALLGSGDDYFVWKSFLETLAAFPGRIPREEWP |
| ELLLTVALTFGEDPRTGDLLGTVPVSTASTEEIDRYLHVARAFGFHMVYL |
| YSRNEHVPPEVVRHFRKGLGPDQVLFVSGNVRSGRQVTEYLDSGADYVGF |
| AGALEQPDWRSALAEIAGRRPAAPARPGSGR (SEQ ID NO: 44) |
| TABLE 62 |
| Sequence Homology of moeO5 |
| gi|110553682|gb|EAT66825.1|geranylgeranylglyceryl phosphate synthase |
| [Thermofilum pendens Hrk 5] |
| Length = 255 |
| Score = 50.8 bits (120), Expect = 6e−05, Method: Composition-based stats. |
| Identities = 68/236 (28%), Positives = 110/236 (46%), Gaps = 14/236 (5%) |
| SEQ ID NO: 205 | |||
| Query | 25 | VLARLREHQPGPVHIIDPFKVPVTEAVEKAAELTRLGFAAVLLASTDYESFESHMEPYVA | 84 |
| +| ++||| + +||| | | | |+ | +|+++ + | |+ + | | |||
| Sbjct | 9 | ILEKIREHGAIHMTLIDPEKTTPEVAARIAREVAEAGTSAIMVGGSIGVS-EAMTDEVVL | 67 |
| SEQ ID NO: 206 SEQ ID NO:207 | |||
| Query | 85 | AVKAATPLPVVLHFPPRPGAGFPVVRgadalllpallgsgddYFVWKSFLETLAAFPGRI | 144 |
| |+| +| +||+| || | | + | |||+ ++| | + ||+ + ++ | | |||
| Sbjct | 68 | AIKRSTEVPVIL-FPGSPTA---LSRHADAVWFLSVLNSQNPYFITGAQMQG-----API | 118 |
| SEQ ID NO:208 SEQ ID NO:209 | |||
| Query | 145 | PREEWPELLLTVALTFGEDPRTGDLLGTVPVSTASTEEIDRYLHVARAFGFHMVYLY--S | 202 |
| + |+| + || + | |+ | | + | | || ||| | | |||
| Sbjct | 119 | VKRYGLEVLPLGYIIVGEGGAVSIVSYTRPLPFAKPEVVAAYALAAEYMGFQFVYLEGGS | 178 |
| SEQ ID NO:210 | |||
| SEQ ID NO:211 | |||
| Query | 203 | RNEHVPPEWRHFRKGLGPDQVLFVSGNVRSGRQVTEYLDSGADYVGFAGALEQPD | 258 |
| | |||++|+ ||+ | | | +|| | +||| + +|+ + | |||
| Sbjct | 179 | GGEPVPPKIVKMV-KGV-TTLPLIVGGGIRSPEVAKELAKAGADIIVTGTIVEESE | 232 |
| SEQ ID NO:212 | |||
These enzymes couple either C20 or Cu2 isoprene chains to sn-glycerol-1-phosphate via an ether link, thus yielding the first intermediate to archaeal membrane lipids (Nemoto 2003, Soderberg 2001, Tachibana 2000). As well as GGGPSs, moeO5 also contains a so called phosphate-binding enzymes domain (COG1646) which is related to the PcrB-FMN domain. PcrB-like protein encoding genes are also present in bacterial genomes; however, their functions remain unknown. Sequence similarity between moeO5 and GGGPSs, and the structural resemblance between the product of GGGPS activity and moenocinol-phosphoglycerate suggests that phosphoglycerate is incorporated into moe A via a moeO5-assisted transfer of either moenocinol pyrophosphate or its precursor to phosphoglycerate. The possibility cannot be excluded, at this point, that phosphoglycerate (unit G) is attached to the sugar (unit F precursor) followed by a moeO5 transfer of the isoprene chain to the F-G intermediate. Additional biochemical characterizations of moeO5 are currently underway to determine substrate preferences. The sequence analysis of moeO5 (Ostash 2007), combined with the isolation of farnesylated monosaccharide intermediates (see below), suggests that the prenylsynthase MoeO5 couples phosphoglycerate to farnesyl pyrophosphate to yield the first dedicated moe A precursor 1P (FIGS. 4A-4D). This precursor is proposed to serve as the starting point for stepwise addition of the sugars.
E. Transport Genes
Four genes which meet functional criteria as components of ATP-binding cassette (ABC) transport systems have been located in moe cluster 1: moeP5, moeX5, moeD5 and moeJ5.
1. moeP5
Gene moeP5 encodes a putative ATP-binding protein (43% identity and 60% similarity) with no transmembrane domains. MoeP5 is related to DrrA-like family of ATP-ases (Kaur 1997) involved in drug resistance and lipid transport. The nucleotide and polypeptide sequences are shown in Tables 63 and 64 respectively. A sequence alignment between moeP5 and the closest homolog identified in the BLAST search is shown in Table 65.
| TABLE 63 |
| DNA Sequence of moeP5. |
| ATGGGCCATTCCGTCGGTGCCCGAGAGGGGTACCACGGCATGTCCGAGCC |
| CGCCGACCGCAAGATTCTCCTGCAGGCGCGCGGCGTCGTGAAACGCTACA |
| AGCGCCGCCGCGTCCTGACCGGGGTCGATCTTGTCGTGCACGCGGGCGAG |
| GTCGCCGCGATCGTCGGCAGCAACGGGACGGGCAAGTCCACCCTGCTCAA |
| GATCTGCGCCGGTCTGCTCTCCCCCGACAAAGGACGGGTCACCGTCTCCG |
| GCCACCTCGGCTACTGCCCGCAGAACGCGGGGGTCATGGGCTTCCTGACC |
| CCCCGGGAGCACTTCACCCTCTTCGGCACCGGCCGGGGCCTGAGCCGCCG |
| GGAGTCCGACCGCCGCGGCCGGAGACTCGCGGGAGAGCTCGACTGGGCCC |
| CCGCGGAGGGCGTCCTTGCCAAGGACCTGTCGGGAGGAACCCGCCAGAAG |
| CTGAACGTCGTCCTGTCGGCCCTGGGAGACCCGGACCTGCTGCTGCTCGA |
| CGAGCCCTACCAGGGCTTCGACCACGGCTCCTACGTGGACTTCTGGCAGA |
| GCGTCTGGGAGTGGCGCGAGGCGGGCAAGGCCGTCGTCGTGGTGACGCAC |
| ATGCTCAACCAGCTCGACCGGGTGGACCAGGTGCTGGACCTCACCCCCGG |
| CAAAGGAAGGGGCAACCGATGA (SEQ ID NO: 22) |
| TABLE 64 |
| Amino Acid Sequence of moeP5 |
| MGHSVGAREGYHGMSEPADRKILLQARGVVKRYKRRRVLTGVDLVVHAGE |
| VAAIVGSNGTGKSTLLKICAGLLSPDKGRVTVSGHLGYCPQNAGVMGFLT |
| PREHFTLFGTGRGLSRRESDRRGRRLAGELDWAPAEGVLAKDLSGGTRQK |
| LNVVLSALGDPDLLLLDEPYQGFDHGSYVDFWQSVWEWREAGKAVVVVTH |
| MLNQLDRVDQVLDLTPGKGRGNR (SEQ ID NO: 45) |
| TABLE 65 |
| Sequence Homology of moeP5 |
| gi|89319945|gb|EAS11435.1|ABC transporter related [Mycobacterium flavescens |
| PYR-GCK] |
| Length = 243 |
| Score = 120 bits (301), Expect = 5e−26 |
| Identities = 79/180 (43%), Positives = 105/180 (58%), Gaps = 0/180 (0%) |
| Frame = +1 |
| SEQ ID NO: 213 | |||
| Query | 115 | LTGVDLVVHAGEVAAIVGSNGTGKSTLLKICAGLLSPDKGRVTVSGHLGYCPQNAGVMGF | 294 |
| | |||| + ||| +|| ||+||||++|| | |+|| | | || |||||| | | |||
| Sbjct | 46 | LRGVDLTLQPGEVVGLVGENGSGKSTIMKILVGELAPDAGTVVRSGVLGYCPQQPVVYER | 105 |
| SEQ ID NO: 214 | |||
| Query | 295 | LTPREHFTLFGTgrglsrresdrrgrrlagELDWAPAEGVLAKDLSGGTRQKLNVVlsal | 474 |
| || || || ++ | | | | + | | ||||| |||+ |+ | | |||
| Sbjct | 106 | LTCDEHIELFARAYRMTHEGERRARRDLYEALGFERYAGTRADRLSGGTLAKLNLTLAML | 165 |
| Query | 475 | gdpdlllldEPYQGFDHGSYVDFWQSVWEWREAGKAVVVVTHMLNQLDRVDQVLDLTPGK | 654 |
| || +||||||| ||| +|+ || | |+ |++|++++| + | |+++ | |+ | |||
| Sbjct | 166 | ADPQVLLLDEPYAGFDWDTYLKFWDLVARRRDDGRSVLIISHFVADEHRFDRIVKLCDGR | 225 |
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeP5 gene is a ABC transporter ATP-binding protein (Table 4).
2. moeX5
Downstream of the moeP5 gene is the moeX5 gene. The putative translation product shows homology to the N-terminal half of predicted bacterial membrane proteins (26% identity and 40% similarity). The nucleotide and polypeptide sequences are shown in Tables 66 and 67, respectively. A sequence alignment between moeX5 and the closest homolog identified in the BLAST search is shown in Table 68. Using topology prediction program TMHHM, 6 transmembrane helices were identified in the moeX5 protein. It is assumed that the moeP5 and moeX5 proteins are two elements of a transport system in which moeX5S is transporter and moeP5 energizes the transport via ATP hydrolysis.
| TABLE 66 |
| DNA Sequence of moeX5. |
| ATGACGGCCACCCTGCGGATGGCGGAGATGACCTTCCGCGAACTGCTGCG |
| CCGGCGGGGCGTGCTGGGCCTGCTGCTCCTGGTCCCGCTCGTCTTCTACC |
| TCGGGCGTTACGACCAGACCGGCCAGGCGGTCCGGTTCGCCAGCCTCGGG |
| GTGGGCTTCGCGGTCAGCGCCGCGGCCCTCTTCTCCGCGGTCGGCGGCCG |
| GGAGATCGAACCGCTCCTGGCCCTCTCCGGGTTCCGCCCGCTCCAGCTCT |
| TCCTGGGCCGCCTGCTGGCCCTCCTCACCGCCGGCATGGGCGTGTCCGCC |
| CTCTACGCCGTGATCATCCTGGTCGGGCAGGACGTGGCGCACCCGCGGGC |
| CGTCGCGGTGGAACTGGCGCTGAGCACACTGGTGGCGGTGCCGCTGGGAC |
| TGCTGCTCGGGGCGGCCGTGCCACGGGACATGGAGGGCGCCCTGCTGCTG |
| ATCTCCGTCATCGGCGCCCAGATGGTGATGGATCCGGCCAAGGATTCGGC |
| CAAGGTGCTTCCCTTCTGGTCGACCCGGGAGATCATCACCTACGCGGTCG |
| ACGGCGCGGACAGCGGGTCGTTCGACTCCGGGGTGGCCCACGCCGTCGGA |
| GTGACGCTGCTGCTGGTCGCGGTGAGCGGTTGCGTGACGGCGGGCCGATT |
| GCGCCGCCGGCGCCATCTGCAATTCGCGTGA (SEQ ID NO: 23) |
| TABLE 67 |
| Amino Acid Sequence of moeX5 |
| MTATLRMAEMTFRELLRRRGVLGLLLLVPLVFYLGRYDQTGQAVRFASLG |
| VGFAVSAAALFSAVGGREIEPLLALSGFRPLQLFLGRLLALLTAGMGVSA |
| LYAVIILVGODVAHPRAVAVELALTTLVAVPLGLLLGAAVPRDMEGALLL |
| ISVIGAQMVMDPAKDSAKVLPFWSTREIITYAVDGADSGSFDSGVAHAVG |
| VTLLLVAVSGCVTAGRLRRRRHLQFA (SEQ ID NO: 46) |
| TABLE 68 |
| Sequence Homology of moeX5 |
| gb|EAS99725.1|putative ABC transporter membrane protein [Mycobacterium, sp. |
| KMS] |
| Length = 500 |
| Score = 55.5 bits (132), Expect = 2e−06 |
| Identities = 63/237 (26%), Positives = 96/237 (40%), Gaps = 20/237 (8%) |
| SEQ ID NO: 215 SEQ ID NO: 216 | |||
| Query | 4 | TLRMAEMTFRELLRRRGVLGLLLLVPLVFYLGR-----------YDQTGQAVRFASLG-- | 50 |
| || + + +| | +|+|||||| | +|| | + |+ | | |||
| Sbjct | 12 | TLLLTRSFITDYVRNPVNLIMLILVPLVFVLVAAGSIADAMELLQGRTGAATQTATSGWA | 71 |
| SEQ ID NO: 217 | |||
| SEQ ID NO: 218 | |||
| Query | 51 | VGFAVSAAALFSAVGGREIEPLLALSGFRPLQLFLGRL-LALLTAGMGVSALYAVIILVG | 109 |
| || | | | + | |+| +| | || ||+ |||+ + | |||
| Sbjct | 72 | AGFLSGLAMFQIRSARRADKRLQLAGLPAARLLAARAGTGLLMAGL-VSAVALAALAAR | 130 |
| SEQ ID NO: 219 | |||
| Query | 110 | QDVAHPRAVAVELALTTLVAVPLGLLLGAAVPRDMEGALLLISVIGAQMVMDPAKDSAK- | 168 |
| + +| | | + |+ + +| |+|| + + ||++++ + + + || | |||
| Sbjct | 131 | TGIDNPARVIVGTLMFALIYLAIGALVGAVTADPVNGAVIILLIWMIDVFVGPAGSGGDY | 190 |
| SEQ ID NO: 220 SEQ ID NO: 221 | |||
| Query | 169 | VLPFWSTREIITYAVDGADSGSF----DSGVAHAVGVTLLLVAVSGCVTAGRLRRRR | 221 |
| | | +| + | | | ||| | | || + | ||| | |||
| Sbjct | 191 | VATRWFPTHFVTLWMVGTPSHHAGRLGDLGVASVWMVGALAVAGTVVSAGSRTGRRR | 247 |
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeX5 gene is a ABC transporter membrane protein (Table 4).
3. moeD5 and moeJ5
Two other genes, moeD5 and moeJ5, encode proteins that both contain a nucleotide binding domain in the C-terminal region, and transmembrane segments (TMS) in the N-terminal half (5 TMS in moeJ5 and 6 TMS in moeD5 according to TMHHM program).
MoeD5 and moeJ5 are 40.9% similar to each other at the amino acid level, and display homology to putative and known ABC transporters/ABC transporter ATP binding proteins (41% identity and 55% similarity). The nucleotide and polypeptide sequences of moeD5 are shown in Tables 69 and 70, respectively. A sequence alignment between moeD5 and the closest homolog identified in the BLAST search is shown in Table 71. The nucleotide and polypeptide sequences of moeJ5 are shown in Tables 72 and 73, respectively. A sequence alignment between moeJ5 and the closest homolog identified in the BLAST search is shown in Table 74. The conserved domain search showed that moeD5 and moeJ5 are most similar to transporters from DPL and MRP families involved in drug, polypeptide, lipid and anionic substances transport (Chang 2003). In its domain architecture, the moeD5 translation product is similar to the well studied E. coli ABC transporter MsbA which also contains only one 6 TMS transmembrane domain and 1 nucleotide binding domain (McKeegan 2003). It is possible that a moeD5/moeJ5 heterodimer functions as an ATP-dependent pump. Additionally or alternatively, two ABC transporter systems may be involved in moe A efflux and/or its intramycelial transport. Multiple transport mechanisms are common for many organisms producing different antibiotics (Wilson 1999, Mendez 2001), in particular peptidoglycan biosynthesis inhibitors (Sosio 2003).
| TABLE 69 |
| DNA Sequence of moeD5. |
| GTGCTGCGC |
| GGCTCGGCCCGCACCTACTGGACCCTCACCGGTCTGTGGGTCCTGCTGCG |
| GGCGGGAACCCTGGTGGTGGGCCTGCTGTTCCAGCGGCTGTTCGACGCGC |
| TGGGCGCGGGCGGGGGCGTGTGGCTGATCATCGCGTTGGTGGCCGCGATC |
| GAGGCGGGACGGCTGTTCCTCCAGTTCGGCGTGATGATCAACAGGCTGGA |
| GCCGCGGGTCCAGTACGGCACCACGGCGCGGCTGCGGCACGCCCTGCTGG |
| GATCGGCCCTGCGCGGGTCGGAGGTGACGGCCCGCACCAGCCCCGGCGAG |
| TCCCTGCGAACGGTGGGCGAGGACGTCGACGAGACGGGGTTCTTCGTCGC |
| CTGGGCGCCGACGAACCTCGCCCACTGGCTGTTCGTCGCCGCGTCGGTCA |
| CGGTGATGATGCGGATCGACGCCGTGGTCACCGGCGCCCTCCTCGCCCTC |
| CTCGTCCTGCTGACGCTGGTCACCGCGCTGGCCCACAGCCGGTTCCTGCG |
| GCACCGGCGGGCCACCCGGGCCGCGTCCGGGGAGGTGGCGGGAGCCCTGC |
| GGGAGATGGTGGGCGCGGTGGGCGCGGTGCAGGCCGCCGCCGCCGAGCCG |
| CAGGTCGCCGCGCACGTCGCCGGGCTGAACGGCGCCCGTGCCGAAGCCGC |
| GGTGCGGGAGGAGCTGTACGCCGTCGTCCAGCGCACGGTGATCGGCAACC |
| CGGCCCCGATCGGGGTCGGCGTGGTGCTGCTGCTGGTCGCGGGGCGGATG |
| GACGAGGGGACCTTCAGCGTCGGCGATCTCGCCCTGTTCGCCTTCTACCT |
| GCAGATCCTGACCGAGGCCCTGGGGTCGATCGGCATGCTGTCCGTGCGGT |
| TGCAGCGGGTCTCGGTGGCGCTCGGCCGGATCACCAACAACCTCGGCTGC |
| CGGCTGCGGCGGTCCCTGGAGCGGGCCAGTCCGCCGATCGCGTCCGACGC |
| GCCGGGAGGGACCGGCGAGGGGGCCGCCGCCCCGGACGCCGGGCCGGAGC |
| CCGCCCCGCCCCTGCGGGAACTGGCCGTGCGCGGGCTGACGGCCCGCCAC |
| CCCGGGGCGGGGCACGGCATAGAGGACGTGGACCTGGTGGTGGAGCGGCA |
| CACCGTCACCGTGGTCACCGGCCGGGTCGGTTCCGGCAAGAGCACCCTGG |
| TCCGGGCCGTCCTCGGACTGCTCCCGCACGAGCGGGGCACCGTGCTGTGG |
| AACGGCGAACCGATCGCCGACCCCGCGTCGTTCCTGGTGGCGCCGCGCTG |
| CGGGTACACCCCGCAGGTCCCGTGTCTGTTCAGCGGGACGGTGCGGGAGA |
| ACGTCCTGCTGGGCCGGACGGCGCGGCCTTCGACGAGGCCGTGCGCCTC |
| GCCGTGGCGGAGCCCGACCTGGCGGCGATGCAGGACGGCCCGGACACCGT |
| GGTGGGCCCGCGGGGCCTGCGCCTCTCGGGCGGGCAGATCCAGCGGGTCG |
| CGATCGCCCGCATGCTGGTCGGCGACCCCGAACTCGTGGTGCTGGACGAC |
| GTCTCCAGTGCCCTGGACCCGGAGACCGAGCACCTGCTGTGGGAGAGGCT |
| GCTGGACGGGACGCGGACCGTGCTCGCGGTCTCCCACCGGCCCGCTCTGC |
| TGCGCGCGGCCGACCGCGTGGTGGTGCTCGAGGGCGGGCGGGTGGAGGCC |
| TCGGGCACCTTCGAGGAGGTCATGGCGGTCTCCGCCGAGATGGGCCGGAT |
| CTGGACGGGTGCGGGTCCGGGGGGCGGGGACGCCGGGCCCGCTCCGCAGA |
| GCCCTCCCGCGGGGTGA (SEQ ID NO: 24) |
| TABLE 70 |
| Amino Acid Sequence of moeD5 |
| VLR |
| GSARTYWTLTGLWVLLRAGTLVVGLLFQRLFDALGAGGGVWLIIALVAAI |
| EAGRLFLQFGVMINRLEPRVQYGTTARLRHALLGSALRGSEVTARTSPGE |
| SLRTVGEDVDETGFFVAWAPTNLAHWLFVAASVTVMMRIDAVVTGALLAL |
| LVLLTLVTALAHSRFLRHRRATRAASGEVAGALREMVGAVGAVQAAAAEP |
| QVAAHVAGLNGARAEAAVREELYAVVQRTVIGNPAPIGVGVVLLLVAGRM |
| DEGTFSVGDLALFAFYLQILTEALGSIGMLSVRLQRVSVALGRITNNLGC |
| RLRRSLERASPPIASDAPGGTGEGAAAPDAGPEPAPPLRELAVRGLTARH |
| PGAGHGIEDVDLVVERHTVTVVTGRVGSGKSTLVRAVLGLLPHERGTVLW |
| NGEPIADPASFLVAPRCGYTPQVPCLFSGTVRENVLLGRDGAAFDEAVRL |
| AVAEPDLAAMQDGPDTVVGPRGLRLSGGQIQRVAIARMLVGDPELVVLDD |
| VSSALDPETEHLLWERLLDGTRTVLAVSHRPALLRAADRVVVLEGGRVEA |
| SGTFEEVMAVSAEMGRIWTGAGPGGGDAGPAPQSPPAG (SEQ ID |
| NO: 47) |
| TABLE 71 |
| Sequence Homology of moeD5 |
| ref|YP_075256.1|ABC transporter ATP-binding protein [Symbiobacterium |
| thermophilum IAM 14863] |
| Length = 590 |
| Score = 372 bits (956), Expect = 2e−101 |
| Identities = 233/559 (41%), Positives = 313/559 (55%), Gaps = 22/559 (3%) |
| SEQ ID NO: 222 SEQ ID NO: 223 | |||
| Query | 24 | LVVGLLFQRLFDALGAGGGV----WLIIALVAAIEAGRLFLQFGVMINRLEPRVQYGTTA | 79 |
| +| ||| | || | | | ||||+ | |+ | | |||
| Sbjct | 33 | VVPGLLTQAFFDRLTGAAPVALDPWAIIALLMAAAVARVAALAAGFFASATGRESMANLL | 92 |
| SEQ ID NO: 251 | |||
| SEQ ID NO: 224 | |||
| Query | 80 | RLRHALLGSALRGSEVTARTSPGESLRTVGEDV---DETGFFVAWAPTNLAHWLFVAASV | 136 |
| | |+ | ||||+| + +|| +|| |+ + | | ++ | |||
| Sbjct | 93 | R-RNVLERILEMPGAAALPESPGEALNRLRDDVLHAEETADFMLDV---VGQTTFAAVAL | 148 |
| SEQ ID NO: 234 SEQ ID NO: 225 | |||
| Query | 137 | TVMMRIDAVVTGALLALLVLLTLVTALAHSRFLRHRRATRAASGEVAGALREMVGAVGAV | 196 |
| ++++|||| +| + | |+ +|| | |++|| +| |+ | + |+ +| || | |||
| Sbjct | 149 | SMLLRIDARLTVLVFLPLALVLVVTRAVGRRILQNRRWSREATARVTALIAELFASVQAV | 208 |
| Query | 197 | QAAAAEPQVAAHVAGLNGARAEAAVREELYAVVQRTVIGNPAPIGVGVVLLLVAGRMDEG | 256 |
| | | || +| ||+ || | | | + | | ++ | + +| |++||| | | | | |||
| Sbjct | 209 | QVAGAESRVVAHLRRLNDERRRAMVADRLLTQVLESIALNASSVGTGLILLLGARTMATG | 268 |
| SEQ ID NO: 226 | |||
| Query | 257 | TFSVGDLALFAFYLQILTEALGSIGMLSVRLQRVSVALGRITNNL-GCRLRRSLERASPP | 315 |
| |+||+ ||| +|| + + | ++ || |+ | | | | | | | |||
| Sbjct | 269 | QFTVGEFALFVYYLGYVADFTHFAGRWLALYRQAGVAKDRLLALLQGAPPTRLLRRTEIP | 328 |
| Query | 316 | IASDAPGGTGEGAAAPDAGPEPAPPLRELAVRGLTARHPGAGHGIEDVDLVVERHTVTVV | 375 |
| + | |+ | || ||||| ||| |+| +| ||| | | + | + ||+ | |||
| Sbjct | 329 | LRGPVP-------VPPEPPPPPAEPLRELRTEGLTYRYPDSGRGIEGVSLTIPRGSFTVI | 381 |
| SEQ ID NO:227 | |||
| Query | 376 | TGRVGSGKSTLVRAVLGLLPHERGTVLWNGEPIADPASFLVAPRCGYTPQVPCLFSGTVR | 435 |
| |||||||+||+| ++|||| + ||| |||||+||| ||+| ||| ||||| |||||+ | |||
| Sbjct | 382 | AGRVGSGKTTLLRVLMGLLPAQAGTVYWNGEPVADPGSFMVPPRCAATPQVPILFSGTLA | 441 |
| SEQ ID NO: 228 | |||
| Query | 436 | ENVLLGRDG--AAFDEAVRLAVAEPDLAAMQDGPDTVVGPRGLRLSGGQIQRVAIARMLV | 493 |
| ||+ +| | | || || | ||| |+|| +| || ||+||||||+|| | ||| + | |||
| Sbjct | 442 | ENIRMGLDATEAEVAAAVYDAVLERDLAGMEDGLETQVGARGVRLSGGQVQRTAAARMFL | 501 |
| SEQ ID NO: 229 | |||
| Query | 494 | GDPELVVLDDVSSALDPETEHLLWERLL-DGTRTVLAVSHRPALLRAADRVVVLEGGRVE | 552 |
| |||+++||+||||| ||| +||||| | | |||| | || ||++++|+ ||| | |||
| Sbjct | 502 | RRPELLIMDDLSSALDVETEQILWERLFRQRDVTCLVVSHREAALRRADQIILLKDGRVV | 561 |
| Query | 553 | ASGTFEEVMAVSAEMGRIW | 571 |
| || +|++| |||| +| | |||
| Sbjct | 562 | DRGTLDELLARSAEMRALW | 580 |
| TABLE 72 |
| DNA Sequence of moeJ5. |
| CTGCGCGGTGAACGGACCGCCGTGGCGCTGCTCGCCCTCCTGGTCCCCGC |
| GGGGATGGGGCTCCAGCTGGTGGCGCCCTACCTGCTGCGCGGATTCATCG |
| ACGGGGCGCTCTCCGGCGACTCCCGGAAGACGCTGCTGGACCTCGCCGCC |
| TGGTCCCTGGCGGCCGCCGTCGGGACGCTCGTGGTCACCGCGGGCACCGA |
| GGCGCTGTCCTCACGGGTCGCCTGGCGCAGCACCAACCGGTTGCGCGCGG |
| ACCTGGTCGAGCACTGCCTGAGCCGGCCGCCGGGCTTCTACCGCAAGCAT |
| CCGCCCGGCGAACTCGTCGAGCGGATGGACGGCGAGGTCACCCGGCTCGC |
| CGCGGTGATGTCGACGCTGCTGCTGGAACTGCTGGCGCAGGCACTGCTGA |
| TCGTCGGCATCCTCGTCGCCCTGTTCCGGCTGGAATGGCGGCTGGCCCTG |
| GTGGTCGCCCCGTTCGCGGCAGGCACCCTCCTGCTGCTGCGGACCCTGGT |
| GGGCCGCGCCATGCCCTTCGTCACCGCGCGGCAGCGGGTCGCGGCGGACC |
| TGCAGGGCTTCCTCGAGGAGCGCCTCGCGGCGGCGGAGGACCTCCGCGTC |
| AACGGGGCCTCGCGGTACACCCTGCGGGAACTCGGCGACCGGCAGGACGA |
| CCTGTACCGGAAGGCCCGCGACGCGGCGCGGGCCTCGGTCCGCTGGCCCG |
| CCACGGTGCAGGGCCTGTCCGCCGTCAGCGTCGTCCTGGCCCTGGCGGTC |
| AGCGCCTGGCTGCACGCCCGCGGACAGCTCTCCACGGGGACGGCCTTCGC |
| CTCCCTGTCCTACGCGATGCTGCTGCGCCGCCCCCTGCTCGCGGTCACCA |
| CCCGCTTCCGCGAACTCGAGGACGCCGCCGCGAGCGCCCAGCGGCTGAGG |
| GACCTGCTGGGCCACGGGACGGCGGCGCCCCGCACGGGACGCGGGACGCT |
| GCCGGCCGGACTGCCCGGAGTCCGCTTCGACGGGGTCTCCTTCGGCTACG |
| AGCCCGACGAGCCGGTGCTGCGGGACGTCTCCTTCACCCTGCGCCCCGGC |
| GAACGCCTCGGCGTCGTGGGACGCACCGGCAGCGGCAAGTCCACCGTGGT |
| CCGGCTGCTGTTCGGGCTCCACCACCCGGGGGCGGGCTCGGTGTCGGCAG |
| GCGGCCTGGACCTGACGGAGATCGATCCCCGGGCGCTGCGCAGCCGGGTC |
| GCGCTGGTCACCCAGGAGGTGCACGTCTTCCACGCCTCGCTGCGGGACAA |
| CCTCACCTTCTTCGACCGCTCCGTCCCCGACGACCGGCTGCGCGCCGCTC |
| TCGGCGAGGCCGGGCTCGGCCCCTGGCTGCGCACCCTGCCCGACGGTCTG |
| GACACGCCGCTCGGCGCCGGGGCCCGCGGCATGTCCGCGGGCGAGGAGCA |
| GCAGCTCGCGCTGGCCAGGGTGTTCCTGCGCGATCCGGGGCTGGTCCTGA |
| TGGACGAGCCGACGGCCCGGCTGGATCCGTACAGCGAGCGGCTCCTGATG |
| CCCGCGCTGGAGCGGCTGCTCGAGGGCCGCACCGCCGTCGTGGTGGAGCA |
| CCGCCCGCACCTGCTCCGGAACGTCGACCGGATCCTGGTGCTGGAGGAGG |
| GGAAGGTCGCCGAGGAGGGGGAGCGGAGGGTCCTCGCCGCCGATCCCGGG |
| TCGCGCTTCCACGCACTCCTCCGCACGGCCGGAGCCACCCGGTGA (SEQ |
| ID NO: 25) |
| TABLE 73 |
| Amino Acid Sequence of moeJ5 |
| LRGERTAVALLALLVPAGMGLQLVAPYLLRGFIDGALSGDSRKTLLDLAA |
| WSLAAAVGTLVVTAGTEALSSRVAWRSTNRLRADLVEHCLSRPPGFYRKH |
| PPGELVERMDGDVTRLAAVMSTLLLELLAQALLIVGTLVALFRLEWRLAL |
| VVAPFAAGTLLLLRTLVGRAMPFVTARQRVAADLQGFLEERLAAAEDLRV |
| NGASRYTLRELGDRQDDLYRKARDAARASVRWPATVQGLSAVSVVLALAV |
| SAWLHARGQLSTGTAFASLSYAMLLRRPLLAVTTRFRELEDAAASAQRLR |
| DLLGHGTAAPRTGRGTLPAGLPGVRFDGVSFGYEPDEPVLRDVSFTLRPG |
| ERLGVVGRTGSGKSTVVRLLFGLHHPGAGSVSAGGLDLTETDPRALRSRV |
| ALVTQEVHVFHASLRDNLTFFDRSVPDDRLRAALGEAGLGPWLRTLPDGL |
| DTPLGAGARGMSAGEEQQLALARVFLRDPGLVLMDEPTARLDPYSERLLM |
| PALERLLEGRTAVVVEHRPHLLRNVDRILVLEEGKVAEEGERRVLAADPG |
| SRFHALLRTAGATR (SEQ ID NO: 48) |
| TABLE 74 |
| Sequence Homology of moeJ5 |
| gi|51892564|ref|YP_075255.1|ABC transporter ATP-binding protein |
| [Symbiobacterium thermophilum |
| IAM 14863] |
| Length = 582 |
| Score = 375 bits (963), Expect = 3e−102, Method: Composition-based stats. |
| Identities = 249/545 (45%), Positives = 335/545 (61%), Gaps = 5/545 (0%) |
| SEQ ID NO: 230 SEQ ID NO: 231 | |||
| Query | 19 | MGLQLVAPYLLRGFID---GALSGDSRKTlldlaawslaaavgtlvvtagtEALSSRVAW | 75 |
| +||||+ | +|| |+| | +|| +|+ || + | || || |+| | |||
| Sbjct | 34 | IGLQLINPQILRRFLDTAAGEVSGGP--SLVTLALAFIGVAFAVQAVTVLARYLSESVSW | 91 |
| SEQ ID NO: 232 SEQ ID NO: 233 | |||
| Query | 76 | RSTNRLRADLVEHCLSRPPGFYRKHPPGELVERMDGDVTRLAAVMSTlllellaqallIV | 135 |
| |+|| ||||| |||| ||+++ |||+|||+||||| |+ | | + +|| +|++ | |||
| Sbjct | 92 | RATNELRADLAEHCLRLDLGFHKRRTPGEMVERIDGDVTALSQFFSQLFIGVLANLVLML | 151 |
| Query | 136 | GILVALFRLEWRLALVVAPFaagtllllrtlvgrAMPFVTARQRVAADLQGFLEERLAAA | 195 |
| |||| ||| +|| + + ||| || +| + ++| | +++ +|+ |+| | |+ | |||
| Sbjct | 152 | GILVLLFREDWRAGVAMTLFAAFTLWVLGRIHELSVPVWTRQRQASAEFYGYLGEVLSGT | 211 |
| Query | 196 | EDLRVNGASRYTLRELGDRQDDLYRKARDAARASVRWPATVQGlsavsvvlalavsaWLH | 255 |
| | +| || + | | ||+ |+ +| || |+| | |||+ | |||
| Sbjct | 212 | EAIRAGGARGWALHRFLRNVQDFYRQNLAASMMFWLTWSTSIVTFAVGAALSLGVGAWLY | 271 |
| Query | 256 | ARGQLSTGTAFASLSYAMLLRRPLLAVTTRFRELEDAAASAQRLRDLLGHGTAAPRTGRG | 315 |
| ||| ++ || + | |||||+ + | +||+ | |+ +|+ +| | | | |||
| Sbjct | 272 | ARGGVTVGTVYLLFHYTELLRRPIEQIRTHLQELQRAGAAVERVEELFAQRTRVPDGPGR | 331 |
| Query | 316 | TLPAGLPGVRFDGVSFGYEPDEPVLRDVSFTLRPGERLGVVGRTGSGKSTVVRLLFGLHH | 375 |
| || | | |||| ||| |||||| + ||| +|++|||||||||+ ||| + | |||
| Sbjct | 332 | ALPPGPLSVELVGVSFAYEPGAPVLRDVDVRIEPGEVVGLLGRTGSGKSTLARLLLRFYD | 391 |
| Query | 376 | PGAGSVSAGGLDLTEIDPRALRSRVALVTQEVHVFHASLRDNLTFFDRSVPDDRLRAALG | 435 |
| | || | ||+|| | +|+|| |||+| +| ++||||||| | | || | | | |||
| Sbjct | 392 | PDAGIVRLGGVDLREATVAGVRARVGFVTQDVQLFAGTVRDNLTFFSPEVSDGRLLAVLE | 451 |
| Query | 436 | EAGLGPWLRTLPDGLDTPLGAGARGMSAGEEQQLALARVFLRDPGLVLMDEPTARLDPYS | 495 |
| | ||||||++|| |||||| +| |+|||| | |||||||| |||||++|| ++|||| + | |||
| Sbjct | 452 | ELGLGPWLQSLPQGLDTPLESGGGGLSAGEAQLLALARVFLADPGLVILDEASSRLDPAT | 511 |
| Query | 496 | ERLLMPALERLLEGRTAVVVEHRPHLLRNVDRILVLEEGKVAEEGERRVLAADPGSRFHA | 555 |
| | |+ |++||||||| +++ || + | ||+||+|+| | | | ||||| ||| | |||
| Sbjct | 512 | ESLVERAVDRLLEGRTGIIIAHRLATVERADTILILEDGRVVEYGPRAELAADPASRFFR | 571 |
| Query | 556 | LLRTA | 560 |
| +|| | |||
| Sbjct | 572 | MLRAG | 576 |
Based on the studies of the present invention, it is propose that the polypeptide encoded by the moeD5 and moeJ5 genes are ABC transporters (Table 4).
G. Regulatory Genes
Genes governing the production of early building blocks of antibiotics are usually part of gene cluster for a given secondary metabolite. For example, NDP-hexoses, the first intermediates to many glycosylated antibiotics are produced from hexose-1-phosphate and NTP by dedicated nucleotidyltransferases encoded within gene clusters for biosynthesis of secondary metabolites (Kudo 2005, Luzhetskyy 2005, Murrell 2004). The association of genes for biosynthesis of isopentenyl pyrophosphate (IPP) and those for certain isoprene-derived antibiotics has also been recently demonstrated (Durr 2006, Kawasaki 2006, Dairi 2005). Genes for activated sugar and IPP biosynthesis were not identified within the moe clusters. This, along with the absence of dedicated regulatory moe genes (as yet, no traditional regulatory sequences were identified) poses intriguing questions about temporal control of enzyme “building blocks” apparently required for Moe A biosynthesis in S. ghanaensis.
It was found that the moeA5, moeO5, moeR5 and moeE5 genes contain codon “TTA” (2 were identified in moeE5). In the S. coelicolor A3(2) genome, only 145 genes out of 7825 possess TTA codons (Chater 2006).
The regulatory role of the TTA codons in genes for transcriptional activators of antibiotic production has been established (Rebets, 2006, Bibb 2005). For example, the gene for leucil tRNAUUA is expressed efficiently in late stationary phase of growth in S. coelicolor, thus exerting temporal control over the expression of antibiotic biosynthesis genes (Leskiw 1993). The moe clusters appears to lack a regulatory genes containing TTA codon(s), while the TAA condon is present in structural moe genes. It is likely that the different efficiency of codon TTA translation in different growth phases is an important mechanism of the temporal regulation of moe A production. However, mistranslation of TTA codons (Trepanier 2002) can negate the importance of such a suggested regulatory mechanism.
One of the unusual features of the moe clusters is the absence of pathway-specific regulatory genes. Rare TTA codons present in several moe genes were speculated to control the onset of moe A production (Ostash 2007). Mutations in the gene bidA, which encodes LeutRNAUUA, are known to affect many processes in streptomycetes, and antibiotic production is one of them (Chater 2006). It is logical to suppose that the regulatory effect of LeutRNAUUA is exerted at the translation level—i.e., that a scarcity of this tRNA until late in the cell cycle might limit the expression of TTA-containing genes. However, the pleiotropic nature of bidA mutants (Hodgson 2000), the presence of TTA codons mainly in regulatory genes and, finally, the mistranslation of TTA codons (Trepanier 2002) may lead to overinterpretation of the role of bldA gene. In this respect, moe cluster 1 is a rare case in which several TTA codons are located within structural genes, making it easier to link the bldA gene to antibiotic production.
To examine whether bidA is important for moe A biosynthesis, S. lividans J1725 carrying a mutated bldA gene (Leskiw 1991) was used. A bioassay of methanol extracts from the strains shows that J1725 coexpressing moeno38-1 and plasmid pUJ584, which carries the intact bidA gene, produced compound 19 (FIG. 14, spot 3) whereas a moeno38-1+ control strain carrying the empty vector pIJ303 did not (FIG. 14, spot 2). Evidently, the I gene regulates moe A production. Expression of pJ584 in the βmoeN5 strain did not, however, enhance the production of moe A intermediate 23, as judged by LC-MS and bioassays. This experiment suggests that increasing bidA expression above wild type levels does not produce a concomitant increase in antibiotic expression, implying that other factors limit the production of moenomycins. The identity of 19 produced in 38-b 1+pIJ584+J1725 strain was also confirmed by MS analysis (data not shown).
The wild-type S. ghanaensis strain produces moe A at a very low level, which complicates the analysis of metabolites produced by wild-type and recombinant S. ghanaensis strains. Thus, a means to increase moe expression is useful. The moe biosythesis-related genes of the invention are useful for the enrichment (i.e., overpression of moe and moe precursor molecules. In one embodiment, the invention provides a cell (prokaryotic or eukaryotic) which is genetically engineered to express one or more moe biosynthesis-related polypeptides encoded by the moe biosynthesis related genes of the invention as a means of expressing moe, a moe precursor molecule or chemical derivative thereof. In one embodiment the cell comprises a vector encoding one or more one or more moe biosynthesis-related genes of the invention. Methods useful for cloning and expression of bacterial genes in both prokaryotes and eukaryotes are well recognized in the art.
Regulatory genes (e.g., repressors, activators) may be identified by methods described above and by methods known in the art. As many bacterial genes involved in antibiotic production are expressed as operons (a cluster of structural genes with shared promoter or operator and terminator sequences), it is possible that a single protein or set of proteins may be responsible for the coordinated expression or repression of the entire moe cluster 1 and/or moe cluster 2 genes. Numerous such regulatory genes have already been identified in various antibiotic producing actinomycetes (e.g., redD involved in undecylprodigiosin biosynthesis regulation; actII-orf4 involved in actinorhodin biosynthesis regulation; dnrI involved in daunorubicin biosynthesis regulation; srmR involved in spiramycin biosynthesis regulation; strR involved in streptomycin biosynthesis regulation; ccaR involved in cepamycin and clavulanic acid biosynthesis regulation; mtmR, involved in mithramycin biosynthesis regulation). See Lombo, et al., 1999.
For example, an in silico search for homologues of such known bacterial repressors and activators, or functional regions of such known repressors and activators (e.g., DNA binding motiffs) may be performed. The putative regulators may then be disrupted and moe A production (e.g., the amount of moe A) may be evaluated in the mutant. An increase in moe A production in the mutant would indicate that the putative regulator was capable of acting as a repressor of moe A production, while a decrease in moe A production would indicate that the putative regulator was capable of acting as an activator of moe A production. Additionally or alternatively, the amount (e.g., the level of expression) of individual moe gene products (either RNA or protein) may be evaluated in the regulatory mutant.
To further test the function of a putative regulatory gene, the gene could be cloned by methods described above (e.g., PCR primers could be constructed which flank the gene sequence of interest; the sequence could then be amplified, isolated, and cloned into an appropriate expression or integration vector). The gene could then be introduced into a moe-producing strain and, if cloned in a high-copy number vector or cloned in front of a strong promoter (e.g., the ermE promoter), the effects of overexpression of the putative regulatory gene could be evaluated. For example, if the putative regulator was a repressor of moe A production, overexpression would lead to a decrease, or completely abolish, moe A production. If the putative regulator was an activator, then overexpression would likely lead to an increase in moe A production, and the subsequent development of moe A overexpressing strains. (See also section V.B, below). The cloned functional copy of the gene could also be introduced into the knockout mutant to verify gene function.
V. Characterization of Moe A Intermediates
A. moeGT3 Disruption
The plasmid for moeGT3 disruption pMO12 was transferred into S. ghanaensis ATCC14672 via conjugation and its homologous integration into the genome was promoted according to the described procedure (Ostash 2007). The site-specific integration of the pMO12 in the S. ghanaensis MO12 strain was confirmed via Southern analysis using DIG-labeled moeGT3 internal fragment as a probe (FIG. 15A). In the wild type strain, the moeGT3 gene resides in a 4.3-kb BamHI fragment whereas in the MO12 strain the corresponding hybridizing band is absent and a new 11-kb band is present. The latter corresponds to integration of a 7-kb pMO12 plasmid into the 4.5-kb BamHI moeGT3-containing fragment of the S. ghanaensis chromosome. Similarly, hybridization pattern of XhoI-digests of wild type and the mutant strain confirms the insertional inactivation of moeGT3 (FIGS. 15A, 15C). Introduction of plasmid pMO14 (PermE-moeGT3) into MO12 strain restored moe A production.
The purified cell extracts of MO12 showed strong antibacterial activity, implying that none of the steps essential for moe A pharmacophore formation is affected in the mutant (FIG. 15B). LC-MS analysis revealed that MO12 accumulated known moenomycin C4. (MmC4) as a final product (FIG. 16). This conclusion was confirmed by high-resolution mass-spectral analysis (calculated mass of negative ion of MmC4: 1418.6012 Da, observed: 1418.6016 Da). Furthermore, the strain accumulated MmC4 precursor lacking chromophore unit (calculated mass for (M-H): 1322.5801 Da; observed: 1322.5796 Da). We also observed the di- and trisaccharide fragments of MmC4 (FIGS. 16A-16B), which could represent its intermediates or result from MmC4 fragmentation already in MS1 experiments (such a phenomenon has been reported for moenomycins (Zehl 2006).
B. Analysis of S. lividans TK24 Strains Various Subsets of Moe Genes
We performed detailed LC-MS analysis of the mixtures of moenomycins produced by the recombinant S. lividans strains. This analysis allowed us to detect and isolate the final moe A-related metabolite produced by each strain for high-resolution MS analysis (see Table 21). Certain pure compounds were also studied by MS/MS and NMR. Results of these experiments as well as the pattern of intermediates/degradation products found in the extract of recombinant strains guided our predictions of the structures of novel moenomycins as it is described below. In all cases the observed masses coincide with calculated ones for compounds shown on FIGS. 4A-4D.
1. S. lividans ΔmoeN5 (Prenyltransferase Gene moeN5 Deletion in moeno38-1)
This strain accumulates two new closely related compounds 22/23 (FIGS. 4A-4D) not detected in the extracts of either empty heterologous host (TK24) or other recombinant S. lividans strains. The dramatically shifted Rt of 22/23 when comparing to moe A or compound 19 is an indication of shortened lipid chain. The analysis of ΔmoeN5 extract revealed the presence of intermediates to 22/23, namely the compounds 2, 3, 5, 8, 25 (FIGS. 17A-17B). The exact masses of negative ions of all aforementioned compounds coincide with calculated ones (compound 5—calculated: 943.3694 Da, observed: 943.3688 Da; 8—calculated: 986.3752 Da, observed: 943.3750 Da; 25—calculated: 1189.4546 Da, observed: 1189.4512 Da) and point to the presence of common polyprenyl chain of 15 carbons. Presence of 1072/1073 Da peak in MS2 spectra of 22/23 (FIGS. 18A-18B) also witness that these compounds possess pentasaccharide-phosphoglyceric acid moiety found in other moenomycins (Ostash 2007, Zehl 2006). Compounds 22/23 show the biological activity (see next section). Taking these data together, we proposed the structures of 22/23 as shown below in Formula II:
R2 may be either —OH (Compound 22) or —NH2 (Compound 23).
We failed to restore the production of moenomycins having C25 isoprenoid chain (e.g. 19) in ΔmoeN5 strain using several constructs where moeN5 expression was driven from constitutive PermE* promoter. Moreover, we revealed that moeN5 overexpression even led to decrease in 22/23 production (data not shown), pointing to the existence of as-yet-unknown regulatory mechanism governing moeN5 expression under natural conditions. Therefore we constructed plasmid pOOB63a which contains both moeO5 and moeN5 genes along with 0.6 kb moeX5-moeO5 intergenic region. We assumed that the intergenic region contains promoter responsible for expression of moeO5moeN5 operon. Indeed, introduction of pOOB63a into ΔmoeN5 strain restored the production of 19. Plasmid pMoeO5extra (contains only moeO5 under PermE*) did not restore the production of 19 in ΔmoeN5 strain, meaning that only gene moeN5 is responsible for the restoration of 19 production when using plasmid pOOB63a.
B. Qualitative Analysis of Antibacterial Activity of Novel Moes
We examined the bioactivity of several purified moe A intermediates described above on a B. cereus reporter strain using a disk diffusion assay. The monosaccharide intermediates had no activity, while the moenocinol-linked penta- and tetrasaccharide compounds were roughly as active as moe A itself (FIG. 19). Disaccharide 4 could not be tested due to an extremely low production level and decomposition to 2/3. Compound 22/23, which features a C15 isoprenoid chain, showed antibacterial activity at submicromolar concentrations. Neryl-moenomycin was recently shown to be biologically inactive. Other moe derivatives having a farnesyl chain may show similar activity to compound 22/23. Therefore, in one embodiment, the present invention provides moe derivatives having the following general structure.
In one embodiment, the present invention provides a moenomycin derivative having the structure:
wherein
R and R1 independently are selected from the group consisting of hydroxyl, and —NHR2 where R2 is hydrogen, alkyl, cycloalkyl, or substituted cycloalkyl;
X is hydrogen, or
where R3 is selected from the group consisting of hydrogen and hydroxyl; and
X1 is hydrogen,
where R4 is selected from the group consisting of hydrogen and hydroxyl;
R5 is selected from the group consisting of hydroxyl, and —NHR6 where R6 is hydrogen, alkyl, cycloalkyl, or substituted cycloalkyl, and
R7 is hydrogen or methyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R and R1 independently are —NH2. In some embodiments, X is hydrogen. In other embodiments, X is
where R3 is selected from the group consisting of hydrogen and hydroxyl.
In some embodiments, X1 is hydrogen. In other embodiments, X1 is
In still other embodiments, X1 is
where R4 is selected from the group consisting of hydrogen and hydroxyl and R5 is selected from the group consisting of hydroxyl, and —NH2.
In some embodiments, the structure of the moenomycin derivative is:
where R3 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R3 is hydrogen. In other embodiments, R3 is hydroxyl.
In some embodiments, the structure of the moenomycin derivative is:
where R4 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R4 is hydrogen. In other embodiments, R4 is hydroxyl.
In some embodiments, the structure of the moenomycin derivative is:
where R4 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R4 is hydrogen. In other embodiments, R4 is hydroxyl.
In some embodiments, the structure of the moenomycin derivative is:
where R4 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R4 is hydrogen. In other embodiments, R4 is hydroxyl.
In some embodiments, the structure of the moenomycin derivative is:
where R4 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments R4 is hydrogen. In other embodiments, R4 is hydroxyl.
In some embodiments, the structure of the moenomycin derivative is:
wherein R4 is hydrogen or hydroxyl and R6 is hydrogen, alkyl, cycloalkyl, or substituted cycloalkyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R4 is hydrogen. In other embodiments, R4 is hydroxyl.
In some embodiments, R6 is hydrogen or substituted cycloalkyl. In some preferred embodiments, substituted cycloalkyl is
In some embodiments, R4 is hydroxyl and R6 is
In some embodiments, pharmaceutical composition comprising the moenomycin derivative as defined above and a pharmaceutically acceptable carrier.
In another embodiment, the present invention provides a moenomycin derivative having the structure:
wherein
R7 and R8 independently are selected from the group consisting of hydroxyl, and —NHR9 where R9 is hydrogen, alkyl, cycloalkyl, or substituted cycloalkyl; and
R10 is hydrogen or hydroxyl;
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, R7 and R8 independently are —NH2. In some embodiments, R10 is hydroxyl.
In some embodiments, the structure of the moenomycin derivative is:
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
In some embodiments, pharmaceutical composition comprising the moenomycin derivative as defined above and a pharmaceutically acceptable carrier.
The moenomycin derivatives disclosed herein can be synthesized by genetic synthesis or by a conventional synthetic chemical synthesis by a person skilled in the art. The synthetic chemical synthesis can use known starting materials such as phosphoglycerate-farnesyl.
Perhaps the most surprising outcome of these studies, however, is that product 11 has biological activity (Welzel 2005) (FIG. 19). Compound 11 is shown below as Formula III:
Compound 11 does not contain the C ring, proposed to be part of the moe A pharmacophore, but instead contains a branching glucose unit. Evidently, either the C or the D ring can confer biological activity on the EF disaccharide, although the molecular basis for their effects is unclear. A crystal structure of moe A bound to a peptidoglycan glycosyltransferase domain has been reported and shows that the C ring binds in the active site cleft while the D ring protrudes from the cleft (Lowering 2007). The resolution of the complex is not sufficient to determine if there are specific contacts from conserved amino acids to the C ring, but it is almost certain that there are none to the D ring.
IV. Moe Assembly Scheme
The bioinformatic and genetic analysis of the identified moe genes suggests a scheme of moe A biosynthesis, depicted in FIGS. 4A-4D. Not wishing to be bound or limited by any theory, structures 23 and 3 witness that moe A biosynthesis starts with a unique reaction of farnesylation of phosphoglyceric acid. Sugars are transferred to the putative molecule 1P one by one. The carboxamide on unit F is required to proceed through the pathway; methylation, in contrast, can occur prior to the second glycosylation, but is not required to make the moe A pentasaccharide. Carbamoylation of the first sugar (unit F, FIG. 1) appears to happen only after attachment of three sugars since we could not detect any mass-peaks corresponding to carbamoylated disaccharide precursors (FIGS. 4A-4D). Prenylation to form the “mature” C25 isoprenoid chain also appears to occur only after the attachment of three sugars. The sequence of carbamoyltransferase and prenyltransferase reactions shown in FIGS. 4A-4D is proposed, however, the reverse order cannot be excluded. However, it is evident from the production of des-carbamoylated MmA pentasaccharides in a ΔmoeM5 strain and C15 MmA pentasaccharides in a ΔmoeN5 strain that carbamoylation is not required prenylation and prenylation is not required for carbamoylation. The attachment of the two remaining sugars and the chromophore completes moe A biosynthesis. Thus, the overall pathway has been delineated, although there remain questions about particular transformations, including the unusual MoeN5-catalyzed prenyl transfer reaction to generate the irregular C25 isoprenoid chain of MmA and the biochemistry of A ring biogenesis.
In one aspect of the present invention, the biosynthetic pathway for moe A may be altered for the production of phosphoglycolipid analogs. The biosynthetic pathway involves approximately ten essential (for biological activity) structural genes. The present inventors have discovered that a complex mixture of related compounds arises because the moenomycin biosynthetic machinery is flexible. Except for unit F carboxyamidation, all examined sugar tailoring reactions can be “switched off” without adverse effects on the assembly of the prenyl-phosphoglycerate-glycoside scaffold. Prenyl transfer to form the C25 lipid from the C15 precursor can also be switched off. Moreover, both MoeGT4 and MoeGT5 can accept either UDP-GlcNAc or UDP-chinovosamine as donor substrates, as evident from production of pholipomycin and moenomycin C3. This, in combination with unbalanced expression of certain moe genes, leads to an interesting phenomenon where relatively simple pathway yields not one compound but a mixture of related ones. Thus, the spectrum of moenomycin metabolites and deriviates may be altered by selective deletion/overexpression of certain genes.
In some embodiments, the present invention provides for genetic manipulations of the moe A pathway for the discovery and production of clinically valuable molecules. Consistent with this expectation, we have already yielded several unexpected bioactive compounds. For example, we have found that the farnesylated moe A analog 23 has biological activity at submicromolar concentrations in a disk diffusion assay. This or other C15 derivatives may have better pharmacokinetic properties than the parent compounds, which would compensate for the evident decrease in potency. We have also shown that trisaccharide 11 is biologically active, providing an alternative scaffold for combinatorial or chemoenzymatic explorations to generate analogs.
VI. Further Examples of the Present Invention
A. Inactivation of Either Individual Moe Genes or Sets of Moe Genes to Generate Moe Derivatives, Analogs, Fragments and Novel Compounds
The above description of the insertional inactivation is one possible model for how disruptions of separate moe genes leads to the generation of bacterial strain with altered profile of moes production. The generated recombinant strains may be the source of novel moes which possess better antibacterial and pharmacological properties. These novel moes may further be chemically or chemoenzymaticaly modified to produce novel compounds. For example, the 406 bp internal fragment of gene moeC4 (corresponding to amino acids 146-281 of moeC4) for 5-aminolevulinate synthase may be amplified with primers alsupHindIII and alsrp1EcoRI and cloned into pKC1139. Following the procedure utilized for moeM5 gene disruption, a S. ghanaensis strain with a deficient aminolevulinate synthase gene may be generated. The strain would then accumulate a late moe intermediate lacking the chromophore unit. This simplified moe derivative would likely have slightly reduced antibacterial activity. Additionally, its acid or amide functionality at unit B could be further modified using standard chemical techniques or chemoenzymatic approaches (which will be described in following examples) to give a compound with improved properties.
For example, a more chemically reactive unit can be attached to the aforementioned simplified moe instead of the natural C5N chromophore. By strengthening the interactions between the chromophore-saccharide portion of moe and its target (transglycosylase involved in bacterial peptidoglycan biosynthesis) it might be possible to then remove/shorten the lipid chain from moe without the loss of its biological activity.
A combination of certain mutations in individual moe genes also presents options for the production of moe analogs. For example, combining the mutations in the methyltransferase gene moeK5, the sugar tailoring gene moeR5 and the moeC4 gene, a novel moe could be produced lacking unitA (chromophore), methyl group in ring F, and bearing a hydroxyl in the C6 position of unit C. S. ghanaensis produces mixture of moes, and some of them are products of branches of the main moe pathway. Thus, the disruptions of certain moe genes can be used to block the shunt moe pathways.
B. Overexpression of Moe Genes in Streptomyces ghanaensis to Generate Moe Overproducing Strains
The amplification of gene clusters for antibiotic biosynthesis in genomes of producing strains is known to lead to overproduction of the antibiotics. The availability of moe genes paves a similar path for the rational generation of moe overproducing strains. For example, protoplasts of wild-type S. ghanaensis strain (obtained according to the described procedure) may be transformed with alkali denaturated cosmid moeno38 (as described in Oh 1997) carrying most of the moe genes. The protoplasts may be regenerated on R2YE medium and selected for kanamycin resistance in order to isolate S. ghanaensis clones in which cosmid moeno38 has integrated into the host chromosome by homologous recombination. The production of moes may then be studied as described above to verify the overproducing phenotype. In this way the duplication of moe genes can be achieved.
In order to obtain S. ghanaensis strains with multiple copies of moe gene cluster per genome, cosmid moeno38-1 from cosmid moeno38, in which the neo gene marker has been replaced with 5.3 kb hyg-oriTRK2-intφC31 PCR fragment of vector POOB40 by suing the λ-Red recombination system (Gust 2003). The construct could be transferred into S. ghanaensis and recombinant colonies could be selected for hygromycin resistance. The production of moes could then be studied as described above. Sometimes the expression of only certain genes may be a limiting factor in biosynthesis of a given secondary metabolite. Therefore, the expression of individual moe genes could be useful to increase the production of moes or moe-related compound.
C. Heterologous Expression of Moe Genes
The heterologous expression of moe genes may be used to for a number of reasons such as 1) to generate recombinant strains which produce more moes than, for example, S. ghanaensis, 2) to produce moe derivatives, 3) to generate novel compounds resulting from the modification of metabolites other than moes with Moe proteins. The moe genes of the present invention may be expressed in a variety of cell expression systems known in the art. By way of example, but not by way of limitation, bacterial (e.g., Streptomyces sp., E. coli), mammalian (e.g., mouse, human, rat, hamster, etc., such as NIH-3T3, HeLa, HEK 293, etc.), yeast (e.g., Saccharomyces cerevisiae, Pichia pastoris) and insect cells (e.g., Drosophila melanogaster Schneider cells) may be used. Numerous expression systems, including appropriate expression vectors, cell growth media and conditions, and cell lines, are known in the art and many are commercially available.
As one example, the moeno38-1 construction (which was transferred to S. lividans TK24, described above) may be transferred to other organisms, e.g. S. coelicolor M145, by applying the conjugation protocol, also described above. The transconjugants may be selected for hygromycin. The production of moes may be checked by biochromatography and LC-MS analysis. The recombinant strains may be better producers of moes than the wild type S. ghanaensis strain. Further, by using qp-Red recombination system, for example, modified moeno38 cosmids with deletions of one or more moe genes may be obtained. Their expression in a heterologous host (as described above) would lead to production of moes analogs.
The expression of sugar tailoring moe genes in the producers of other glycoside antibiotics may lead to production of novel hybrid compounds. For example, a given sugar tailoring gene may be cloned into a Streptomyces expression vector (such as pMKI9 or analogs). The resulting construct may then be transferred into a strain of interest via intergeneric conjugation, protoplast transformation or electroporation (Kieser 2000). The recombinant strain could then be subject to detailed analysis in order to detect the changes in antibiotic production.
D. Overexpression of Moe Proteins in E. coli or Streptomyces and their Use as Catalysts for Generation of Novel Molecules
Purified enzymes encoded by moe genes can be used to produce novel molecules. This approach is based on certain degree of substrate promiscuity of the enzymes involved in antibiotic production. For example, the gene for moenocinol 3-phosphoglycerate synthase may be amplified from cosmid moeno38 with primers moeO5HindIIIrp (AAAAAGCTTCCGCCCGCTCCCCGGAC; SEQ ID NO. 105) and moeO5NdeIup (AAACATATGCTCGCCCGGCTGCGC; SEQ ID NO. 106), resulting in an approximately 774 bp fragment. The amplification product may then be digested with HindIII and NdeI restriction endonucleases and cloned into respective sites of E. coli protein expression vector, such as pET24b (or any analogous vector that allows for affinity column protein purification). The resulting plasmid may then be introduced in an E. coli strain such as BL21(DE3) (or its derivatives that utilize similar strategy for induction of protein expression) using standard methods.
Alternatively, the moeO5 gene may be amplified along with its native ribosome binding site and a hexahistidine tag; desired restrictions sites may be engineered at the ends of the gene via PCR. This recombinant moeO5 gene can then be cloned into corresponding restrictions sites of a vector such as pMK19. The resulting plasmid can be introduced into S. ghanaensis using the above-described procedures. His-tagged moeO5 protein may then be purified from S. ghanaensis using standard IMAC chromatography.
The optimal conditions for moeO5 protein expression and purification from E. coli or Streptomyces can be developed experimentally; such methods and optimizations are well known to those skilled in the art. The pure moeO5 protein may then be used in vitro to, for example, reconstitute the reaction of prenyl transfer onto 3-phosphoglycerate. The ability of moeO5 to transfer unnatural prenyl chains onto 3-phosphoglycerate may also be exploited. The products of the reaction may be monitored by HPLC-MS. Since one of the disadvantage of moe A as a clinically valuable antibiotic is its poor pharmacokinetics, due in part to the long prenyl chain, the ability to produce the moes with altered prenyl chain length/stereochemistry would be a valuable step towards improved moes.
The above-described example provides an exemplary experimental framework for development of such technology for the production of improved moes. Additionally, if the moeO5 protein appears unable to transfer prenyl chains of shorter length/different stereochemistry, then it can be subjected to directed mutagenesis to relax/change its substrate specificity (see following example). The same approach as described above for moeO5 protein may be applied to the expression of any of moe proteins; that is, their ability to catalyze novel chemical reactions can be studied using a variety of different substrates and mutagenesis may be employed to change substrate specificity.
E. Site Specific Mutagenesis of Moe Genes in Order to Generate the Mutated Moe Proteins with Novel Enzymatic Activities.
Although the enzymes involved in antibiotic production are usually able to accept unnatural substrates resembling the natural one, their inherent level of substrate promiscuity might not be sufficient to produce a different compound. Accordingly, changes to specific amino acids which are identified as important for substrate recognition/reaction catalysis can be mutated within the given protein to generate highly efficient catalyst of novel reaction. Extracts from cells expressing the mutant moe biosynthesis-related gene (i.e. a “test strain”), may be assessed for anti-microbial activity using for example, a zone inhibition assay, such as depicted in FIG. 19. Comparison may be made between extracts from the test strain and extracts from a control strain (e.g. a strain expressing the natural moe biosynthesis-related genes). Test strains that have a larger zone of inhibition compared to the control strain may possess novel moes or moe derivatives. Test strains that have a smaller zone of inhibition compared to the control strain may lack novel moes or moe deriviatives. This approach depends on detailed structural information about the protein or, at least, its functional homologues. For example, the crystal structure of moeO5 homologue, GGGPS from Archaeoglobus fulgidus exists, as does information about kinetics of the reactions catalyzed by this class of enzymes. Using protein fold prediction programs, the structure of moeO5 may be modeled using A. fulgidus GGGPS as a template. In this way, amino acids critical for substrate recognition and binding may be identified within moeO5 and mutated to alter enzyme activity, for example, to help a catalytic pocket accommodate an altered or unnatural substrate. Alternatively, the entire polypeptide or portions of the polypeptide may be mutated at random sites to create mutant libraries (Lehtovaara et al., Protein Eng. 2: 63-8 (1988)). The mutants created in this way may also be tested, using, for example, the zone of inhibition assay described above.
F. Use of DNA Fragments of Moe Genes as a Hybridization Probes for Discovery of Genes Governing the Biosynthesis of Related Phosphoglycolipid Antibiotics
The moe genes of the present invention may be used to identify genes involved in the biosynthesis of other antibiotics in bacteria or other organisms. For example, the entire moeO5 gene (described above) may be labeled using non-radioactive digoxigenin or a radioactive approach (according to standard procedures) (Sambrook 1989). Genomic DNA of producers of other phosphoglycolipid antibiotics (e.g., AC326alpha, teichomycin, prasinomycin etc) may be isolated, digested with certain restriction endonucleases and separated on an agarose gel according to standard procedures. Southern analysis may then be used to identify any moeO5S homologues (i.e., the presence of positive hybridization signals using the labeled moeO5 gene with the genomic digests would demonstrate the presence of genes similar to moeO5). Therefore, the moe genes, such as moeO5, can be used to probe the genomic library of a given strain to identify, clone and characterize homologues and surrounding genes. Any other moe gene can be used in the same way as a probe for discovery of related genes in other producers.
G. Use of an Internal Fragment of Moe Genes and Homologous Recombination for Discovery of Genes Governing the Biosynthesis of Related Phosphoglycolipid Antibiotics
The carbamoyltransferase moeM5 disruption plasmid pOOB20a (described above) may be transferred into Actinoplanes teichomiceticus, the producer of teichomycins, via standard intergeneric conjugation protocol. The integration of pOOB20a into the A. teichomyceticus genome may be promoted as described for the moeM5 disruption in S. ghanaensis ATCC14672 strain. If there is a gene in the A. teichomyceticus genome which shows even moderate homology to moeM5 (50-70% at nucleotide level), then homologous recombination could occur between the moeM5 fragment on plasmid pOOB20a and the similar gene present in the host's genome. The integration of pOOB20a into A. teichomyceticus genome could be verified through Southern analysis, and the production of teichomycins may be monitored using bioassays and HPLC-MS analysis. Homologues of moeM5 and surrounding sequences could be rescued from pOOB20a+ A. teichomyceticus integrant by digesting total DNA with restriction endonucleases which do not cut the pOOB20a plasmid (HindIII, XbaI, EcoRV). In this way pOOB20a can be excised from the A. teichomyceticus genome along with some genomic flanking sequence (the amount of flanking sequence obtained would depend on how far the restriction sites were from the pOOB20a insertion). These digests may be set-up to be self-ligating and then used to transform competent cells such as E. coli. The apramycin-resistant clones resulting from this transformation can then be used for the isolation of plasmid DNA and further restriction mapping. The fragments of A. teichomyceticus genome can also be subcloned into suitable vectors (e.g., pUC19, pBluescript etc.) for sequencing. The described procedure would be useful to identify homologues or genes that have sequence similarity to any of the moe biosynthesis-related genes of the invention.
H. Design of Degenerate Primers on the Basis of Moe Genes for Discovery of Novel Genes
One method to identify novel genes (having homology to the moe genes described above) may include designing degenerate primers capable of amplifying sequences similar to those of the identified moe genes. For example, to design such primers, the sequence of a moe gene, such as the moeO5 gene, may be aligned with sequences of known prenyl-glycerol synthases from other bacterial species, such as Archaea. The conserved amino acid residues may be identified and their significance assessed through comparison with the crystal structure of prenyl-glycerol synthases from other bacteria, such as A. fulgidus. Two stretches of amino acids within a conserved C-terminus of the compared proteins (e.g., 88-ADALLL-93 (SEQ ID NO: 252) and 190-GADYVG-195 (SEQ ID NO: 253)) can be back-translated into DNA sequence taking into account the codon usage of Streptomyces (if other organisms are targeted in this kind of experiment, then the choice of codons is planned according to codon usage table of that organism) and allowing for ambiguity in a third codon position. The program CODEHOP (Rose et al., Nucl Acids Res, 1998 26:1628-1635) can be used to design degenerate primers.
PCR conditions using such degenerate primers may be developed in the course of additional experimentation using positive controls (e.g., the template DNA of the moe producer). Such PCR optimizations are well known in the art. The PCR products from unknown strains may then be cloned using, for example, PCR LIC cloning vectors (Novagen, San Diego, Calif.) according to the manufacturer's instructions. The insert can be sequenced compared with and moeO5 and other known homologues.
Examples F, G and H all describe methods in which novel moe gene homologues can be identified and isolated. Because the methods are based on sequence similarity, they allow for the discovery of genes which may have different biochemical or functional characteristics than the moe genes used to find them. Such characteristics may include but are not limited to different substrate specificity (e.g., more or less specific for a particular substrate; specificity for a different, but similar substrate); a different reaction rate (e.g., much faster or much slower, thereby allowing other reactions or modifications to occur or not); the ability to function under different reaction conditions (e.g., modified salt, temperature or pH); improved or increased stability. Any of the discovered homologues with different characteristics could prove useful in an in vitro or in vivo moe A synthesis and/or modification system, in conjunction with, or in place of, one of the identified moe genes. Additionally, identification of such moe homologues may lead to the identification of different moe-like or other antibiotic biosynthetic pathway.
I. Generating and Testing Novel Moes
The present invention provides for the generating of novel moe or moe derivatives which are capable of inhibiting the activity of bacterial transglycoslase enzymes. The novel moes may be generated according to the methods described herein, including the expression of moe biosynthesis-related genes, or fragments or variants thereof, in S. ghanaensis or a heterologous host, e.g. S. lividans. Extracts from cells expressing the moe biosynthesis-related genes, fragments, or variants thereof (i.e. a “test strain”), may be assessed for anti-microbial activity using for example, a zone inhibition assay, such as depicted in FIG. 19. Comparison may be made between extracts from the test strain and extracts from a control strain (e.g. a strain expressing the natural moe biosynthesis-related genes). Test strains that have a larger zone of inhibition compared to the control strain may possess novel biologically-active moes or moe derivatives. Test strains that have a smaller zone of inhibition compared to the control strain may lack novel moes or moe deriviatives.
Novel moes or moe derivatives might also be identified using LC-MS analysis of extracts from cells expressing the moe biosynthesis-related genes, fragments, or derivatives thereof. Comparison may be made between the LC-MS spectra of the test strain and a control strain. The appearance of new peaks may indicate the presence of novel moes or moe derivatives in that test strain. Those compounds may be purified using methods known to those of skill in the art (e.g. chromatography). The anti-microbial activity of those compounds can then be assayed using, for example, a zone of inhibition assay.
J. Improved Moe A Characteristics
In some embodiments, the modified and improved moe A formulations of the present invention (“improved moe A”) are contemplated to exhibit increased bioavailability as compared to the currently available, or conventional moe A formulations such as Flavomycin®. The increased bioavailability is also likely to result in a dosage form that exhibits greater drug absorption than conventional formulations of moe A; as such, a pharmaceutically acceptable formulation for use in humans is contemplated.
Increased bioavailability can be ascertained by methods known in the art. For example, the drug absorption, distribution, and/or elimination rates may be evaluated and compared to conventional moe A, as may the different pharmacokinetic profiles. Exemplary, desirable pharmacokinetic profiles preferably include, but are not limited to: (1) a Cmax for an improved moe, such as an improved moe A, or a derivative or salt thereof, when assayed in the plasma of a mammalian subject following administration, that is preferably greater than the Cmax for the conventional moe A administered at the same dosage; and/or (2) an AUC for an improved moe, such as an improved moe A, or a derivative or a salt thereof, when assayed in the plasma of a mammalian subject following administration, that is preferably greater than the AUC for conventional moe A, administered at the same dosage; and/or (3) a Tmax for an improved moe, such as moe A, or a derivative or a salt thereof, when assayed in the plasma of a mammalian subject following administration, that is preferably less than the Tmax for a conventional formulation moe A, administered at the same dosage. The desirable pharmacokinetic profile, as used herein, is the pharmacokinetic profile measured after the initial dose of the moe A or derivative or a salt thereof.
For example, in one embodiment, a composition comprising at least one improved formulation of moe A exhibits in comparative pharmacokinetic testing with a non-improved formulation of the same moe A (e.g. Flavomycin), administered at the same dosage, a Tmax not greater than about 90%, not greater than about 80%, not greater than about 70%, not greater than about 60%, not greater than about 50%, not greater than about 30%, not greater than about 25%, not greater than about 20%, not greater than about 15%, not greater than about 10%, or not greater than about 5% of the Tmax exhibited by the conventional moe A formulation.
In another embodiment, the composition comprising at least one improved moe A formulation or derivative or salt thereof, exhibits in comparative pharmacokinetic testing with a conventional moe A formulation (e.g., Flavomycin), administered at the same dosage, a Cmax which is at least about 50%, at least about 100%0, at least about 200%, at least about 300%, at least about 400%, at least about 500%, at least about 600%, at least about 700%, at least about 800%, at least about 900%, at least about 1000%, at least about 1100%, at least about 1200%, at least about 1300%, at least about 14000%, at least about 1500%, at least about 1600%, at least about 1700%, at least about 1800%, or at least about 1900% greater than the Cmax exhibited by the conventional moe A formulation.
In yet another embodiment, the composition comprising at least one improved moe A or a derivative or salt thereof, exhibits in comparative pharmacokinetic testing with a conventional formulation of moe A (e.g., Flavomycin), administered at the same dosage, an AUC which is at least about 25%, at least about 50%, at least about 75%, at least about 100%, at least about 125%, at least about 150%, at least about 175%, at least about 200%, at least about 225%, at least about 250%, at least about 275%, at least about 300%, at least about 350%, at least about 400%, at least about 450%, at least about 500%, at least about 550%, at least about 600%, at least about 750%, at least about 700%, at least about 750%, at least about 800%, at least about 850%, at least about 900%, at least about 950%, at least about 1000%, at least about 1050%, at least about 1100%, at least about 1150%, or at least about 1200% greater than the AUC exhibited by the conventional moe A formulation.
The moe A formulations contemplated also include a variety of pharmaceutical acceptable dosage forms. By way of example, but not by way of limitation, pharmaceutically acceptable formulations may include: formulation for oral, pulmonary, intravenous, rectal, ophthalmic, colonic, parenteral, intracisternal, intravaginal, intraperitoneal, local, buccal, nasal, and topical administration; dosage forms such as liquid dispersions, gels, aerosols, ointments, creams, tablets, sachets and capsules; dosage forms such as lyophilized formulations, fast melt formulations, controlled release formulations, delayed release formulations, extended release formulations, pulsatile release formulations, and mixed immediate release and controlled release formulations, or any combination of the above. In some embodiments, preferred formulations for administration may include oral tablets or capsules. In other embodiments, parenteral formulations may be preferred.
K. Prophylactic and Therapeutic Use of Moe A Derivatives
General.
The moe A derivatives and intermediates of the present invention can be used in treatment of bacterial infections. Specifically, the invention provides for both prophylactic and therapeutic methods of treating a subject at risk of (or susceptible to) a disorder or having a disorder associated with an bacterial infections. While not wishing to be limited by theory, administration of moe A results in inhibition of bacterial transglycosylase enzymes and killing or slowing the growth of the bacteria.
In one aspect, the invention provides a method for preventing, in a subject, a disease or condition associated with a bacterial infection, by administering to the subject a moe A derivative. Administration of a prophylactic moe A derivative can occur prior to the manifestation of symptoms characteristic of the infection, such that a disease or condition is prevented or, alternatively, delayed in its progression. In therapeutic applications, moe A derivatives are administered to a subject suspected of, or already suffering from, a bacterial infection. An amount adequate to accomplish therapeutic or prophylactic treatment is defined as a therapeutically- or prophylactically-effective dose.
Determination of the Biological Effect of a Moe A Derivative Therapeutic.
In various embodiments of the invention, suitable in vitro or in vivo assays are performed to determine the effect of moe A derivatives and whether the administration is indicated for treatment of the affected tissue in a subject.
Typically, an effective amount of the compositions of the present invention, sufficient for achieving a therapeutic or prophylactic effect, range from about 0.000001 mg per kilogram body weight per day to about 10,000 mg per kilogram body weight per day. Preferably, the dosage ranges are from about 0.0001 mg per kilogram body weight per day to about 100 mg per kilogram body weight per day. For example dosages can be 1 mg/kg body weight or 10 mg/kg body weight every week, every two weeks or every three weeks or within the range of 1-10 mg/kg every week, every two weeks or every three weeks. In one embodiment, a single dosage of antibody range from 0.1-10,000 micrograms per kg body weight. In one embodiment, antibody concentrations in a carrier range from 0.2 to 2000 micrograms per delivered milliliter. An exemplary treatment regime entails administration once per every two weeks or once a month or once every 3 to 6 months. Alternatively, moe A derivatives can be administered as a sustained release formulation, in which case less frequent administration is required. Dosage and frequency vary depending on the half-life of the moe A derivative in the subject. The dosage and frequency of administration can vary depending on whether the treatment is prophylactic or therapeutic. In prophylactic applications, a relatively low dosage is administered at relatively infrequent intervals over a long period of time. Some subjects continue to receive treatment for the rest of their lives. In therapeutic applications, a relatively high dosage at relatively short intervals is sometimes required until progression of the disease is reduced or terminated, and preferably until the subject shows partial or complete amelioration of symptoms of disease. Thereafter, the patent can be administered a prophylactic regime.
Toxicity.
Preferably, an effective amount (e.g., dose) of a moe A derivative described herein will provide therapeutic benefit without causing substantial toxicity to the subject. Toxicity of the moe A derivative described herein can be determined by standard pharmaceutical procedures in cell cultures or experimental animals, e.g., by determining the LD50 (the dose lethal to 50% of the population) or the LD100 (the dose lethal to 100% of the population). The dose ratio between toxic and therapeutic effect is the therapeutic index. The data obtained from these cell culture assays and animal studies can be used in formulating a dosage range that is not toxic for use in human. The dosage can vary within this range depending upon the dosage form employed and the route of administration utilized. The exact formulation, route of administration and dosage can be chosen by the individual physician in view of the subject's condition. See, e.g., Fingl et al., In: The Pharmacological Basis of Therapeutics, Ch. 1 (1975).
Formulations of Pharmaceutical Compositions.
According to the methods of the present invention, the moe A derivative can be incorporated into pharmaceutical compositions suitable for administration. Pharmaceutically-acceptable carriers are determined in part by the particular composition being administered, as well as by the particular method used to administer the composition. Accordingly, there is a wide variety of suitable formulations of pharmaceutical compositions for administering the antibody compositions (see, e.g., Remington's Pharmaceutical Sciences, Mack Publishing Co., Easton, Pa. 18th ed., 1990). The pharmaceutical compositions are generally formulated as sterile, substantially isotonic and in full compliance with all Good Manufacturing Practice (GMP) regulations of the U.S. Food and Drug Administration.
The terms “pharmaceutically-acceptable,” “physiologically-tolerable,” and grammatical variations thereof, as they refer to compositions, carriers, diluents and reagents, are used interchangeably and represent that the materials are capable of administration to or upon a subject without the production of undesirable physiological effects to a degree that would prohibit administration of the composition. For example, “pharmaceutically-acceptable excipient” means an excipient that is useful in preparing a pharmaceutical composition that is generally safe, non-toxic, and desirable, and includes excipients that are acceptable for veterinary use as well as for human pharmaceutical use. Such excipients can be solid, liquid, semisolid, or, in the case of an aerosol composition, gaseous. “Pharmaceutically-acceptable salts and esters” means salts and esters that are pharmaceutically-acceptable and have the desired pharmacological properties. Such salts include salts that can be formed where acidic protons present in the moe A derivative are capable of reacting with inorganic or organic bases. Suitable inorganic salts include those formed with the alkali metals, e.g., sodium and potassium, magnesium, calcium, and aluminum. Suitable organic salts include those formed with organic bases such as the amine bases, e.g., ethanolamine, diethanolamine, triethanolamine, tromethamine, N-methylglucamine, and the like. Such salts also include acid addition salts formed with inorganic acids (e.g., hydrochloric and hydrobromic acids) and organic acids (e.g., acetic acid, citric acid, maleic acid, and the alkane- and arene-sulfonic acids such as methanesulfonic acid and benzenesulfonic acid). Pharmaceutically-acceptable esters include esters formed from carboxy, sulfonyloxy, and phosphonoxy groups present in the moe A derivative, e.g., C1-6 alkyl esters. When there are two acidic groups present, a pharmaceutically-acceptable salt or ester can be a mono-acid-mono-salt or ester or a di-salt or ester, and similarly where there are more than two acidic groups present, some or all of such groups can be salified or esterified. The moe A derivative named in this invention can be present in unsalified or unesterified form, or in salified and/or esterified form, and the naming of such moe A derivative is intended to include both the original (unsalified and unesterified) compound and its pharmaceutically-acceptable salts and esters. Also, certain moe A derivatives named in this invention can be present in more than one stereoisomeric form, and the naming of such moe A derivatives is intended to include all single stereoisomers and all mixtures (whether racemic or otherwise) of such stereoisomers. A person of ordinary skill in the art, would have no difficulty determining the appropriate timing, sequence and dosages of administration for particular drugs and compositions of the present invention.
Preferred examples of such carriers or diluents include, but are not limited to, water, saline, Ringer's solutions, dextrose solution, and 5% human serum albumin. Liposomes and non-aqueous vehicles such as fixed oils may also be used. The use of such media and compounds for pharmaceutically active substances is well known in the art. Except insofar as any conventional media or compound is incompatible with the moe A derivative, use thereof in the compositions is contemplated. Supplementary active compounds can also be incorporated into the compositions.
A pharmaceutical composition of the invention is formulated to be compatible with its intended route of administration. The moe A derivative compositions of the present invention can be administered by parenteral, topical, intravenous, oral, subcutaneous, intraarterial, intradermal, transdermal, rectal, intracranial, intraperitoneal, intranasal; intramuscular route or as inhalants. The moe A derivative can optionally be administered in combination with other agents that are at least partly effective in treating conditions associated with bacterial infection.
Solutions or suspensions used for parenteral, intradermal, or subcutaneous application can include the following components: a sterile diluent such as water for injection, saline solution, fixed oils, polyethylene glycols, glycerine, propylene glycol or other synthetic solvents; antibacterial compounds such as benzyl alcohol or methyl parabens; antioxidants such as ascorbic acid or sodium bisulfite; chelating compounds such as ethylenediaminetetraacetic acid (EDTA); buffers such as acetates, citrates or phosphates, and compounds for the adjustment of tonicity such as sodium chloride or dextrose. The pH can be adjusted with acids or bases, such as hydrochloric acid or sodium hydroxide. The parenteral preparation can be enclosed in ampoules, disposable syringes or multiple dose vials made of glass or plastic.
Pharmaceutical compositions suitable for injectable use include sterile aqueous solutions (where water soluble) or dispersions and sterile powders for the extemporaneous preparation of sterile injectable solutions or dispersion. For intravenous administration, suitable carriers include physiological saline, bacteriostatic water, Cremophor ELTM (BASF, Parsippany, N.J.) or phosphate buffered saline (PBS). In all cases, the composition must be sterile and should be fluid to the extent that easy syringeability exists. It must be stable under the conditions of manufacture and storage and must be preserved against the contaminating action of microorganisms such as bacteria and fungi. The carrier can be a solvent or dispersion medium containing, e.g., water, ethanol, polyol (e.g., glycerol, propylene glycol, and liquid polyethylene glycol, and the like), and suitable mixtures thereof. The proper fluidity can be maintained, e.g., by the use of a coating such as lecithin, by the maintenance of the required particle size in the case of dispersion and by the use of surfactants. Prevention of the action of microorganisms can be achieved by various antibacterial and antifungal compounds, e.g., parabens, chlorobutanol, phenol, ascorbic acid, thimerosal, and the like. In many cases, it will be preferable to include isotonic compounds, e.g., sugars, polyalcohols such as manitol, sorbitol, sodium chloride in the composition. Prolonged absorption of the injectable compositions can be brought about by including in the composition a compound which delays absorption, e.g., aluminum monostearate and gelatin.
Sterile injectable solutions can be prepared by incorporating the moe A derivative in the required amount in an appropriate solvent with one or a combination of ingredients enumerated above, as required, followed by filtered sterilization. Generally, dispersions are prepared by incorporating the binding agent into a sterile vehicle that contains a basic dispersion medium and the required other ingredients from those enumerated above. In the case of sterile powders for the preparation of sterile injectable solutions, methods of preparation are vacuum drying and freeze-drying that yields a powder of the active ingredient plus any additional desired ingredient from a previously sterile-filtered solution thereof. The agents of this invention can be administered in the form of a depot injection or implant preparation which can be formulated in such a manner as to permit a sustained or pulsatile release of the active ingredient.
Oral compositions generally include an inert diluent or an edible carrier. They can be enclosed in gelatin capsules or compressed into tablets. For the purpose of oral therapeutic administration, the binding agent can be incorporated with excipients and used in the form of tablets, troches, or capsules. Oral compositions can also be prepared using a fluid carrier for use as a mouthwash, wherein the compound in the fluid carrier is applied orally and swished and expectorated or swallowed. Pharmaceutically compatible binding compounds, and/or adjuvant materials can be included as part of the composition. The tablets, pills, capsules, troches and the like can contain any of the following ingredients, or compounds of a similar nature: a binder such as microcrystalline cellulose, gum tragacanth or gelatin; an excipient such as starch or lactose, a disintegrating compound such as alginic acid, Primogel, or corn starch; a lubricant such as magnesium stearate or Sterotes; a glidant such as colloidal silicon dioxide; a sweetening compound such as sucrose or saccharin; or a flavoring compound such as peppermint, methyl salicylate, or orange flavoring.
For administration by inhalation, the moe A derivative are delivered in the form of an aerosol spray from pressured container or dispenser which contains a suitable propellant, e.g., a gas such as carbon dioxide, or a nebulizer.
Systemic administration can also be by transmucosal or transdermal means. For transmucosal or transdermal administration, penetrants appropriate to the barrier to be permeated are used in the formulation. Such penetrants are generally known in the art, and include, e.g., for transmucosal administration, detergents, bile salts, and fusidic acid derivatives. Transmucosal administration can be accomplished through the use of nasal sprays or suppositories. For transdermal administration, the moe A derivative is formulated into ointments, salves, gels, or creams as generally known in the art.
The moe A derivative can also be prepared as pharmaceutical compositions in the form of suppositories (e.g., with conventional suppository bases such as cocoa butter and other glycerides) or retention enemas for rectal delivery.
In one embodiment, the moe A is prepared with carriers that will protect the moe A derivative against rapid elimination from the body, such as a controlled release formulation, including implants and microencapsulated delivery systems. Biodegradable, biocompatible polymers can be used, such as ethylene vinyl acetate, polyanhydrides, polyglycolic acid, collagen, polyorthoesters, and polylactic acid. Methods for preparation of such formulations will be apparent to those skilled in the art. The materials can also be obtained commercially from Alza Corporation and Nova Pharmaceuticals, Inc. Liposomal suspensions (including liposomes targeted to infected cells with monoclonal antibodies to viral antigens) can also be used as pharmaceutically-acceptable carriers. These can be prepared according to methods known to those skilled in the art, e.g., as described in U.S. Pat. No. 4,522,811.
It is especially advantageous to formulate oral or parenteral compositions in dosage unit form for ease of administration and uniformity of dosage. Dosage unit form as used herein refers to physically discrete units suited as unitary dosages for the subject to be treated; each unit containing a predetermined quantity of binding agent calculated to produce the desired therapeutic effect in association with the required pharmaceutical carrier. The specification for the dosage unit forms of the invention are dictated by and directly dependent on the unique characteristics of the compound and the particular therapeutic effect to be achieved, and the limitations inherent in the art of compounding such moe A derivatives for the treatment of a subject.
REFERENCES
- Adachi, M., Zhang, Y., Leimkuhler, C., Sun, B., LaTour, J. V., and Kahne, D. E. (2006), Degradation and reconstruction of moenomycin A and derivatives: dissecting the function of the isoprenoid chain. J Am Chem Soc. 128, 14012-14013.
- Arai M, Torikata A, Enokita R, Fukatsu H, Nakayama R and Yoshida K. Pholipomycin, a new member of phosphoglycolipid antibiotics. I. Taxonomy of producing organism and fermentation and isolation of pholipomycin. J Antibiot. 1977. V. 30(12): 1049-1054.
- Baizman E R, Branstrom A A, Longley C B, Allanson N, Sofia M J, Gange D, Goldman R C: Antibacterial activity of synthetic analogues based on disaccharide structure of moe, an inhibitor of bacterial transglycosylase. Microbiology 2000, 146: 3129-3140.
- Bardone M R, Paternoster M and Coronelli C. Teichomycins, new antibiotics from Actinoplanes teichomyceticus nov sp. II. Extraction and chemical characterization. J Antibiot. 1978. V. 31(3): 170-177.
- Belanger M, Burrows L L and Lam J S. Functional analysis of genes responsible for the synthesis of the B-band O antigen of Pseudomonas aeruginosa serotype 06 lipopolysaccharide. Microbiology. 1999. V. 145:3505-3521.
- Bentley S D, Chater K F, Cerdeno-Tarraga A M, Challis G L, Thomson N R, James K D, Harris D E, Quail M A, Kieser H, Harper D, Bateman A, Brown S, Chandra G, Chen C W, Collins M, Cronin A, Fraser A, Goble A, Hidalgo J, Hornsby T, Howarth S, Huang C H, Kieser T, Larke L, Murphy L, Oliver K, O'Neil S, Rabbinowitsch E, Rajandream M A, Rutherford K, Rutter S, Seeger K, Saunders D, Sharp S, Squares R, Squares S, Taylor K, Warren T, Wietzorrek A, Woodward J, Barrell B G, Parkhill J, Hopwood D A. Complete genome sequence of the model actinomycete Streptomyces coelicolor A3(2). Nature. 2002. 417:141-147.
- Bibb M J. Regulation of secondary metabolism in streptomycetes. Curr Opin Microbiol. 2005. V. 8:208-215.
- Bierman M, Logan R, O'Brien K, Seno E T, Rao R N, Schoner B E. Plasmid cloning vectors for the conjugal transfer of DNA from Escherichia coli to Streptomyces spp. Gene. 1992. 116:43-49.
- Blondelet-Rouault, M. H., Weiser, J., Lebrihi, A., Branny, P., and Pernodet, J. L. (1997). Antibiotic resistance gene cassettes derived from the omega interposon for use in E. coli and Streptomyces. Gene 190, 315-317.
- Chaffin D O, McKinnon K and Rubens C E. CpsK of Streptococcus agalactiae exhibits α2,3-sialyltransferase activity in Haemophilus ducreyi. Mol Microbiol. 2002. V. 45(1):109-122.
- Chang G. Multidrug resistance ABC transporters. FEBS Lett. 2003 Nov. 27; 555(1):102-5.
- Chater K F. Streptomyces inside-out: a new perspective on the bacteria that provide us with antibiotics. Phil Trans R Soc B. 2006. V. 361:761-768.
- Chen L, Walker D, Sun B, Hu Y, Walker S, Kahne D: Vancomycin analogues active against vanA-resistant strains inhibit bacterial transglycosylase without binding substrate. Proc Natl Acad Sci USA 2003, 100: 5658-5663.
- Dairi T. Studies on biosynthetic genes and enzymes of isoprenoids produced by actinomycetes. J Antibiot (Tokyo). 2005 April; 58(4):227-43.
- Datsenko, K. A., and Wanner, B. L. (2000). One-step inactivation of chromosomal genes in Escherichia coli K-12 using PCR products. Proc. Natl. Acad. Sci. USA 97, 6640-6645.
- Decker H, Gaisser S, Pelzer S, Schneider P, Westrich L, Wohlleben W, Bechthold A. A general approach for cloning and characterizing dNDP-glucose dehydratase genes from actinomycetes. FEMS Microbiol Lett. 1996. V. 141: 195-201.
- Du, Y., Li, T., Wang, Y. G. and Xia, H. Identification and Functional Analysis of dTDP-Glucose-4,6-Dehydratase Gene and Its Linked Gene Cluster in an Aminoglycoside Antibiotics Producer of Streptomyces tenebrarius H Curt. Microbiol. 49 (2), 99-107 (2004).
- Durr C, Schnell H-J, Luzhetskyy A, Murillo R, Weber M, Welzel K, Vente A and Bechthold A. Biosynthesis of the terpene phenalinolactone in Streptomyces sp. Tu6071: analysis of the gene cluster and generation of derivatives. Chem Biol. 2006. V. 13:365-377.
- Eichhorn P and Aga D. Characterization of moe antibiotics from medicated chicken feed by ion-trap mass spectrometry with electrospray ionization. Rapid Commun Mass Spectrom. 2005. V. 19:2179-2186.
- Feng L, Tao J, Guo H, Xu J, Li Y, Rezwan F, Reeves P, Wang L. Structure of the Shigella dysenteriae 7 O antigen gene cluster and identification of its antigen specific genes. Microb Pathog. 2004 February; 36(2):109-15.
- Flett F, Mersinias V, Smith C P. High efficiency intergeneric conjugal transfer of plasmid DNA from Escherichia coli to methyl DNA-restricting streptomycetes. FEMS Microbiol Lett. 1997. 155:223-229.
- Garneau S, Qiao L, Chen L, Walker S, Vederas J C: Synthesis of mono- and disaccharide analogs of moe and lipid II for inhibition of transglycosylase activity of penicillin-binding protein 1b. Bioorg Med Chem 2004, 12: 6473-6494.
- Genetika. 2001 October; 37(10):1340-7. Russian.
- Goldman R C, Baizman E R, Branstrom A A, Longley C B: Differential antibacterial activity of moe analogues on gram-positive bacteria. Bioorg Med Chem Lett 2000, 10: 2251-2254.
- Goldman, R. C., and Gange, D. (2000). Inhibition of transglycosylation involved in bacterial peptidoglycan synthesis. Curr. Med. Chem. 7, 801-820.
- Gromyko O M, Rebets YuV, Ostash B, Luzhetskyy A, Fukuhara M, Bechthold A, Nakamura T and Fedorenko V. Generation of Streptomyces globisporus SMY622 strain with increased landomycin E production and it's initial characterization. J Antibiot. 2004. V. 57:383-389.
- Gust B, Challis G L, Fowler K, Kieser T, Chater K F. PCR-targeted Streptomyces gene replacement identifies a protein domain needed for biosynthesis of the sesquiterpene soil odor geosmin. Proc Natl Acad Sci USA. 2003. 100:1541-1546.
- Halliday J, McKeveney D, Muldoon C, Rajaratnam P, Meutermans W. Targeting the forgotten transglycosylases. Biochem Pharmacol. 2006 Mar. 30; 71(7):957-67.
- He H, Shen B, Korshalla J, Siegel M M and Carter G T. Isolation and structural elucidation of AC326-α, a new member of the moe group. J Antibiot. 2000. V. 53(2): 191-195.
- Heijenoort van J: Formation of glycan chains in the synthesis of bacterial peptidoglycan. Glycobiol 2001, 11: 25R-36R.
- Hodgson, D. A. Primary metabolism and its control in streptomycetes: a most unusual group of bacteria. (2000). Adv. Microb. Physiol. 42, 47-238.
- Hong H J, Paget M S, Buttner M J. A signal transduction system in Streptomyces coelicolor that activates the expression of a putative cell wall glycan operon in response to vancomycin and other cell wall-specific antibiotics. Mol Microbiol. 2002 June; 44(5):1199-1211.
- Hong Y S, Lee D, Kim W, Jeong J K, Kim C G, Sohng J K, Lee J H, Paik S G, Lee J J. Inactivation of the carbamoyltransferase gene refines post-polyketide synthase modification steps in the biosynthesis of the antitumor agent geldanamycin. J Am Chem Soc. 2004 Sep. 15; 126(36):11142-3.
- Hopwood D. Soil to genomics: the Streptomyces chromosome. Ann Rev Microbiol. 2006. V. 40:1-23 (epub ahead of print)
- Ishikawa J, Hotta K. FramePlot: a new implementation of the Frame analysis for the predicting protein-coding regions in the bacterial DNA with a high G+C content. FEMS Microbiol Lett. 1999. V. 174:251-253.
- Iyobe S, Mitsuhashi S and Saito T. Sex pili mutants isolated by macarbomycin treatment. Antimicrob Agents Chemother. 1973. 3(5):614-620.
- Jabbouri S, Fellay R, Talmont F, Kamalaprija P, Burger U, Relic B, Prome J C, Broughton W J. Involvement of nodS in N-methylation and nodU in 6-O-carbamoylation of Rhizobium sp. NGR234 nod factors. J Biol Chem. 1995 Sep. 29; 270(39):22968-73.
- Kaplan J, Velliyagounder K, Ragunath C, Rohde H, Mack D, Knobloch J K-M and Ramamsubbu N. Genes involved in the synthesis and degradation of matrix polysaccharide in Actinobacillus actinomycetemcomitans and Actinobacillus pleuropneumoniae biofilms. J Bacteriol. 2004. V. 186:8213-8220.
- Kaur P. Expression and characterization of DrrA and DrrB proteins of Streptomyces peucetius in Escherichia coli: DrrA is an ATP binding protein. J Bacteriol. 1997 February; 179(3):569-75.
- Kawasaki T, Hamano Y, Kuzuyama T, Itoh N, Seto H and Dairi T. Interconversion of the product specificity of type I eubacterial farnesyl diphosphate synthase and geranylgeranyl diphosphate synthase through one amino acid substitution. J Biochem. 2003. V. 133:83-91.
- Kawasaki T, Hayashi Y, Kuzuyama T, Furihata K, Itoh N, Seto H, Dairi T. Biosynthesis of a natural polyketide-isoprenoid hybrid compound, furaquinocin A: identification and heterologous expression of the gene cluster. J Bacteriol. 2006. 188(4):1236-44.
- Kieser T, Bibb M J, Buttner M J, Chater K F and Hopwood D A. Practical Streptomyces genetics. 2000. Norwich, England: The John Innes Foundation.
- Knirel Y A, Dashunin V V, Shashkov A S, Kochetkov N K, Dmitriev B A, Hofman I L. Somatic antigens of Shigella: structure of the O-specific polysaccharide chain of the Shigella dysenteriae type 7 lipopolysaccharide. Carbohydrate Res. 1988. V. 179:51-60.
- Kudo F, Kawabe K, Kuriki H, Eguchi T, Kakinuma K. A new family of glucose-1-phosphate/glucosamine-1-phosphate nucleotidylyltransferase in the biosynthetic pathways for antibiotics. J Am Chem Soc. 2005 Feb. 16; 127(6):1711-8.
- Leskiw B K, Mah R, Lawlor E J and Chater K F. Accumulation ofbldA-specified tRNA is temporally regulated in Streptomyces coelicolor A3(2). J Bacteriol. 1993. V. 175:1995-2005.
- Leskiw, B. K., Lawlor, E J., Fernandez-Abalos, J. M., and Chater, K. F. (1991). TTA codons in some genes prevent their expression in a class of developmental, antibiotic-negative, Streptomyces mutants. Proc. Natl. Acad. Sci. USA. 88, 2461-2465.
- Lin W S, Cunneen T, Lee C Y. Sequence analysis and molecular characterization of genes required for the biosynthesis of type 1 capsular polysaccharide in Staphylococcus aureus. J Bacteriol. 1994 November; 176(22):7005-16.
- Lindner 1961
- Liu H, Ritter T K, Sadamoto R, Sears P S, Wu M, Wong C H. Acceptor specificity and inhibition of the bacterial cell-wall glycosyltransferase MurG. Chembiochem. 2003.4:603-609.
- Lombo, Felipe, Brana A. F., Mendez, C and Salas J. A. The mirithramycin gene cluster of Streptomyces argillaceus contains a positive regulatory gene and two repeated DNA sequences that are located at both ends of the cluster. J. Bacteriol. 1999 January; 181(2):642-647.
- Lovering, A. L., de Castro, L. H., Lim, D., and Strynadka, N. C. (2007). Structural insight into the transglycosylation step of bacterial cell-wall biosynthesis. Science. 315, 1402-1405.
- Luzhetskyy A, Fedoryshyn M, Durr C, Taguchi T, Novikov V and Bechthold A. Iteratively acting glycosyltransferases involved in the hexasaccharide biosynthesis of landomycin A. Chem Biol. 2005. V. 12:725-729.
- Luzhetskii A N, Ostash B E, Fedorenko V A. Interspecies conjugation of Escherichia coli-Streptomyces globisporus 1912 using integrative plasmid pSET152 and its derivatives]
- McAlpine J B, Bachmann B O, Piraee M, Tremblay S, Alarco A M, Zazopoulos E, Farnet C M. Microbial genomics as a guide to drug discovery and structural elucidation: ECO-02301, a novel antifungal agent, as an example. J Nat Prod. 2005. 68(4):493-6.
- McKeegan K S, Borges-Walmsley M I and Walmsley A R. The structure and function of drug pumps: an update. Trends Microbiol. 2003. V. 11(1):21-28.
- Men H, Park P, Ge M and Walker S. Substrate synthesis and activity assay for MurG. J Am Chem Soc. 1998. V. 120:2484-2485.
- Mendez C, Salas J A. The role of ABC transporters in antibiotic-producing organisms: drug secretion and resistance mechanisms. Res Microbiol. 2001. 152(3-4):341-50.
- Meyers E, Smith D, Slusarchyk W A, Bouchard J L and Weisenbom F L. The diumycins. New members of an antibiotic family having prolonged in vivo activity. J Antibiot. 1969. V. 22:490-493.
- Murrell J M, Liu W, Shen B. Biochemical characterization of the SgcA1 alpha-D-glucopyranosyl-1-phosphate thymidylyltransferase from the enediyne antitumor antibiotic C-1027 biosynthetic pathway and overexpression of sgcA1 in Streptomyces globisporus to improve C-1027 production. J Nat Prod. 2004 February; 67(2):206-13.
- Muth G, Nussbaumer B, Wohlleben W and Puhler A. A vector system with temperature-sensitive replication for gene disruption and mutational cloning in streptomycetes. Mol Gen Genet. 1989. V. 219: 341-348.
- Nakagawa A, Wu T-S, Keller P J, Lee J P, Omura S, Floss H G. Biosynthesis of asukamycin. Formation of the 2-amino-3-hydroxycyclopent-2-enone moiety. J Chem Soc Chem Commun. 1985. P. 519-521.
- Nemoto N, Oshima T, Yamagishi A. Purification and characterization of geranylgeranylglyceryl phosphate synthase from a thermoacidophilic archaeon, Thermoplasma acidophilum. J Biochem (Tokyo). 2003. 133(5):651-657.
- Neundorf I, Kohler C, Hennig L, Findeisen M, Arigoni D and Welzel P. Evidence for the combined participation of a C10 and a C15 precursor in the biosynthesis of moenocinol, the lipid part of the moe antibiotics. ChemBioChem. 2003. V. 4:1201-1205.
- Oh S H, Chater K F. Denaturation of circular or linear DNA facilitates targeted integrative transformation of Streptomyces coelicolor A3(2): possible relevance to other organisms. J Bacteriol. 1997. 179(1):122-127.
- Ostash, B., Saghatelian, A., and Walker, S. (2007). A streamlined metabolic pathway for the biosynthesis of moenomycin a. Chem Biol. 14, 257-267.
- Ostash B, Walker S. Bacterial transglycosylase inhibitors. Current Opin Chem Biol. 2005. 9:459-466.
- Pacholec M, Freel Meyers C L, Oberthur M, Kahne D, Walsh C T. Characterization of the aminocoumarin ligase SimL from the simocyclinone pathway and tandem incubation with NovM,P,N from the novobiocin pathway. Biochemistry. 2005 Mar. 29; 44(12):4949-56.
- Paton A W and Paton J C. Molecular characterization of the locus encoding biosynthesis of the lipopolysaccharide O antigen of Escherichia coli serotype 0113. Infection Immun. 1999. V. 67(11):5930-5937.
- Petricek M, Petrickova K, Havlicek L and Felsberg J. Occurrence of two 5-aminolevulinate biosynthetic pathways in Streptomyces nodosus subsp. asukaensis is linked with the production of asukamycin. J. Bacteriol. 2006. V. 188(14): 5113-5123.
- Pfaller M A. Flavophospholipol use in animals: Positive implications for antimicrobial resistance based on its microbiologic properties. Diagn Microbiol Infect Dis. 2006 May 12; [Epub ahead of print].
- Rascher A, Hu Z, Viswanathan N, Schirmer A, Reid R, Nierman W C, Lewis M, Hutchinson C R. Cloning and characterization of a gene cluster for geldanamycin production in Streptomyces hygroscopicus NRRL3602. FEMS Microbiol Lett. 2003. V. 218:223-230.
- Rebets YuV, Ostash B O, Fukuhara M, Nakamura M and Fedorenko V O. Expression of the regulatory protein LndI for landomycin E production in Streptomyces globirporus 1912 is controlled by the availability of tRNA for the rare UUA codon. FEMS Microbiol Lett. 2006. V. 256:30-37.
- Redenbach M, Flett F, Piendl W, Glocker I, Rauland U, Wafzig O, Kliem R, Leblond P, Cullum J. The Streptomyces lividans 66 chromosome contains a 1 MB deletogenic region flanked by two amplifiable regions. Mol Gen Genet. 1993. 241:255-262.
- Riedl S, Ohlsen K, Werner G, Witte W, Hacker J. Impact of flavophospholipol and
- vancomycin on conjugational transfer of vancomycin resistance plasmids. Antimicrob Agents Chemother. 2000. 44(11):3189-92.
- Sambrook J, Fritsch E F and Maniatis T. Molecular cloning, a laboratory manual. 1989. Cold Spring Harbor Laboratory, Cold Spring Harbor, N.Y.
- Sambrook, J., and Russel, D. W. (2001) Molecular Cloning: A Laboratory Manual (Cold Spring Harbor Lab. Press, Cold Spring Harbor, N.Y.), 3rd Ed.
- Schuricht U, Endler K, Hennig L, Findeisen M and Welzel P. Studies on the biosynthesis of the antibiotic moe A. J Prakt Chem. 2000. V. 342(8). P. 761-772.
- Schuricht U, Hennig L, Findeisen M, Endler K, Welzel P and Arigoni D. The biosynthesis of moenocinol, the lipid part of the moe antibiotics. Tetrahedron Lett. 2001. V. 42:3835-3837.
- Sekurova, O. N., Brautaset, T., Sletta, H., Borgos, S. E., Jakobsen, M. O. M., Ellingsen, T. E., Strom, A. R., Valla, S., and Zotchev, S. B. (2004). In vivo analysis of the regulatory genes in the nystatin biosynthetic gene cluster of Streptomyces noursei ATCC11455 reveals their differential control over antibiotic biosynthesis. J. Bacteriol. 186, 1345-1354.
- Slusarchyk W A, Weisenborn F L. The structure of the lipid portion of the antibiotic prasinomycin. Tetrahedron Lett. 1969.8: 659-662.
- Smith H E, Veenbergen V, Velde J, Damman M, Wisselink and Smits M A. The cps genes of Streptococcus suis serotypes 1, 2 and 9: development of rapid serotype-specific PCR assays. J Clin Microbiol. 1999. V. 37:3146-3152.
- Soderberg T, Chen A and Poulter C D. Geranylgeranylglycerylphosphate synthase.
- Characterization of the recombinant enzyme from Methanobacterium thermoautotrophicum. Biochemistry. 2001. V. 40:14847-14854.
- Sosio M, Stinchi S, Beltrametti F, Lazzarini A and Donadio S. The gene cluster for the biosynthesis of the glycopeptide antibiotic A40926 by Nomomuraea species. Chem Biol. 2003. V. 10:541-549.
- Subramaniam-Niehaus, B., Schneider, T., Metzger, J. W. & Wohleben, W. (1997). Isolation and analysis of moenomycin and its biosynthetic intermediates from Streptomyces ghanaensis (ATCC14672) wildtype and selected mutants. Z. Naturforsch. 52, 217-226.
- Tachibana A, Yano Y, Otani S, Nomura N, Sako Y, Taniguchi M. Novel prenyltransferase gene encoding farnesylgeranyl diphosphate synthase from a hyperthermophilic archaeon, Aeropyrum pernix. Molecular evolution with alteration in product specificity. Eur J Biochem. 2000 January; 267(2):321-8.
- Tahlan K, Park H U, Jensen S E. Three unlinked gene clusters are involved in clavam metabolite biosynthesis in Streptomyces clavuligerus. Can J Microbiol. 2004. 50(10):803-10.
- Takahashi H, Liu Y N, Liu H W. A two-stage one-pot enzymatic synthesis of TDP-L-mycarose from thymidine and glucose-1-phosphate. J Am Chem Soc. 2006. 128(5):1432-1433.
- Takahashi S, Okanishi A, Utahara R, Nitta K, Maeda K, Umezawa H. Macarbomycin, a new antibiotic containing phosphorus. J Antibiot. 1970. V. 23(1). P: 48-50.
- Taylor, J. G., Li, X., Oberthur, M., Zhu, W., and Kahne, D. E. (2006). The total synthesis of moenomycin A. J. Am. Chem. Soc. 128, 15084-15085.
- Thuy T T, Lee H C, Kim C G, Heide L, Sohng J K. Functional characterizations of novWUS involved in novobiocin biosynthesis from Streptomyces spheroides. Arch Biochem Biophys. 2005. 436(1):161-7.
- Trepanier N K, Jensen S E, Alexander D C and Leskiw B K. The positive activator of cephamycin C and clavulanic acid production in Streptomyces clavuligerus is mistranslated in a bldA mutant. Microbiology. 2002. V. 148: 643-656.
- Wallhausser K H, Nesermann G, Prave P and Steigler A. Moe, a new antibiotic. I. Fermentation and isolation. Antimicrob Agents Chemother. 1965. P. 734-736.
- Wang X, Preston III J F and Romeo T. The pgaABCD locus of Escherichia coli promotes the synthesis of a polysaccharide adhesin required for biofilm formation. J Bacteriol. 2004. V. 186:2724-2734.
- Weber T, Welzel K, Pelzer S, Vente A, Wohlleben W. Exploiting the genetic potential of polyketide producing streptomycetes. J Biotechnol. 2003. V. 106: 221-232.
- Weisenborn F L, Bouchard J L, Smith D, Pansy F, Maestrone G, Miraglia G, Meyers E. The prasinomycins: antibiotics containing phosphorus. Nature. 1967. V. 213: P. 1092-1094.
- Welzel P, Kunisch F, Kruggel F, Stein H, Scherkenbeck J, Hiltmann A, Duddeck H, Muller D, Maggio J E, Fehlhaber H-W, Seibert G, van Heijenoort Y and van Heijenoort J. Moe A: minimum structural requirements for biological activity. Tetrahedron 1987. V. 43(3):585-598.
- Welzel P: Transglycosylase inhibition. In Antibiotics and antiviral compounds—chemical synthesis and modification. Edited by Krohn K, Kirst H and Maag H. VCH Weinheim, Germany, 1993: 373-378. Welzel, P. (2005).
- Welzel P. Syntheses around the transglycosylation step in peptidoglycan biosynthesis. Chem Rev. 2005. V. 105:4610-4660.
- Westrich L, Domann S, Faust B, Bedford D, Hopwood D A, Bechthold A. Cloning and characterization of a gene cluster from Streptomyces cyanogenus S136 probably involved in landomycin biosynthesis. FEMS Microbiol Lett. 1999. 170:381-387.
- Wilson V T and Cundliffe E. Molecular analysis of tirB, an antibiotic-resistance gene from tylosin-producing Streptomycesfradiae, and discovery of a novel resistance mechanism. J Antibiot. 1999. V. 52 P: 288-296.
- Yuan, Y., Barrett, D., Zhang, Y., Kahne, D., Sliz, P., and Walker, S. (2007). Crystal structure of a peptidoglycan glycosyltransferase suggests a model for processive glycan chain synthesis. Proc. Natl. Acad. Sci. USA. 104, 5348-5353.
- Yu T-W, Bai L, Clade D, Hoffman D, Toelzer S, Trihn K Q, Xu J, Moss S J, Leistner E and Floss H G. The biosynthetic gene cluster of the maytansinoid antitumor agent ansamitocin from Actinosynnema pretiosum. Proc Natl Acad Sci. 2002. V. 99(12):7968-7973.
- Zalkin H, Smith J L. Enzymes utilizing glutamine as an amide donor. Adv Enzymol Relat Areas Mol Biol. 1998. V. 72:87-144.
- Zehl M, Pitternauer E, Rizzi A, Allmaier G. Characterization of moe antibiotic complex by multistage MALDI-IT/RTOF-MS and ESI-IT-MS. J Am Soc Mass Spectrom. 2006. V. 17:1081-1090.
- Zhang L, Radziejewska-Lebrecht J, Krajewska-Pietrasik D, Toivanen P and Skurnik M. Molecular and chemical characterization of the lipopolysaccharide O-antigen and its role in the virulence of Yersinia enterocolitica serotype O:8. Mol Microbiol. 1997. V. 27(1):63-76.
- Zhu L, Ostash B, Rix U, Nur-E-Alam M, Mayers A, Luzhetskyy A, Mendez C, Salas J A, Bechthold A, Fedorenko V, Rohr J. Identification of the function of gene IndM2 encoding a bifunctional oxygenase-reductase involved in the biosynthesis of the antitumor antibiotic landomycin E by Streptomyces globisporus 1912 supports the originally assigned structure for landomycinone. J Org Chem. 2005. 70:631-638.
The contents of the aforementioned references are incorporated herein by reference in their entireties.
EQUIVALENTS
The present invention is not to be limited in terms of the particular embodiments described in this application, which are intended as single illustrations of individual aspects of the invention. Many modifications and variations of this invention can be made without departing from its spirit and scope, as will be apparent to those skilled in the art. Functionally equivalent methods and apparatuses within the scope of the invention, in addition to those enumerated herein, will be apparent to those skilled in the art from the foregoing descriptions. Such modifications and variations are intended to fall within the scope of the appended claims. The present invention is to be limited only by the terms of the appended claims, along with the full scope of equivalents to which such claims are entitled.
Claims
1-11. (canceled)
12. A method of synthesizing a moenomycin, a moenomycin derivative, or a moenomycin intermediate wholly or partially in vitro comprising: reacting a one or more moenomycin precursor, derivative and/or moenomycin intermediate with a one or more polypeptide selected from the group consisting of: moeA4, moeB4, moeC4, moeB5, moe A5, moeD5, moeJ5, moeE5, moeF5, moeH5, moeK5, moeM5, moeN5, moe05, moeX5, moeP5, moeR5, moeS5, moeGT1, moeGT2, moeGT3, moeGT4, and moeGT5, under conditions wherein the moenomycin, the moenomycin derivative, or the intermediate is wholly or partially synthesized.
13. A method of modifying a moenomycin wholly or partially in vitro comprising: reacting a moenomycin, a moenomycin derivative or a moe intermediate with a one or more polypeptide selected from the group consisting of: moeA4, moeB4, moeC4, moeB5, moe A5, moeD5, moeJ5, moeE5, moeF5, moeH5, moeK5, moeM5, moeN5, moeO5, moeX5, moeP5, moeR5, moeS5, moeGT1, moeGT2, moeGT3, moeGT4, and moeGT5, under conditions wherein the moenomycin, the moenomycin derivative, or the moenomycin intermediate is modified.
14-15. (canceled)
16. A moenomycin derivative having the structure:
wherein
Ac is acetyl;
R and R1 independently are selected from the group consisting of hydroxyl, and —NHR2 where R2 is hydrogen, alkyl, cycloalkyl, or substituted cycloalkyl;
X is hydrogen, or
R3 is selected from the group consisting of hydrogen and hydroxyl; and
X1 is selected from the group consisting of hydrogen,
R4 is selected from the group consisting of hydrogen and hydroxyl;
R5 is selected from the group consisting of hydroxyl and —NHR6 where R6 is selected from the group consisting of hydrogen, alkyl, cycloalkyl, and substituted cycloalkyl, and
R7 is hydrogen or methyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
17. The moenomycin derivative of claim 16, wherein R and R1 independently are —NH2.
18. The moenomycin derivative of claim 16, wherein X is hydrogen or
19. (canceled)
20. The moenomycin derivative of claim 16, wherein X1 is hydrogen,
21-22. (canceled)
23. The moenomycin derivative of claim 16, wherein the structure is:
R3 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
24. The moenomycin derivative of claim 23, wherein R3 is hydrogen or hydroxyl.
25. (canceled)
26. The moenomycin derivative of claim 16, wherein the structure is:
R4 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
27-28. (canceled)
29. The moenomycin derivative of claim 16, wherein the structure is:
R4 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
30-31. (canceled)
32. The moenomycin derivative of claim 16, wherein the structure is:
R4 is selected from the group consisting of hydrogen and hydroxyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
33-34. (canceled)
35. The moenomycin derivative of claim 16, wherein the structure is:
R4 is selected from the group consisting of hydrogen and hydroxyl, PGP-151,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
36-37. (canceled)
38. The moenomycin derivative of claim 16, wherein the structure is:
wherein R4 is hydrogen or hydroxyl and R6 is selected from the group consisting of hydrogen, alkyl, cycloalkyl, and substituted cycloalkyl,
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
39-43. (canceled)
44. A pharmaceutical composition comprising the moenomycin derivative of claim 16 and a pharmaceutically acceptable carrier.
45. A moenomycin derivative having the structure:
wherein
R7 and R8 independently are selected from the group consisting of hydroxyl and —NHR9 where R9 is selected from the group consisting of hydrogen, alkyl, cycloalkyl, and substituted cycloalkyl; and
R10 is hydrogen or hydroxyl;
or a pharmaceutically acceptable salt, tautomer, and/or ester thereof.
46-48. (canceled)
49. A pharmaceutical composition comprising the moenomycin derivative of claim 45 and a pharmaceutically acceptable carrier.
50. An isolated Streptomyces strain selected from the group consisting of: Streptomyces ghanaensis, Streptomyces ederensis, Streptomyces geysiriensis, and Streptomyces bambergiensis strain which carries a one or more mutant or inactivated genes, wherein the mutant or inactivated genes are selected from the group consisting of: moeA4, moeB4, moeC4, moeB5, moe A5, moeD5, moeJ5, moeE5, moeF5, moeH5, moeK5, moeM5, moeN5, moeO5, moeX5, moeP5, moeR5, moeS5, moeGT1, moeGT2, moeGT3, moeGT4, and moeGT5.
51. The isolated Streptomyces strain of claim 50, wherein the Streptomyces ghanaensis strain is Streptomyces ghanaensis ATCC14627.
52-54. (canceled)
55. The method according to claim 12, wherein the method further comprises reacting the moenomycin, moenomycin derivative and/or moenomycin intermediate with a one or more reactants selected from the group consisting of: UDP-sugars, prenyl-pyrophosphates, phosphoglycerate, amino acids, carbamoyl phosphate, ATP and biological cofactors.
56. The method according to claim 13, wherein the method further comprises reacting the moenomycin, moenomycin derivative and/or moenomycin intermediate with a one or more reactants selected from the group consisting of: UDP-sugars, prenyl-pyrophosphates, phosphoglycerate, amino acids, carbamoyl phosphate, ATP and biological cofactors.
Images & Drawings included:






























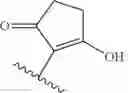
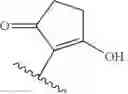












Sources:
- United States Patent and Trademark Office - verify current appl. status at the USPTO↗
Similar patent applications:
Recent applications in this class:
- » 20250146039 2025-05-08
Terpene Glycoside Derivatives and Uses Thereof - » 20250129401 2025-04-24
PH- AND TEMPERATURE-STABLE ETHERIC SOPHOROLIPIDS AND THEIR USE - » 20250066829 2025-02-27
OZONE TREATMENT OF FERMENTATION MEDIA - » 20240368660 2024-11-07
ENHANCED PRODUCTION OF RHAMNOLIPIDS USING AT LEAST TWO CARBON SOURCES - » 20240279701 2024-08-22
Preparation Method and Enrichment Method for Cyanidin-3-Diglucoside-5-Glucoside - » 20240254533 2024-08-01
METHODS FOR PRODUCING TRYPTAMINE DERIVATIVES - » 20240191272 2024-06-13
METHOD FOR PRODUCING ANTIBODY-DRUG CONJUGATE AND ENZYME USED FOR THE SAME - » 20240182940 2024-06-06
Enhanced Sophorolipid Derivatives - » 20240175066 2024-05-30
MODIFIED HOST CELLS FOR HIGH EFFICIENCY PRODUCTION OF VANILLIN - » 20240124911 2024-04-18
ENZYMATIC METHOD FOR PREPARATION OF GDP-FUCOSE
Recent applications for this Assignee:
- » 20250172524 2025-05-29
AUTONOMOUS DIRECTIONAL MICROFLUIDIC DEVICES - » 20250172433 2025-05-29
LUMINESCENCE SPECTROSCOPY APPARATUS - » 20250171829 2025-05-29
MULTIPLEX FLUORESCENT CELLULAR AND TISSUE IMAGING WITH DNA ENCODED THERMAL CHANNELS AND USES THEREOF - » 20250160718 2025-05-22
SYSTEMS AND METHODS FOR HIGH-DENSITY LONG-TERM INTRACELLULAR ELECTROPHYSIOLOGY - » 20250152611 2025-05-15
IMMUNOMODULATORY LIPIDS AND USES THEREOF - » 20250144231 2025-05-08
COMPOSITIONS AND METHODS FOR LOCALIZED DELIVERY OF CYTOKINES FOR ADOPTIVE CELL THERAPY - » 20250144227 2025-05-08
C-16 MODIFIED TRIOXACARCINS, ANTIBODY DRUG CONJUGATES, AND USES THEREOF - » 20250136769 2025-05-01
ENTANGLED POLYMER NETWORKS - » 20250128256 2025-04-24
MICROFLUIDIC DEVICES WITH AUTONOMOUS DIRECTIONAL VALVES - » 20250127929 2025-04-24
SCAFFOLDS FOR MODIFYING IMMUNE CELLS AND THE USES THEREOF