METHOD FOR PERFORMING PRIVACY-PRESERVING FEDERATED LEARNING IN THE FRAMEWORK OF RE-IDENTIFICATION
US20250272575A1
2025-08-28
19/066,561
2025-02-28
Smart Summary: A new method helps improve privacy while using federated learning, which allows different computers to learn from data without sharing it directly. It starts by a central computer calculating an updated model based on a main dataset. Then, this updated model and some example data are sent to several local computers. Each local computer trains its own model using the information it received and the central dataset. Finally, the local models send their results back to the central computer, which combines them to create an improved overall model. 🚀 TL;DR
Abstract:
The invention concerns a method that includes a computation loop including a transmission step for computing, by a central node, an output of a current aggregated model for each image of a central dataset. The method also includes transferring, to each of n local nodes, data representative of the aggregated model; and a set of prototypes. The method also includes a training step including for each local node, training a respective local computer vision model to obtain a respective trained local model; and performing supervised training of the aggregated model, based on the central dataset, thereby obtaining a trained central model. The method also includes an aggregation step including for each local node, transferring, to the central node, corresponding local model data; and updating the aggregated model based on the local model data; and data representative of the trained central model.
Inventors:
- Hamza RAMI 2 🇫🇷 Palaiseau, France
- Nicolas WINCKLER 5 🇫🇷 Villard Bonnot, France
- Jhony Heriberto GIRALDO ZULUAGA 2 🇫🇷 Massy, France
- Stéphane LATHUILIÈRE 2 🇫🇷 Massy, France
Assignee:
- Bull SAS 372 🇫🇷 Les Clayes Sous Bois, France
Applicant:
Interested in similar patents?
Get notified when new applications in this technology area are published.
Classification:
G06V10/82 » CPC further
Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
Description
This application claims priority to European Patent Application Number 24305312.1, filed 28 Feb. 2024, the specification of which is hereby incorporated herein by reference.
BACKGROUND OF THE INVENTION
Field of the Invention
At least one embodiment of the invention relates to a computer-implemented method for performing privacy-preserving federated learning in the framework of re-identification.
At least one embodiment of the invention further relates to a computer program and a framework.
At least one embodiment of the invention applies to the field of computer science, and more specifically to artificial intelligence for image processing.
Description of the Related Art
Re-identification (also referred to as “Re-ID”) is a crucial task in computer vision, aimed at identifying specific individuals from a collection of images acquired through various cameras.
The ability to perform Re-ID, and more specifically person Re-ID, in an accurate and efficient manner is essential for advancing intelligent surveillance systems and enhancing public safety.
Recent years have witnessed remarkable progress in Re-ID performance, thanks to the adoption of deep learning techniques. However, applying these approaches to data that is visually different from their training set results in a performance drop. Furthermore, annotating new data for each distinct environment is often infeasible.
This has prompted the introduction of Unsupervised Domain Adaptation (UDA) methods for person Re-ID.
UDA methods are known to combine an annotated dataset, corresponding to a source domain, with an unlabeled dataset, corresponding to a target domain. The objective of UDA methods is to train a model that can perform effectively in a new target environment.
However, such methods are not entirely satisfactory.
Indeed, applying UDA to person Re-ID encounters privacy concerns due to the need to collect and store images of individuals in public areas. Yet, rigorous privacy regulations in many countries prohibit technology providers from retaining images of people. As a result, the majority of UDA methods are impractical for person Re-ID
A purpose of at least one embodiment of the invention is to overcome at least one of these drawbacks.
Another purpose of at least one embodiment of the invention is to provide a method that allows to align the distributions of different local nodes (regarded as remote clients) with a source domain in a privacy-preserving manner, i.e., without sharing images at any point.
BRIEF SUMMARY OF THE INVENTION
To this end, at least one embodiment of the invention concerns method of the aforementioned type, the method comprising iteratively performing a computation loop including:
-
- a transmission step comprising:
- based on a labeled central dataset including a set of images, each image being associated with a label indicative, for each subject shown on said image, of an identity of said subject, computing, by a central node, for each identity, and for each associated image, a corresponding output of a current aggregated model using said image as input;
- transferring, from the central node to each of n local nodes, n being an integer greater than or equal to 1, each local node being distinct from the central node:
- aggregated model data representative of the aggregated model; and
- for each identity, an associated prototype depending on the corresponding computed outputs of the aggregated model;
- a training step including:
- for each local node, a local training phase comprising training a respective local computer vision model based on:
- a respective unlabeled local dataset stored in said local node and including a set of images previously acquired with at least one respective camera; and
- the received aggregated model data and prototypes, thereby obtaining a respective trained local model; and
- a central training phase comprising performing supervised training of the aggregated model, at the central node, based on the central dataset, thereby obtaining a trained central model;
- for each local node, a local training phase comprising training a respective local computer vision model based on:
- an aggregation step including:
- for each local node, transferring, from said local node to the central node, local model data representative of the respective trained local model;
- updating the aggregated model based on:
- the local model data; and
- central model data representative of the trained central model; and
- storing, in the central node, the updated aggregated model as the current aggregated model.
- a transmission step comprising:
Indeed, thanks to the use of the prototypes, privacy-preserving constraints are not breached. Consequently, alignment between the source domain and each target domain can be performed, and each local model can be trained, without actually exchanging images.
According to one or more embodiments of the invention, the method includes one or several of the following features, taken alone or in any technically possible combination:
the method further comprises, prior to performing the computation loop, an initialization step including:
-
- performing supervised training of a central computer vision model, based on the central dataset; and
- storing, in the central node, a result of the supervised training of the central computer vision model as the current aggregated model;
the aggregated model, the trained central model, and each trained local model have the same architecture, and wherein:
-
- the aggregated model data are coefficient values of the aggregated model;
- for each local node, the corresponding local model data are coefficient values of the respective trained local model; and
- the central model data are coefficient values of the trained central model;
updating the aggregated model includes computing the coefficient values of the aggregated model as a linear combination of the local model data and the central model data,
preferably as a weighted average sum calculated as:
θ = αθ s + ( 1 - α ) ∑ i = 1 n w i θ i
where:
-
- θ is a vector of the coefficient values of the aggregated model;
- α is a predetermined weight contribution of the trained central model;
- θs is a vector of the coefficient values of the trained central model;
- θi is a vector of the coefficient values of the i-th trained local model; and
- wi is a weight assigned to i-th local node, preferably computed as:
w i = N i / ∑ i = 1 n N i ;
and
-
- Ni is the number of images in the local dataset stored in the i-th local node;
for each identity, the respective prototype is an average of the outputs of the aggregated model using, as input, the images of the central dataset associated with said identity,
each prototype being preferably calculated as:
p k = 1 S k ∑ I ∈ S k F θ ( x I s ) , ∀ 1 ≤ k ≤ K
where:
-
- pk is the prototype associated with identity k;
- Sk is a subset of the central dataset including the images associated with identity k;
- |Sk| is the number of images in the subset Sk;
- Fe is the aggregated model;
- XlS is the l-th image of the subset Sk; and
- K is the number of identities associated with the central dataset;
the method further comprises, for each local dataset, implementing a clustering algorithm on the images of said local dataset to determine, for each image of said local dataset, a pseudo-label indicative, for each subject shown on said image, of an identity of said subject, and
for each local node, the local training phase comprising:
-
- initializing a teacher model and a student model with the received aggregated model data;
- iteratively performing, at said local node, a local training loop including:
- selecting a subset of the respective local dataset to form a current local subset;
- modifying the student model to minimize a local loss function depending on:
- an output of the current teacher model for each image of the local subset;
- an output of the current student model for each image of the local subset;
- a subset of the received prototypes, forming a prototype subset and having the same size as the local subset;
- storing the modified student model as the current student model;
- updating the teacher model based on the current student model;
- storing the updated teacher model as the current teacher model;
- assigning the current teacher model as the trained local model;
the local loss function is computed based on a pseudo-label loss function for each image of the current local subset and on a maximum mean discrepancy loss between the current local subset and the current prototype subset,
preferably computed as:
ℒ i = 1 m ∑ j ∈ D i . m ℒ p ( x j ( i ) ) + λℒ M ( D i , m , P m )
where:
-
- is the local loss function;
- m is the size of the local subset;
- Di,m is the current local subset;
- p(xj(i)) is the pseudo-label loss function for the j-th image of the local subset Di,m;
- λ is a predetermined weighting factor;
- Pm is the current prototype subset; and
- M(Di,m, Pm) is the maximum mean discrepancy loss between the local subset Di,m and the current prototype subset Pm;
the pseudo-label loss for the j-th image of the local subset Di,m is computed as:
ℒ p ( x j ( i ) ) = ℒ C , i ( x j ( i ) ) + ℒ T , i ( x j ( i ) )
where:
-
- C,i(xj(i)) is a cross-entropy loss term; and
-
T,i(xj(i)) is a triplet loss term,
the cross-entropy loss term C,i(xj(i)) being preferably calculated as:
ℒ C , i ( x j ( i ) ) = β 1 ℒ C ( C i ∘ F θ i ( x j ( i ) ) , y ~ j ( i ) ) + β 2 ℒ C ( C i ∘ F θ i ( x j ( i ) ) , C _ i ∘ F θ _ i ( x j ( i ) ) )
and/or the triplet loss term T,i(xj(i)) being preferably calculated as:
ℒ T , i ( x j ( i ) ) = γ 1 ℒ T ( F θ i ( x j ( i ) ) , y ~ j ( i ) ) + γ 2 ℒ T ( F θ i ( x j ( i ) ) , F θ _ i ( x j ( i ) ) )
where:
-
- xj(i) is j-th image of the local subset Di,m;
- C is a cross-entropy loss;
- T is a triplet loss;
- Ci is a student classifier head for local node i;
- Ci is a teacher classifier head for local node i;
β 1 + β 2 = 1 γ 1 + γ 2 = 1
-
- xj(i) is the j-th image of the local subset Di,m;
- {tilde over (y)}j(i) is the pseudo-label associated with image xj(i);
- Fθi is the student model; and
- Fθi is the teacher model;
the central training phase comprising:
-
- initializing a teacher model and a student model with the current aggregated model;
- iteratively performing, at the central node, a central training loop including:
- selecting a subset of the central dataset to form a current central subset;
- modifying the student model to minimize a source loss function depending on:
- an output of the current teacher model for each image of the current central subset; and
- an output of the current student model for each image of the current central subset;
- storing the modified student model as the current student model;
- updating the teacher model based on the current student model;
- storing the updated teacher model as the current teacher model;
- assigning the current teacher model as the trained central model;
the source loss function is computed as:
ℒ = 1 m ∑ j ∈ D i . m ℒ S ( x j S , y j S )
where:
-
- is the source loss function;
- m is the size of the central subset;
- DS,m is the current central subset;
- S(xjs, yjs) is a central model loss function for the j-th image of the central subset DS,m;
- xjS is the j-th image of the central subset DS,m; and
- yjS is the label associated with image xjS;
the central model loss function is computed as:
ℒ S ( x j S , y j S ) = ℒ C , S ( x j S , y j S ) + ℒ T , S ( x j S , y j S )
where:
-
- C,S(xjS, yjS) is a cross-entropy loss term; and
-
T,S(xjS, yjS) is a triplet loss term,
the cross-entropy loss term C,S(xjS, yjS) being preferably calculated as:
ℒ C , S ( x j S , y j S ) = δ 1 ℒ C ( C S ∘ F θ S ( x j S ) , y j S ) + δ 2 ℒ C ( C S ∘ F θ S ( x j S ) , C ¯ S ∘ F θ _ S ( x j S ) )
and/or the triplet loss term T,S(xjS, yjS) being preferably calculated as:
ℒ T , S ( x j S , y j S ) = μ 1 ℒ T ( F θ i ( x j S ) , y j S ) + μ 2 ℒ T ( F θ i ( x j S ) , F θ _ i ( x j S ) )
where:
-
- C is a cross-entropy loss;
- T is a triplet loss;
- CS is a student classifier head for the central node;
- CS is a teacher classifier head for the central node;
- FθS is the student model;
- FθS is the teacher model;
- δ1+δ2=1; and
- μ1+μ2=1;
for each local node, each corresponding local subset includes the images of the respective local dataset associated with a predetermined number of identities, and
for each local node, and for each local training phase, the local training loop being performed a number of times calculated as:
P i = K i I
where:
-
- Pi is the number of iterations of the local training loop;
- Ki is the number of identities associated with the respective local dataset Di; and
- I is the predetermined number of identities associated with each local subset Di,m;
and/or
each central subset includes the images of the central dataset associated with a predetermined number of identities, and
for each central training phase, the central training loop being performed a number of times calculated as:
P S = K S J
where:
-
- PS is the number of iterations of the central training loop;
- KS is the number of identities associated with the central dataset; and
- J is the predetermined number of identities associated with each central subset;
for each local node, and for each iteration of the local training loop, the updated teacher model is a linear combination of the current teacher model and the current student model,
preferably calculated using exponential moving averaging according to:
θ ¯ i ( t + 1 ) = T θ ¯ i ( t ) + ( 1 - T ) θ i
where:
-
- θi(t+1) is a vector of the coefficient values of the updated teacher model of the i-th local node;
- θi(t) is a vector of the coefficient values of the current teacher model of the i-th local node;
- θi is a vector of the coefficient values of the current student model of the i-th local node; and
- τ is a predetermined weighting factor comprised in an interval ranging from 0 to 1;
and/or
for each iteration of the central training loop, the updated teacher model is a linear combination of the current teacher model and the current student model,
preferably calculated using exponential moving averaging according to:
θ ¯ S ( t + 1 ) = ρ θ ¯ S ( t ) + ( 1 - ρ ) θ S
where:
-
- θS(t+1) is a vector of the coefficient values of the updated teacher model;
- θS(t) is a vector of the coefficient values of the current teacher model;
- θS is a vector of the coefficient values of the current student model; and
- ρ is a predetermined weighting factor comprised in an interval ranging from 0 to 1.
According to at least one embodiment of the invention, it is proposed a computer program comprising instructions, which when executed by a computer, cause the computer to carry out the steps of the method as defined above.
The computer program may be in any programming language such as C, C++, JAVA, Python, etc.
The computer program may be in machine language.
The computer program may be stored, in a non-transient memory, such as a USB stick, a flash memory, a hard-disc, a processor, a programmable electronic chop, etc.
The computer program may be stored in a computerized device such as a smartphone, a tablet, a computer, a server, etc.
According to at least one embodiment of the invention, it is proposed a framework for performing privacy-preserving federated learning for re-identification, the framework comprising a central node and n local nodes, n being an integer greater than or equal to 1, each local node being distinct from the central node,
the central node being configured to store a labeled central dataset including a set of images, each image being associated with a label indicative, for each subject shown on said image, of an identity of said subject,
each local node being configured to store a respective unlabeled local dataset stored in said local node and including a set of images previously acquired with at least one respective camera,
the framework being configured to iteratively perform a computation loop including:
-
- a transmission step wherein:
- the central node computes, based on the central dataset, for each identity, and for each associated image, a corresponding output of a current aggregated model using said image as input;
- the central node transfers to each local node:
- aggregated model data representative of the aggregated model; and
- for each identity, an associated prototype depending on the corresponding computed outputs of the aggregated model;
- a training step wherein:
- each local node performs a local training phase comprising training a respective local computer vision model based on:
- the respective unlabeled local dataset; and
- the received aggregated model data and prototypes, thereby obtaining a respective trained local model; and.
- the central node performs a central training phase comprising performing supervised training of the aggregated model based on the central dataset, thereby obtaining a trained central model;
- each local node performs a local training phase comprising training a respective local computer vision model based on:
- an aggregation step wherein:
- each local node transfers, to the central node, local model data representative of the respective trained local model;
- the central node updates the aggregated model based on:
- the local model data; and
- central model data representative of the trained central model; and
- the central node stores the updated aggregated model as the current aggregated model.
- a transmission step wherein:
The framework may include personal devices such as a smartphone, a tablet, a smartwatch, a computer, any wearable electronic device, etc.
The framework according to one or more embodiments of the invention may execute one or several applications to carry out the method according to at least one embodiment of the invention.
The framework according to one or more embodiments of the invention may be loaded with, and configured to execute, the computer program according to at least one embodiment of the invention.
BRIEF DESCRIPTION OF THE DRAWINGS
Other advantages and characteristics will become apparent on examination of the detailed description of at least one embodiment which is in no way limitative, and the attached figures, where:
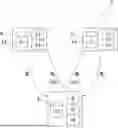
FIG. 1 is a schematic representation of a framework according to one or more embodiments of the invention;
FIG. 2 is a flowchart of a method implemented by the framework of FIG. 1, according to one or more embodiments of the invention.
DETAILED DESCRIPTION OF THE INVENTION
It is well understood that the one or more embodiments that will be described below are in no way limitative. In particular, it is possible to imagine variants of the one or more embodiments of the invention comprising only a selection of the characteristics described hereinafter, in isolation from the other characteristics described, if this selection of characteristics is sufficient to confer a technical advantage or to differentiate the one or more embodiments of the invention with respect to the state of the prior art. Such a selection comprises at least one, preferably functional, characteristic without structural details, or with only a part of the structural details if this part alone is sufficient to confer a technical advantage or to differentiate the one or ore embodiments of the invention with respect to the prior art.
In the figures, elements common to several figures retain the same reference.
A framework 2 according to one or more embodiments of the invention is shown on FIG. 1.
The framework 2 is designed to perform privacy-preserving federated learning for re-identification, and more specifically for person re-identification.
The framework 2 includes a central node 4 and n local nodes 6, n being an integer greater than or equal to 1. Each local node 6 is distinct from the central node 4.
The central node 4 is configured to store an artificial intelligence model 8 (referred to as “central model”). More specifically, the artificial intelligence model 8 is a computer vision model, preferably a re-identification model.
The central node 4 is also configured to store a central dataset 10.
The central dataset 10 is suitable for the training of an artificial intelligence model, and more specifically a computer vision model, such as the central model 8. More precisely, the central dataset 10 is a labelled (i.e., annotated) dataset including a set S of NS samples. Each sample comprises an image and, for each subject shown on said image, a corresponding label indicative of an identity of said subject.
The central dataset 10 is associated with a source domain which represents a known environment.
Preferably, in at least one embodiment, each image of the central dataset 10 is associated with a single identity. In other words, for two identities i and j, Si ∩ Sj=ϕ, ∀ i≠j, where Si (respectively Sj) is the subset of the central dataset 10 formed by the images associated with identity i (respectively with identity j).
Alternatively, the central dataset 10 is stored in a data storing unit (not shown) of the framework 2, distinct from the central node 4 and the local nodes 8. In this case, the data storing unit is configured so that the central dataset 10 can be accessed and read by the central node 4.
Advantageously, in at least one embodiment, the central dataset 10 only includes synthetic data and/or real data gathered in compliance with relevant legislation.
Each local node 6 is configured to store an artificial intelligence model 12 (referred to as “local model”). More specifically, each artificial intelligence model 12 is a computer vision model, such as a re-identification model.
Preferably, in at least one embodiment, each local model 12 has the same architecture as the central model 8.
Furthermore, each local node 6 is configured to store a respective local dataset 14. More precisely, for each local node 6, the corresponding local dataset 14 is an unlabeled dataset including a set of images, for instance a set of images previously acquired using at least one respective camera.
Each local dataset 14 is associated with a target domain that represents an unknown environment which may be different from the source domain.
Advantageously, in at least one embodiment, the framework 2 is configured so that each local dataset 14 is a private dataset that can only be read by the respective local node 6. This feature is advantageous, as it prevents data leakage, thereby enhancing privacy.
The remaining features of the framework 2 will be better understood through the description of the operation of the framework 2, provided below with reference to the figures.
The framework 2 is configured to perform a method 20, shown on FIG. 2, according to one or more embodiments of the invention.
The method 20 comprises iteratively performing a computation loop 24 including a transmission step 26, a training step 28 and an aggregation step 30.
Preferably, in at least one embodiment, the method 20 also comprises an optional initialization step 22 prior to the execution of the computation loop 24.
Initialization Step 22
During the initialization step 22, supervised training of the central model 8 is performed based on the central dataset 10.
For instance, said supervised training of the central model 8 is performed by the central node 4.
Moreover, a result of the supervised training of the central model 8 is stored, in the central node 4, as a current aggregated model 32.
Consequently, the aggregated model 32 has the same architecture as the central model 8.
Computation Loop 24
Then, the computation loop 24 is iteratively performed.
For instance, the computation loop 24 is performed until a predetermined stopping criterion is reached. The stopping criterion may be reached when a predetermined number of iterations of the computation loop 24 is performed, or when a relative change in performance between the results of two consecutive iterations of the computation loop 24 is lower than a predetermined minimal relative change.
Transmission Step 26
More precisely, in at least one embodiment, during the transmission step 26, for each identity associated with the central dataset 10, the central node 4 applies the current aggregated model 32 to the images of the central dataset 10 that are associated with said identity. In other words, for each identity, and for each image associated with said identity, the central node 4 computes a corresponding output of the aggregated model 32 using said image as input.
Then, for each identity associated with the central dataset 10, the central node 4 computes an associated prototype depending on the corresponding computed outputs of the aggregated model 32.
Resorting to such prototypes is advantageous. Indeed, with enough diverse identities and images per identity in the local dataset 10, the set of prototypes can serve as an approximation of the source domain distribution which can be transmitted with little cost to the local nodes 6. As will be shown below, said prototypes are used to align target domain distributions with the source domain distribution in each local node, during the training step 28.
Preferably, in at least one embodiment, for each identity, the central node 4 computes the respective prototype as an average of the respective outputs of the aggregated model 32.
For instance, the central node 4 is configured to compute each prototype as:
p k = 1 S k ∑ I ∈ S k F θ ( x I S ) , ∀ 1 ≤ k ≤ K
where:
-
- pk is the prototype associated with identity k;
- Sk is a subset of the central dataset 10 including the images associated with identity k;
- |Sk| is the number of images in the subset Sk;
- Fθ is the aggregated model 32;
- xlS is the l-th image of the subset Sk; and
- K is the number of identities associated with the central dataset 10.
Consequently, for each identity, the associated prototype pk is the centroid of the corresponding feature representation.
Moreover, for each identity k associated with the central dataset 10, the central node 4 transfers, to each local node 6, the associated prototype pk.
In the case where the images of the central dataset 10 have been gathered in compliance with relevant legislation, the transmission of the prototypes from the central node 4 to the local nodes 6 does not breach the privacy-preserving constraints, which is advantageous.
Furthermore, during the transmission step 26, the central node 4 also transfers, to each local node 6, aggregated model data representative of the current aggregated model 32.
Preferably, in at least one embodiment, the aggregated model data are coefficient values of the aggregated model 32, designated by refence “θS” in FIG. 1.
Training Step 28
Then, during the training step 28, each local node 6 performs a respective local training phase.
Furthermore, during the training step 28, the central node 4 performs a respective central training phase.
Local Training Phase
More precisely, during the local training phase, each local node 6 trains the respective local model 12 based on:
-
- the respective local dataset 14 stored thereon; and
- the received aggregated model data θS and prototypes {pk}.
As a result, a respective trained local model 34 is obtained.
Preferably, in at least one embodiment, during the local training phase, each local node 6 initializes the local model 12 using the aggregated model data θS received from the central node 4.
Preferably, in at least one embodiment, the aggregated model 32 and each local model 12 have the same architecture (which is especially the case if each local model 12 has the same architecture as the central model 8). In this case, each local node 6 initializes the corresponding local model 12 by replacing the value of each coefficient of said local model 12 with the value of the corresponding coefficient of the aggregated model 32 included in the received aggregated model data θS.
Then, each local node 6 preferably performs clustering on the images of the respective local dataset 14 to determine, for each image of said local dataset 14, a pseudo-label indicative, for each subject shown on said image, of an identity of said subject.
More precisely, each local node 6 applies the current local model 12 to the images of the respective local dataset 14, then implements a clustering algorithm on the resulting outputs to identify a certain number of clusters that are each assigned to a corresponding class.
In this case, each class is preferably used as a pseudo-label. More precisely, for any given identified cluster j, the corresponding class {tilde over (y)}j(i) is used as a pseudo-label for each image xj(i) belonging to said cluster j.
For instance, the clustering algorithm is DBSCAN (<<Density-Based Spatial Clustering of Applications with Noise >>).
Then, each local node 6 creates a teacher model and a student model based on the resulting local model.
For instance, each of the teacher model and the student model is a copy of the current local model.
Moreover, during the local training phase, each local node 6 iteratively performs a local training loop.
During each iteration of the local training loop, the local node 6 first selects a subset of the respective local dataset 14 to form a current local subset (also designated as Di,m).
Advantageously, for each local node 6, each selected local subset includes the images of the respective local dataset 14 associated with a predetermined number I of identities. This feature is advantageous, as it allows to set a number of iterations of the local training loop, as detailed below.
Then, the local node 6 modifies the student model to minimize a local loss function which depends on:
-
- an output of the current teacher model for each image of the current local subset;
- an output of the current student model for each image of the current local subset; and
- a current subset of the received prototypes, forming a prototype subset and having the same size as the current local subset.
Resorting to a loss function that depends on the received prototypes is advantageous, as it allows to align the target domain distribution (i.e., the distribution of the feature representations of the target domain, computed by the student model) with the source domain distribution (i.e., the distribution of the feature representations of the source domain, that is, of the prototypes).
Preferably, in at least one embodiment, the local node 6 computes the local loss function based on a pseudo-label loss function for each image of the local subset Di,m, and on a maximum mean discrepancy loss (or “MMD loss”) between the local subset Di,m and the current prototype subset Pm.
More precisely, the local node 6 may compute the local loss function as:
ℒ i = 1 m ∑ j ∈ D i , m ℒ p ( x j ( i ) ) + λℒ M ( D i , m , P m )
where:
-
- i is the local loss function;
- m is the size of the local subset;
- Di,m is the current local subset;
- p(xj(i)) is the pseudo-label loss function for the j-th image of the local subset Di,m;
- λ is a predetermined weighting factor;
- Pm is the current prototype subset; and
- M(Di,m, Pm) is the maximum mean discrepancy loss between the local subset Di,m and the current prototype subset Pm.
Using the MMD loss has many advantages. Indeed, it is flexible, as it allows to choose any kernel function to project the data in the corresponding reproducing kernel Hilbert space (or “RKHS space”). It is also effectively used in high dimensional settings (especially when working with images). Furthermore, the MMD loss has been shown to be useful when used as a loss function for domain adaptation tasks.
The MMD loss can be understood as a distance between two distributions. In particular, if p and q are two distributions then we should have MMD (p,q)=0 if and only if p=q.
Preferably, considering the j-th image of the local subset Di,m, the local node 6 computes the corresponding pseudo-label loss as:
ℒ p ( x j ( i ) ) = ℒ C , i ( x j ( i ) ) + ℒ T , i ( x j ( i ) )
where:
-
- C,i(xj(i)) is a cross-entropy loss term; and
- T,i(xj(i)) is a triplet loss term.
Preferably, the cross-entropy loss term C,i(xi(i)) is calculated as:
ℒ C , i ( x j ( i ) ) = β 1 ℒ C ( C i ∘ F θ i ( x j ( i ) ) , y ~ j ( i ) ) + β 2 ℒ C ( C i ∘ F θ i ( x j ( i ) ) , C _ i ∘ F θ _ i ( x j ( i ) ) )
Preferably, the triplet loss term T,i(xj(i)) is calculated as:
ℒ T , i ( x j ( i ) ) = γ 1 ℒ T ( F θ i ( x j ( i ) ) , y ~ j ( i ) ) + γ 2 ℒ T ( F θ i ( x j ( i ) ) , F θ _ i ( x j ( i ) ) )
More precisely:
-
- xj(i) is j-th image of the local subset Di,m;
- C is a cross-entropy loss;
- T is a triplet loss;
- Ci is a student classifier head for local node i;
- Ci is a teacher classifier head for local node i;
- β1+β2=1
- γ1+γ2=1
- xj(i) is the j-th image of the local subset Di,m;
- {tilde over (y)}j(i) is the pseudo-label associated with image xj(i);
- Fθi is the student model; and
- Fθi is the teacher model.
Using the cross-entropy loss and the triplet loss is advantageous, as they are particularly well suited for reidentification models.
Each classifier head is designed to match the number of classes of the teacher model and the student model to the respective number of identities determined for each local dataset 14.
Then, the local node 6 stores the modified student model as the current student model, and updates the teacher model based on the current student model.
Preferably, in at least one embodiment, for each iteration of the local training loop, the updated teacher model is a linear combination of the current teacher model and the current student model.
For instance, for each iteration of the local training loop, a given local node 6 calculates the updated teacher model using exponential moving averaging according to:
θ _ i ( t + 1 ) = T θ _ i ( t ) + ( 1 - T ) θ i
where:
-
- θi(t+1) is a vector of the coefficient values of the updated teacher model of the i-th local node 6;
- θi(t) is a vector of the coefficient values of the current teacher model of the i-th local node;
- θi is a vector of the coefficient values of the current student model of the i-th local node; and
- τ is a predetermined weighting factor comprised in an interval ranging from 0 to 1.
Then, the local node 6 stores the updated teacher model as the current teacher model, used for the next iteration of the local training loop.
As mentioned previously, for each local node 6, each corresponding local subset advantageously includes the images of the respective local dataset associated with the predetermined number I of identities. In this case, for each local node 6, the local training loop is performed a number of times Pi calculated as:
P i = K i I
where:
-
- Pi is the number of iterations of the local training loop;
- Ki is the number of identities associated with the respective local dataset 14; and
- I is the predetermined number of identities associated with each local subset Di,m.
This feature is advantageous, as it helps preventing over-fitting in local nodes 6 having local datasets 14 with only a few identities or images. Consequently, the number of iterations Pi ensures equal usage of all identities within a local node 6 during a given iteration of the computation loop 22, regardless of the variation in the number of identities across the local datasets 14.
Then, after the local training phase has been completed for the current iteration of the computation loop 22, the local node 6 stores the current teacher model as the aforementioned trained local model 34.
Central Training Phase
Advantageously, in at least one embodiment, during the training step 28, the central node 4 performs a central training phase similar to the local training phase, to obtain a trained central model 36. This feature is advantageous, as it facilitates more efficient model aggregation.
More precisely, during the central training phase, the central node 4 performs supervised training based on the current aggregated model 32, using the central dataset 10 stored thereon. As a result, the trained central model 36 is obtained.
More precisely, the central node 4 first creates a teacher model and a student model based on the current aggregated model 32. For instance, each of the teacher model and the student model is a copy of the current aggregated model 32.
Furthermore, during the central training phase, the central node 4 iteratively performs a central training loop.
During each iteration of the central training loop, the central node 4 first selects a subset of the central dataset 10 to form a current central subset (also designated as DS,m).
Advantageously, each selected central subset includes the images of the central dataset 10 that are associated with a predetermined number of identities J.
Then, the central node 4 modifies the student model to minimize a source loss function which depends on:
-
- an output of the current teacher model for each image of the current central subset; and
- an output of the current student model for each image of the current central subset.
Preferably, the central node 4 computes the source loss function as:
ℒ = 1 m ∑ j ∈ D i , m ℒ S ( x j S , y j S )
where:
-
- is the source loss function;
- m is the size of the central subset;
- DS,m is the current central subset;
- S(xjS, yjS) is a central model loss function for the j-th image of the central subset DS,m;
- xjS is the j-th image of the central subset DS,m; and
- yjS is the label associated with image xjS.
Preferably, considering the j-th image of the central subset, the central node 4 computes the central model loss function as:
ℒ S ( x j S , y j S ) = ℒ C , S ( x j S , y j S ) + ℒ T , S ( x j S , y j S )
where:
-
- C,S(xjS, yjS) is a cross-entropy loss term; and
- T,S(xjS, yjS) is a triplet loss term.
Preferably, the cross-entropy loss term C,S(xjS, yjS) is calculated as:
ℒ C , S ( x j S , y j S ) = δ 1 ℒ C ( C S ∘ F θ S ( x j S ) , y j S ) + δ 2 ℒ C ( C S ∘ F θ S ( x j S ) , C _ S ∘ F θ _ S ( x j S ) )
Preferably, the triplet loss term T,S(xjS, yjS) is calculated as:
ℒ T , S ( x j S , y j S ) = μ 1 ℒ T ( F θ i ( x j S ) , y j S ) + μ 2 ℒ T ( F θ i ( x j S ) , F θ _ i ( x j S ) )
More precisely:
-
- C is the cross-entropy loss;
- T is the triplet loss;
- CS is a student classifier head for the central node;
- CS is a teacher classifier head for the central node;
- FθS is the student model;
- FθS is the teacher model;
δ 1 + δ 2 = 1 ; and μ 1 + μ 2 = 1.
Each classifier head is designed to match the number of classes of the teacher model and the student model to the number of identities associated with the central dataset 10.
Then, the central node 4 stores the modified student model as the current student model, and updates the teacher model based on the current student model.
Preferably, in at least one embodiment, for each iteration of the central training loop, the updated teacher model is a linear combination of the current teacher model and the current student model.
For instance, for each iteration of the central training loop, the central node 4 calculates the updated teacher model using exponential moving averaging according to:
θ _ S ( t + 1 ) = ρ θ _ S ( t ) + ( 1 - ρ ) θ S
where:
-
- θS(t+1) is a vector of the coefficient values of the updated teacher model;
- θS(t) is a vector of the coefficient values of the current teacher model;
- θS is a vector of the coefficient values of the current student model; and
- ρ is a predetermined weighting factor comprised in an interval ranging from 0 to 1.
Then, the central node 4 stores the updated teacher model as the current teacher model, used for the next iteration of the central training loop.
Preferably, the central training loop is performed a number of times PS calculated as:
P S = K S J
where:
-
- PS is the number of iterations of the central training loop;
- KS is the number of identities associated with the central dataset 10; and
- J is the predetermined number of identities associated with each central subset DS,m.
Then, after the central training phase has been completed for the current iteration of the computation loop 22, the central node 4 stores the current teacher model as the trained central model 36.
Aggregation Step 30
Then, during the aggregation step 30, each local node 6 transfers, to the central node 4, local model data θi representative of the respective trained local model.
Preferably, in at least one embodiment, for each local node 6, the corresponding local model data θi are coefficient values of the respective trained local model 34.
Then, the central node 4 updates the aggregated model 32 based on:
-
- the local model data θi received from each local node 6; and
- central model data representative of the trained central model 36.
Preferably, in at least one embodiment, the central model data are coefficient values of the trained central model.
Preferably, in at least one embodiment, to update the aggregated model 32, the central node 4 computes the coefficient values of the aggregated model 32 as a linear combination of the local model data and the central model data.
For instance, the central node 4 computes the coefficient values of the aggregated model as a weighted average sum given by:
θ = αθ s + ( 1 - α ) ∑ i = 1 n w i θ i
where:
-
- θ is a vector of the coefficient values of the aggregated model;
- α is a predetermined weight contribution of the trained central model;
- θS is a vector of the coefficient values of the trained central model;
- θi is a vector of the coefficient values of the i-th trained local model; and
- wi is a weight assigned to i-th local node 6; and
- Ni is the number of images in the local dataset stored in the i-th local node.
Preferably, in at least one embodiment, the weight wi assigned to i-th local node is computed as:
w i = N i ∑ i = 1 n N i
As a result, an updated aggregated model, forming the current aggregated model 32, is obtained.
As mentioned previously, the computation loop 24 is iteratively performed until the predetermined stopping criterion is reached. At this stage, each local model 34 is considered as trained, and domain alignment between the source domain and each target domain is considered as performed.
Of course, the one or more embodiments of the invention are not limited to the examples detailed above.
Claims
1. A computer-implemented method for performing privacy-preserving federated learning in the framework of re-identification, the computer-implemented method comprising:
iteratively performing a computation loop that comprises
a transmission step comprising
based on a labeled central dataset including a set of images, each image of said set of images being associated with a label indicative, for each subject shown on said each image, of an identity of said each subject,
computing, by a central node, for said identity of said each subject, and for said each image associated therewith, a corresponding output of a current aggregated model using said each image as input;
transferring, from the central node to each of n local nodes, n being an integer greater than or equal to 1, each local node being distinct from the central node,
aggregated model data representative of the current aggregated model; and
for said identity of said each subject, an associated prototype depending on the corresponding output that is computed of the current aggregated model;
a training step comprising
for said each local node, a local training phase comprising training a respective local computer vision model based on
a respective unlabeled local dataset stored in said each local node and including a set of images previously acquired with at least one respective camera; and
the aggregated model data and said associated prototype that are received,
thereby obtaining a respective trained local model; and
a central training phase comprising performing supervised training of the current aggregated model, at the central node, based on the central dataset, thereby obtaining a trained central model;
an aggregation step comprising
for said each local node, transferring, from said each local node to the central node, local model data representative of the respective trained local model;
updating the current aggregated model based on
the local model data; and
central model data representative of the trained central model; and
storing, in the central node, the current aggregated model that is updated as the current aggregated model.
2. The computer-implemented method according to claim 1, further comprising, prior to performing the computation loop, an initialization step comprising
performing supervised training of a central computer vision model, based on the central dataset; and
storing, in the central node, a result of the supervised training of the central computer vision model as the current aggregated model.
3. The computer-implemented method according to claim 1, wherein the current aggregated model, the trained central model, and each trained local model have a same architecture, and wherein,
the aggregated model data are coefficient values of the current aggregated model;
for said each local node, the local model data corresponding thereto are coefficient values of the respective trained local model; and
the central model data are coefficient values of the trained central model.
4. The computer-implemented method according to claim 3, wherein said updating the aggregated model includes computing the coefficient values of the current aggregated model as a linear combination of the local model data and the central model data, as a weighted average sum calculated as:
θ = αθ s + ( 1 - α ) ∑ i = 1 n w i θ i
where:
θ is a vector of the coefficient values of the current aggregated model;
α is a predetermined weight contribution of the trained central model;
θS is a vector of the coefficient values of the trained central model;
θi is a vector of the coefficient values of the i-th trained local model; and
wi is a weight assigned to i-th local node, computed as: wi=Ni/Σi=1n Ni; and
Ni is a number of images in the respective unlabeled local dataset stored in the i-th local node.
5. The computer-implemented method according to claim 1, wherein, for said identity of said each subject, the respective prototype is an average of the corresponding output of the current aggregated model using, as input, the images of the central dataset associated with said identity, each prototype calculated as:
p k = 1 ❘ "\[LeftBracketingBar]" S k ❘ "\[RightBracketingBar]" ∑ l ∈ S k F θ ( x l S ) , ∀ 1 ≤ k ≤ K
where:
pk is the prototype associated with identity k;
Sk is a subset of the central dataset including the images associated with identity k;
|Sk| is a number of images in the subset Sk;
Fθ is the current aggregated model;
xlS is the l-th image of the subset Sk; and
K is a number of identities associated with the central dataset.
6. The computer-implemented method according to claim 1, further comprising, for each local dataset, implementing a clustering algorithm on the images of said each local dataset to determine, for said each image of said each local dataset, a pseudo-label indicative, for said each subject shown on said image, of said identity of said each subject, and for said each local node, the local training phase comprising
initializing a teacher model and a student model with the aggregated model data that is received;
iteratively performing, at said each local node, a local training loop including selecting a subset of the respective local dataset to form a current local subset;
modifying the student model to minimize a local loss function depending on:
an output of the teacher model for said each image of the local subset;
an output of the student model for said each image of the local subset;
a subset of the prototype that is received, forming a prototype subset and having a same size as the local subset;
storing the student model that is modified as the student model;
updating the teacher model based on the student model;
storing the teacher model that is updated as the teacher model;
assigning the teacher model as the trained local model.
7. The computer-implemented method according to claim 6, wherein the local loss function is computed based on a pseudo-label loss function for said each image of the current local subset and on a maximum mean discrepancy loss between the current local subset and the current prototype subset, computed as:
ℒ i = 1 m ∑ j ∈ D i , m ℒ p ( x j ( i ) ) + λℒ M ( D i , m , P m )
where:
i is the local loss function;
m is a size of the local subset;
Di,m is the current local subset;
p(xj(i)) is the pseudo-label loss function for a j-th image of the local subset Di,m;
λ is a predetermined weighting factor;
Pm is the current prototype subset; and
M(Di,m, Pm) is a maximum mean discrepancy loss between the local subset Di,m and the current prototype subset Pm.
8. The computer-implemented method according to claim 7, wherein the pseudo-label loss for the j-th image of the local subset Di,m is computed as:
ℒ p ( x j ( i ) ) = ℒ C , i ( x j ( i ) ) + ℒ T , i ( x j ( i ) )
where:
C,i(xj(i)) is a cross-entropy loss term; and
T,i(xj(i)) is a triplet loss term,
the cross-entropy loss term C,i(xj(i)) being calculated as:
ℒ C , i ( x j ( i ) ) = β 1 ℒ C ( C i ∘ F θ i ( x j ( i ) ) , y ~ j ( i ) ) + β 2 ℒ C ( C i ∘ F θ i ( x j ( i ) ) , C i _ ∘ F θ _ i ( x j ( i ) ) )
and/or the triplet loss term T,i(xj(i)) being calculated as:
ℒ T , i ( x j ( i ) ) = γ 1 ℒ T ( F θ i ( x j ( i ) ) , y ~ j ( i ) ) + γ 2 ℒ T ( F θ i ( x j ( i ) ) , F θ _ i ( x j ( i ) ) )
where:
xj(i) is j-th image of the local subset Di,m;
C is a cross-entropy loss;
T is a triplet loss;
Ci is a student classifier head for local node i;
Ci is a teacher classifier head for local node i;
β 1 + β 2 = 1 γ 1 + γ 2 = 1
xj(i) is the j-th image of the local subset Di,m;
yj(i) is the pseudo-label associated with image xj(i);
Fθi is the student model; and
Fθi is the teacher model.
9. The computer-implemented method according to claim 1, wherein the central training phase further comprises
initializing a teacher model and a student model with the current aggregated model;
iteratively performing, at the central node, a central training loop including selecting a subset of the central dataset to form a current central subset;
modifying the student model to minimize a source loss function depending on
an output of the teacher model for said each image of the current central subset; and
an output of the student model for said each image of the current central subset;
storing the student model that is modified as the student model;
updating the teacher model based on the student model;
storing the teacher model that is updated as the teacher model;
assigning the teacher model as the trained central model.
10. The computer-implemented method according to claim 9, wherein the source loss function is computed as:
ℒ = 1 m ∑ j ∈ D i , m ℒ S ( x j s , y j s )
where:
is the source loss function;
m is a size of the central subset;
DS,m is the current central subset;
S(xjS, yjS) is a central model loss function for the j-th image of the central subset DS,m;
xjS is a j-th image of the central subset DS,m; and
yjS is the label associated with image xjS.
11. The computer-implemented method according to claim 10, wherein the central model loss function is computed as:
ℒ S ( x j s , y j s ) = ℒ C , S ( x j s , y j s ) + ℒ T , S ( x j s , y j s )
where:
C,S(xjS, yjS) is a cross-entropy loss term; and
T,S(xjS, yjS) is a triplet loss term,
the cross-entropy loss term C,S(xjS, yjS) being calculated as:
ℒ C , S ( x j s , y j s ) = δ 1 ℒ C ( C S ∘ F θ s ( x j s ) , y j s ) + δ 2 ℒ C ( C S ∘ F θ s ( x j s ) , C _ S ∘ F θ _ s ( x j s ) )
and/or the triplet loss term T,S(xjS, yjS) being calculated as:
ℒ T , S ( x j s , y j s ) = μ 1 ℒ T ( F θ i ( x j s ) , y j s ) + μ 2 ℒ T ( F θ i ( x j s ) , F θ _ i ( x j s ) )
where:
C is a cross-entropy loss;
T is a triplet loss;
CS is a student classifier head for the central node;
CS is a teacher classifier head for the central node;
FθS is the student model;
FθS is the teacher model;
δ 1 + δ 2 = 1 ; and μ 1 + μ 2 = 1.
12. The computer-implemented method according to claim 6, wherein, for said each local node, each corresponding local subset includes the images of the respective local dataset associated with a predetermined number of identities, and
for said each local node, and for each local training phase, the local training loop being performed a number of times calculated as:
P i = K i I
where:
Pi is a number of iterations of the local training loop;
Ki is a number of identities associated with the respective local dataset Di; and
I is the predetermined number of identities associated with each local subset Di,m;
and/or
each central subset includes the images of the central dataset associated with a predetermined number of identities, and
for each central training phase, the central training loop being performed a number of times calculated as:
P S = K S J
where:
PS is a number of iterations of the central training loop;
KS is a number of identities associated with the central dataset; and
J is the predetermined number of identities associated with each central subset.
13. The computer-implemented method according to claim 6, wherein, for said each local node, and for each iteration of the local training loop, the teacher model that is updated is a linear combination of the teacher model and the student model, calculated using exponential moving averaging according to:
θ _ i ( t + 1 ) = τ θ _ i ( t ) + ( 1 - τ ) θ i
where:
θi(t+1) is a vector of the coefficient values of the updated teacher model of the i-th local node;
θi(t) is a vector of the coefficient values of the current teacher model of the i-th local node;
θi is a vector of the coefficient values of the current student model of the i-th local node; and
τ is a predetermined weighting factor comprised in an interval ranging from 0to 1;
and/or
for each iteration of the central training loop, the teacher model that is updated is a linear combination of the current teacher model and the student model, calculated using exponential moving averaging according to:
θ _ S ( t + 1 ) = ρ θ _ S ( t ) + ( 1 - ρ ) θ S
where:
θS(t+1) is a vector of the coefficient values of the updated teacher model;
θS(t) is a vector of the coefficient values of the current teacher model;
θS is a vector of the coefficient values of the current student model; and
ρ is a predetermined weighting factor comprised in an interval ranging from 0 to 1.
14. A computer program comprising instructions, which when executed by a computer, cause the computer to carry out a computer-implemented method comprising:
iteratively performing a computation loop that comprises
a transmission step comprising
based on a labeled central dataset including a set of images, each image of said set of images being associated with a label indicative, for each subject shown on said each image, of an identity of said each subject, computing, by a central node, for said identity of said each subject, and for said each image associated therewith, a corresponding output of a current aggregated model using said each image as input;
transferring, from the central node to each of n local nodes, n being an integer greater than or equal to 1, each local node being distinct from the central node,
aggregated model data representative of the current aggregated model; and
for said identity of said each subject, an associated prototype depending on the corresponding output that is computed of the current aggregated model;
a training step comprising
for said each local node, a local training phase comprising training a respective local computer vision model based on
a respective unlabeled local dataset stored in said each local node and including a set of images previously acquired with at least one respective camera; and the aggregated model data and said associated prototype that are received,
thereby obtaining a respective trained local model; and
a central training phase comprising performing supervised training of the current aggregated model, at the central node, based on the central dataset, thereby obtaining a trained central model;
an aggregation step comprising
for said each local node, transferring, from said each local node to the central node, local model data representative of the respective trained local model;
updating the current aggregated model based on the local model data; and
central model data representative of the trained central model; and
storing, in the central node, the current aggregated model that is updated as the current aggregated model.
15. A framework for performing privacy-preserving federated learning for re-identification, the framework comprising:
a central node and n local nodes, n being an integer greater than or equal to 1, each local node of said n local nodes being distinct from the central node, the central node being configured to store a labeled central dataset including a set of images, each image of said set of images being associated with a label indicative, for each subject shown on said each image, of an identity of said each subject, said each local node being configured to store a respective unlabeled local dataset stored in said each local node and including a set of images previously acquired with at least one respective camera, the framework being configured to iteratively perform a computation loop that comprises
a transmission step wherein,
the central node computes, based on the central dataset, for said identity of said each subject, and for said each image associated therewith, a corresponding output of a current aggregated model using said each image as input;
the central node transfers to said each local node,
aggregated model data (θS) representative of the current aggregated model; and
for said identity of said each subject, an associated prototype (pk) depending on the corresponding output that is computed of the current aggregated model;
a training step wherein,
said each local node performs a local training phase comprising training a respective local computer vision model based on
the respective unlabeled local dataset; and
the aggregated model data (θS) and associated prototypes that are received,
thereby obtaining a respective trained local model; and
the central node performs a central training phase comprising performing supervised training of the current aggregated model based on the central dataset, thereby obtaining a trained central model;
an aggregation step wherein,
said each local node transfers, to the central node, local model data (θ1, θn) representative of the respective trained local model;
the central node updates the current aggregated model based on:
the local model data (θ1, θn); and
central model data representative of the trained central model; and
the central node stores the current aggregated model that is updated as the current aggregated model.
Images & Drawings included:
















































Sources:
- United States Patent and Trademark Office - verify current appl. status at the USPTO↗
Recent applications in this class:
- » 20250272574 2025-08-28
OFFLINE MULTI-VENDOR TRAINING FOR CROSS-NODE MACHINE LEARNING - » 20250272573 2025-08-28
METHOD AND APPARATUS FOR PROVIDING CUSTOMIZED ARTIFICIAL NEURAL NETWORK MODEL BY USING FEDERATED LEARNING - » 20250265475 2025-08-21
Model Training Method and Apparatus - » 20250265474 2025-08-21
INFORMATION PROCESSING APPARATUS, INFORMATION PROCESSING METHOD, AND NON-TRANSITORY RECORDING MEDIUM - » 20250259076 2025-08-14
SYSTEMS AND METHODS FOR EXECUTING VERTICAL FEDERATED LEARNING - » 20250252319 2025-08-07
METHODS AND SYSTEMS FOR GENERATING, TRAINING, COMBINING, AND USING FEDERATED LARGE LANGUAGE MODELS (LLMs) IN AN ENTERPRISE CONTEXT - » 20250245519 2025-07-31
INFORMED PRUNING FOR DEFENDING AGAINST MODEL INVERSION ATTACKS IN FEDERATED LEARNING - » 20250238682 2025-07-24
MULTI-EDGE COOPERATIVE UNIVERSAL FRAMEWORK FOR LOAD PREDICTION WITH PERSONALIZED FEDERATED DEEP LEARNING - » 20250232188 2025-07-17
METHOD AND SYSTEM FOR A CROSS-SILO SERVERLESS COLLABORATIVE LEARNING IN A MALICIOUS CLIENT THREAT-MODEL - » 20250232187 2025-07-17
Modular Large Language Model (LLM) Guided Tree-of-Thought System
Recent applications for this Assignee:
- » 20250280261 2025-09-04
METHOD, SYSTEM AND BASE STATION FOR CHARACTERIZING CELLULAR DEVICES - » 20250278742 2025-09-04
METHOD FOR MANAGING CUSTOMER COMMUNICATIONS - » 20250272595 2025-08-28
METHOD OF SIMULATING EXECUTION OF A QUANTUM ALGORITHM BY USING A CLUSTER OF NON-QUANTUM COMPUTERS - » 20250245535 2025-07-31
DATA PROCESSING METHOD AND APPARATUSES FOR IMPLEMENTING THE SAME - » 20250238995 2025-07-24
DATA GENERATION METHOD, ASSOCIATED COMPUTER PROGRAM AND COMPUTING DEVICE - » 20250233909 2025-07-17
SYSTEM AND METHOD FOR MANAGING PACKET TRANSMISSION ISSUES IN HIGH-PERFORMANCE COMPUTERS - » 20250232224 2025-07-17
METHOD FOR TRAINING AN ARTIFICIAL INTELLIGENCE MODEL AND ASSOCIATED COMPUTER PROGRAM - » 20250232059 2025-07-17
PRIVACY-PRESERVING FEDERATED LEARNING METHOD, ASSOCIATED COMPUTER PROGRAM AND FRAMEWORK - » 20250183676 2025-06-05
Supervision module for managing digital battery passports - » 20250183675 2025-06-05
DISTRIBUTION MODULE FOR MANAGING DIGITAL BATTERY PASSPORTS