Pyramid algorithm for video compression and video analysis
US20200314451A1
2020-10-01
16/300,986
2017-05-14
✅ Patent granted
US 11,259,051 B2
2022-02-22
WO; PCT/IB2017/052834; 20170514
WO; WO2017/199149; 20171123
Stefan Gadomski
Manelli Selter PLLC | Edward Stemberger
2038-02-06
Abstract:
A method of representing image data comprising a spatial pyramid data structure of order L, said method comprising: providing an initial representation of said image data, said representation comprising a set of lattices of level 0; connecting each said lattices of level 0 to said image data; performing L reduction steps each comprising: for each one of at least one current lattice of the current level, optionally blurring said current lattice; providing a plurality of down sampled sub-lattices of said current optionally blurred lattice, said at least one current lattice being the parent lattice of said respective plurality of down sampled sub-lattices; and conecting said plurality of down sampled sub-lattices to said respective parent lattice, wherein said plurality of down sampled sub-lattices of the current level, comprise the set of current lattices for the next level.
Assignee:
- NUMERI LTD. 8 🇮🇱 Haifa, Israel
Applicant:
Interested in similar patents?
Get notified when new applications in this technology area are published.
Classification:
H04N19/59 » CPC further
Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving spatial sub-sampling or interpolation, e.g. alteration of picture size or resolution
H04N19/61 » CPC main
Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using transform coding in combination with predictive coding
Description
CROSS-REFERENCE TO RELATED PATENT APPLICATIONS
This patent application claims priority from and is related to U.S. Provisional Patent Application Ser. No. 62/336,770, filed on 16 May 2016, this U.S. Provisional Patent Application incorporated by reference in its entirety herein.
TECHNOLOGY FIELD
The present invention is in the field of video compression and video analysis.
BACKGROUND
A video consists of a sequence of frames, with a given spatial and temporal resolution. The spatial resolution is given by the number of pixels sampled along the x and y space directions, so called the number of columns and rows of the frame. The temporal resolution is given by the number of pixels sampled along the time direction so called the number of frames in the video. We can therefore view the sampled frame as a two dimensional rectangular lattice with corresponding sub-lattices as in FIG. 1, In diagram 110, we display the four Dyadic sub-lattices of the frame lattice, namely: the Dyadic-Even-Even sub-lattice of the Triangle pixels, the Dyadic-Even-Odd sub-lattice of the Diamond pixels, the Dyadic-Odd-Even sub-lattice of the Square pixels, and the Dyadic-Odd-Odd sub-lattice of the Star pixels, In diagram 120 we display the two Quincunx sub-lattices of the frame lattice, namely: the Quincunx-Even sub-lattice of the Black pixels and the Quincunx-Odd sub-lattice of the White pixels. Note that whereas the Dyadic sub-lattices are regular rectangular frame lattices as the original frame lattice is, the Quincunx sub-lattices are not. In order to make them regular, we can rotate them for example by 45° clockwise. In FIG. 2, we display the Quincunx-Even sub-lattice. Note that the un-rotated Quincunx-Even sub-lattice frame in diagram 210 is non rectangular. The rotated Quincunx-Even sub-lattice of diagram 220 is rectangular, but still not regular as the original frame lattice is because of the missing pixels on the four corners of the frame. In FIG. 3 we display the two Quincunx-Even's sub-lattices. As displayed in diagram 310, the Quincunx-Even-Even sub-lattice is denoted by 1, and the Quincunx-Even-Odd sub-lattice is denoted by 2. These Quincunx-Even's sub-lattices, as displayed in diagram 320, are again not regular frames because of the missing pixels at the four corners of the frame. In order to make them regular we need to un-rotate them counter clockwise by 45°. The resulting un-rotated Quincunx-Even's sub-lattices, displayed in diagram 330, now become regular rectangular frame lattices as the original frame lattice is. Note further that the Quincunx-Even-Even sub-lattice corresponds to the Dyadic-Even-Even sub-lattice, and that the Quincunx-Even-Odd sub-lattice corresponds to the Dyadic-Even-Odd sub-lattice. In FIG. 4, we display similarly the Quincunx-Odd sub-lattice. Note again that the un-rotated Quincunx-Odd sub-lattice frame in diagram 410 is non rectangular. The rotated Quincunx-Odd sub-lattice of diagram 420 is rectangular, but still not regular as the original frame lattice because of the missing pixels on the four corners of the frame. In FIG. 5, we display the two Quincunx-Odd's sub-lattices. As displayed in diagram 510, the Quincunx-Odd-Even sub-lattice is denoted by 3, and the Quincunx-Odd-Odd sub-lattice is denoted by 4. These Quincunx-Odd's sub-lattices, as displayed in diagram 520, are again not regular frames because of the missing pixels at the four corners of the frame. In order to make them regular we need to un-rotate them counter clockwise by 45°. The resulting un-rotated Quincunx-Odd's sub-lattices, displayed in diagram 530, now become regular frame lattices as the original frame lattice is. Here the Quincunx-Odd-Even sub-lattice corresponds to the Dyadic-Odd-Even sub-lattice, and the Quincunx-Odd-Odd sub-lattice corresponds to the Dyadic-Odd-Odd sub-lattice.
We therefore conclude that any two consecutive Quincunx down sampling operations correspond to one Dyadic down sampling operation, resulting in a regular frame lattice as the original frame lattice is.
SUMMARY
BRIEF DESCRIPTION OF THE DRAWINGS
For better understanding of the invention and to show how the same may be carried into effect, reference will now be made, purely by way of example, to the accompanying drawings.
With specific reference now to the drawings in detail, it is stressed that the particulars shown are by way of example and for purposes of illustrative discussion of the preferred embodiments of the present invention only, and are presented in the cause of providing what is believed to be the most useful and readily understood description of the principles and conceptual aspects of the invention. In this regard, no attempt is made to show structural details of the invention in more detail than is necessary for a fundamental understanding of the invention, the description taken with the drawings making apparent to those skilled in the art how the several forms of the invention may be embodied in practice. In the accompanying drawings:
FIG. 1 is a diagram of a frame lattice and some of its sub-lattices;
FIG. 2 is a diagram of the Quincunx-Even sub-lattice;
FIG. 3 is a diagram of the Quincunx-Even's sub-lattices;
FIG. 4 is a diagram of the Quincunx-Odd sub-lattice;
FIG. 5 is a diagram of the Quincunx-Odds sub-lattices;
FIG. 6 is a diagram of some additional interpolated frames;
FIG. 7 is a diagram of an example of a complete Spatial Pyramid with L=2, N=2, and q=½;
FIG. 7a is a diagram of an example of a partial Spatial Pyramid with L=2, N=2, and q=½;
FIG. 8 is a diagram of an example of a complete Quincunx Spatial Pyramid with L=2, and q=½;
FIG. 8a is a diagram of an example of a partial Quincunx Spatial Pyramid with L=2, and q=½;
FIG. 9 is a diagram of an example of optical flow at odd levels k=(2m+1),
FIG. 10 is a diagram of an example of the up scaled optical flow of FIG. 9; and
FIG. 11 is a diagram of an example of spatial pixel prediction.
DETAILED DESCRIPTION OF EMBODIMENTS
In the present invention we present a new pyramid data structure and algorithms for video compression and video analysis.
The Spatial Pyramid of Sub-Lattices
A Spatial Pyramid is created using the current frame lattice and its related sub-lattices.
Initialization
We begin by creating additional frames of the same resolution as the original frame using interpolation. For example, we may interpolate the original frame by half pixel along the x (columns) direction, or by half pixel along the y (rows) direction or by half pixel along both the x and y directions. In FIG. 6, we show such possible half pixel interpolations. We assume here that the original frame, displayed in diagram 610, corresponds to the Dyadic down-sampled Triangle sub-lattice of the frame displayed in diagram 110 of FIG. 1. Then, half pixel interpolations of the original frame along the x direction, as displayed in diagram 620, correspond to the Dyadic down-sampled Square sub-lattice of the frame in diagram 110. Similarly, half pixel interpolations along the y direction as displayed in diagram 630, correspond to the Dyadic down-sampled Star sub-lattice of the frame in diagram 110, and half pixel interpolations along both the x and y directions, as displayed in diagram 640, correspond to the Dyadic down-sampled Diamond sub-lattice of the frame in diagram 110. We can similarly create additional frames by quarter pixel interpolation etc.
In general, let
q = 1 p
denotes the q-fractional interpolation method used to create the additional frames, and let Z denotes the original frame. Then we begin with a set of p2 shifted frames of the same resolution as the original frame, which we denote as:
Zi,j, 0≤i, j<p.
Here the i-index above represents the q-fractional interpolation of the original frame along the y-direction, and the j-index above represents similarly the q-fractional interpolation of the original frame along the x-direction. Hence, for example, frame Z0,0 corresponds to the original frame Z, frame Z1,0 corresponds to the frame resulting from
q = 1 p
fractional interpolation of the original frame Z along the y-direction, etc. We now define the Spatial Pyramid for this set of p2 shifted frames as defined above. Let L≥0 be some integer defining the order of the Spatial Pyramid. Then we begin by denoting the 0-level of the pyramid by the set of lattices
Zi,j0,0≡Zi,j, 0≤i,j<p,
where the first top index represents the level number, and the second top index represents a global numbering for that lattice. We then connect each such lattice to the original frame, see for example FIG. 7, and FIG. 7a.
Now, assume we are using some down sampling method, such as Quincunx down sampling, Dyadic down sampling etc. Then, let N denote the number of sub-lattices for that method. For example, for the Quincunx down sampling method N=2, and for the Dyadic down sampling method N=4.
We now proceed to define the creation of the Spatial Pyramid of order L.
Step k=0, . . . , L−1
We first optionally blur each frame lattice of level k to get the blurred frame lattices:
Z i , j k , n k → Z ~ i , j k , n k , { 0 n k < N k 0 i , j < p
Next, given said above down sampling method, with N possible sub-lattices, we create all the possible sub-lattices for each of these optionally blurred frame lattices, namely:
Z ~ i , j k , n k → Z i , j k + 1 , n k N + n , { n = 0 , … , N - 1 0 n k < N k 0 i , j < p
Finally, we denote all these down-sampled sub-lattices as:
Z i , j k + 1 , n k + 1 , { 0 n k + 1 < N k + 1 0 i , j < p
and call them the respective frame lattices of level (k+1).
The Pyramid Relations
We construct the Pyramid by connecting the frame lattices of each level, namely
Z i , j k , n k , { 0 ≤ k < L 0 n k < N k 0 i , j < p
to their respective frame lattices of the next level, namely:
Z i , j k + 1 , n k N + n , n = 0 , … , N - 1 , { 0 ≤ k < L 0 n k < N k 0 i , j < p .
In this context we define {tilde over (Z)}i,jk,nk to be the parent of Zi,jk+1,nkN+n and we denote this as
Z ~ i , j k , n k = Par ( Z i , j k + 1 , n k N + n ) , n = 0 , … , N - 1 , { 0 ≤ k < L 0 n k < N k 0 i , j < p
An example of a complete Spatial Pyramid and its pyramid relations for L=2, N=2 and q=½ is depicted in FIG. 7. In practice, we can apply the reduction step to only some of the respective lattices of the corresponding level, yielding a partial Spatial Pyramid as for example depicted in FIG. 7a. for L=2, N=2, and q=½.
EXAMPLE
The Quincunx Spatial Pyramid
In this section we give a more concrete example of the Quincunx Spatial Pyramid.
Initialization
We begin by creating additional frames of the same resolution as the original frame using interpolation as was done in the previous section. Here, we let q=2−p denote the fractional interpolation method used to create the additional frames, so that the total number of initial frames is now 4p, namely:
Zi,j, 0≤i, j<2p.
Here the index above represents again the q-fractional interpolation of the original frame along the y-direction, and the j-index above represents similarly the q-fractional interpolation of the original frame along the x-direction. Hence, for example, frame Z0,0 corresponds to the original frame Z, frame Z1,0 corresponds to the frame resulting from q=2−p fractional interpolation of the original frame Z along the y-direction, etc. We now use the Quincunx down sampling method to create the Quincunx Spatial Pyramid of order L using the following notations for level 0:
Zi,j0≡Zi,j, 0≤i,j<2p,
In what follows we assume the distances between the pixels of the original frame, along the x and the y directions, are the same, and are equal to 1. We now distinguish between Even and Odd steps as follows.
Even Step k=0, 2, 4, . . .
Let the frame lattices of level k be denoted by
Z i , j k , { 0 i , j < 2 m + p k = 2 m
Here, we can assume by induction that the pixel distances along the x and the y directions are (√{square root over (2)})k=2m. Note also that the ith and jth indices of each such lattice correspond to the respective fractional shift of the top left pixel of that lattice with respect to the top left pixel of the original lattice.
Then, as in the previous section, we first optionally blur each such frame lattice to get the optionally blurred frame lattices:
Z i , j k → Z ~ i , j k , { 0 i , j < 2 m + p k = 2 m
Then, we create for each of these optionally blurred lattices, the Quincunx-Even sub-lattice and the Quincunx-Odd sub-lattice which we denote as:
Z ~ i , j k → Z i , i k + 1 , Z i , i + 2 m + p k + 1 , { 0 i , j < 2 m + p k = 2 m
Or more simply as:
Z i , j k + 1 , { 0 i < 2 m + p 0 j < 2 m + p + 1 k = 2 m
Note that the ith and jth indices of each of these un-rotated Quincunx sub-lattices, as depicted in diagram 210 and diagram 410 respectively, correspond again to the fractional-shift of the top left pixels with respect to the top left pixel of the original frame. Furthermore, the pixel distances along the x and the y directions of these rotated Quincunx sub-lattices, as depicted in diagram 220 and diagram 420 respectively, are now √{square root over (2)}(k+1)=√{square root over (2)}*2m. In this context we define similarly {tilde over (Z)}i,jk to be the parent of these corresponding sub-lattices, and we denote this as:
Z ~ i , j k = Par ( Z i , j k + 1 ) Par ( Z i , j + 2 m + p k + 1 ) , { 0 i , j < 2 m + p k = 2 m
Step k=1, 3, 5, . . .
Let the frame lattices of level k be denoted as above, i.e.
Z i , j k , { 0 i < 2 m + p 0 j < 2 m + p + 1 k = 2 m + 1
Then, as observed above, the pixel distances along the x and the y directions of these rotated Quincunx sub-lattices, as depicted in diagram 220 and diagram 420 respectively, are now √{square root over (2)}k=√{square root over (2)}*2m. Similarly, the ith and jth indices of each of these un-rotated Quincunx sub-lattices, as depicted in diagram 210 and diagram 410 respectively, correspond to the fractional-shift of the top left pixels with respect to the top left pixel of the original frame.
Then, as in the previous section, we first optionally blur each such frame lattice to get the optionally blurred frame lattices:
Z i , i k → Z ~ i , j k , { 0 i < 2 m + p 0 j < 2 m + p + 1 k = 2 m + 1
Then, we create for each of these optionally blurred lattices, the Quincunx-Even sub-lattice and the Quincunx-Odd sub-lattice which we denote as:
Z ~ i , j k → Z i , j k + 1 , Z i + 2 m + p , ( j + 2 m + p ) mod ( 2 m + p + 1 ) k + 1 , { 0 i < 2 m + p 0 j < 2 m + p + 1 k = 2 m + 1
Or more simply as
Z i , j k + 1 , { 0 i , j < 2 m + p + 1 k = 2 m + 1
Note that by now, these sub-lattices become regular rectangular lattices. The ith and jth indices of each of these lattices correspond again to the fractional-shift of the top left pixels with respect to the top left pixel of the original frame. Furthermore, the pixel distances along the x and the y directions are now √{square root over (2)}(k+1)=2m+1. In this context we define similarly {tilde over (Z)}i,jk to be the parent of these corresponding sub-lattices, and we denote this as:
Z ~ i , j k = Par ( Z i , j k + 1 ) Par ( Z i , j + 2 m + p , ( j + 2 m + p ) mo d ( 2 m + p + 1 ) k + 1 ) , 0 i < 2 m + p 0 j < 2 m + p + 1 k = 2 m + 1
To summarize, we can denote the frame lattices of each level as follows:
Step k=0, 1, . . . , 1
Z i , j k = { 0 j < 2 k 1 + p , k 1 = ⌊ k 2 ⌋ 0 j < 2 k 2 + p , k 2 = ⌈ k 2 ⌉
An example of a complete Quincunx Spatial Pyramid and its pyramid relations for L=2 and q=½ is depicted in FIG. 8. In practice, we can apply the reduction step to only some of the respective lattices of the corresponding level, yielding a partial Quincunx Pyramid as for example depicted in FIG. 8a. for L=2, and q=½.
An Application to Video Compression
In this section we describe the usage of the Spatial Pyramid in the context of video compression as discussed in the No Latency algorithm presented in Pat [1]. The Spatial Pyramid can also be used in the context of many other video compression algorithms such as the ones presented in Pat [2], and Pat [3], as well as with standard video compression algorithms such as MPEG, see Ref[1].
Introduction
We consider here the problem of encoding and decoding a sequence of video frames, in the order of their appearance. In particular, we do not consider here the problem of encoding and decoding the first frame in the sequence, but only any of the following frames in the sequence. We call the frame to be encoded and decoded the current frame, and assume that all the previously processed frames are known in their decoded form to both Encoder and Decoder. We now describe the process of encoding and decoding the current frame using the previously decoded frames. For simplicity, we use here only the last previously decoded frame, although more of the previously decoded frames can be used. Furthermore, for the purpose of presentation, we use here the Quincunx Spatial Pyramid and the Quincunx down sampling method.
Initialization
Let Y be the current frame to be encoded and decoded, let Z be the last previously decoded frame, and let L denotes the order of the Quincunx Spatial Pyramid to be used. Then we begin by creating a simple pyramid decomposition for Y≡Y0 as follows: Iteratively perform the following step for k=0, 1, . . . , L−1:
Optionally blur the frame lattice Yk and denote the optionally blurred lattice by {tilde over (Y)}k. Then either Quincunx-Even down sample or Quincunx-Odd down sample this optionally blurred lattice and denote the resulting down sampled frame lattice as Yk+1. We finally denote this whole resulting simple pyramid decomposition of Y by:
Yk, {tilde over (Y)}k 0≤k<L, YL.
We now create a corresponding Quincunx Spatial Pyramid of order L for the last previously decoded frame Z, as discussed in the previous section, in both the Encoder and the Decoder. To recap, given an initial parameter p≥0, we create the respective 4p interpolated frames:
Zi,j0, 0≤i,j<2p.
Then, we create the corresponding optionally blurred lattices:
Z ~ i , j k , 0 k < L { 0 i < 2 k 1 + p , k 1 = ⌊ k 2 ⌋ 0 1 < 2 k 2 + p , k 2 = ⌈ k 2 ⌉
where each such lattice of level k is optionally blurred in the same way as {tilde over (Y)}k was blurred. Finally we down sample each of these lattices, creating both the Quincunx-Even and Quincunx-Odd sub-lattices, which we then denote as:
Z i , j k , 0 < k ≤ L { 0 i < 2 k 1 + p , k 1 = ⌊ k 2 ⌋ 0 1 < 2 k 2 + p , k 2 = ⌈ k 2 ⌉ .
The Algorithm
We encode and decode the current frame Y using the simple pyramid decomposition of Y and the respective Quincunx Spatial Pyramid of the last previously decoded frame Z as discussed above. Denoting by Ŷ the resulting decoded current frame, we will obtain in the process a corresponding simple pyramid decomposition for Ŷ, i.e.
Ŷk, {tilde over (Ŷ)}k 0≤k<L, ŶL.
More precisely, we process the pyramids bottom up, in (L+1) steps, starting from the lowest level L of the pyramid up to the top most level 0 of the pyramid. On each such step we compress/decompress the respective pyramid lattice of Y of that level, yielding the respective pyramid lattice of the decoded frame it of that level. Therefore, by the end of the algorithm we obtain the required decoded frame it as proclaimed.
Step L: We Compress/Decompress YL.
-
- 1) In the Encoder, we compress YL either directly using some known compression method such as Jpeg or Jpeg2000, or we compress YL indirectly as follows: We inspect the lowest level lattices of the respective Z Quincunx Spatial Pyramid:
Z i , j L , { 0 i < 2 L 1 + p , L 1 = ⌊ L 2 ⌋ 0 j < 2 L 2 + p , L 2 = ⌈ L 2 ⌉
-
-
- and choose the one, say Zi0,j0L, which best approximates YL. Then we compress the difference between that lattice and YL, namely DL=YL−Zi0,j0L, using any known compression method such as for example wavelet based compression methods, see for example Ref[3]. The Encoder then sends the respective compressed bit stream to the Decoder. In the first case above (direct compression of YL), the bit stream consists of the compressed lattice ŶL. In the second case above (compression of the difference between that lattice and YL), the bit stream consists of the compressed lattices' difference {circumflex over (D)}L together with the indices i0, j0.
- 2) In the Decoder, as well as in the Encoder, we now reconstruct the compressed lattice ŶL. In the first case above we decompress the bit stream to obtain ŶL directly. In the second case above we decompress the bit stream to obtain the compressed lattices' difference {circumflex over (D)}L, and then use the transmitted indices i0, j0 to obtain ŶL by computing ŶL={circumflex over (D)}L+Zi0,j0L.
-
Step k=L−1, . . . , 0: We may now assume by induction, that we have already processed all the Y pyramid lattices of level m>k, namely:
YL, Ym, {tilde over (Y)}m m=L−1, . . . , k+1.
and obtained the respective pyramid lattices of Ŷ, namely:
ŶL, Ŷm, {tilde over (Ŷ)}m m=L−1, . . . , k+1.
We now show how to proceed and obtain Ŷk and {tilde over (Ŷ)}k from that respect pyramid of lattices of Ŷ and Yk and {tilde over (Y)}k. Hence, by the end of the algorithm we obtain the decoded frame Ŷ≡Ŷ0 as required.
-
- 1) In both the Encoder and Decoder, we first compute the optical flows, see Ref[2], between the lattice Ŷk+1 and each of the respective lattices of level (k+1) of the Z Quincunx Spatial Pyramid:
F i , j k + 1 = OpticalFlow ( Y ^ k + 1 → Z i , j k + 1 ) , { 0 i < 2 k 1 + p , k 1 = ⌊ k + 1 2 ⌋ 0 j < 2 k 2 + p , k 2 = ⌈ k + 1 2 ⌉
-
- 2) Let Yk denote some proposed lattice with the same resolution as Yk and for which the lattice Ŷk+1 is its respective sub-lattice. Note that about half of the pixels in Yk are yet unknown but they will be defined later on.
- 3) In both the Encoder and Decoder, we then upscale the optical flows constructed in 1) above, to respective proposed optical flows between the proposed lattice Yk and each of the respective optionally blurred lattices of the Z Quincunx Spatial Pyramid of that level, namely,
F _ i , j k = OpticalFlow ( Y _ k + 1 → Z ~ i , j k ) , { 0 i < 2 k 1 + p , k 1 = ⌊ k 2 ⌋ 0 j < 2 k 2 + p , k 2 = ⌈ k 2 ⌉
-
-
- This can be done for example as follows: Suppose k=2m is an even level, and the optical flow between the lattice Ŷk+1 and the lattice Zi,jk+1 as computed in 1) above is given for example by FIG. 9. Then, since by the definition, the lattice Ŷk+1 is a sub-lattice of lattice Yk, then the optical flow for the Black pixels in lattice Yk is already known, see FIG. 10. It therefore remains only to compute the optical flow for the White pixels in FIG. 10. However, every “White” pixel in Yk is surrounded by four neighboring Black pixels for which the optical flow is already known. Therefore we can use this information to predict an optical flow for the surrounded White pixel of that neighborhood. For example, we can average the surrounding optical flows to get that value. In FIG. 10, the optical flow for the “White” pixel denoted by w, is therefore predicted by the average of the optical flows for pixels a,b,c and d, yielding the pixel denoted by W.
- 4) In both the Encoder and Decoder, we now complete the definition of Yk as follows. First we note that again since Ŷk+1 is a sub-lattice of Yk, we already know half of the pixels of Yk, for example the Black pixels in FIG. 10. Next, to compute the remaining pixels, we can use spatial and/or temporal prediction.
- 5) Spatial prediction: We use the known pixel values of Yk to predict the remaining pixel values of Yk. For example, we may look at a pixel's 4 surrounding neighbors as in diagram 1110 of FIG. 11, or at a pixel's 16 surroundings neighbors as in diagram 1120 of FIG. 11, etc. Using these surrounding neighbors we may now predict the White pixel value using averaging, interpolation, etc.
- 6) Temporal prediction: We use the computed proposed optical flows between the lattice Yk and the respective lattices {tilde over (Z)}i,jk of the Quincunx Spatial Pyramid of Z, computed in 3) above, to predict the missing pixels. For example, in FIG. 10, we can predict the value of the White pixel w in Yk from the corresponding value W in {tilde over (Z)}i,jk.
- 7) By now, we have completely defined the lattice Yk which should be an approximation to the lattice of {tilde over (Y)}k. In practice, however, not all pixels in Yk are good predictions to the corresponding pixels in {tilde over (Y)}k. Therefore, some corrections are needed. Accordingly, in the Encoder, we may now compute the difference
-
Dk={tilde over (Y)}k−Yk,
-
-
- and decide to improve the values of some of the pixels in the so predicted lattice Yk. For example, we can compress that difference, using some known compression method, and send the compressed bit stream to the Decoder.
- 8) In the Decoder and the Encoder, we then decompress the respective bit stream to obtain {circumflex over (D)}k. Finally, in both the Decoder and the Encoder we add that compressed difference to compute {tilde over (Ŷ)}k={circumflex over (D)}k+Yk.
- 9) in both the Decoder and Encoder we compute Ŷk by de-blurring {tilde over (Ŷ)}k.
-
The Compressed Bit Stream
The compressed bit stream consists of the aggregate compressed bit streams for:
-
- ŶL as computed in 1) of Step L above; and for
- {circumflex over (D)}k, k=L−1, . . . , 0, as computed in 7) of Step k above.
REFERENCE
Ref[1] https://en.wikipedia.org/wiki/Moving_Picture_Experts_Group.
Ref[2] https://en.wikipedia.org/wiki/Optical_flow.
Ref[3] https://en.wikipedia.org/wiki/Embedded_Zerotrees_of_Wavelet_transforms.
Patents
-
- Pat [1] Ilan Bar-On and Oleg Kostenko, Multi-Level Spatial-Temporal Resolution Increase of Video, App. No. PCT/182014/062524
- Pat [2] Ilan Bar-On and Oleg Kostenko, Video Compression Method, App. No. PCT/182013/059007
- Pat [3] Ilan Bar-On and Oleg Kostenko, A New Universal Video Codec, App. No. PCT/IB2015/054735.
Claims
1. A method of representing image data comprising a spatial pyramid data structure of order L, said method comprising:
providing an initial representation of said image data, said representation comprising a set of lattices of level 0;
connecting each said lattices of level 0 to said image data;
performing L reduction steps each comprising:
for each one of at least one current lattice of the current level, optionally blurring said current lattice;
providing a plurality of down sampled sub-lattices of said current optionally blurred lattice, said at least one current lattice being the parent lattice of said respective plurality of down sampled sub-lattices; and
connecting said plurality of down sampled sub-lattices to said respective parent lattice,
wherein said plurality of down sampled sub-lattices of the current level, comprise the set of current lattices for the next level.
2. The method of claim 1, wherein said initial representation of the image data comprises a set of lattices comprising fractional shifts of the image data.
3. The method of claim 2, wherein said set of lattices comprises only one lattice.
4. The method of claim 1, wherein said providing down sampled sub-lattices comprises performing down sampling using the Quincunx down sampling method.
5. The method of claim 1, wherein said at least one current lattice comprises all current lattices of the current level.
6. A method of representing N+1 frames of image data comprising:
providing a set of N frames, and using the method of claim 1 to create a spatial pyramid structure of order L for each one of said frames in said set of N frames;
providing another frame and creating a simple spatial pyramid data structure of order L for said another frame as follow:
said another frame comprising the current lattice of level 0;
performing L reduction steps each comprising:
optionally blurring said current lattice;
providing a down sampled sub-lattice of said current optionally blurred lattice, said current lattice being the parent lattice of said respective down sampled sub-lattice; and
connecting said down sampled sub-lattice to said respective parent lattice,
wherein said down sampled sub-lattice of the current level, comprises the current lattice for the next level.
7. The method of claim 6, used for performing video compression, wherein said set of N frames comprises a set of N already decoded frames and wherein said another frame comprises a current frame to be encoded and decoded, comprising:
compressing /decompressing the lowest level lattice of said simple spatial is pyramid using said N spatial pyramids, said decompressed lattice being the current decompressed lattice:
performing L raise steps each comprising:
computing the optical flows between said current decompressed lattice and the respective lattice of each of said N spatial pyramids;
up scaling said optical flows to optical flows for the next higher level;
predicting a decompressed lattice of the next higher level using said up scaled optical flows and the respective lattices of said N spatial pyramids:
computing an enhancement data for said decompressed lattice using the respective lattice of said simple spatial pyramid;
compressing/decompressing said enhancement data;
adding said decompressed enhancement data to said decompressed lattice of the next higher level to create an enhanced decompressed lattice of the next higher level; and
optionally deblurring said enhanced decompressed lattice of the next higher level to create the current decompressed lattice.
8. The method of claim 7 where said predicting the decompressed lattice of the next higher level comprises spatial and/or temporal prediction.
9. The method of claim 7, wherein said N already decoded frames comprise N already decoded frames of an original video, and wherein said current frame to be encoded and decoded comprises a new frame of the original video,
wherein said creating the N spatial pyramids for said N frames, is performed in both the Encoder and Decoder;
wherein said creating the simple spatial pyramid for said another frame is performed in the Encoder;
wherein said compressing the lowest level lattice of said simple spatial pyramid is performed in the Encoder; said decompressing said compressed lowest level lattice is performed in both the Encoder and Decoder;
wherein said performing L raise steps is performed in the Encoder/Decoder as follows:
said computing the optical flows is performed in both the Encoder and Decoder;
said up scaling of said optical flows is performed in both the Encoder and Decoder;
said predicting the decompressed lattice of the next higher level is performed in both the Encoder and Decoder;
said computing enhancement and said compressing of said enhancement data is performed in the Encoder;
said decompressing of said compressed enhancement data is performed in both the Encoder and Decoder; and
said adding said decompressed enhancement data and said optionally deblurring said enhanced decompressed lattice is performed in both the Encoder and Decoder.
10. The method of claim 9 where said predicting the decompressed lattice of the next higher level comprises spatial and/or temporal prediction.
Images & Drawings included:







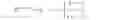
















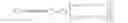
Sources:
- United States Patent and Trademark Office - verify current appl. status at the USPTO↗
Recent applications in this class:
- » 20250294188 2025-09-18
INTRA PREDICTION BASED ON TRANSFORM DOMAIN EQUATION - » 20250267306 2025-08-21
COEFFICIENT DECODING METHOD, ELECTRONIC DEVICE AND STORAGE MEDIUM - » 20250254360 2025-08-07
VIDEO CODING METHOD ON BASIS OF SECONDARY TRANSFORM, AND DEVICE THEREFOR - » 20250247562 2025-07-31
IMAGE CODING METHOD BASED ON SECONDARY TRANSFORM AND DEVICE THEREFOR - » 20250247561 2025-07-31
SELECTIVE SIGNALING OF INTER TRANSFORM TYPES AND/OR TRANSFORM SETS - » 20250234042 2025-07-17
METHOD AND APPARATUS FOR VIDEO ENCODING/DECODING USING SECONDARY TRANSFORM AND RECORDING MEDIUM STORING BITSTREAM - » 20250227299 2025-07-10
METHODS AND APPARATUSES FOR PROCESSING VIDEO SIGNAL - » 20250220239 2025-07-03
Method and Apparatus for Sign Coding of Transform Coefficients in Video Coding System - » 20250220238 2025-07-03
IMAGE DECODING METHOD AND DEVICE - » 20250211792 2025-06-26
IMAGE DECODING METHOD RELATED TO RESIDUAL CODING, AND DEVICE THEREFOR
Recent applications for this Assignee:
- » 20200193565 2020-06-18
Multi-level temporal resolution increase of video - » 20190096036 2019-03-28
Multi-level temporal resolution increase of video - » 20170150163 2017-05-25
Universal video codec - » 20160148346 2016-05-26
Multi-level spatial resolution increase of video - » 20150256837 2015-09-10
Video compression method - » 20110032994 2011-02-10
Method and a system for wavelet based processing - » 20090034624 2009-02-05
Method and apparatus for a multidimensional discrete multiwavelet transform